









サーバの UP と DOWN が短時間に頻繁に切り替わるフラッピングは、一般的な問題です。一般的に、サーバ フラッピングは、サーバが健全性モニターの許容される最大応答時間に到達するか、わずかに超えた場合に発生します。
サーバのフラッピングが起きているかを検証するには、次のようにプール内の特定のサーバの分析ページを確認します。
の順に移動し、プール名をクリックします。
[サーバ] タブをクリックします。
サーバ名をクリックすると、次に示すようにそのメトリックが表示されます。
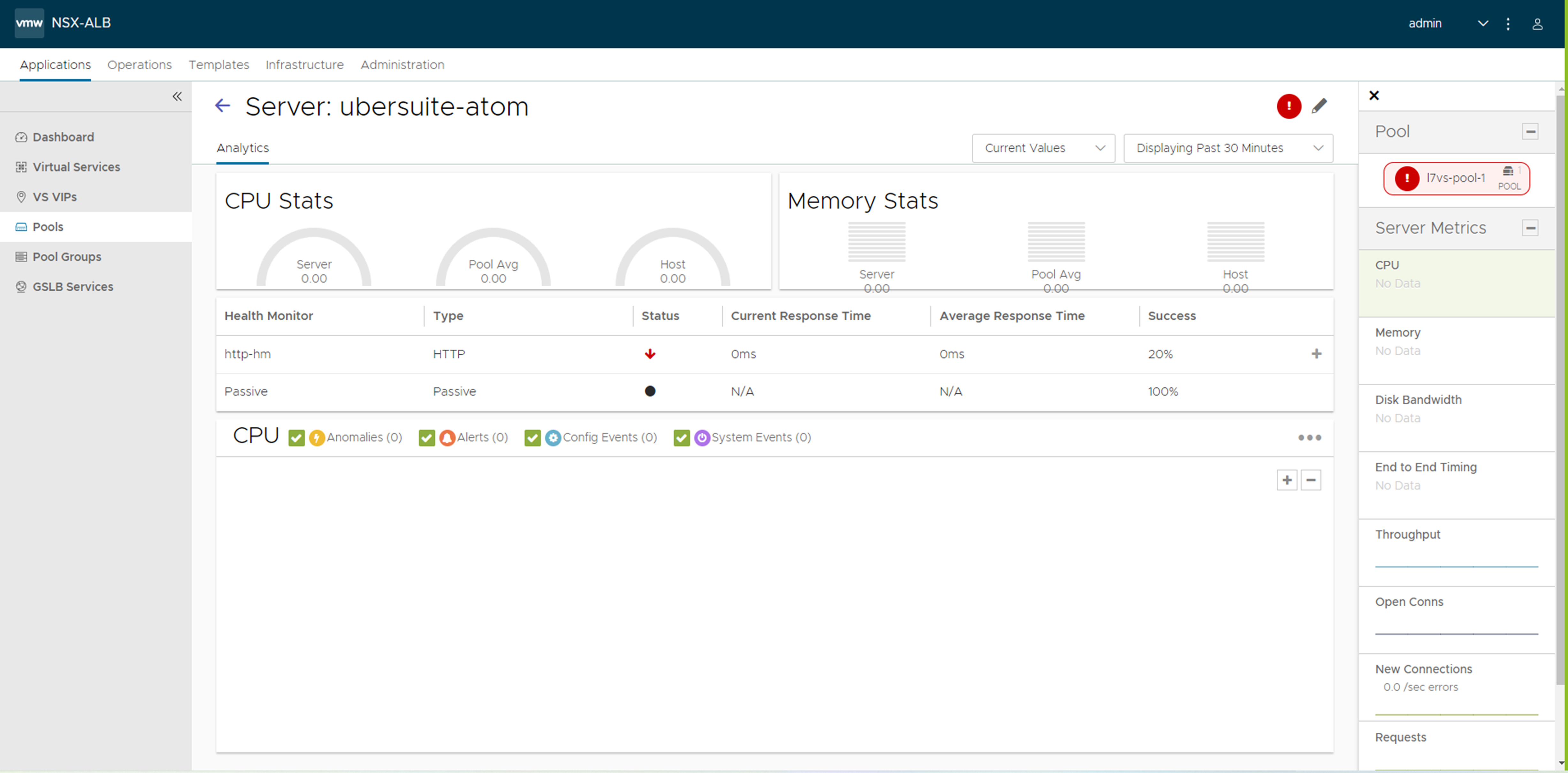
メイン チャートの [アラート] アイコンと [システム イベント オーバーレイ] アイコンを選択すると、選択した期間のサーバの UP および DOWN イベントが表示されます。このページには、失敗した健全性モニターのリストも表示されます。
サーバからの応答時間を、健全性モニターの構成済みの受信タイムアウト期間と比較します。障害がこれらのタイマーに起因する可能性がある場合は、次の手順を使用してタイマーを修正できます。
サーバを追加:速度低下の原因がバックエンド データベースにある場合は効果がありませんが、サーバが単にビジーまたは過負荷状態にある場合は、この方法が迅速で永続的な解決策となる可能性があります。
健全性モニターの受信タイムアウト期間の長さを増やす:タイムアウト値は 1 ~ 300 秒の範囲で指定できます。タイムアウト値は、常に健全性モニターの送信間隔よりも短くする必要があります。
必要なチェックの成功数を増やし、許可されるチェックの失敗数を減らします。これにより、サーバがすぐにローテーションに復帰しないようになるため、応答の遅延の原因となるプロセスの処理の時間を増やすことができます。
接続ランプアップを変更(最小接続のロード バランシング アルゴリズムを使用している場合):サーバを最初に起動したときは、短時間で大量の接続を受信する可能性があります。たとえば、1 台のサーバに 1 つの接続があり、残りのサーバに 100 の接続がある場合、最小接続アルゴリズムに従って、新しいサーバは後続の 99 の接続を取得します。これにより、サーバが簡単に過負荷状態になり、接続のフラッシュ クラウドを残りのサーバで処理する必要があるため、ドミノ効果が発生します。プールの構成の [詳細] タブで、接続ランプアップ機能を構成できます。接続ランプアップ機能により、新しいサーバに送信される新しい接続の割合が徐々に増加します。サーバのカスケード障害が発生している場合は、ランプアップ時間を増やすと解決できる場合があります。
サーバ当たりの最大接続数を設定:このオプションは、プール構成の [詳細] タブで構成できます。これにより、サーバが過負荷状態にならず、接続を最適な速度で処理できるようになります。
