









VMware Integrated OpenStack CLI 상태 점검 지침서는 보고된 문제를 해결하기 위한 viocli check health 사례 및 절차를 설명합니다.
viocli check health에서 보고된 문제에 대해 다음 솔루션을 실행할 수 있습니다.
노드 준비 안 됨
- 노드 상태를 가져오려면
osctl get node명령을 실행합니다.osctl get node NAME STATUS ROLES AGE VERSION controller-dqpzc8r69w Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-lqb7xjgm9r Ready openstack-control-plane 17d v1.17.2+vmware.1 controller-mvn5nmdrsp Ready openstack-control-plane 17d v1.17.2+vmware.1 vxlan-vm-111-161.vio-mgmt.eng.vmware.com Ready master 17d v1.17.2+vmware.1
- 다음 명령을 사용하여
not ready node에서 kubelet 서비스를 다시 시작합니다.viosshcmd ${not_ready_node} 'sudo systemctl restart kubelet' - 이 문제의 상태를 다시 확인하려면
viocli check health -n kubernetes를 실행합니다.
IP 주소가 중복된 노드
IP 주소가 중복된 노드에 대한 자세한 내용은 KB 82608 항목을 참조하십시오.
이 문제의 상태를 다시 확인하려면 viocli check health -n kubernetes를 실행합니다.
비정상 노드
osctl describe node <node>를 실행하여 노드의 상태를 가져옵니다.Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Sat, 05 Jun 2021 10:47:53 +0000 Sat, 05 Jun 2021 10:47:53 +0000 CalicoIsUp Calico is running on this node MemoryPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:29 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Mon, 07 Jun 2021 01:21:55 +0000 Mon, 07 Jun 2021 00:57:32 +0000 KubeletReady kubelet is posting ready status
NetworkUnavailable,MemoryPressure,DiskPressure또는PIDPressure상태가 true이면 Kubernetes 노드는 비정상 상태입니다. 따라서 비정상 노드의 시스템 상태 및 리소스 사용량을 확인해야 합니다.- 이 문제의 상태를 다시 확인하려면
viocli check health -n kubernetes를 실행합니다.
디스크 사용량이 많은 노드
- 높은 디스크 사용량이 보고되는 노드에 로그인합니다.
#viossh ${node} df -h로 디스크 사용량을 확인합니다.- 노드에서 사용되지 않는 파일을 제거합니다.
- 이 문제의 상태를 다시 확인하려면
viocli check health -n kubernetes를 실행합니다.
Evicted 상태가 되면 VMware 지원팀에 문의하여 복구하십시오.
- inode 사용량이 많은 노드에 로그인합니다.
#viossh ${node} df -i /를 사용하여 inode 사용을 확인합니다.- 노드에서 사용되지 않는 파일을 제거합니다.
- 이 문제의 상태를 다시 확인하려면
viocli check health -n kubernetes를 실행합니다.
스냅샷이 있는 노드
- vCenter에 로그인하고 VMware Integrated OpenStack 컨트롤러 노드에 대해 생성된 스냅샷을 제거합니다.
- fail to connect to vCenter 오류가 보고되면 VMware Integrated OpenStack에서 vCenter 연결 정보를 확인해야 합니다.
- 이 문제의 상태를 다시 확인하려면
viocli check health -n kubernetes를 실행합니다.
FQDN을 확인할 수 없음
- VMware Integrated OpenStack 관리 노드에서 다음 명령을 사용하여 DNS 확인을 확인합니다.
#viosshcmd ${node_name} -c "nslookup ${reported_host}" #toolbox -c "dig $host +noedns +tcp" - 실패하면 VMware Integrated OpenStack 노드 /etc/resolve.conf에서 구성된 DNS 서버를 확인합니다.
- 이 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
NTP가 노드에서 동기화되지 않음
NTP 노드에 대한 자세한 내용은 KB 78565에서 참조하십시오. 이 문제의 상태를 다시 확인하려면 viocli check health -n connectivity를 실행합니다.
LDAP에 연결할 수 없음
VMware Integrated OpenStack 노드에서 지정된 LDAP 서버로의 연결을 확인하고 VMware Integrated OpenStack의 LDAP(사용자, 자격 증명) 설정이 올바른지 확인합니다. 이 문제의 상태를 다시 확인하려면 viocli check health -n connectivity를 실행합니다.
vCenter에 연결할 수 없음
vCenter에 연결할 수 없는 경우 VMware Integrated OpenStack 노드에서 지정된 vCenter로의 연결을 확인하고 VMware Integrated OpenStack의 vCenter 설정(사용자, 자격 증명)이 올바른지 확인합니다. 이 문제의 상태를 다시 확인하려면 viocli check health -n connectivity를 실행합니다.
NSX에 연결할 수 없음
NSX에 연결할 수 없는 경우 VMware Integrated OpenStack 노드에서 지정된 NSX 서버로의 연결을 확인하고 NSX 설정(사용자, 자격 증명)이 올바른지 확인합니다. 이 문제의 상태를 다시 확인하려면 viocli check health -n connectivity를 실행합니다.
- VMware Integrated OpenStack을 vRealize Log Insight와 통합 문서에 나열된 모든 사전 요구 사항이 준비되어 있어야 합니다.
- 이 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
- DNS 서버가 VMware Integrated OpenStack API 액세스 네트워크와 통신할 수 있는지 확인합니다.
- Designate 구성 요소를 사용하도록 설정 문서에 나열된 모든 사전 요구 사항이 준비되어 있어야 합니다.
- 이 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
rabbitmq 노드의 네트워크 파티션이 잘못됨
rabbitmq노드를 강제로 다시 생성하려면 VMware Integrated OpenStack 관리 노드에서 실행합니다.#osctl delete pod ${reported_rabbitmq_node}- 이 문제의 상태를 다시 확인하려면
viocli heath check -n rabbitmq를 실행합니다.
WSREP 클러스터 문제
viocli get deployment의 배포가 실행 중인 상태이면 VIO 지원팀에 문의하십시오. 그렇지 않은 경우 아래 지침을 따르십시오.
- VMware Integrated OpenStack Manager 노드에서 다음 명령을 실행합니다.
#kubectl -n openstack exec -ti mariadb-server-0 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-1 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;" #kubectl -n openstack exec -ti mariadb-server-2 -- mysql --defaults-file=/etc/mysql/admin_user.cnf --connect-timeout=5 --host=localhost -B -N -e "show status;"
mariadb-server-x의 출력wsrep_cluster_size가 3이 아닌 경우 다음을 사용하여mariadb노드를 다시 생성합니다.#kubectl -n openstack delete pod mariadb-server-x
- 3개 노드 사이에
wsrep_last_commited에 큰 차이가 있으면wsrep_last_committed를 사용하여mariadb노드 또는 더 작은 수의 노드를 다시 시작합니다.#kubectl -n openstack delete pod mariadb-server-x
- 이 문제의 상태를 다시 확인하려면
viocli check health -n mariadb를 실행합니다.
OpenStack 데이터베이스의 큰 테이블
nova.instancesKB 83768을 참조하십시오.
glance.imagesGlance 데이터베이스에서 일시 삭제된 레코드를 자동으로 제거하기 위해 기본적으로 사용하도록 설정된 cron 작업이 있습니다.
db 제거 cron 작업이 사용되도록 설정되어 있고 제대로 실행 중인지 확인하십시오.
viocli update glance jobs: db_purge: age_in_days: 60 max_rows: 1000 db_purge_images: age_in_days: 60 max_rows: 1000 manifests: cron_job_db_purge: true cron_job_db_purge_images: truecron_job_db_purge는 'image' 테이블을 제외하고 Glance 테이블에 대해 db 제거를 사용하도록 설정하는 데 사용됩니다.cron_job_db_purge_images는 Glance 'image' 테이블에 대해 db 제거를 사용하도록 설정하는 데 사용됩니다.--age_in_days NUM은 삭제된 지 NUM일이 넘는 행만 제거합니다. 기본값은 30일입니다.--max_rows NUM은 각 테이블에서 최대 NUM개 행을 제거합니다. 기본값은 100입니다.cinder.volumes및cinder.volume_attachmentCinder 데이터베이스 지우기 수동 단계
- Cinder db를 백업합니다.
osctl exec -ti mariadb-server-0 -- mysqldump --defaults-file=/etc/mysql/admin_user.cnf -R cinder > /tmp/cinder_backup.sql
- cinder-api-xxxxx 포드에 로그인합니다.
osctl exec -ti deploy/cinder-api bash
- Cinder 데이터베이스를 정리합니다.
cinder-manage db purge 60
참고:명령 사용법: cinder-manage db purge
age_in_days.위치 인수:
age_in_days, 삭제된 지 특정 기간(일)보다 오래된 행을 제거합니다.Cinder 데이터베이스에서 일시 삭제된 레코드를 더 많이 정리하려면
age_in_days를 조정해야 할 수 있습니다.
제어부에 레거시 네트워크 리소스가 너무 많음
솔루션은 VMware Integrated OpenStack 7.1 릴리스 정보에서 Neutron 테넌트 네트워크가 10k인 경우 Ceilometer를 사용하도록 설정하지 못함을 참조하십시오.
OpenStack Keystone이 제대로 작동하지 않음
- 도구 상자에서 관리자로 OpenStack에 로그인을 시도하고
openstack user list및openstack user show와 같은 명령을 실행해야 합니다. 로그인이 실패하면 Keystone 로그를 수집하여 오류 메시지 확인합니다. - keystone-api 포드 목록을 가져옵니다.
#osctl get pod | grep keystone-api
- 로그 수집:
#osctl logs keystone-api-xxxx -c keystone-api >keystone-api-xxxx.log
- 이 문제의 상태를 확인하려면
viocli check health -n keystone를 실행합니다.
Neutron 데이터베이스의 네트워크 ID가 비어있음
솔루션은 KB 76455 항목을 참조하십시오. 이 문제의 상태를 확인하려면 viocli check health -n neutron를 실행합니다.
Neutron의 vCenter 참조가 잘못됨
viocluster이름을 가져옵니다.osctl get viocluster
viocluster1이 반환되면 다음 단계를 계속합니다. 그렇지 않으면 잘못된 경보입니다. 영구적인 솔루션은 VMware 지원팀에 문의하십시오.vioclustervCenter 구성을 가져옵니다.# osctl get viocluster viocluster1 -oyaml
- Neutron 구성을 백업합니다.
osctl get neutron -oyaml > neutron-<time-now>.yml
- Neutron CR
cmd:osctl edit neutron neutron-xxx를 편집한 다음, 1단계에서 찾은 vCenter 참조를 대체하여 CR 규격을 변경합니다.spec: conf: plugins: nsx: dvs: dvs_name: vio-dvs host_ip: .VCenter:vcenter812:spec.hostname <---- change the vcenter instance to viocluster refered host_password: .VCenter:vcenter812:spec.password <---- same above host_username: .VCenter:vcenter812:spec.username <---- insecure: .VCenter:vcenter812:spec.insecure <---- - 이 문제의 상태를 확인하려면
viocli check health -n neutron를 실행합니다.
- Nova 포드를 가져옵니다.
osctl get pod | grep nova
Nova 포드가 실행 중 상태가 아닌지 확인합니다.
osctl delete pod xxx를 사용하여 포드를 삭제합니다.새 포드의 상태가 실행 중이 될 때까지 기다립니다.
- 이 문제의 상태를 확인하려면
viocli check health -n nova를 실행합니다.
오래된 Nova 서비스
오래된 Nova 서비스에 대한 자세한 내용은 KB 78736 항목을 참조하십시오. 이 문제의 상태를 확인하려면 viocli check health -n nova를 실행합니다.
- 도구 상자에 로그인하고 중복된 Nova 서비스와 끝점이 없는 일부 Nova 서비스를 찾아서 삭제합니다.
# openstack catalog list

# openstack service list

- 사용 중인 Nova 서비스를 확인합니다.
# openstack endpoint list |grep nova
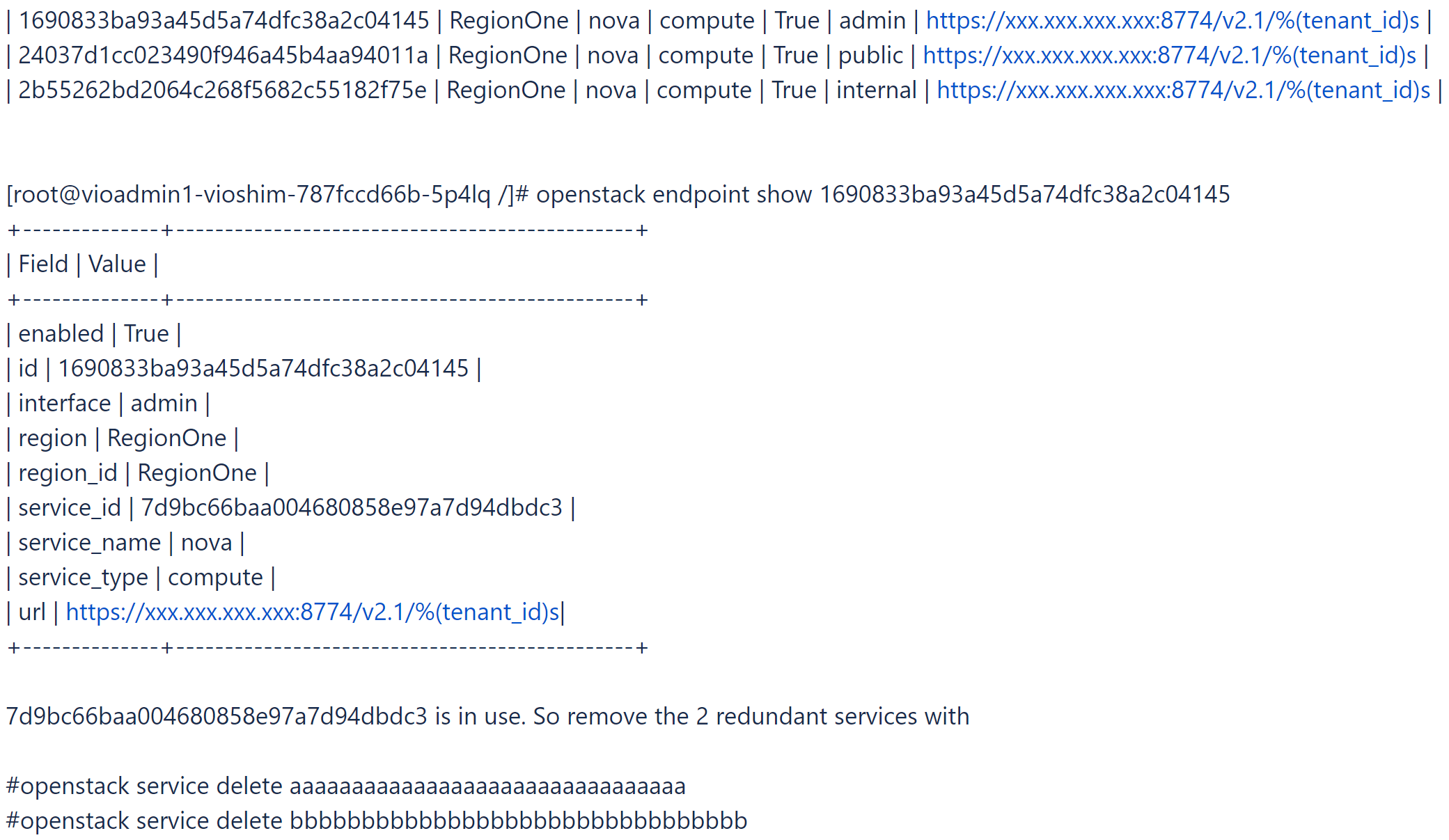
- 이 문제의 상태를 확인하려면
viocli check health -n nova를 실행합니다.
시작 시간 초과로 인해 일부 Nova 컴퓨팅 포드가 계속 다시 시작됨
이 경보는 일부 Nova 컴퓨팅 포드가 비정상 상태일 수 있음을 나타냅니다. 솔루션을 위해 VMware 지원팀에 문의하십시오. 문제의 상태를 확인하려면 viocli check health -n nova를 실행하십시오.
Glance 데이터스토어에 연결할 수 없음
- Glance 서비스 목록을 가져옵니다.
osctl get glance
- Glance 데이터스토어 정보를 가져옵니다.
osctl get glance $glance-xxx -o yaml
- 데이터스토어 연결 정보를 찾습니다.
spec: conf: backends: vmware_backend: vmware_datastores: xxxx vmware_server_host: xxxx vmware_server_password: xxxx vmware_server_username: .xxxx - 정보가 잘못된 경우 vCenter 및 데이터스토어 연결을 확인하고 그에 따라
osctl update glance $glance-xxx를 사용하여 업데이트합니다. - 이 문제의 상태를 확인하려면
viocli check health -n glance를 실행합니다.
잘못된 위치 형식의 Glance 이미지
이 메시지는 일부 Glance 이미지가 잘못된 위치 형식임을 나타냅니다. 솔루션을 위해 VMware 지원팀에 문의하십시오. 문제의 상태를 확인하려면 viocli check health -n glance를 실행하십시오.
Cinder 서비스 다운
- Cinder 포드를 가져옵니다.
osctl get pod | grep cinder | grep -v Completed
Cinder 포드가 실행 중 상태가 아닌지 확인합니다.
osctl delete pod xxx를 사용하여 포드를 삭제합니다.새 포드의 상태가 실행 중으로 표시될 때까지 기다립니다.
- 이 문제의 상태를 확인하려면
viocli check health -n cinder를 실행합니다.
cinder-volume포드에 로그인합니다.#osctl exec -ti cinder-volume-0 bash
- 오래된 Cinder 서비스를 확인하고 나열합니다.
#cinder-manage service list
예:#cinder-manage service list
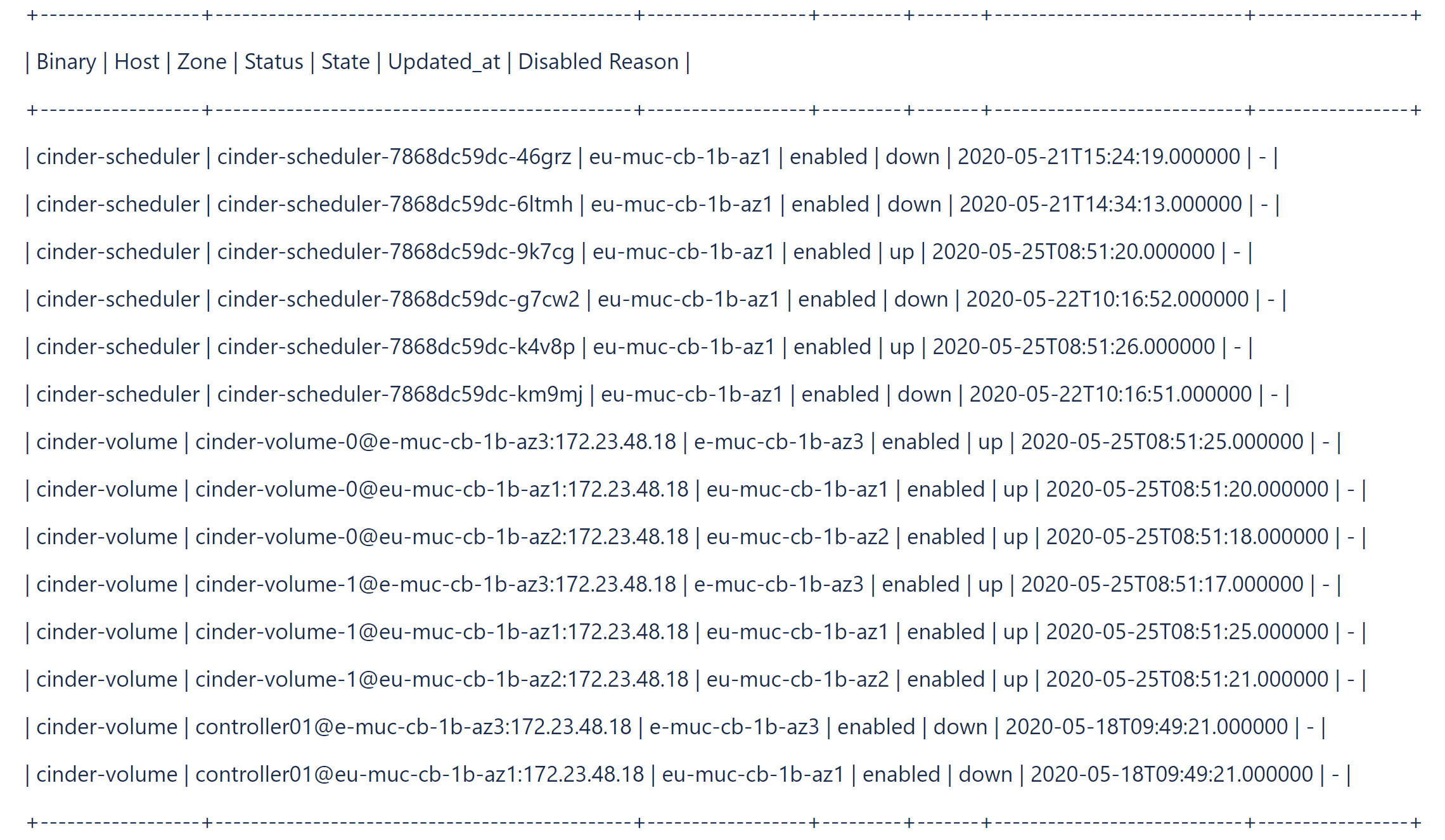
cinder-volume포드에서cinder-manage명령을 사용하여 오래된 Cinder 서비스를 제거합니다.# cinder-manage service remove cinder-scheduler cinder-scheduler-7868dc59dc-km9mj # cinder-manage service remove cinder-volume controller01@e-muc-cb-1b-az3:172.23.48.18
- 이 문제의 상태를 확인하려면
viocli check health -n cinder를 실행합니다.
- VMware Integrated OpenStack 관리 노드에 필요한 명령을 설치하려면
tdnf install xxx를 실행합니다. - 이 문제의 상태를 확인하려면
viocli check health -n basic를 실행합니다.
비어있는 Kubernetes 노드 목록 또는 노드에 연결할 수 없음
VMware Integrated OpenStack 관리 노드에서 osctl get nodes를 실행하고 올바른 출력을 캡처할 수 있는지 확인합니다. 이 문제의 상태를 확인하려면 viocli check health -n basic를 실행합니다.
실행 중인 포드가 없음
VMware Integrated OpenStack 관리 노드에서 osctl get pod |grep xxx를 실행하고 출력에서 실행 중인 포드를 캡처할 수 있는지 확인합니다. 이 문제의 상태를 확인하려면 viocli check health -n basic을 실행합니다.
포드에 연결할 수 없음
VMware Integrated OpenStack 관리 노드에서 osctl exec -it $pod_name bash를 실행하고 포드에 로그인할 수 있는지 확인합니다. 이 문제의 상태를 확인하려면 viocli check health -n basic를 실행합니다.
포드에서 명령을 실행
로그 파일 /var/log/viocli_health_check.log에서 자세한 내용을 확인하고 VMware Integrated OpenStack 관리 노드에서 명령을 다시 실행해봅니다. 이 문제의 상태를 확인하려면 viocli check health -n basic를 실행합니다.
- 도구 상자에 로그인하고 OpenStack 명령(예:
openstack catalog list)을 실행하여 명령이 올바른 반환을 캡처할 수 있는지 확인합니다. - 자세한 메시지를 보려면 디버그 옵션을 추가합니다. 예:
openstack catalog list --debug
- 이 문제의 상태를 확인하려면
viocli check health -n basic를 실행합니다.
- OpenStack 관리자 암호를 가져와서
OS_PASSWORD와 비교합니다.osctl get secret keystone-keystone-admin -o jsonpath='{.data.OS_PASSWORD} keystone-keystone-admin에 저장된 값이 없으면osctl edit secret keystone-keystone-admin을 사용하여 업데이트합니다.- 이 문제의 상태를 확인하려면
viocli check health -n basic를 실행합니다.
vCenter 클러스터가 오버로드됨 / 호스트에 부담이 있음
vCenter 호스트에서 VIO 제어부를 확인하고 리소스를 더 추가하거나 사용되지 않은 일부 인스턴스를 정리하여 리소스에 대한 부담을 덜어줍니다.
- /var/log/viocli_health_check.log 로그를 확인하고 마지막 메시지에서
check_vio_cert_expire를 검색하여 인증서가 만료된 지 얼마나 지났는지, 또는 만료까지 얼마나 남았는지 알 수 있습니다. - 인증서를 업데이트하려면 VMware Integrated OpenStack에 대한 인증서 업데이트의 지침을 따르십시오.
- 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
LDAP 인증서가 만료됨 / 만료 예정임
- /var/log/viocli_health_check.log 로그를 확인하고 마지막 메시지에서
check_ldap_cert_expire를 검색하여 인증서가 만료된 지 얼마나 지났는지, 또는 만료까지 얼마나 남았는지 알 수 있습니다. - 인증서를 업데이트하려면 LDAP 서버에 대한 인증서 업데이트의 지침을 따르십시오.
참고: 구성된 LDAP가 없으면 검사를 건너뛰고
No LDAP Certificate found라는 로그 메시지가 나타납니다. - 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
vCenter 인증서가 만료됨 / 만료 예정임
- /var/log/viocli_health_check.log 로그를 확인하고 마지막 메시지에서
check_vcenter_cert_expire를 검색하여 인증서가 만료된 지 얼마나 지났는지, 또는 만료까지 얼마나 남았는지 알 수 있습니다. - 인증서를 업데이트하려면 업데이트된 vCenter 또는 NSX-T 인증서를 사용하여 VMware Integrated OpenStack 구성의 지침을 참조하십시오.
참고: vCenter가 안전하지 않은 연결을 사용하도록 구성된 경우 검사를 건너뛰고
Use insecure connection이라는 로그 메시지가 나타납니다. - 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
NSX 인증서가 만료됨 / 만료 예정임
- /var/log/viocli_health_check.log 로그를 확인하고 마지막 메시지에서
check_nsx_cert_expire를 검색하여 인증서가 만료된 지 얼마나 지났는지, 또는 만료까지 얼마나 남았는지 알 수 있습니다. - 인증서를 업데이트하려면 업데이트된 vCenter 또는 NSX-T 인증서를 사용하여 VMware Integrated OpenStack 구성의 지침을 참조하십시오.
참고: NSX가 안전하지 않은 연결을 사용하도록 구성된 경우 검사를 건너뛰고
Use insecure connection이라는 로그 메시지가 나타납니다. - 문제의 상태를 다시 확인하려면
viocli check health -n connectivity를 실행합니다.
xxx 서비스가 중지됨
viocli start xxx를 실행하여 서비스를 시작합니다. 이 문제의 상태를 확인하려면 viocli check health -n lifecycle_manager를 실행합니다.
- /var/log/viocli_health_check.log 로그를 확인하고
check_cluster_workload에 대한 마지막 메시지를 검색하여 자세한 리소스 사용량을 확인합니다. - 보고된 리소스 문제를 수정한 다음
viocli check health -n kubernetes를 실행하여 상태를 다시 확인합니다.
