









このセクションでは、SD-WAN Edge クラスタリング機能の全体的な仕組みについて詳しく説明します。
SD-WAN Edge クラスタリング機能を説明する重要な概念は次のとおりです。
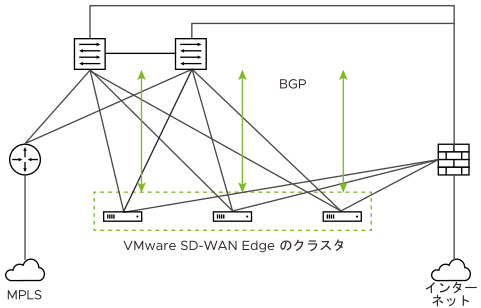
- Edge クラスタリングは、次のようにハブで使用できます。
- 個々の Edge がハブとして機能する場合よりも多くのトンネル容量をハブで提供できるようになります。
- リモート スポーク Edge を複数のハブに分散させて、発生する可能性のあるインシデントの影響を軽減します。
- クラスタ スコアは、システムの全体的な使用率を次のように計算したものです。
使用率を求めるための要素として、CPU 使用率、メモリ使用率、トンネル容量の 3 つが測定されます。
- 使用率の各測定値は、最大値 100% に占める割合として処理されます。
- トンネル容量は、指定されたハードウェア モデルまたは Virtual Edge 設定に基づきます。
- 3 つの使用率のすべての割合を平均して、整数単位のクラスタ スコア(1 ~ 100)が求められます。
- スループットは直接的には考慮されませんが、CPU 使用率とメモリ使用率によって、指定されたハブのスループットとフロー ボリュームが間接的に反映されます。
- たとえば、Edge 2000 の場合、次のようになります。
- CPU 使用率 = 20%
- メモリ使用率 = 30%
- 接続されているトンネル = (容量 6,000 のうちの)600 = 10%
- クラスタ スコア:(20 + 30 + 10)/3 = 20
- クラスタ スコアが 70 より大きい場合は「容量超過」とみなされます。
- 「論理 ID」は、VMware ネットワーク内の要素を一意に識別する 128 ビットの UUID です。
- たとえば、各 Edge は論理 ID で表され、各クラスタも論理 ID で表されます。
- ユーザーが Edge とクラスタ名を指定する限り、論理 ID は一意であることが保証され、要素の内部識別に使用されます。
- デフォルトでは、負荷はハブ間で均等に分散されます。したがって、クラスタに含まれるすべての Edge が同じモデルおよびキャパシティである必要があります。
Edge クラスタは VMware SD-WAN Gateway によってどのように追跡されるか。[]
ハブが VMware SD-WAN クラスタに追加されると、ハブは、割り当てられているすべての Gateway へのトンネルを分解して再構築し、ハブがクラスタに割り当てられたことを各 Gateway に示唆し、クラスタの論理 ID を提供します。
- 論理 ID
- 名前
- 自動再分配の有効になっているか
- クラスタのメンバーのハブ オブジェクトのリスト
クラスタ内の各ハブ オブジェクトについては、Gateway は次の情報を追跡します。
- 論理 ID
- 名前
- 次を含む一連の統計情報(割り当てられた各 Gateway にハブから送信される定期的なメッセージを通じて 30 秒ごとに更新されます)
- ハブの最新の CPU 使用率
- ハブの最新のメモリ使用率
- ハブの最新のトンネル数
- ハブの最新の BGP ルート数
- 上記の式に基づいて計算された最新のクラスタ スコア
Gateway でハブ Edge からのパケットが受信されない時間が 7 秒を超えると、ハブがハブ オブジェクトのリストから削除されます。
Edge はどのようにしてクラスタ内の特定のハブに割り当てられるか。
従来のハブとスポークのトポロジでは、SASE Orchestrator は、接続する必要があるハブの論理 ID を Edge に提供します。Edge は、ハブに接続するために使用する、そのハブの論理 ID の接続情報(IP アドレスとポート)を、割り当てられた Gateway にたずねます。
Edge の観点から見ると、この動作はクラスタに接続するときと同じです。Orchestrator が、Edge に対し、接続先のハブの論理 ID が個々のハブの論理 ID ではなくクラスタの論理 ID であることを通知します。Edge は、Gateway にハブ接続要求を送信するのと同じ手順に従い、接続情報が応答として返されることを予期します。
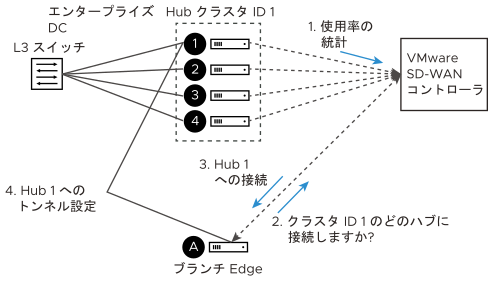
この段階で、基本的なハブの動作との相違点が 2 つあり、それらは次のとおりです。
- [相違点 1]:割り当てるハブを Gateway が選択する必要があります。
- [相違点 2]:相違点 1 のため、Edge が異なる Gateway から異なる割り当てを受け取ることがあります。
相違点 1 については、元々は、クラスタ スコアを使用して、クラスタ内で最も負荷が小さいハブを Edge に割り当てるという方法で処理されていました。しかし、そのような方法は論理上のものであり、実際には理想的なソリューションではないことがわかります。なぜならば、一般的な再割り当てイベントには数百または数千もの Edge が関与する場合があるうえ、クラスタ スコアは 30 秒ごとにしか更新されないからです。つまり、ハブ 1 のクラスタ スコアが 20 であり、ハブ 2 のクラスタ スコアが 21 である場合、30 秒間、すべての Edge でハブ 1 が選択され、その時点で、過負荷状態になり、さらなる再割り当てがトリガーされる可能性があるということです。
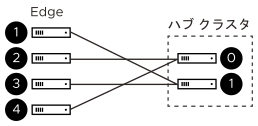
その代わりに、Gateway では、クラスタ スコアを無視して、最初に公正な算術分散を試行します。Orchestrator 上のセキュアなランダム数値ジェネレータによって生成される Edge の論理 ID によって、(十分な Edge があることを前提として)値が均等に分散されます。つまり、論理 ID を使用して公平な共有分散を計算できるということです。
- Edge の論理 ID をクラスタ内のハブの数で[剰余演算] = 割り当てられるハブ インデックス
- たとえば、次のようになります。
- 論理 ID が 1、2、3、4 で終わる 4 つの Edge があり、
- クラスタにハブが 2 つある場合、
- 1 % 2 = 1、2 % 2 = 0、3 % 2 = 1、4 % 2 = 0(注:「%」は剰余演算子を示すために使用)となり、
- Edge 2 および 4 にはハブ インデックス 0 が割り当てられ、
- Edge 1 および 3 にはハブ インデックス 1 が割り当てられます
この方がラウンドロビン方式の割り当てよりも一貫性が確保されます。というのも、Edge に、毎回、同じハブが割り当てられることが多くなるからです。また、その結果、割り当てとトラブルシューティングが予測されるようになります。
ハブが最大許容トンネル容量を超えた場合
Edge 割り当てロジックでは、使用可能なすべてのハブ間での Edge の均等分散が試行されます。ただし、ハブで(再起動などの)イベントが発生した後は、Edge の分散は均等ではなくなります。
そのようなイベントがハブで発生した(または、ネットワークに Edge が追加された)場合、クラスタが、個々のハブの許容トンネル容量の 70% を超えるレベルに達することがあります。そのようなことが発生し、他の 1 つ以上のハブのトンネル容量が 70% 未満の場合は、Orchestrator で再調整が有効になっているかどうかに関係なく、公平な共有再分散が自動的に実行されます。ほとんどの Edge は、論理 ID を使用した予測的かつ数学的な割り当てにより、既存の割り当てを保持します。また、フェイルオーバーや以前の使用率の再調整によって他のハブに割り当てられた Edge は、クラスタが均等分散状態に戻るように自動的に再調整されます。
ハブが最大許容クラスタ スコアを超えた場合
すぐに利用できるトンネルの割合(容量の直接的な尺度)とは異なり、クラスタ スコアは 30 秒ごとにしか更新されません。また、Edge の再割り当て後に調整されたクラスタ スコアがどのようになるかを Gateway が自動的に計算することはできません。必要な場合は、クラスタ設定で、Gateway が各ハブの Edge 負荷を動的に移動させるかどうかを示す自動再分配パラメータを指定することができます。
自動再分配がアクティベーション解除されている状態で、ハブがクラスタ スコア 70(ただし、トンネル容量の 70% ではありません)を超えた場合、アクションは実行されません。
自動再分配が有効になっている状態で、1 つ以上のハブがクラスタ スコア 70 を超えた場合、Gateway は、すべてのハブが 70 を下回るか、またはそれ以上再割り当てができなくなるまで、最新のクラスタ スコアが最も低いハブに 1 分ごとに 1 台の Edge を再割り当てします。
2 つの VMware SD-WAN Gateway によって異なるハブ割り当てが行われた場合
分散制御プレーンの特性として、各 Gateway がクラスタの割り当てを個別に決定します。Gateway は同じ数式を使用するため、ほとんどの場合、割り当てはすべての Edge で同じになります。ただし、クラスタ スコアに基づく再調整などの場合には、そのようなことは保証されません。
Edge がクラスタ内のハブに接続されていない場合、Edge は応答する任意の Gateway からの割り当てを受け入れます。そのようにして、一部の Gateway が停止し、その他の Gateway が稼動しているというシナリオで、Edge が未割り当てのままにならないようにします。
VMware SD-WAN Gateway が停止した場合
SD-WAN Gateway が停止した場合、停止したのが最も優先順位の高い Gateway であり、次に優先される Gateway が別の割り当てを提供していれば、Edge が再割り当てされます。たとえば、Super Gateway がハブ A を Edge に割り当て、代替 Super Gateway がハブ B を同じ Edge に割り当てていたとします。
Super Gateway が停止すると、代替 Super Gateway が接続情報に関して最も優先される Gateway になるので、ハブ B へのフェイルオーバーが開始されます。
Super Gateway が回復すると、Edge は、再び、その Gateway にハブの割り当てを要求します。以上のシナリオで Edge がハブ A にスイッチバックしないようにするため、ハブ割り当て要求には現在割り当てられているハブ(存在する場合)が含まれます。Gateway が割り当て要求を処理しているときに、その時点で Edge にクラスタ内のハブが割り当てられており、そのハブのクラスタ スコアが 70 未満であれば、Gateway は、割り当てロジックを経由せずに、既存の割り当てに一致するように自らのローカル割り当てを更新します。そうすることで、Super Gateway が回復時に、その時点で接続されているハブを確実に割り当てるようになり、割り当て済みの Edge で不必要なフェイルオーバーが発生するのを防げます。
クラスタ内のハブが動的ルートを失った場合
前述したように、ハブは、BGP 経由で 30 秒ごとに学習した動的ルートの数を SD-WAN Gateway に報告します。クラスタ内の 1 つのハブに対してのみルートが失われた場合(誤って取り消されたか、BGP ネイバーシップが失敗した場合)、SD-WAN Gateway は、正常なルーティング テーブルを持つクラスタ内の別のハブにスポーク Edge をフェイルオーバーします。
更新は 30 秒ごとに送信されるため、ルート数は、更新が SD-WAN Gateway に送信された時点に基づきます。SD-WAN GATEWAY の再バランシング ロジックは 60 秒ごとに行われます。つまり、ユーザーは、LAN 側の BGP ネイバーが完全に失われるというまれなイベントが発生した場合に、フェイルオーバーに 30 ~ 60秒かかることを予想できます。このようなイベントが発生した場合に、すべてのハブが再び Gateway を更新できるようにするために、再調整は 120 秒あたり最大 1 回に制限されます。つまり、2 回目の障害が連続的に発生した場合、ユーザーは、フェイルオーバーに 120 秒かかることを予想できます。
クラスタ ハブでルーティングを設定する方法
Gateway は、クラスタの任意のメンバー ハブに接続するようにスポークに指示できるため、ルーティング設定をすべてのハブでミラーリングする必要があります。たとえば、スポークが Hub の背後で BGP プレフィックス 192.168.2.1 に到達する必要がある場合、クラスタ内のすべての Hub は、完全に同じルート属性で 192.168.2.1 を広報する必要があります。
クラスタの展開では、BGP アップリンク コミュニティ タグを使用する必要があります。BGP ピアにルートを再配布するときに、アップリンク コミュニティ タグを設定するようにクラスタ ノードを設定します。
クラスタ内のハブに障害が発生した場合の動作について
SD-WAN Gateway は、スポーク Edge をフェイルオーバーする前に、トンネルが停止していると宣言されるまで待機します(7 秒)。つまり、SD-WAN Hub または関連するすべての WAN リンクに障害が発生した場合、ユーザーは、フェイルオーバーに 7 ~ 10 秒(RTT によって異なる)かかることを予想できます。
