









VMware Cloud on AWS Autoscaler サービスでは、SDDC インフラストラクチャの健全性を監視し、初期の障害と実際の障害を検出して、障害が発生する前または後にホストを置き換えることでインフラストラクチャを自動的に修正します。
AWS インフラストラクチャは信頼性に優れていますが、最も信頼性の高いインフラストラクチャであっても障害は避けられません。AWS アーキテクチャ フレームワークの信頼性ピラーでは、クラウドの信頼性に関する設計原則を取り上げています。VMware Cloud on AWS では、基盤となるインフラストラクチャを抽象化し、vCenter Server と ESXi の予期される障害の分析機能を活用することで、これらの原則を拡張し、障害が発生した場合のリアクティブな修正および障害によるワークロードへの影響を防ぐことができる予測的な修正を提供します。
自動修正プロセスの大部分はバックグラウンドで実行され、既存のワークロードに影響を与えることなく実行されます。自動修正では、システムの健全性を監視し、必要に応じて SDDC にハードウェアを迅速に追加できます。これにより、障害の発生時や、健全性の問題が検出された場合に新しいホストをクラスタに挿入し、障害が発生しそうなハードウェアまたは障害が発生したハードウェアからワークロード仮想マシンを退避させることができます。また、すべての
VMware Cloud on AWS SDDC は VMware
vSAN と vSphere HA を使用するため、ホスト障害の影響を受けるワークロードは自動的に再配置され、再起動されます。
注: 自動修正または予定メンテナンスに使用される追加ホストの料金が請求されることはありません。
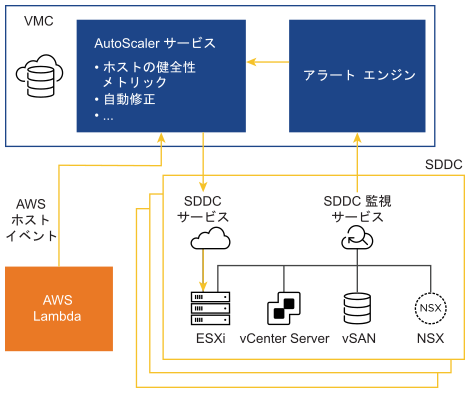
自動修正のハイレベル アーキテクチャ
自動修正のアーキテクチャには、AWS と VMware の両方から提供されるコンポーネントが含まれます。
- AWS は VMware のホストレベルの情報を送信します。中でも重要なのは、AWS 予定メンテナンス イベントです。これらの通知は、Autoscaler サービスが受信して、SDDC 内の問題を自動的に修正します。
- SDDC レベルの監視サービスは、基盤となる VMware Cloud on AWS コンポーネントから通知を受け取ります。
リアクティブな修正
リアクティブな自動修正では、ハードウェアとソフトウェアの障害を監視し、いくつかの方法で問題の修正を試みます。自動修正は内部プロセスであり、常に進化しています。VMware Cloud on AWS ユーザーは、ワークフローまたはその構成にアクセスできませんが、理解を深めるために、現在必要な手順の概要をここで示します。
- 1:監視
- VMware Cloud on AWS では、SDDC 内のすべてのホストの健全性を継続的に監視します。障害が検出されると、自動修正にイベントが送信されます。
- 2:一時的なイベントの待機
- 検出される障害の一部は一時的なものです。たとえば、一時的な接続の問題のために、監視システムがホストにアクセスできない場合などです。自動修正は、問題が一時的なものかどうかを判断するために 5 分間待機します。一時的な問題の場合、自動修正はアクションを実行せずに戻ります。
- 3:ホストの追加
- 5 分後もエラーが解決しない場合、自動修正によって SDDC に対するホストの追加が開始します。この方法でホストをあらかじめ追加しておくと、必要に応じてホストを使用できるようになります。SDDC 内の障害のあるホストがこのホストに置き換えられるまで、このホストは請求対象になりません。
- 4:障害タイプの特定とアクションの実行
- ホストの障害はさまざまな理由で発生し、さまざまなアクションが必要になる場合があります。たとえば、vCenter Server に引き続き接続された状態のホストで発生する vSAN ディスク障害は、ソフト リブートで解消できますが、PSOD ホストにはハード リブートが必要です。
- 5:ホストの健全性の確認
- 次の手順では、修正アクションでホストの問題が修正されたかどうかを確認します。障害発生ホストの状態が、ソフト リブートまたはハード リブート後に健全になった場合、自動修正では、SDDC のそれ以上の中断は行われません。自動修正では、その他の必要なアクションを収集して実行し、手順 3 であらかじめ追加しておいた新しいホストを削除します。
- 6:ホストの置き換え
- 障害発生ホストを回復できない場合、障害発生ホストは Autoscaler によって削除され、手順 3 で追加したホストに置き換えられます。vSphere HA と vSAN がトリガされ、コンピューティング ポリシー タグが新しいホストに添付されます。
プリエンプティブな修正
Autoscaler では、リアクティブな修正に加えて、いくつかの独立したフィードを監視して、障害の発生前の特定を試みます。ホストでハードウェア障害が発生する可能性が高いとサービスが判断した場合、無停止のプリエンプティブな予定メンテナンス イベントがトリガされます。予定メンテナンスが完了する前にホストで障害が発生する可能性はありますが、ホストの交換をあらかじめ開始しておくことで、影響は最小限に抑えられます。予定メンテナンス中の動作は次のとおりです。
- 新しいホストがクラスタに追加されます。タグは、置き換えるホストからこの新しいホストにコピーされます。
- 障害が発生したホストがメンテナンス モードになります。すべてのデータが退避されます。これにより、仮想マシンや vSAN データがクラスタ内の他のホストに無停止で移動されます。
- 障害が発生したホストがクラスタから削除されます。
Autoscaler イベント
Autoscaler サービスが障害イベントを受信すると、障害タイプを判断して適切なアクションを実行します。SDDC アクティビティ ログには Autoscaler のアクティビティが含まれますが、アクティビティをトリガした障害イベントは表示されません。
- vCenter Server のイベント
-
- ホストの接続状態を確認するイベントがトリガされます
- イベントは、ESXi ホストが切断されるか、応答しない場合にトリガされます。
- DAS イベント
-
- vSphere HA イベント: マスター ノードとの通信がない場合や、HA がダウンしている場合にイベントが作成されます。(FDM)
- ホストがダウンすると、HA システムはホスト障害を報告します。
- vSAN 個のイベント
-
- ホストでディスク障害が発生したとき。
- vSAN ホストが切断されたとき。
- EDRS イベント (非障害)
- アップグレード:EDRS が無効になります。メンテナンス アクティビティでは、多くの場合、追加のホストが必要です。このホストはメンテナンス イベントの一部として追加されます。予定メンテナンス中は、メンテナンス アクティビティでスケールイン/アウト イベントがトリガされるのを防ぐため、EDRS は無効になります。
- AWS イベント
-
- 予定メンテナンス イベント。インスタンスの健全性の問題が検出され、インスタンスを退避させる必要があることを示す AWS からの通知です。
- Personal Health Dashboard (PHD)。さまざまなハードウェア コンポーネントに関する判断材料を提供し、VMware がハードウェア障害を事前に検出できるようにするイベント ストリームです。
- システムのステータス チェック。インスタンスが依存する AWS システムの健全性を監視します。このチェックでは、AWS でのみ修正できる問題が報告されます。多くの場合、これらの問題は一時的なものであり、アクションは必要ありません。
- インスタンスのステータス チェック。各インスタンスのソフトウェアとネットワークの構成を監視します。このチェックでは、NIC に ARP 要求を定期的に発行して、インスタンスの可用性を監視します。EC2 レイヤーでのインスタンスの可用性に関するレポートに加えて、インスタンスのステータス チェックでは、基盤となるハードウェアの使用率を監視し、ネットワークの問題、メモリの枯渇、ファイル システムの破損、カーネル エラーなどを報告します。システムのステータス チェックとは異なり、インスタンスのステータス チェックでは、解決のために VMware による操作が必要です。
- SDDC イベント
- vCenter Server ホストの健全性。
