









このセクションでは、2 日間の運用シナリオでエンタープライズ オンプレミス デプロイを監視、バックアップ、およびアップグレードするために使用できるオプションについて説明します。
概要
- ソリューションの分離:VMware クラウド運用チームは、ホットフィックスとアップグレードを適用するためのアクセス権を持っていません。
- 変更管理の制限により、パッチ適用とアップグレードの頻度が制限されます。
- 適切でない、または不十分なソリューションの監視:この状況は、インフラストラクチャを管理できる人員が不足している場合に発生することがあり、機能上の問題、問題の解決の遅れ、および顧客の不満につながります。
このアプローチでは、管理、運用、パッチ適用を適切に行うために、人員と時間に大きな投資が必要になります。次の表は、システムをオンプレミスで管理する際に考慮する必要があるいくつかの要素の概要を示しています。
| システム | 説明 | VMware ホスト型の責任 | オンプレミスの責任 |
|---|---|---|---|
| SD-WAN オーケストレーション | アプリケーション QoS とリンク ステアリング ポリシー | はい | はい |
| アプリケーションおよび SD-WAN アプライアンスのセキュリティ ポリシー | はい | はい | |
| SD-WAN アプライアンスのプロビジョニングとトラブルシューティング | はい | はい | |
| SD-WAN のアラートとイベントの処理 | はい | はい | |
| リンクのパフォーマンスとキャパシティの監視 | はい | はい | |
| ハイパーバイザー | 監視/アラート | いいえ | はい |
| コンピューティングとメモリのリソース | いいえ | はい | |
| 仮想ネットワークとストレージ | いいえ | はい | |
| バックアップ | いいえ | はい | |
| レプリケーション | いいえ | はい | |
| インフラストラクチャ | CPU、メモリ、コンピューティング | いいえ | はい |
| スイッチとルーティング | いいえ | はい | |
| 監視と管理システム | いいえ | はい | |
| キャパシティ プランニング | いいえ | はい | |
| ソフトウェアのアップグレード/パッチ適用 | いいえ | はい | |
| アプリケーションとインフラストラクチャの問題のトラブルシューティング | いいえ | はい | |
| バックアップとインフラストラクチャ DR | バックアップ インフラストラクチャ | いいえ | はい |
| バックアップ レジームの定期的なテスト | いいえ | はい | |
| DR インフラストラクチャ | いいえ | はい | |
| DR テスト | いいえ | はい |
エンタープライズ オンプレミス デプロイの 2 日間の運用シナリオについては、それぞれ以下の 2 つのセクション(1 日目の運用と 2 日目の運用)で説明します。
1 日目の運用
セキュリティ アドバイザリへのサブスクライブ
VMware セキュリティ アドバイザリでは、VMware 製品で報告されたセキュリティの脆弱性についての修正を文書化しています。オンプレミス コンポーネントでアクションが必要な場合にアラートを受け取るには、以下のリンクにサブスクライブしてください。
https://www.vmware.com/security/advisories.html
SASE Orchestrator での cloud-init の無効化
data-source には、meta-data と user-data の 2 つのセクションが含まれています。meta-data にはインスタンス ID が含まれており、インスタンスの有効期間中は変更されません。一方、user-data は(meta-data のインスタンス ID に対する)最初の起動時に適用される設定です。
最初の起動後は、cloud-init ファイルを無効にして SASE Orchestrator の起動シーケンスを高速化することをお勧めします。cloud-init を無効にするには、次の手順を実行します。
./opt/vc/bin/cloud_init_ctl -d
「apt purge cloud-init」コマンドを使用して cloud-init ファイルを「削除」することはお勧めしません(この手順では、VMware SD-WAN Controller で問題が発生することはありません)。cloud-init ファイルを削除すると、いくつかの重要な SASE Orchestrator ツールとスクリプト(アップグレード スクリプトやバックアップ スクリプトなど)も消去されます。「purge」コマンドを使用した場合は、次のコマンドを使用してファイルをリストアできます。
- /opt/vcrepo/pool/main/v/vco-tools フォルダに移動します。
- フォルダから SASE Orchestrator ツール パッケージをインストールします:「sudo dpkg -i vco-tools_3.4.1-R341-20200423-GA-69c0f688bf.deb」。vco-tools パッケージ名は、リリースに応じて変更される場合があります。「ls vco-tools」コマンドを使用して、正しいファイル名を確認してください。
NTP タイムゾーン
SASE Orchestrator および Gateway のタイムゾーンは、「Etc/UTC」に設定する必要があります。
vcadmin@vco1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vco1-example:~$
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
NTP オフセット
NTP オフセットは 15 ミリ秒以下であることが期待されます。
vcadmin@vco1-example:~$ sudo ntpq -p
remote refid st t when poll reach delay offset
jitter
==============================================================================
*ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033
ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000
vcadmin@vco1-example:~$
sudo service ntp stop sudo ntpdate <server> sudo service ntp start
SASE Orchestrator のストレージ
SASE Orchestrator が最初にデプロイされると、「/」、「/store」、「/store2」、「/store3」の 4 つのパーティションが作成されます(バージョン 4.0 以降)。パーティションは、デフォルトのサイズで作成されます。設計に合わせてデフォルトのサイズを変更する場合のガイダンスについては、「SASE Orchestrator でのストレージの拡張」セクションの手順に従ってください。
追加のタスク
- システム プロパティを設定します。
- 最初のオペレータ プロファイルを設定します。
- オペレータ アカウントを設定します。
- SD-WAN Gateway を作成します。
- SASE Orchestrator を設定します。
- カスタマー アカウント/パートナー アカウントを作成します。
上記のリストに記載されている設定は、このドキュメントには記載されていません。これらは、VMware ドキュメントのデプロイ ガイドに記載されています。詳細な手順については、『VMware SASE Orchestrator のデプロイおよび監視ガイド』の「SASE Orchestrator のインストール」のセクションを参照してください。
2 日目の運用
SASE Orchestrator のバックアップ
このセクションでは、SASE Orchestrator データベースを定期的にバックアップし、アクティブ Orchestrator とスタンバイ Orchestrator の両方のオペレータ エラーまたは壊滅的な障害から回復するために利用可能なメカニズムについて説明します。
ディザスタ リカバリ機能 (DR) が優先されるリカバリ方法であることに注意してください。アクティブ Orchestrator 上のすべての設定が即座に複製されるため、この方法では目標復旧ポイントがほぼゼロになります。ディザスタ リカバリ機能の詳細については、次のセクションを参照してください。
組み込みスクリプトを使用したバックアップ
SASE Orchestrator には設定のバックアップ メカニズムが組み込まれており、設定を定期的にバックアップして、アクティブ Orchestrator とスタンバイ Orchestrator の両方のオペレータ エラーまたは壊滅的な障害から回復します。このメカニズムはスクリプト駆動型であり、/opt/vc/scripts/db_backup.sh にあります。
スクリプトは基本的に設定データとイベントのデータベース ダンプを取得し、一方でデータベース ダンプ プロセス中に大規模な監視テーブルの一部を除外します。スクリプトを実行すると、上記のスクリプトに入力されたローカル ディレクトリのパスにバックアップ ファイルが作成されます。
バックアップは 2 つの .gzs ファイルで構成されます。1 つはデータベース スキーマ定義を含み、もう 1 つは、定義を含まず、実際のデータを含んでいます。管理者は、バックアップ ディレクトリの場所にバックアップのための十分なディスク容量があることを確認する必要があります。
ベスト プラクティス
- リモートの場所をマウントし、バックアップ スクリプトを設定します。フローもバックアップする場合、リモートの場所には、「/store」と同じストレージが必要です。
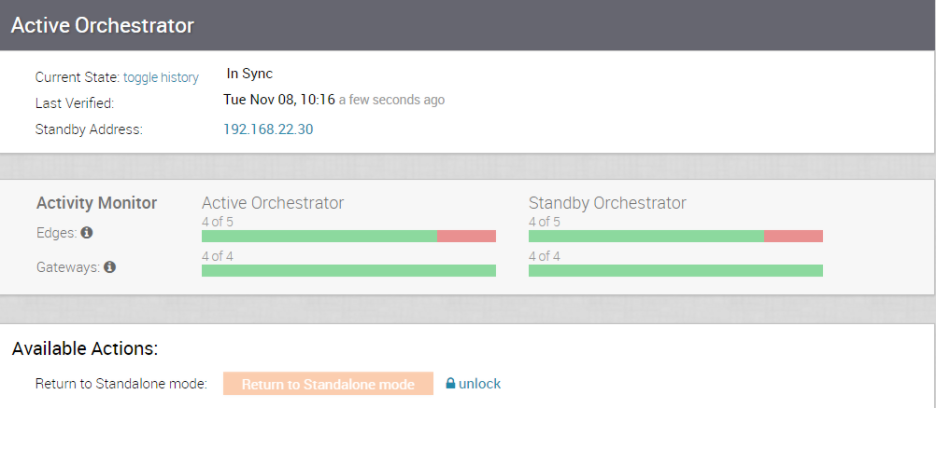
- バックアップ スクリプトを使用する前に、SASE Orchestrator のレプリケーション ページでディザスタ リカバリ (DR) のレプリケーション状態を確認します。これらは同期中で、エラーがない必要があります。
- さらに、MySQL クエリを実行し、レプリケーション ラグを確認します。
- SHOW SLAVE STATUS \G
- 上記のクエリの seconds_behind_master フィールドを確認します。ゼロであることが理想的ですが、10 未満であれば十分です。
- 大規模な SASE Orchestrator の場合は、バックアップ スクリプトの実行にスタンバイを使用することをお勧めします。どちらの SASE Orchestrator から生成してもバックアップに違いはありません。
注意事項- このスクリプトでは、設定のバックアップのみが実行されます。フロー統計情報またはイベントは含まれません。
- 設定をリストアするには、サポート/エンジニアリング チームのサポートが必要です。
- スクリプトの実行にはどのくらい時間がかかりますか。
バックアップの期間は、実際のカスタマー設定の規模によって異なります。監視テーブルはバックアップ操作から除外されるため、設定のバックアップ操作はすぐに完了することが予想されます。数千の SD-WAN Edge と多数の履歴イベントが含まれる大規模な SASE Orchestrator の場合は最大 1 時間かかることがありますが、小規模な SASE Orchestrator の場合は数分以内に完了します。
- 推奨されるバックアップ スクリプトの実行頻度はどれくらいですか。
バックアップ操作の頻度は、サイズおよび最初のバックアップを完了するのにかかる時間に応じて決定できます。バックアップ操作は、SASE Orchestrator リソースへの影響を減らすために、ピーク時以外の時間帯に実行するようにスケジュール設定する必要があります。
- ルート ファイルシステムにバックアップ用の十分な空き容量がない場合はどうなりますか。
他のマウントされたボリュームを使用してバックアップを保存することをお勧めします。バックアップにルート ファイルシステムを使用することはベスト プラクティスではありません。
- バックアップ操作が正常に完了したかどうかを確認するにはどうすればよいですか。
バックアップ操作の成功または失敗を判断するのには、スクリプト stdout および stderr を実行すれば十分です。スクリプトの起動が自動化されている場合、終了コードによってバックアップ操作の成功または失敗を判断できます。
- 設定はどのようにリカバリされますか。
現在 VMware では、設定データをリカバリする必要がある場合は VMware サポートにお問い合わせいただくようお願いしています。VMware サポートがカスタマー設定のリカバリをサポートします。設定がリストアされるまで、追加の設定変更は行わないようにしてください。
- このスクリプトを実行した場合、具体的にはどんな影響がありますか。
設定のバックアップによるパフォーマンスへの影響はほとんどありませんが、MySQL プロセスのリソース使用率が増加します。バックアップは、ピーク時以外の時間帯に実行することをお勧めします。
- バックアップ操作の実行中に、設定を変更することはできますか。
バックアップ操作の実行中でも安全に設定を変更できます。ただし、バックアップを最新の内容に保つため、バックアップの実行中は設定の操作を実行しないことをお勧めします。
- 設定を元の SASE Orchestrator でリストアすることはできますか。それとも新しい SASE Orchestrator が必要ですか。
はい。設定は同じ SASE Orchestrator でリストアすることができ、そうすることが理想です(使用可能であれば)。これにより、リストア操作が完了した後に、監視データが確実に使用されるようになります。元の SASE Orchestrator をリカバリできず、スタンバイ Orchestrator がダウンしている場合は、新しい SASE Orchestrator で設定をリストアします。この場合、監視データが失われます。
- 設定を新しい SASE Orchestrator にリストアする必要がある場合は、どのようなアクションを実行する必要がありますか。
手順は実際のデプロイによって異なるので、新しい SASE Orchestrator での推奨されるアクションのセットについては VMware サポートにお問い合わせください。
- SD-WAN Edge を新しくリストアされた SASE Orchestrator に再登録する必要がありますか。
いいえ。バックアップの一部として必要な情報がすべて保持されるため、SD-WAN Edge を新しい SASE Orchestrator に登録する必要はありません。
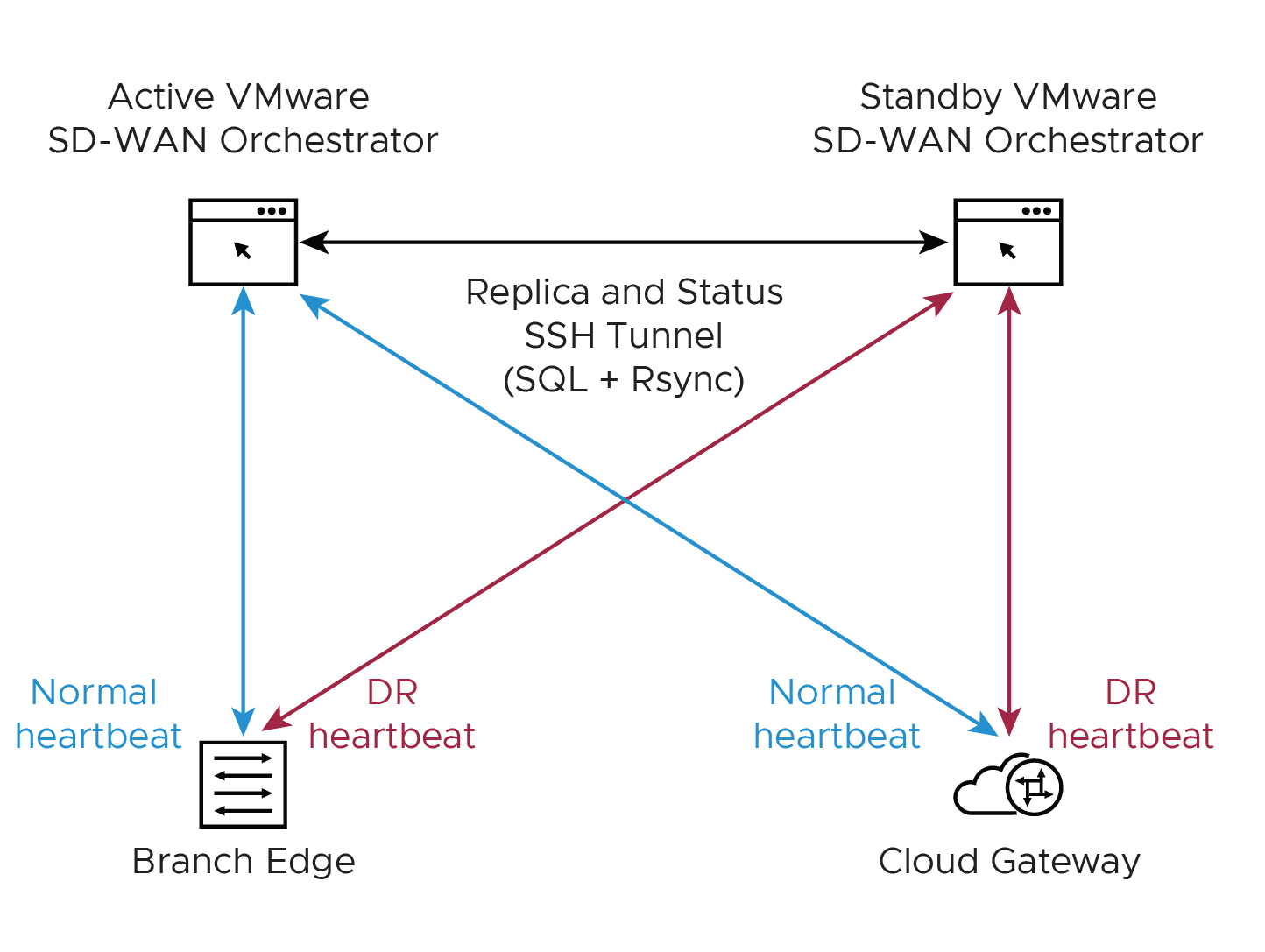
SASE Orchestrator のディザスタ リカバリ
状態
- スタンドアローン(DR が設定されていません)
- アクティブ(DR が設定済み、プライマリ SASE Orchestrator サーバとして動作)
- スタンバイ(DR が設定済み、非アクティブなレプリカ SASE Orchestrator サーバとして動作)
- ゾンビ(以前は DR が設定されていてアクティブであったが、現在はアクティブまたはスタンバイとして動作していない)
| フェーズ | SASE Orchestrator の A ロール | SASE Orchestrator の B ロール |
|---|---|---|
| 初期 | スタンドアローン | スタンドアローン |
| ペアリング | アクティブ | スタンバイ |
| フェイルオーバー | ゾンビ | スタンドアローン |
- SASE Orchestrator DR を地理的に離れたデータセンターに配置します。
- スタンバイ Orchestrator をアクティブとして昇格する前に、DR のレプリケーション状態が [In Sync (同期中)] であることを確認します。以前のアクティブ Orchestrator では、インベントリと設定を管理できなくなります。
- スタンバイが以前のアクティブ Orchestrator と通信できる場合、その Orchestrator にゾンビ状態に移るように指示します。[ゾンビ (Zombie)] 状態では、SASE Orchestrator からクライアント (SD-WAN Edge、SD-WAN Gateway、UI/API) に、自身がアクティブでなくなったこと、クライアントでは新たに昇格した SASE Orchestrator と通信する必要があることを通知します。
- 昇格されたスタンバイが以前のアクティブ Orchestrator と通信できない場合、オペレータは、可能であれば以前のアクティブを手動で降格する必要があります。
- 詳細な手順については、SASE Orchestrator の公式ドキュメント サイト (docs.vmware.com) の「SASE Orchestrator のディザスタ リカバリの設定」を参照してください。
SASE Orchestrator のアップグレード手順
- VMware サポートがアップグレードをサポートします。VMware サポートに問い合わせる前に、次の情報を収集します。
- SASE Orchestrator の現在のバージョンとターゲットのバージョンを入力します。例:現在のバージョン (3.4.2)、ターゲットのバージョン (3.4.3)。
注: 現在のバージョンについては、この情報は [ヘルプ (Help)] リンクをクリックして [バージョン情報 (About)] を選択すると、 SASE Orchestrator の右上隅に表示されます。
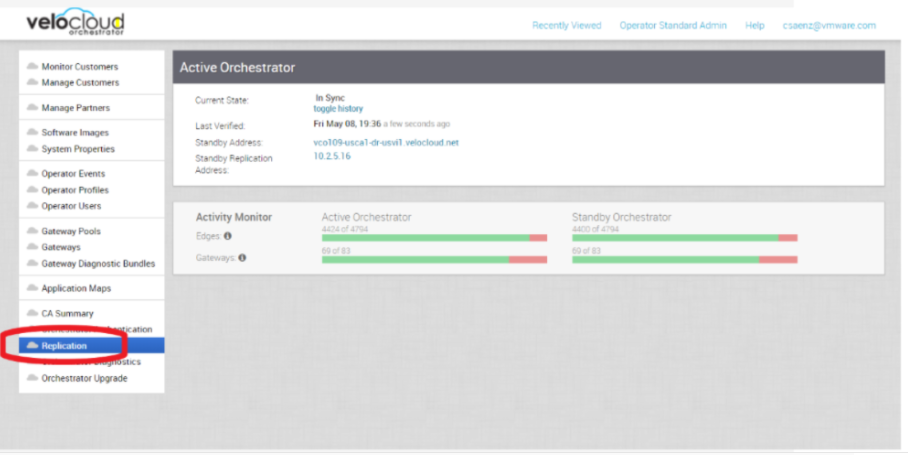
- 次の図のように、SASE Orchestrator のレプリケーション ダッシュボードのスクリーンショットを提供します。
- ハイパーバイザーのタイプとバージョン (vSphere 6.7)
- SASE Orchestrator からのコマンド(コマンドは root として実行する必要があります(例:「sudo <command>」または「sudo -i」))。
- LVM レイアウト
- pvdisplay -v
- vgdisplay -v
- lvdisplay -v
- df -h
- cat /etc/fstab
- メモリ情報
- free -m
- cat /proc/meminfo
- ps -ef
- top -b -n 2
- CPU 情報
- cat /proc/cpuinfo
- /var/log のコピー
- tar -czf /store/log-`date +%Y%M%S`.tar.gz --newer-mtime="36 hours ago" /var/log
- スタンバイ Orchestrator から:
- sudo mysql --defaults-extra-file=/etc/mysql/velocloud.cnf velocloud -e 'SHOW SLAVE STATUS \G'
- アクティブ Orchestrator から:
- sudo mysql --defaults-extra-file=/etc/mysql/velocloud.cnf velocloud -e 'SHOW MASTER STATUS \G'
- LVM レイアウト
- SASE Orchestrator の現在のバージョンとターゲットのバージョンを入力します。例:現在のバージョン (3.4.2)、ターゲットのバージョン (3.4.3)。
- SASE Orchestrator のアップグレードについては、上記の情報を用意し、VMware SD-WAN サポート (https://kb.vmware.com/s/article/53907) にお問い合わせください。
- カスタマーがアップグレード後に迅速なロールバック ソリューションを必要とする場合に備えて、次のセクションに ESXi スナップショットのガイドラインを示します。
ESXi スナップショット
SASE Orchestrator をアップグレードする前に ESXi スナップショット機能を使用すると、以前の SASE Orchestrator バージョンにすばやくロールバックできます。
ESXi スナップショットのベスト プラクティス
- データベースの不整合を回避するため、スナップショットを実行またはリストアする前に、スタンバイとアクティブの両方の Orchestrator をパワーオフする必要があります。
- データベースの不整合を回避するため、すべてのスナップショット関連のタスクはスタンバイおよびアクティブ Orchestrator で実行する必要があります。
- アップグレード プロセスが成功した場合は、スナップショットを統合することが不可欠です。スナップショット ファイルのサイズは、長期間保持されると増え続けます。これにより、スナップショットのストレージの場所が容量不足になり、システムのパフォーマンスに影響が及ぶ可能性があります。
- 誤ったアラームを回避するには、スナップショットを作成するときに SASE Orchestrator でアラートを無効にします。
- 1 つのスナップショットを 72 時間以上使用しないでください。
- スナップショットをバックアップとして使用することは推奨されません。
- 機能の検証は、ESXi 6.7 および SASE Orchestrator バージョン 3.4.4 で実行されました。
VMware スナップショットのベスト プラクティスについては、次のナレッジベースの記事を参照してください:https://kb.vmware.com/s/article/1025279
ESXi スナップショットの作成
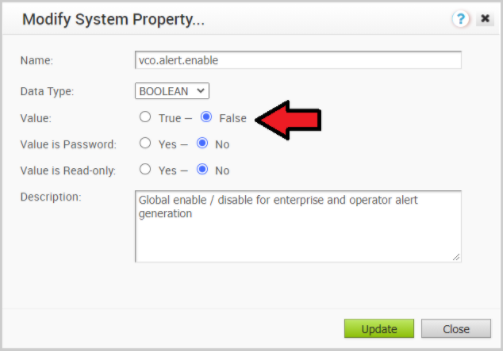
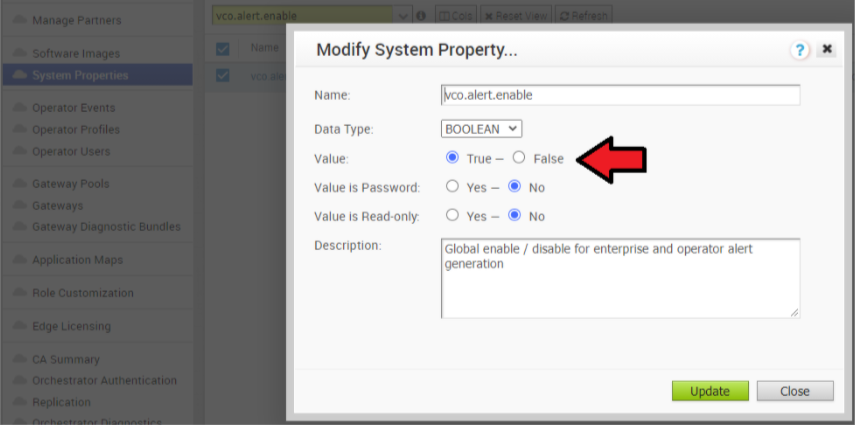
- アクティブ Orchestrator で、アラート、通知、およびシステム プロパティの監視を無効にします。所要時間は約 10 分です。
- オペレータ ポータルで、[システム プロパティ (System Properties)] をクリックします。次のシステム プロパティを false に変更します。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- オペレータ ポータルで、[システム プロパティ (System Properties)] をクリックします。次のシステム プロパティを false に変更します。
- スタンバイ Orchestrator で、アラート、通知、および監視のシステム プロパティを無効にします。
- 次のシステム プロパティを false に変更します。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- 次のシステム プロパティを false に変更します。
- アクティブ Orchestrator をパワーオフします。
[ESXi/vCenter Server] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [パワーオフ (Power Off)] の順に移動します。
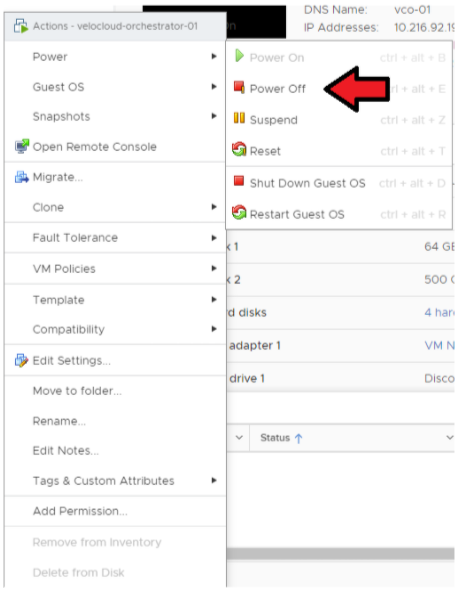
- スタンバイ Orchestrator をパワーオフします。
[[ESXi/vCenter Server] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [パワーオフ (Power Off)]] の順に移動します
- アクティブ Orchestrator のスナップショットを作成します。この手順を実行する前に、仮想マシンがパワーオフされていることを確認します。
[[ESXi] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [スナップショット (Snapshots)] → [スナップショットの作成 (Take Snapshot)]] の順に移動します。
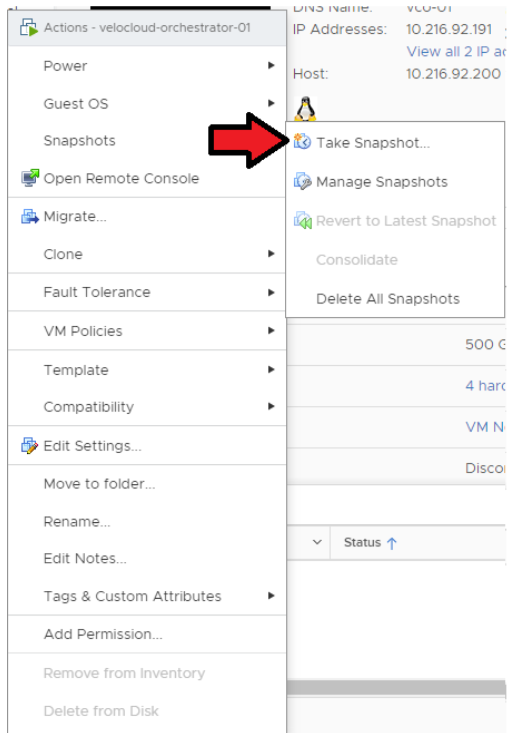
- スタンバイ Orchestrator のスナップショットを作成します。この手順を実行する前に、仮想マシンがパワーオフされていることを確認します。
[[ESXi] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [スナップショット (Snapshots)] → [スナップショットの作成 (Take Snapshot)]] の順に移動します。
ESXi スナップショットの統合
- アクティブおよびスタンバイ Orchestrator でアップグレードが正常に完了したことを確認したら、まずアクティブ Orchestrator からスナップショットを統合します。
[[ESXi] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [スナップショット (Snapshots)] → [スナップショット マネージャ (Snapshot Manager)] → [すべてを削除 (Delete All)]] の順に移動します。
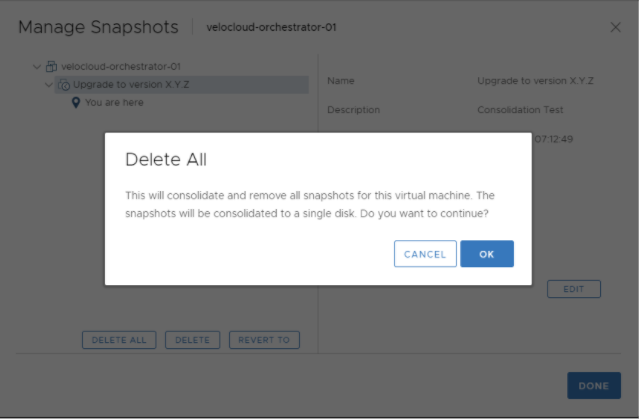
- スタンバイ Orchestrator のスナップショットを統合します。
[[ESXi] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [スナップショット (Snapshots)] → [スナップショット マネージャ (Snapshot Manager)] → [すべてを削除 (Delete All)]] の順に移動します。
- アクティブ Orchestrator とスタンバイ Orchestrator で、アラート、通知、監視の各システム プロパティを再度有効にします。
オペレータ ポータルで、 [システム プロパティ (System Properties)] をクリックします。次のシステム プロパティを true に変更します。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- すべてのスナップショットを削除するアクションが vSphere 6.x/7.x で動作しない場合は、スナップショットの統合を試みることができます。詳細については、vSphere 製品ドキュメントの「スナップショットの統合」セクションを参照してください。
ESXi スナップショットからのリストア
- アクティブ Orchestrator をパワーオフします。
[[ESXi/vCenter Server] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [パワーオフ (Power Off)]] の順に移動します。
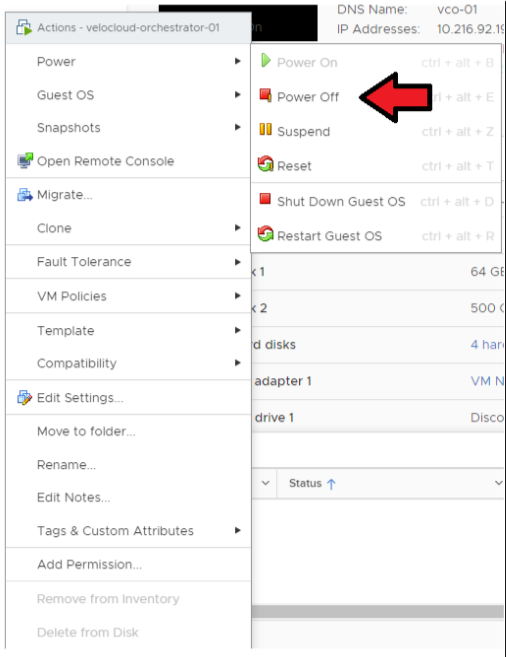
- スタンバイ Orchestrator をパワーオフします。
[[ESXi/vCenter Server] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [パワーオフ (Power Off)]] の順に移動します。
- アクティブ Orchestrator のスナップショットをリストアします。
[[ESXi] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [スナップショット (Snapshots)] → [スナップショットの管理 (Manage Snapshots)]] の順に移動します。
仮想マシンをリストアするスナップショットを選択し、[元に戻す (Revert to)] を選択します(下の図を参照)。
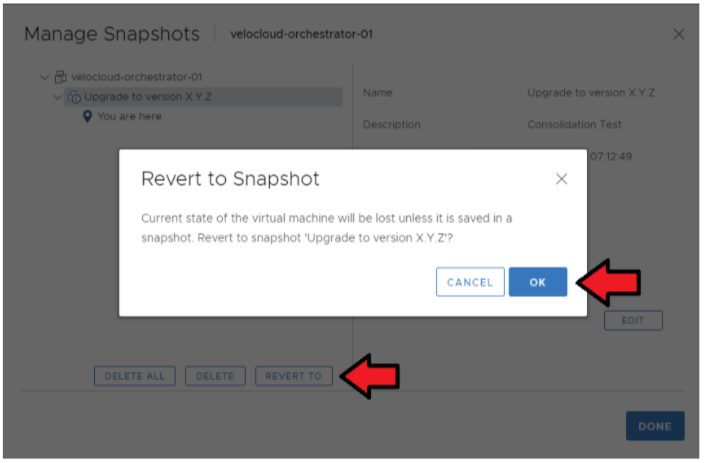
- スタンバイ Orchestrator のスナップショットをリストアします。
[[ESXi] → [Orchestrator 仮想マシン (Orchestrator VM)] → [アクション (Actions)] → [電源 (Power)] → [スナップショット (Snapshots)] → [スナップショットの管理 (Manage Snapshots)]] の順に移動します。
仮想マシンをリストアするスナップショットを選択し、[元に戻す (Revert to)] を選択します。
- アクティブ Orchestrator とスタンバイ Orchestrator で、アラート、通知、監視の各システム プロパティを再度有効にします。オペレータ ポータルで、[システム プロパティ (System Properties)] をクリックします。次のシステム プロパティを true に変更します。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
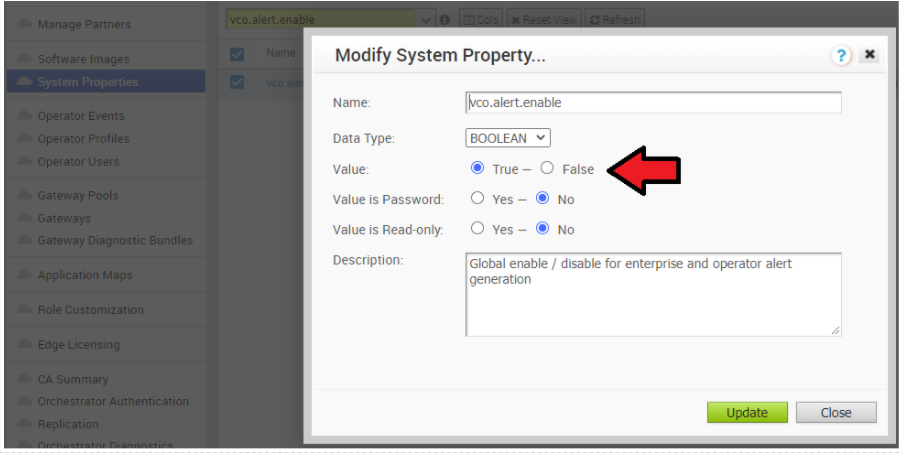
コントローラのマイナー ソフトウェア アップグレード(例:3.3.2 P3 から 3.4.4)
ソフトウェア アップグレード ファイルには、Gateway とシステムの更新が含まれています。「apt-get update && apt-get –y upgrade」を実行しないでください。
VMware SD-WAN Controller のアップグレードを続行する前に、SASE Orchestrator が同じバージョンまたはそれ以上のバージョンにアップグレードされていることを確認します。
- SD-WAN Controller の更新パッケージをダウンロードします。
- イメージを SD-WAN Controller ストレージにアップロードします(たとえば、SCP コマンドを使用します)。イメージをシステム上の /var/lib/velocloud/software_update/vcg_update.tar にコピーします。
- SD-WAN Controller コンソールに接続し、次のコマンドを実行します。
sudo /opt/vc/bin/vcg_software_update
root@VCG:/var/lib/velocloud/software_update# wget -O 'vcg_update.tar' <image location>
Resolving ftpsite.vmware.com (ftpsite.vmware.com)...
Connecting to ftpsite.vmware.com (ftpsite.vmware.com)| <ip address>|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/octet-stream]
Saving to: 'vcg_update.tar'
[ <=> ] 325,939,200 3.81MB/s in 82s
2020-05-23 21:59:27 (3.79 MB/s) - ‘vcg_update.tar’ saved [325939200]
root@VCG:/var/lib/velocloud/software_update# sudo /opt/vc/bin/vcg_software_update
=========== VCG upgrade: Sat May 23 22:08:15 UTC 2020
Upgrading gateway version 3.4.0-106-R340-20200218-GA-c57f8316dd to 3.4.1-39-R341-20200428-GA-44354-44451-596496a88a
Ign file: trusty InRelease
Ign file: trusty Release.gpg
Get: 1 file: trusty Release [2,668 B]
Ign file: trusty/main Translation-en_US
Ign file: trusty/main Translation-en
(...)
Writing extended state information...
Reading package lists...
Building dependency tree...
Reading state information...
Reading extended state information...
Initializing package states...
update-initramfs: Generating /boot/initrd.img-3.13.0-176-generic
Reboot is required. Reboot? (y/n) [y]:
コントローラのメジャー ソフトウェア アップグレード(例:3.3.2 または 3.4 から 4.0)
- LVM ベースの新しいシステム ディスク レイアウトにより、ボリューム管理の柔軟性を向上
- 新しいカーネル バージョン
- 新規およびアップグレードされた基本 OS パッケージ
- Center for Internet Security ベンチマークに基づくセキュリティ強化の向上
これらの変更の結果、アップグレード スクリプトを使用する標準のアップグレード手順は機能しません。特定のアップグレード手順を実行する必要があります。これについては、以下の製品マニュアルに記載されています。この手順では、3.3.2 または 3.4 の Gateway 仮想マシンを新しい 4.0 Gateway 仮想マシンに置き換えます。『VMware SD-WAN Partner Gateway の 3.3.2 または 3.4 から 4.0 へのアップグレードと移行』ドキュメントを参照してください。
このアップグレード手順には、SASE Orchestrator システム プロパティの設定が必要です。これは SASE Orchestrator のオペレータ アカウントのみが実行できます。システム プロパティの変更をリクエストするには、VMware サポート チームへのサポート チケットを作成してください。
監視
- SD-WAN Controller の監視
オペレータ ポータルで使用可能なコントローラの状態と使用量データを監視できます。
手順は次のとおりです。
- オペレータ ポータルで、[Gateway (Gateways)] をクリックします。
- [Gateway (Gateways)] ページに、使用可能なコントローラのリストが表示されます。
- Gateway へのリンクをクリックします。選択したコントローラの詳細が表示されます。
- [監視 (Monitor)] タブをクリックすると、選択したコントローラの使用量データが表示されます。
次の図に示すように、選択したコントローラの [監視 (Monitor)] タブには次の詳細が表示されます。
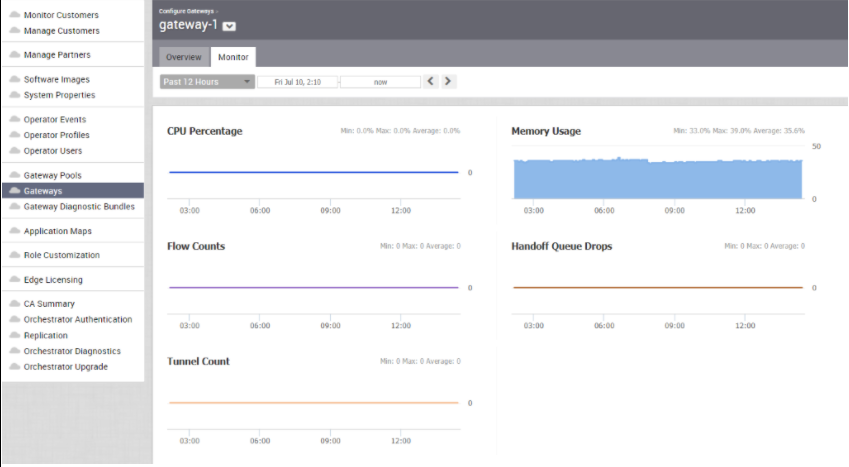
ページの上部で特定の期間を選択し、その期間のコントローラの詳細を表示できます。
このページには、選択した期間の次のパラメータの使用率の詳細が、最小値、最大値、平均値とともにグラフで表示されます。
| 使用率 | 説明 |
|---|---|
| CPU 使用率 (CPU Percentage) | CPU の使用率 |
| メモリ使用率 (Memory Usage) | メモリの使用率 |
| フロー数 (Flow Counts) | トラフィック フローの数 |
| ハンドオフ キューのドロップ数 (Handoff Queue Drops) | 待機中のハンドオフによってドロップされたパケット数 |
| トンネル数 (Tunnel Count ) | トンネル セッションの数 |
- SD-WAN Gateway Controller によって推奨される監視対象の値
次のリストに、監視する必要がある値とそのしきい値を示します。次のリストは出発点として提供されたものであり、完全ではありません。デプロイによっては、フロー、パケット ロスなどの追加コンポーネントの評価が必要になる場合があります。
警告しきい値に達した場合は、現在のデバイスのスケール設定を確認し、必要に応じてリソースを追加することをお勧めします。重大なアラームがトリガされた場合は、VMware サポート担当者に連絡してソリューションを確認し、必要なアドバイスを受け取ることが重要です。
表 4. 推奨される監視対象の値 サービス チェック サービス チェックの説明 警告しきい値 クリティカルしきい値 CPU 負荷 システムの負荷を確認します。 60 80 メモリ メモリ使用量バッファ、キャッシュ、および使用されているメモリを確認します。 70 80 トンネル 接続された SD-WAN Edge からのトンネル数。 最大スケールの 60% 最大スケールの 80% 注:すべてのトンネルの突然の損失または異常に少ないトンネル数も懸念事項となります。
ハンドオフ ドロップ コントローラを通過するトラフィックにはビジーという性質があるため、ときどきドロップすることが予想されます。 特定のキューで一貫してドロップする場合は、キャパシティに問題がある可能性があります。 ディスク容量 現在のディスク使用率 40% 空き 20% 空き コントローラ NTP 時間オフセットを確認します。 5 秒のオフセット 10 秒のオフセット
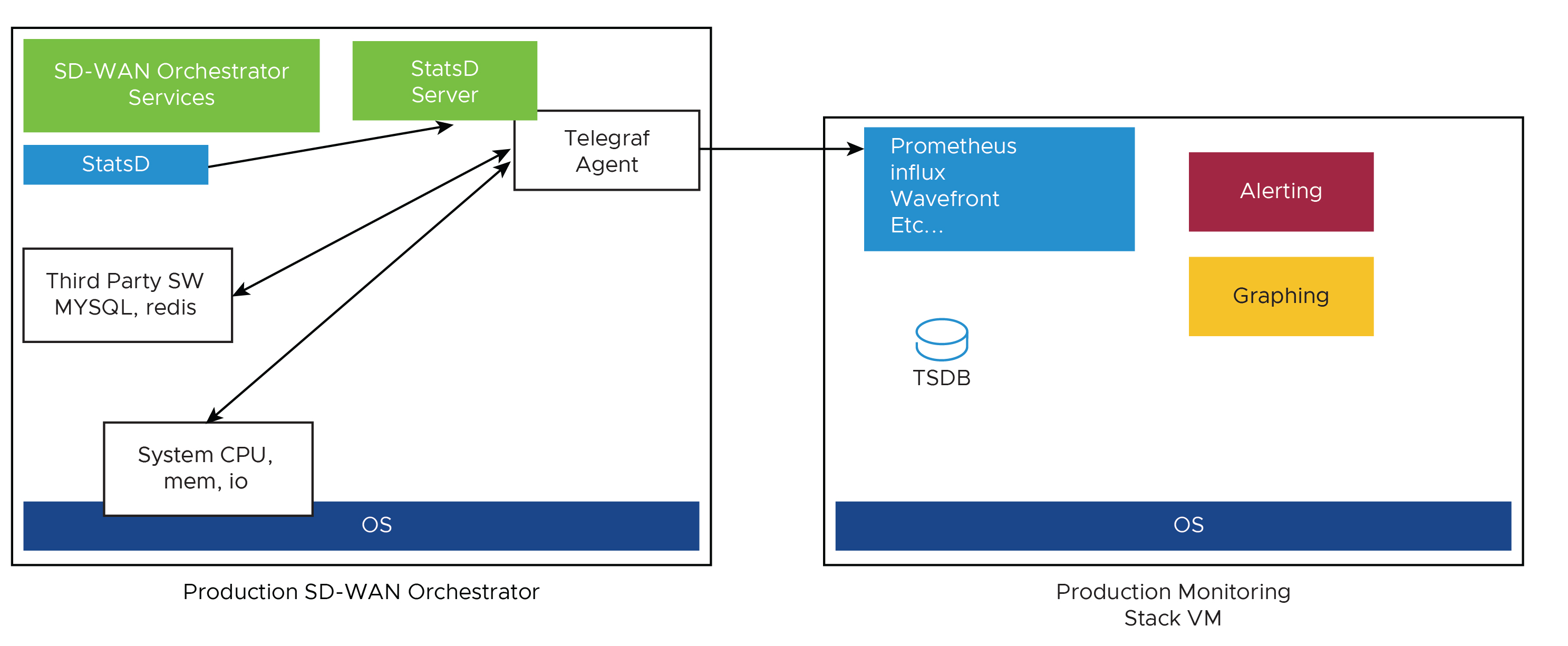
- SASE Orchestrator と監視スタックの統合
SASE Orchestrator には、外部メトリック コレクタと時系列データベースに接続できるシステム メトリックの監視スタックが組み込まれています。監視スタックを使用すると、SASE Orchestrator の健全性の状態とシステムの負荷を素早く確認できます。
-
- 監視スタックを有効にするには、Orchestrator で次のコマンドを実行します。
sudo /opt/vc/scripts/vco_observability_manager.sh enable
- 監視スタックの状態を確認するには、次のコマンドを実行します。
sudo /opt/vc/scripts/vco_observability_manager.sh status
- 監視スタックを無効にするには、次のコマンドを実行します。
sudo /opt/vc/scripts/vco_observability_manager.sh disable
- 監視スタックを有効にするには、Orchestrator で次のコマンドを実行します。
- メトリック コレクタ
Telegraf は、さまざまなシステム メトリックを収集するための豊富なプラグインを含んでおり、 SASE Orchestrator システム メトリック コレクタとして使用されます。デフォルトでは、次のメトリックが有効になっています。
表 5. メトリック コレクタ メトリック名 説明 サポートされるバージョン inputs.cpu CPU 使用率に関するメトリック。 3.4/4.0 inputs.mem メモリ使用量に関するメトリック。 3.4/4.0 inputs.net ネットワーク インターフェイスに関するメトリック。 4.0 inputs.system システムの負荷と連続稼動時間に関するメトリック。 4.0 inputs.processes 状態でグループ化されたプロセスの数 4.0 inputs.disk ディスク使用量に関するメトリック。 4.0 inputs.diskio デバイス別のディスク I/O に関するメトリック。 4.0 inputs.procstat 特定のプロセスの CPU およびメモリの使用量。 4.0 inputs.nginx Nginx の基本状態情報 (ngx_http_stub_status_module)。 4.0 inputs.mysql MySQL サーバの統計情報データ。 3.4/4.0 inputs.redis 1 台または複数の Redis サーバのメトリック。 3.4/4.0 inputs.statds API およびシステム メトリック。 3.4/4.0(4.0 に追加のメトリックが含まれる) inputs.filecount 指定されたディレクトリ内のファイルの数と合計サイズ。 4.0 inputs.ntpq 標準の NTP クエリ メトリック。ntpq 実行ファイルが必要。 4.0 Inputs.x509_cert SSL 証明書のメトリック。 4.0 さらにメトリックを有効にしたり、有効なメトリックを無効にしたりするには、SASE Orchestrator で次のコマンドを実行して、Telegraf 設定ファイルを編集できます。
sudo vi /etc/telegraf/telegraf.d/system_metrics_input.conf
sudo systemctl restart telegraf
- 時系列データベース
時系列データベースを使用して、Telegraf によって収集されるシステム メトリックを保存できます。時系列データベース (TSDB) は、時系列データ用に最適化されたデータベースです。
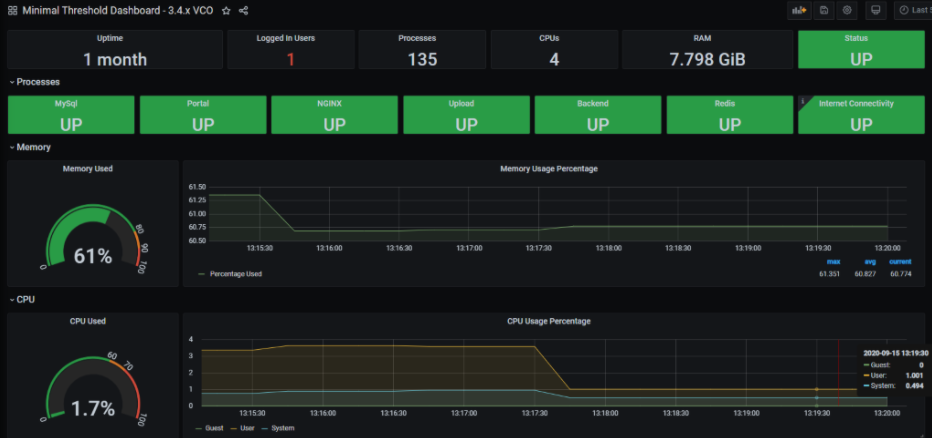
- ダッシュボードとアラート エージェント
ダッシュボードとアラート エージェントを使用すると、TSDB に格納されているデータをクエリ、可視化、アラート、および確認できます。次の図は、ソリューションを監視するために作成できる Telegraph(TSDB およびダッシュボード エンジン)を使用したダッシュボードの例を示します。
- 時系列データベースの設定
時系列データベースを設定するには、次の手順を実行します。
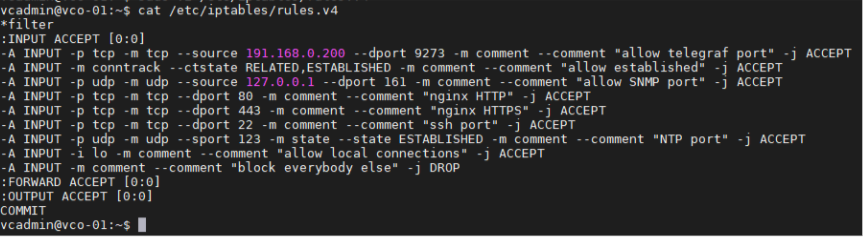
- iptables エントリを追加します。これにより、外部監視システムが Telegraf ポートにアクセスできるようになります。セキュリティ上の理由により、送信元 IP アドレスを指定する必要があります。
- 例:外部監視システムの IP アドレスは、「191.168.0.200」です。「-A INPUT -p tcp -m tcp --source 191.168.0.200 --dport 9273 -m comment --comment "allow telegraf port" -j ACCEPT"」を /etc/iptables/rules.v4 に追加します。
- iptables を再起動します。
sudo service iptables-persistent restart (Orchestrator 3.4.x)
sudo systemctl restart netfilter-persistent (Orchestrator 4.x)
- iptables エントリが追加されていることを確認します。
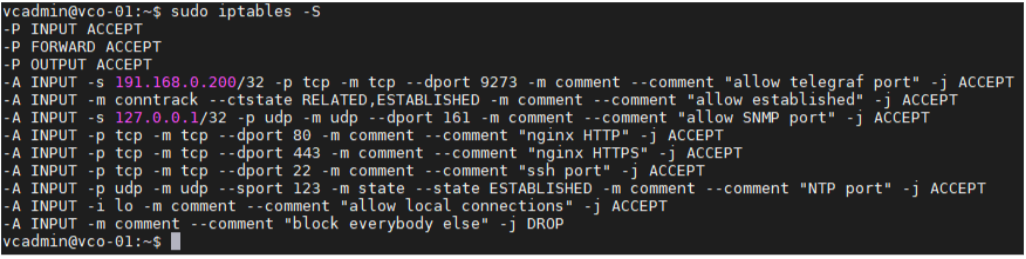
- 例:外部監視システムの IP アドレスは、「191.168.0.200」です。「-A INPUT -p tcp -m tcp --source 191.168.0.200 --dport 9273 -m comment --comment "allow telegraf port" -j ACCEPT"」を /etc/iptables/rules.v4 に追加します。
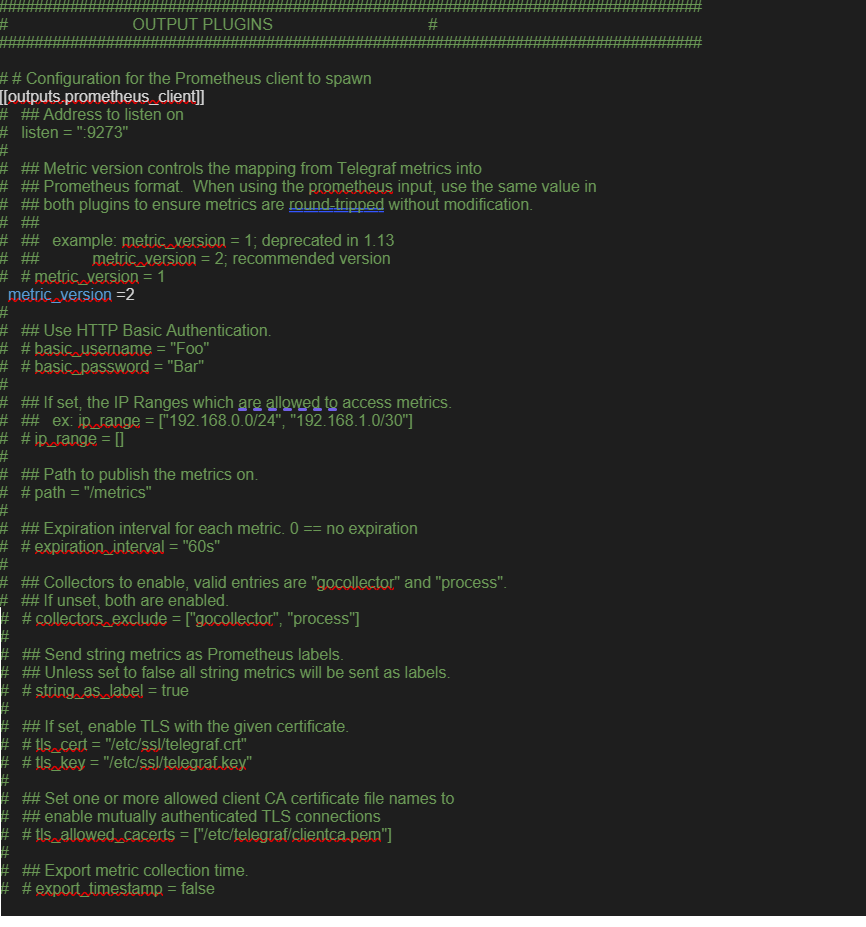
- Telegraf 設定に時系列データベースの詳細を追加します。出力設定ファイルを作成します。prometheus の例は次のとおりです。
/etc/telegraf/telegraf.d/prometheus_out.conf
- SASE Orchestrator で監視することが推奨される値
次のリストに、監視する必要がある値とそのしきい値を示します。次のリストは完全ではなく、出発点として提供されたものです。デプロイによっては、データベース トランザクションや自動バックアップなどの追加のコンポーネントの評価が必要になる場合があります。
警告しきい値に達した場合は、現在のデバイスのスケール設定を確認し、必要に応じてリソースを追加することをお勧めします。重大なアラームがトリガされた場合は、VMware サポート担当者に連絡してソリューションを確認し、必要なアドバイスを受け取ることが重要です。表 6. 監視する値とそのしきい値 サービス チェック サービス チェックの説明 警告しきい値 クリティカルしきい値 CPU 負荷 システムの負荷を確認します。Telegraf の入力プラグイン:inputs.cpu。 60 70 メモリ メモリ使用量バッファ、キャッシュ、および使用されているメモリを確認します。Telegraf の入力プラグイン:inputs.memory。 70 80 ディスク使用率 Orchestrator のパーティション別(「/」、「/store」、「/store2」、「/store3」)のディスク使用率(バージョン 4.0 以降)。Telegraf の入力プラグイン: inputs.disk(バージョン 4.0 以降)。 40% 空き 20% 空き MySQL サーバ MySQL 接続を確認します。Telegraf の入力プラグイン:inputs.mysql。 mysql.conf (/etc/mysql/my.cnf) で定義されている最大接続の 80% を超える SASE Orchestrator の時刻 時間オフセットを確認します。Telegraf の入力プラグイン:inputs.ntpq(バージョン 4.0 以降)。 5 秒のオフセット 10 秒のオフセット SASE Orchestrator の SSL 証明書 証明書の有効期限を確認します。Telegraf の入力プラグイン:inputs.x509_cert(バージョン 4.0 以降)。 60 日 30 日 SASE Orchestrator のインターネット(MPLS のみのトポロジには適用されません) インターネットへのアクセスを確認します。 応答時間 > 5 秒 応答時間 > 10 秒 SASE Orchestrator の HTTP localhost の HTTP が応答していることを確認します。 localhost が応答していない。 SASE Orchestrator の証明書の合計数 合計数を確認します。mysql クエリの例: SELECT count(id) FROM VELOCLOUD_EDGE_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()', 'SELECT count(id) FROM VELOCLOUD_GATEWAY_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()
CRL 証明書の合計数が 5000 を超える DR レプリケーション状態 スタンバイ Orchestrator が最新であることを確認します。 アクティブ Orchestrator に対する DR SASE Orchestrator Orchestrator の遅れが 1000 秒以下であることを確認します。 Seconds_Behind_Master:mysql コマンドから:show slave STATUS\G;
DR レプリケーション SD-WAN Edge Gateway の差分 SD-WAN Edge と SD-WAN Gateway が DR SASE Orchestrator と通信できることを確認します。 アクティブ Orchestrator とスタンバイ Orchestrator の値が異なる場合は、SD-WAN Edge と SD-WAN Gateway のタイムゾーンが異なる可能性があります。
アクティブ Orchestrator と通信している同じ数の SD-WAN Edge が、スタンバイ Orchestrator に到達できる必要があります。この値は、[レプリケーション (replication)] タブまたは API を使用して確認できます。
API のベスト プラクティス
- SASE Orchestrator ポータル
SASE Orchestrator ポータルを使用すると、ネットワーク管理者(またはネットワーク管理者の代わりとして実行されているスクリプトやアプリケーション)は、ネットワークとデバイスの設定を管理し、ネットワークとデバイスの現在または過去の状態をクエリできます。API クライアントは、JSON-RPC インターフェイスまたは REST ライクなインターフェイスを介してポータルと通信できます。どちらかのインターフェイスを使用して、このドキュメントで説明されているすべてのメソッドを呼び出すことができます。JSON-RPC クライアントまたは REST ライクなクライアントのどちらかにアクセスが排他的に制限されているポータル機能はありません。
どちらのインターフェイスも、HTTP POST 要求のみを受け入れます。どちらも、要求の本文(存在する場合)は JSON 形式で、RFC 2616 に従っていることを期待します。Content-Type 要求ヘッダーを使用する場合、クライアントは正式にアサートする可能性があります(例:Content-Type:application/json)。
VMware SD-WAN API の詳細については、以下を参照してください。
- API を使用するエンタープライズおよびサービス プロバイダのベスト プラクティス
API を使用する場合のベスト プラクティスは次のとおりです。
- 可能であれば、エンタープライズ固有の API 呼び出しよりも集約された API 呼び出しを優先します。たとえば、monitoring/getAggregateEdgeLinkMetrics の単一の呼び出しを使用して、すべての SD-WAN Edge のトランスポート統計情報を同時に取得できます。
- VMware はクライアントに対して、実行中の API 呼び出しの数を常に少なくしておく(2 ~ 4 個)ことを要求します。API 呼び出しを並列化する説得力のある理由があるとユーザーが感じている場合、VMware は、ユーザーが VMware サポートに問い合わせて代替ソリューションについて話し合うことを要求します。
- 通常、API で統計データをポーリングする場合、その頻度を 10 分間隔よりも短くすることはお勧めしません。新しい統計データは、5 分ごとに SASE Orchestrator に届きます。レポート/処理のジッターが原因で、5 分ごとにポーリングするクライアントは、統計情報が API 呼び出しの結果に反映されない「誤検知」のケースに遭遇する場合があります。ユーザーが要求間隔を 10 分以上にすると、最適な結果が得られる傾向があります。
- 同じ情報のクエリを 2 回実行することは避けてください。
- 次の API を実行するまでの間はスリープを使用します。
- 複雑なソフトウェア自動化の場合は、スクリプトを実行して、CPU/メモリへの影響を評価します。次に、必要に応じて調整します。
SASE Orchestrator の Syslog 設定
VMware SASE Orchestrator の Syslog 機能は、ポータル、アップロード、バックエンドの各 Orchestrator プロセスに対して個別に設定できます。
- ポータル:ポータル プロセスは、NGINX からの内部 HTTP サーバのダウンストリームとして実行されます。ポータル サービスでは、SASE Orchestrator Web インターフェイスまたは HTTP/SDK クライアントからの受信 API 要求を、まず同期的に処理します。これらの要求により、認証されたユーザーには、SASE Orchestrator で提供されるさまざまなサービスの設定、監視、管理を行うことが許可されます。
次のログには、SASE Orchestrator でユーザーが実行したすべてのアクションが含まれているため、AAA アクティビティに非常に役立ちます。
ログ ファイル:/var/log/portal/velocloud.log(すべての情報、警告、およびエラー ログを記録します)
- アップロード:アップロード プロセスは、NGINX からの内部 HTTP サーバのダウンストリームとして実行されます。アップロード サービスでは、SD-WAN Edge および SD-WAN Gateway からの受信要求を同期的または非同期的に処理します。これらの要求は主に、アクティベーション、ハートビート、フロー統計情報、リンク統計情報、および SD-WAN Edge と SD-WAN Gateway によって送信されるルーティング情報で構成されます。
ログ ファイル:/var/log/upload/velocloud.log(すべての情報、警告、およびエラー ログを記録します)
- バックエンド:主にスケジュール設定されたジョブまたはキューに入れられたジョブを実行するジョブ ランナー。スケジュール設定されたジョブは、クリーンアップ、ロールアップ、または状態更新のアクティビティで構成されます。キューに入れられたジョブは、リンクとフロー統計情報の処理で構成されます。
ログ ファイル:/var/log/backend/velocloud.log(すべての情報、警告、およびエラー ログを記録します)
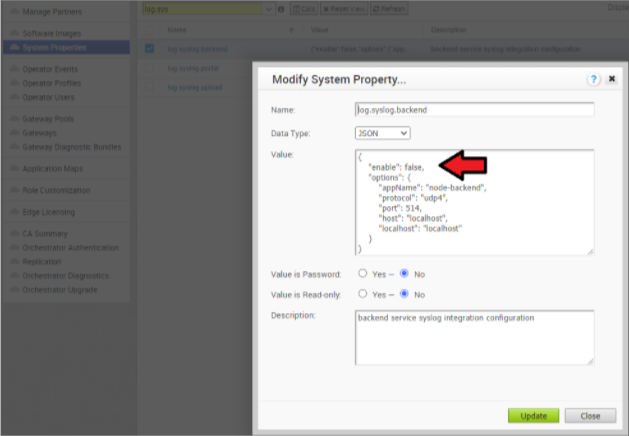
- SASE Orchestrator のシステム プロパティ log.syslog に移動します。<サーバ>(例:log.syslog.portal)に移動します。SASE Orchestrator の [システム プロパティ (System Properties)] に移動し、検索バーで「log.syslog」と入力します。
- 1 台以上のサーバについて、「"enable":false」の値を「true」に変更します。ホストの IP アドレスとポートを、実装環境に合わせて変更します。
SASE Orchestrator のストレージ容量の増加
SASE Orchestrator のストレージ容量を増やすための詳細な手順については、SASE Orchestrator
のドキュメント (https://docs.vmware.com/) の「SASE Orchestrator のインストール」および「ディスク サイズの拡張 (VMware)」を参照してください。
- ベスト プラクティス:
- スタンバイ Orchestrator に同じ LVM ディストリビューションが適用されていることを確実にします。
- 一度大きくしたボリュームのサイズを後で小さくすることはお勧めしません。代わりにシン プロビジョニングを使用します。
- 3.4 では、ディスク サイズを大きくすると、次の割合/値のディストリビューションを使用することができます。
- 「/」ボリューム:このボリュームは、オペレーティング システムに使用されます。本番環境の Orchestrator は通常 140 GB に設定されており、使用率は 40% から 60% です。
- /store および /store2:本番環境の Orchestrator に適用される割合は、/store で 85%、/store2 で 15% に近くなります。
- 次の表に示すガイドラインは、4.x リリース以降で使用されます。
インスタンス サイズ /store /store2 /store3 /var/log 小規模 (5,000 SD-WAN Edge) 2 TB 500 GB 8 TB 15 GB 中規模 (10,000 SD-WAN Edge) 2 TB 500 GB 12 TB 20 GB 大規模 (15,000 SD-WAN Edge) 2 TB 500 GB 16 TB 25 GB
SASE Orchestrator での証明書の管理
SASE Orchestrator では、組み込みの証明書サーバを使用して、すべての SD-WAN Edge と SD-WAN Controller の全体的な PKI ライフサイクルを管理します。X.509 証明書は、ネットワーク内のデバイスに対して発行されます。
CA を設定するための詳細な手順については、VMware SD-WAN の公式オペレータ ドキュメント (https://docs.vmware.com/jp/VMware-SD-WAN/index.html) の「SASE Orchestrator のインストール」および「SSL 証明書のインストール」を参照してください。
- SASE Orchestrator と SD-WAN Edge SD-WAN Controller 間の管理プレーン TLS 1.2 トンネル。
- SD-WAN Edge 間および SD-WAN Edge と SD-WAN Controller 間の制御およびデータ プレーン IKEv2/IPsec トンネル。
証明書失効リスト
vcadmin@vcg1-example:~$ openssl crl -in /etc/vc-public/vco-ca-crl.pem -text | grep 'Serial Number' | wc -l 14 vcadmin@vcg1-example:~
サポートへの問い合わせ
当社のカスタマー サポート組織は、VMware SD-WAN のカスタマーに 24 時間年中無休の世界クラスの技術支援および個別のガイダンスを提供します。
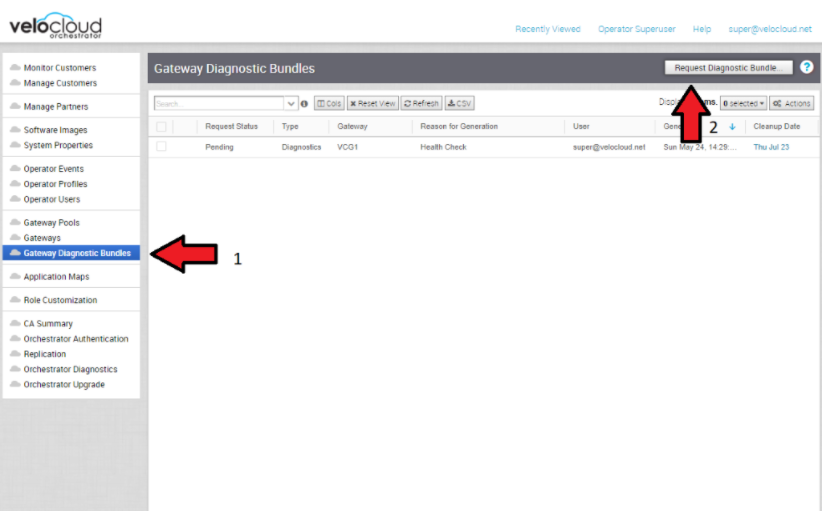
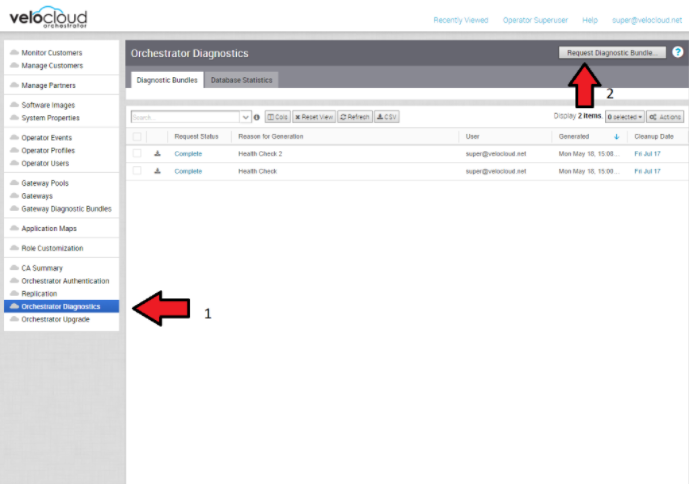
- 診断バンドル
インシデントを調査している間に、SASE Orchestrator と SD-WAN Controller の診断バンドルを作成できます。作成されたファイルは、VMware サポート チームが問題に関するイベントをさらに分析するのに役立ちます。
- サポートとのアクセス共有
場合によっては、SASE Orchestrator および SD-WAN Controller について VMware サポート担当者のサポートが必要になることがあります。
アクセス権を付与するには、次のような方法があります。- サポートとのリモート セッション:カスタマーは SSH ジャンプ サーバへのリモート操作を許可するか、またはサポート担当者の指示に従います。
- SASE Orchestrator でサポート チームのアカウントを作成する。これにより、サポート チームはカスタマーとのやり取りなしでログを収集できます。
- Bastion ホストを使用する:SSH の権限とキーを設定することにより、サポート エンジニアは、Bastion ホストを使用してオンプレミスの SASE Orchestrator と SD-WAN Controller にアクセスできるようになります。
問題のトリアージを支援するために VMware SD-WAN サポートに連絡する場合は、以下の表に記載されているデータを含めてください。
詳細については、次のリンクを参照してください:https://kb.vmware.com/s/article/53907
| 必須 | 推奨 |
|---|---|
| パートナーのケース番号 | 問題の開始/停止 |
| パートナーへの返信用メール アドレス/電話番号 | 影響を受けるフロー SRC/DST IP アドレス |
| SASE Orchestrator の URL | 影響を受けるフロー SRC/DST ポート |
| SASE Orchestrator のカスタマー名 | フロー パス(E2E、E2GW、直接) |
| カスタマーへの影響(高/中/低) | SD-WAN Gateway 名 |
| SD-WAN Edge 名 | SASE Orchestrator の PCAP へのリンク |
| SASE Orchestrator の診断バンドルへのリンク | |
| 問題についての短い記述 | |
| 分析および要求された支援 |
