









保護されたワークロードを以前の状態にリカバリするために、ローテーションまたは保存されたインスタンスを使用できます。ローテーションされたインスタンスの自動保持を回避するために、ローテーションされた特定のインスタンスを保存できます。保存されたインスタンスは変更されず、ローテーションされたインスタンスの全体的な保持期間に関係なく、それらを使用して、保存されたインスタンスにワークロードをリカバリできます。
VMware Cloud Director Availability は、保護されたワークロードをリカバリできる次の 2 種類のインスタンスをサポートします。
- ローテーションされたインスタンス:
-
ローテーションされたインスタンスは、保護の存続期間中に自動的に保持され、ローテーションされます。
VMware Cloud Director Availability は、最後にローテーションされたインスタンスの構成可能な数を自動的に保持し、ワークロードをいずれかのインスタンスにリカバリできるようにします。
- 保存されたインスタンス:
-
自動保持は、保存されたインスタンスには影響しません。
インスタンスを手動で保存した後も、保存されたインスタンスは変更されず、保護が引き続き有効な場合は、その保存されたインスタンスにワークロードをリカバリできます。
- インスタンスは、ソース仮想マシンに対して有効になっている [変更ブロックのトラッキング (CBT)] と相互運用できません。詳細については、その他のストレージのレプリケートを参照してください。
- 移行では、インスタンスは使用されません。
ローテーションされたインスタンスの自動保持は、保存することでバイパスできます。VMware Cloud Director Availability は、保存されたインスタンスを、保存済みとしてマークされなくなるまで、または手動で削除されるまで保持します。最新のインスタンスを使用しない場合、保存されているすべてのインスタンスを削除できます。
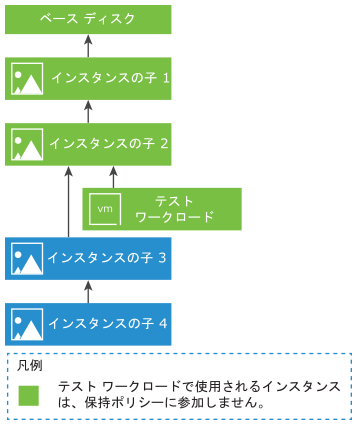
その結果、リカバリされた仮想マシンの読み取りパフォーマンスは、階層の深さとインスタンスのサイズの両方に依存します。インスタンスがベース ディスクに近いほど、リカバリされた仮想マシンの読み取りパフォーマンスが向上します。
- フェイルオーバーまたは移行の実行後、インスタンスの統合が完了すると、リカバリされた仮想マシンは最適な読み取りパフォーマンスに達します。インスタンスを統合する期間は、親インスタンスの数とそのサイズによって異なります。この統合は、パワーオン状態の仮想マシンとパワーオフ状態の仮想マシンの両方で実行されます。
- テスト フェイルオーバーの実行後、インスタンスの統合が実行されないため、リカバリされた仮想マシンの読み取りパフォーマンスが最適でない場合があります。テスト フェイルオーバーの実行時にリカバリされた仮想マシンの読み取りパフォーマンスを向上させるには、ベース ディスクに近い古いインスタンスを選択します。
高度な保持ルール
VMware Cloud Director Availability 4.3 以降では、保護のローテーションされたインスタンスに対して複数の保持ルールを構成できます。
- 組織に割り当てられたレプリケーション ポリシーで、保護のための複数の保持ルール(最大 5 つ)の構成を許可するには、[高度な保持ルールを許可] を選択します。
このオプションを選択解除すると、複数の保持ルールで構成されている組織に割り当てられた SLA プロファイルを選択しない限り、保護のために単一の保持ルールのみを構成できます。SLA プロファイルを使用する場合、レプリケーション ポリシーのインスタンスの最大数は考慮されず、インスタンスは SLA プロファイルに従って制限されます。
- 組織に割り当てられた SLA プロファイルでは、最大 5 つの保持ルールを構成できます。
割り当てられたレプリケーション ポリシーで高度な保持ルールが許可されていない場合は、保護のレプリケーション設定で、複数の保持ルールで構成された、組織に割り当てられた SLA プロファイルを選択できます。
- 新規または既存の保護のレプリケーション設定で、単一の保持ルールを構成できます。割り当てられたレプリケーション ポリシーで許可されている場合は、複数の保持ルールを構成できます。
割り当てられたレプリケーション ポリシーで高度な保持ルールが許可されていない場合、複数の保持ルールで構成された、組織に割り当てられた SLA プロファイルを選択できます。
SLA プロファイルまたはレプリケーション設定で、[ポイント イン タイム インスタンスの保持ポリシー] の下の [保持ポリシーを有効化] を選択し、[ルールの追加] をクリックして最大 5 つのルールを作成します。これにより、ローテーションされたインスタンスの数とその分散した時間の距離など、保持ルールの構成が有効になります。
各保持ルールでは、次の保持設定を選択できます。
- 10 個のインスタンス(距離 10 分単位) - 保持期間:100 分。
- 10 個のインスタンス(距離 1 時間単位) - 保持期間:10 時間。
- 2 個のインスタンス(距離 3 日単位) - 保持期間:6 日。
- 2 個のインスタンス(距離 2 か月単位) - 保持期間:4 か月。
この例のインスタンスの合計数は、最大 24 個のローテーションされたインスタンスに一致します。
VMware Cloud Director Availability は、上から下に複数の保持ルールを評価し、最初に上位レベルのルールに一致するインスタンスを保持してから、保持ルールのチェーンを続行します。
- ターゲット目標復旧ポイント (RPO) は、常に構成された保持期間の距離以下にする必要があります。そうしないと、「保持の距離は RPO よりも大きくする必要があります」というメッセージが表示されます。
- 各高度な保持ルールでは、ローテーションされたインスタンス間の時間の距離を変更できます。最初のルールから最後のルールまで、次の各ルールの距離を増やす必要があります。増やさないと、「
Retention rules should have increasing distance」というメッセージが表示されます。
- 複数の保持ルールを持つ SLA プロファイルを使用したレプリケーションを、手動で構成された SLA 設定(レプリケーション ポリシーで [高度な保持ルールを許可] を選択解除)を使用するように再構成する場合は、追加のルールを削除して保持ルールを 1 つしか残さないまで、「
Policy doesn not allow multiple rules」というメッセージが表示されます。
