









このセクションでは、2 つのアベイラビリティ ゾーン (AZ) にまたがる Controller クラスタの展開、障害が発生した場合の動作、および特定の障害が発生した際に必要なリカバリ アクションについて説明します。
NSX Advanced Load Balancer Controller は、高可用性とスケーラビリティのために 3 ノード クラスタとして展開されます。これらのノードは、2 台のコントローラ ノード間の RTT(往復時間)値が 20 ミリ秒未満になるように展開する必要があります。AWS などのパブリック クラウド環境では、リージョンに複数のアベイラビリティ ゾーンがあります。このような環境では、ベスト プラクティスとして、各コントローラ ノードを個別の AZ に展開する必要があります。
リージョンに 3 つ以上の AZ がある場合、Controller クラスタの展開に関する考慮事項は単純です。ただし、多くのディザスタ リカバリ (DR) 環境では、次に示すように、3 台の Controller クラスタ ノードが展開される場合の AZ は 2 つのみです。
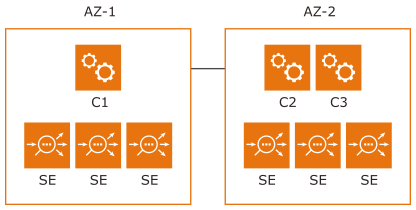
パーティション シナリオでは、少なくとも 2 台のノードが UP 状態で、かつ接続されている場合、Controller クラスタは UP になります。SE はアクティブなパーティションへの接続を試みます。アクティブなパーティションに接続できない場合、それらはヘッドレスな方法で、コントローラなしで動作し、アプリケーション トラフィックの処理を継続します。
上記の展開では、AZ-2 が DOWN になると、C1 が、クォーラムが足りないために停止します。このようなシナリオでは、Controller クラスタを UP にするため、手動での介入が必要となります。
大枠で見ると、手動ワークフローによって、残りのノードをスタンドアローン クラスタとしてリカバリすることができ、必要に応じて 2 台の新しいノードを追加することも可能です。この手順は手動で行うように意図的に設定されています。これにより、ユーザーはパーティションのリカバリを慎重に行うことになります。
動作しないクラスタのリカバリ
コントローラ C1 にログインし、/opt/avi/scripts/recover_cluster.py スクリプトを実行します。これにより、C1 がスタンドアローン クラスタとして再構成され、構成と分析データ(ログとメトリック)が保持され、Controller クラスタが UP になります。他の 2 台のコントローラ ノードのセキュア チャネル認証情報が失効になり、C1 と接続している SE が UP になります。この一環として、SE が、C1 にのみ接続するように自身を再構成します。
AZ-2 がリカバリされた場合の動作
C2 と C3 はクラスタを形成できます。AZ-2 の SE は、パーティション(C1 または C2+C3)のいずれかに接続する場合があります。この時点では、どちらのパーティションもアクティブであるため、実行時間が長くなりすぎると、中断が発生する可能性があります。これを回避するため、各コントローラ ノードは、構成済みメンバー リストにある他のコントローラ ノードをモニターします。ノードが、他のノードの構成済みメンバー リストにないことを識別すると、手動リカバリのために停止します。この場合、C1 が手動リカバリに進むために停止していることを C2 と C3 の両方が検出します。
すべての SE のセキュア チャネル認証情報が失効になります。この間に C2 または C3 に接続している SE は、Controller クラスタが手動リカバリ状態であることを検出し、再起動して、それ以上アプリケーション トラフィックを処理しなくなります。SE は、UP になると、C1 に接続して通常の操作を確立しようとします。コントローラ、C2、および C3 に送信された REST API コマンドは、状態コード 520 で失敗します。これは、clean_cluster.py スクリプトを使用して、これらのノードを工場出荷時のデフォルト値にリセットする必要があることを示します。
動作しないクラスタの作成
AZ-2 が稼動状態になると、直後に C2 と C3 が停止すると想定されます。C2 および C3 にログインし、/opt/avi/scripts/clean_cluster.py スクリプトを実行します。このスクリプトは、すべての構成と分析を消去し、スタンドアローン ノードとして起動します。C2 と C3 がクリーンアップされると、C1 に再度参加して 3 ノード クラスタを形成できます。
