









클라우드 관리자가 VMware Aria Automation에서 Private AI Automation Services를 설정한 경우 Automation Service Broker 카탈로그를 사용하여 AI 워크플로를 요청할 수 있습니다.
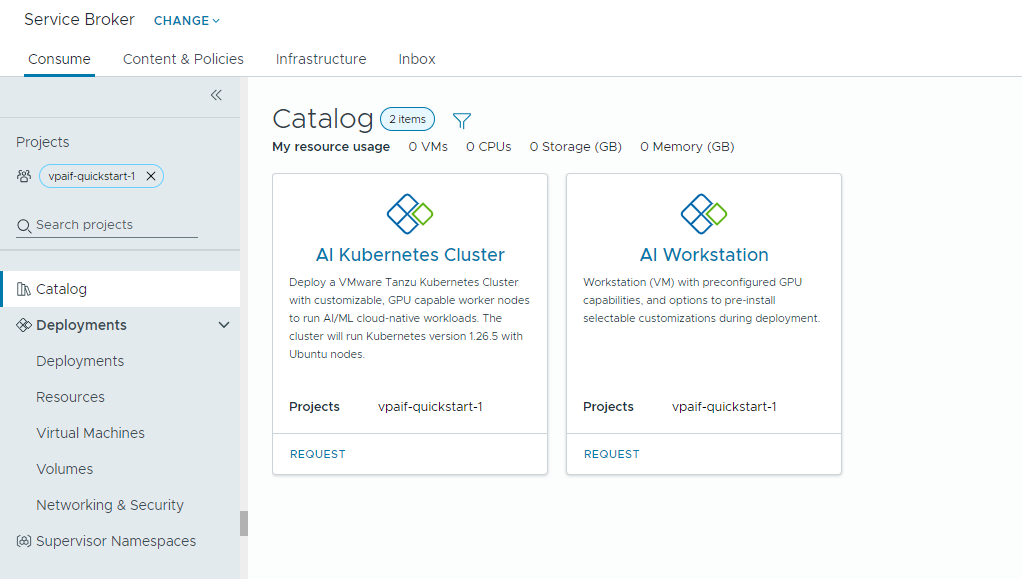
Private AI Automation Services는 Automation Service Broker에서 해당 사용 권한이 있는 사용자가 액세스하고 요청할 수 있는 두 가지 카탈로그 항목을 지원합니다.
- AI Workstation – NVIDIA의 원하는 vCPU, vGPU, 메모리 및 AI/ML 소프트웨어로 구성할 수 있는 GPU 지원 가상 시스템입니다.
- AI Kubernetes 클러스터 - NVIDIA GPU 연산자로 구성할 수 있는 GPU 지원 Tanzu Kubernetes 클러스터입니다.
시작하기 전에
- 프로젝트에 대해 Private AI Automation Services가 구성되어 있고 AI 카탈로그 항목을 요청할 수 있는 사용 권한이 있는지 확인합니다.
여기의 모든 값은 사용 사례 샘플입니다. 계정 값은 환경에 따라 다릅니다.
VI 워크로드 도메인에 딥 러닝 가상 시스템 배포
데이터 과학자는 셀프 서비스 Automation Service Broker 카탈로그에서 단일 GPU 소프트웨어 정의 개발 환경을 배포할 수 있습니다. 시스템 매개 변수를 사용하여 GPU 지원 가상 시스템을 사용자 지정하여 개발 요구 사항을 모델링하고, 교육 및 유추 요구 사항을 충족하도록 AI/ML 소프트웨어 구성을 지정하고, 포털 액세스 키를 통해 NVIDIA NGC 레지스트리에서 AI/ML 패키지를 지정할 수 있습니다.
프로시저
AI 지원 Tanzu Kubernetes 클러스터 배포
DevOps 엔지니어는 작업자 노드가 AI/ML 워크로드를 실행할 수 있는 GPU 지원 Tanzu Kubernetes 클러스터를 요청할 수 있습니다.
TKG 클러스터에는 TKG 클러스터 노드에서 NVIDIA GPU 하드웨어에 대한 적절한 NVIDIA 드라이버 설정을 담당하는 Kubernetes 연산자인 NVIDIA GPU 연산자가 포함되어 있습니다. 배포된 클러스터는 추가적인 GPU 관련 설정 없이도 AI/ML 워크로드에 바로 사용할 수 있습니다.
프로시저
- AI Kubernetes 클러스터 카드를 찾아 요청을 클릭합니다.
- 프로젝트를 선택합니다.
- 배포의 이름과 설명을 입력합니다.
- 제어 창 노드 수를 선택합니다.
설정 샘플 값 노드 수 1 VM 클래스 cpu-only-medium - CPU 8개 및 메모리 16GB 클래스 선택은 가상 시스템 내에서 사용할 수 있는 리소스를 정의합니다.
- 작업 노드 수를 선택합니다.
설정 설명 노드 수 3 VM 클래스 a100-medium - vGPU 4개(64GB), CPU 16개 및 메모리 32GB - 제출을 클릭합니다.
결과
배포에는 감독자 네임스페이스, 3개의 작업 노드가 있는 TKG 클러스터, TKG 클러스터 내부의 여러 리소스, GPU 연산자 애플리케이션을 배포하는 Carvel 애플리케이션이 포함됩니다.
개인 AI 배포 모니터링
[배포] 페이지를 사용하여 배포 및 연결된 리소스를 관리하고, 배포를 변경하고, 실패한 배포 문제를 해결하고, 리소스를 변경하고, 사용되지 않는 배포를 삭제할 수 있습니다.
배포를 관리하려면 를 선택합니다.
자세한 내용은 내 Automation Service Broker 배포를 관리하는 방법 항목을 참조하십시오.
