









ロード バランシング アルゴリズムの選択により、使用可能なサーバ間で接続または HTTP 要求を分散する方法と優先順位が決まります。使用可能なアルゴリズムは次のとおりです。
コンシステント ハッシュ
コア アフィニティ
最速応答
最小サーバ
最小接続数
最小負荷
ラウンド ロビン
少ないタスク数
ロード バランシング アルゴリズムは、NSX Advanced Load Balancer ユーザー インターフェイスと NSX Advanced Load Balancer CLI を使用して変更されます。 内の [アルゴリズム] フィールドを使用して、ローカル サーバのロード バランシング アルゴリズムを選択します。プールの LB アルゴリズムの変更は、新しい接続または要求にのみ影響し、既存の接続には影響しません。使用可能なオプションは次のとおりです(アルファベット順)。
コンシステント ハッシュ
新しい接続は、[LB アルゴリズム] フィールドの下に表示されるフィールドで指定されるキー、または avi.pool.chash DataScript 関数を介してユーザーが提供するカスタム文字列で指定されるキーに基づくハッシュを使用して、サーバ間で分散されます。以下に、URI クエリ値を保持する例を示します。
hash = avi.http.get_query("r")
if hash then
avi.pool.select("Pool-Name")
avi.pool.chash(hash)
end
このアルゴリズムは本質的にロード バランシングとパーシステンスを組み合わせて、パーシステンス メソッドを追加する必要性を最小限に抑えます。このアルゴリズムは、動的コンテンツを扱う大量のキャッシュ サーバのロード バランシングに最適です。サーバを追加または削除しても、ハッシュ テーブルが完全に再計算されることはないため、「一貫性」は保たれます。たとえば、キャッシュ サーバの場合、すべてのキャッシュにすべてのコンテンツの再キャッシュを強制することはありません。プールに 9 台のサーバがある場合、10 台目のサーバを追加すると、既存のサーバはハッシュの結果に基づいて、ヒット数の約 9 分の 1 を新しく追加されたサーバに送信します。したがって、パーシステンスが引き続き貴重である場合があります。サーバのその他の接続は中断されません。使用可能なハッシュ キーは次のとおりです。
フィールド |
説明 |
|---|---|
[カスタム ヘッダー] |
[カスタム ヘッダー] フィールドで使用する HTTP ヘッダー([リファラー] など)を指定します。このフィールドでは大文字と小文字が区別されます。フィールドが空白の場合、またはヘッダーが存在しない場合、接続または要求がないとみなされ、サーバにハッシュされます。 |
[呼び出し ID] |
SIP ヘッダーの [呼び出し ID] フィールドを指定します。このオプションを設定すると、新しい呼び出し ID の SIP トランザクションはコンシステント ハッシュを使用してロード バランシングされますが、既存の呼び出し ID は以前に選択したサーバに保持されます。既存の呼び出し ID の状態は、アプリケーション プロファイルの「Transaction timeout」パラメータで定義されたアイドル タイムアウトの期間維持されます。既存の呼び出し ID の状態は、SIP トランザクションの基盤となる TCP/UDP 転送状態が同じである限り関連します。 |
[送信元 IP アドレス] |
クライアントの [送信元 IP アドレス]。 |
[送信元 IP アドレスおよびポート] |
クライアントの [送信元 IP アドレスおよびポート]。 |
[HTTP URI] |
これには、ホスト ヘッダーとパスが含まれます。たとえば、www.avinetworks.com/index.htm です。 |
カスタム文字列コンシステント ハッシュ アルゴリズムは、プール グループのメンバーであるプールでも使用できます。
プール グループによって同じプールが選択されている場合にのみ、同じサーバが選択されます。プール グループによって別のプールが選択されている場合、トラフィックは、対応するプールのロード バランシング アルゴリズムに応じて、新しく選択されたプール内のサーバにロード バランシングされます。
コア アフィニティ
各 CPU コアはサーバのサブセットを使用し、各サーバはコアのサブセットによって使用されます。これは基本的に、サーバとコア間の多対多のマッピングを提供します。これらのサブセットのサイズは、プール オブジェクト内の変数 lb_algorithm_core_nonaffinity によってパラメータ化されます。サイズを増やすと、すべてのサーバがすべてのコアで使用されるポイントまでマッピングが増加します。
コアにマッピングされたすべてのサーバが使用できない場合、コアは次の (wrap neutronund) コアにマッピングされるサーバを使用します。
最速応答
新しい接続は、現在新しい接続または要求に対して最も高速に応答しているサーバに送信されます。これは、最初のバイトまでの時間として測定されます。エンドツーエンドのタイミング チャートでは、これはサーバ RTT とアプリケーション応答時間の合計として反映されます。このオプションは、プールのサーバにさまざまな機能が含まれている場合や、一時的な接続を処理する場合に適しています。イメージを含むデータストアへの接続が失われるなど、問題のあるサーバは通常、HTTP 404 エラーで非常に迅速に応答します。これは、最も高速な応答アルゴリズムを使用してパッシブ健全性モニターも有効にする場合のベスト プラクティスです。パッシブ健全性モニターは、応答速度だけでなく、サーバの応答の品質も考慮して、このようなシナリオを認識して調整します。
イメージを含むデータストアへの接続が失われるなど、問題のあるサーバは通常、HTTP 404 エラーで非常に迅速に応答します。最速応答アルゴリズムを、このようなシナリオを認識して調整するパッシブ健全性モニターとともに使用します。
最小サーバ
すべてのサーバに対してすべての接続または要求を分散する代わりに、NSX Advanced Load Balancer は、現在のクライアント負荷を満たすために必要なサーバの最小数を決定します。余分なサーバはトラフィックを受信しなくなり、プロビジョニング解除されるか、一時的にパワーオフされる場合があります。このアルゴリズムは、負荷を調整し、応答待ち時間に変化があるサーバを監視することで、サーバのキャパシティを監視します。接続がプール内の最初のサーバに送信され、キャパシティがいっぱいであると判断されると、次の新しい接続はキャパシティに空きがある次のサーバに送信されます。このアルゴリズムは、仮想マシンにコストがかかるホステッド環境に適しています。
最小接続数
新しい接続は、現在実行中の同時接続数が最も少ないサーバに送信されます。これは、新しいプールを作成するときのデフォルトのアルゴリズムであり、汎用サーバおよびプロトコルに適しています。接続数がゼロの新しいサーバは、 の [接続増加時間] 設定を使用して、短時間でグレースフルに導入されます。この機能は、新しいサーバをプール内の他のサーバーの接続レベルまで徐々に引き上げます。
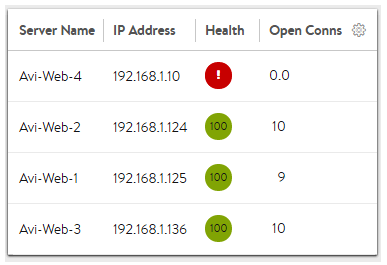
すべての新しい接続の拒否などの問題が発生しているサーバでは、同時接続数がゼロになり、すべての新しい接続を受信する資格が最も高くなる場合があります。NSX Advanced Load Balancer では、最小接続数アルゴリズムを、このようなシナリオを認識して調整するパッシブ健全性モニターとともに使用することをお勧めします。パッシブ モニターは、クライアントに返す応答に基づいて、サーバに送信される新しい接続の割合を削減します。
最小負荷
新しい接続は、サーバの接続数に関係なく、負荷が最も小さいサーバに送信されます。たとえば、200 kB の応答を必要とする HTTP 要求がサーバに送信され、1 KB の応答を生成する 2 番目の要求がサーバに送信された場合、このアルゴリズムは、以前の要求に基づいて、1 KB の応答を送信するサーバが 200 KB をストリーミングしているサーバよりも使用可能であると判断します。小さく速く処理できる要求が、非常に長い要求の後にキューに登録されないようにします。このアルゴリズムは HTTP 固有です。HTTP 以外のトラフィックの場合、アルゴリズムはデフォルトで [最小接続数] アルゴリズムに設定されます。
ラウンド ロビン
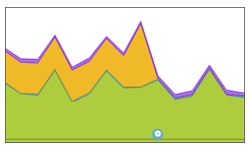
新しい接続は、プール内の次の適格なサーバに順番に送信されます。この静的アルゴリズムは基本的な負荷テストに最適ですが、個々のサーバの速度の違いや定期的な中断を考慮しないため、本番トラフィックには最適ではありません。低速サーバは、パフォーマンスのより高いサーバと同じ数の接続を受け取ります。
この図の例では、グラフのオレンジ色で示すように、サーバはエンドツーエンドのタイミング グラフでアプリケーションの非常に長い応答時間を引き起こしていました。静的ラウンドロビン アルゴリズムから動的 LB アルゴリズム(下部の青い構成イベント アイコン)に切り替えることで、NSX Advanced Load Balancer は接続をより高速にクライアントに応答していたサーバへ正常に転送し、アプリケーションの応答待ち時間を実質的に排除しました。
最小タスク
負荷は、サーバのフィードバックに応じて最適に分散されます。このアルゴリズムは、外部健全性モニターによって促進され、NSX Advanced Load Balancer CLI と REST API を使用して構成できます。最少タスク アルゴリズムは、NSX Advanced Load Balancer ユーザー インターフェイスから構成できません。
NSX Advanced Load Balancer CLI を使用した構成
configure pool foo lb_algorithm lb_algorithm_fewest_tasks save
外部健全性モニターは、データを <hm_name>.<pool_name>.<ip>.<port>.tasks ファイルに書き込むことにより、数値(1 ~ 100 など)をアルゴリズムにフィードバックできます。このファイルからの各出力は、アルゴリズムへのフィードバックとして使用されます。フィードバックとして提供される数値の範囲と健全性モニターの送信間隔を調整して、ロード バランシング アルゴリズムの動作を特定の環境に合わせて調整できます。
たとえば、2 台のバックエンド サーバ(s1 と s2)を持つプール p1 について考えてみます。健全性モニターが 10 秒(送信間隔)ごとにチェックを入れ、100(高負荷)と 10(低負荷)のフィードバックを返すとします。時刻 t1 では、s1 と s2 にそれぞれ 100 個のタスクと 10 個のタスクが設定されています。これで、200 個の要求を送信すると、最初の 90 個は、利用可能なユニットがさらに 90 個ある s2 に送信されます。次の 110 個は s1 と s2 に等しく送信されます。時刻 t2(= t1 + 10 秒)で、s1 と s2 は外部健全性モニターによって提供される新しいデータに補充されます。
外部健全性モニターで使用するスクリプトの例を次に示します。
#!/usr/bin/python
import sys
import httplib
import os
conn = httplib.HTTPConnection(sys.argv[1]+':'+sys.argv[2])
conn.request("GET", "/")
r1 = conn.getresponse()
print r1
if r1.status == 200:
print r1.status, r1.reason ## Any output on the screen indicates SUCCESS for health monitor
try:
fname = sys.argv[0] + '.' + os.environ['POOL'] + '.' + sys.argv[1] + '.' + sys.argv[2] + '.tasks'
f = open(fname, "w")
try:
f.write('230') # Write a string to a file - instead of 230 - find the data from the curl output and feed it.
finally:
f.close()
except IOError:
pass
show pool <foo> detail コマンドと show pool <foo> server detail コマンドを使用して、プール内のサーバに送信される接続数に関する詳細情報を表示できます。
重み付けされた比率
NSX Advanced Load Balancer には専用の重み付けされた比率アルゴリズムは含まれません。代わりに、比率を使用して重みが達成され、プール内の任意のサーバに適用することができます。比率は、任意のロード バランシング アルゴリズムとともに使用することもできます。比率を設定すると、各サーバは静的に調整されたトラフィックの比率を受信します。あるサーバの比率が 1(デフォルト)で、もう 1 台のサーバの比率が 4 の場合、4 に設定されたサーバは、4 倍の接続数を受信します。たとえば、最小接続数を使用する場合、1 台目のサーバの同時接続は 100 で、2 台目のサーバの同時接続数は 400 です。
