









NSX는 하나의 NSX Manager 클러스터에서 모든 사이트를 관리할 수 있는 다중 사이트 배포를 지원합니다.
- 재해 복구
- 활성-활성
다음 다이어그램은 재해 복구 배포를 보여줍니다.
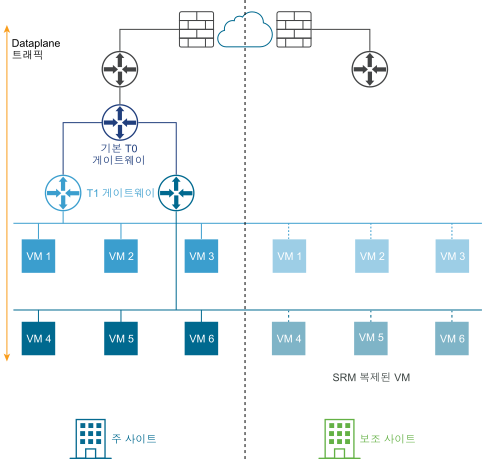
재해 복구 배포의 경우, 주 사이트의 NSX가 엔터프라이즈에 대한 네트워킹을 처리합니다. 보조 사이트는 주 사이트에 심각한 오류가 발생하는 경우 인계하기 위해 대기 중입니다.
다음 다이어그램은 활성-활성 배포를 보여줍니다.
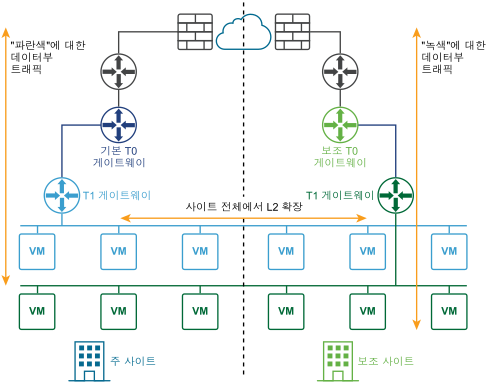
관리부 및 데이터부의 자동 또는 수동/스크립팅된 복구를 위해 두 개의 사이트를 배포할 수 있습니다.
관리부의 자동 복구
- 구성된 사이트 간에 HA가 있는 확장된 vCenter 클러스터.
- 확장된 관리 VLAN.
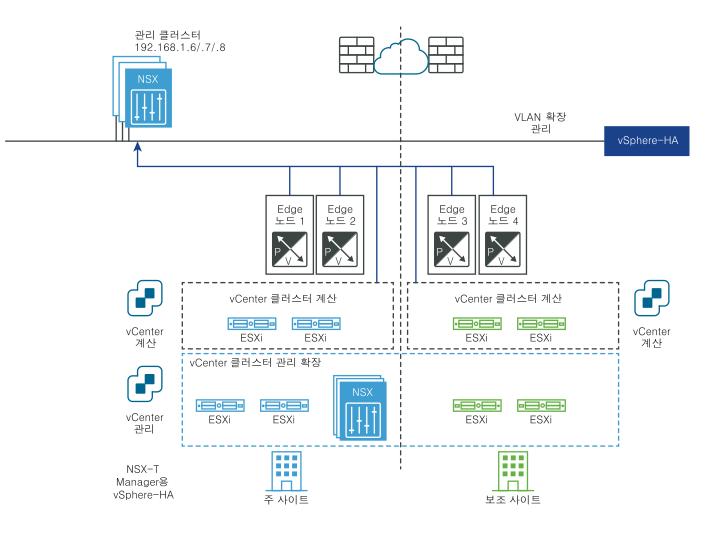
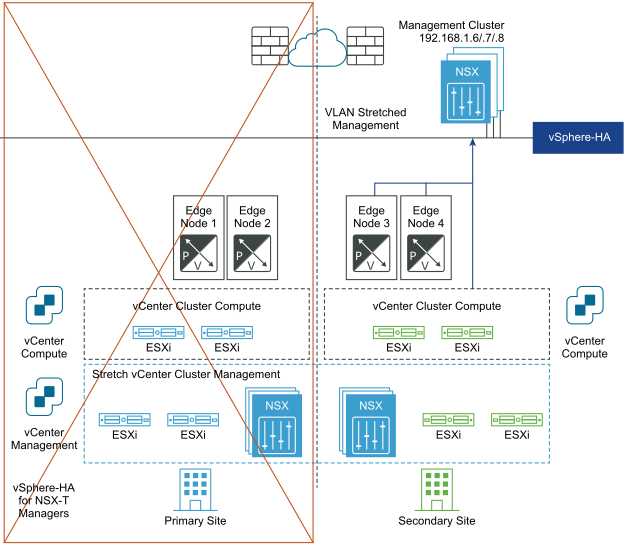
NSX Manager 클러스터가 관리 VLAN에 배포되고 물리적으로 기본 사이트에 있습니다. 기본 사이트 장애가 있는 경우 vSphere HA는 보조 사이트에서 NSX Manager를 다시 시작합니다. 모든 전송 노드가 다시 시작된 NSX Manager에 자동으로 다시 연결됩니다. 이 프로세스는 10분 정도 소요됩니다. 이 시간 동안에는 관리부를 사용할 수 없지만 데이터부는 영향을 받지 않습니다.
다음 다이어그램에서는 관리부의 자동 복구를 보여 줍니다.
재해 전:
재해 복구 후:
데이터부의 자동 복구
Edge 노드에 대한 장애 도메인을 구성하여 데이터부를 자동으로 복구할 수 있습니다. Edge 클러스터 내에서 Edge 노드를 다른 장애 도메인으로 그룹화할 수 있습니다. NSX Manager는 새 활성 Tier-1 게이트웨이를 기본 장애 도메인에 자동으로 배치하고 다른 도메인에는 대기 Tier-1 게이트웨이를 자동으로 배치합니다. 장애 도메인 생성 전에 배포된 T1은 원래 Edge 노드 배치를 유지하고 원하는 위치에 실행되지 않을 수 있습니다. 배치를 수정하려면 T1을 편집하고 T1-Active 및 T1-Standby에 대한 Edge 노드를 수동으로 선택합니다.
- Edge 노드 간의 최대 지연 시간은 10밀리초입니다.
- 예를 들어 물리적 방화벽이 NSX Edge 노드에 대해 노스바운드로 사용되는 경우와 같이 비대칭 북-남 라우팅을 구현할 수 없는 경우 Tier-0 게이트웨이의 HA 모드는 활성-대기 모드여야 하며 페일오버 모드는 선점형이어야 합니다.
- 비대칭 북-남 라우팅이 가능한 경우(예: 사이에 물리적 방화벽이 없는 두 위치의 두 건물) Tier-0 게이트웨이의 HA 모드가 활성-활성일 수 있습니다.
Edge 노드는 VM 또는 베어메탈일 수 있습니다. Tier-1 게이트웨이의 페일오버 모드는 선점형이거나 비선점형일 수 있지만 Tier-0 및 Tier-1 게이트웨이가 동일한 위치에 있도록 보장하려면 선점형 모드를 사용하는 것이 좋습니다.
- API를 사용하여 두 사이트에 대한 장애 도메인을 생성합니다(예: FD1A-Preferred_Site1 및 FD2A-Preferred_Site1).
참고: Edge 노드에서 T1-활성이 있는 모든 Tier-1과 다른 Edge 노드의 T1-대기가 동일한 장애 도메인(FD1A-Preferred_Site1 및 FD2A-Preferred_Site1)에 속하도록 하려면 먼저 선점 옵션을 사용하여 Tier-1을 생성한 다음, 장애 도메인 기본(FD1A-Preferred_Site1)을
preferred_active_edge_services = true로 설정해야 합니다. 예를 들면 다음과 같습니다.POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - API를 사용하여 두 사이트 간에 확장되는 Edge 클러스터를 구성합니다. 예를 들어, 클러스터의 기본 사이트에는 Edge 노드 EdgeNode1A 및 EdgeNode1B가 있고 보조 사이트에는 Edge 노드 EdgeNode2A 및 EdgeNode2B가 있습니다. 활성 Tier-0 및 Tier-1 게이트웨이는 EdgeNode1A 및 EdgeNode1B에서 실행됩니다. 대기 Tier-0 및 Tier-1 게이트웨이는 EdgeNode2A 및 EdgeNode2B에서 실행됩니다.
- API를 사용하여 각 Edge 노드를 사이트의 장애 도메인에 연결합니다. 먼저
GET /api/v1/transport-nodes/<transport-node-id>API를 호출하여 Edge 노드에 대한 데이터를 가져옵니다. 추가 속성인 failure_domain_id를 적절하게 설정하여 GET API의 결과를PUT /api/v1/transport-nodes/<transport-node-id>API 입력으로 사용합니다. 예를 들면 다음과 같습니다.GET /api/v1/transport-nodes/<transport-node-id> Response: { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - API를 사용하여 장애 도메인에 따라 노드를 할당하도록 Edge 클러스터를 구성합니다. 먼저
GET /api/v1/edge-clusters/<edge-cluster-id>API를 호출하여 Edge 클러스터에 대한 데이터를 가져옵니다. 추가 속성인 allocation_rules를 적절하게 설정하여 GET API의 결과를PUT /api/v1/edge-clusters/<edge-cluster-id>API 입력으로 사용합니다. 예를 들면 다음과 같습니다.GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - API 또는 NSX Manager UI를 사용하여 Tier-0 및 Tier-1 게이트웨이를 생성합니다.
전체 기본 사이트 장애의 경우 보조 사이트의 Tier-0 대기 및 Tier-1 대기는 자동으로 새 활성 게이트웨이가 되어 작업을 담당합니다.
다음 다이어그램에서는 데이터부의 자동 복구를 보여줍니다.
재해 전:
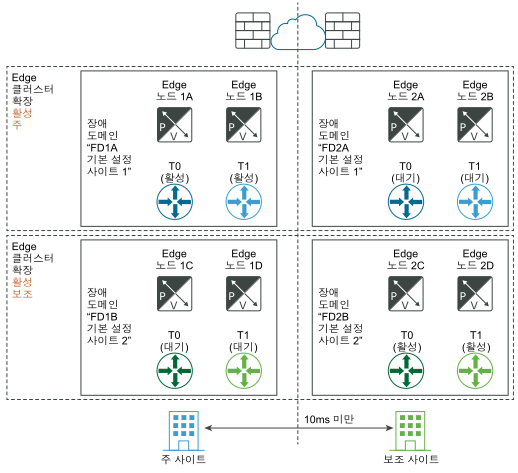
재해 복구 후:
기본 사이트의 Edge 노드 중 하나가 실패하고 전체 사이트가 실패하는 경우에도 동일한 원칙이 적용된다는 점을 알아야 합니다. 예를 들어 다이어그램에서 Edge 노드 1B는 Tier-1-blue 활성을 호스팅하고 Edge 노드 2B는 Tier-1-blue 대기를 호스팅한다고 가정합니다. Edge 노드 1B가 실패하면 Edge 노드 2B의 대기 Tier-1-blue가 인계받아 새 Tier-1-blue 활성 게이트웨이가 됩니다.
관리부의 수동/스크립팅된 복구
- 짧은 TTL(예: 5분)이 지정된 NSX Manager의 DNS.
- 연속 NSX Manager 백업.
vSphere HA 및 확장된 관리 VLAN은 필요하지 않습니다. NSX Manager는 짧은 TTL을 가진 DNS 이름과 연결되어야 합니다. 모든 전송 노드(Edge 노드 및 하이퍼바이저)는 해당 DNS 이름을 사용하여 NSX Manager에 연결해야 합니다. 시간을 절약하기 위해 선택적으로 보조 사이트에 NSX Manager 클러스터를 미리 설치할 수 있습니다.
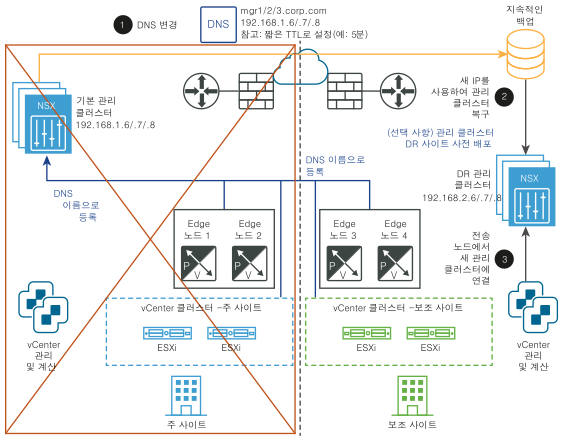
- NSX Manager 클러스터에 다른 IP 주소가 사용되도록 DNS 레코드를 변경합니다.
- 백업에서 NSX Manager 클러스터를 복원합니다.
- 전송 노드를 새 NSX Manager 클러스터에 연결합니다.
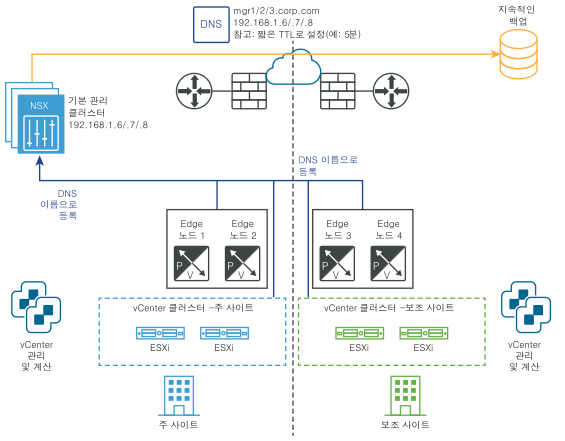
다음 다이어그램은 관리부의 수동/스크립팅된 복구를 보여 줍니다.
재해 전:
재해 후:
데이터부의 수동/스크립팅된 복구
요구 사항: Edge 노드 간의 최대 지연 시간은 150밀리초입니다.
Edge 노드는 VM 또는 베어메탈일 수 있습니다. 각 위치의 Tier-0 게이트웨이는 활성-대기 또는 활성-활성일 수 있습니다. Edge 노드 VM을 서로 다른 vCenter Server에 설치할 수 있습니다. vSphere HA는 필요하지 않습니다.
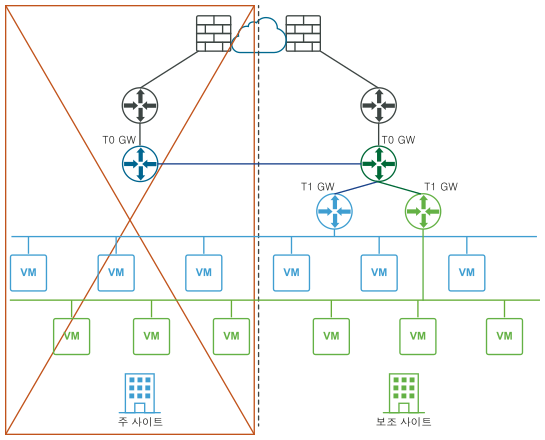
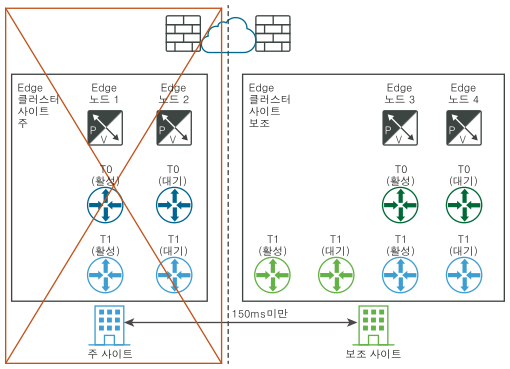
- 기본 사이트(파란색)의 모든 Tier-1에 대해 Edge 클러스터 구성을 Edge 클러스터 사이트로 업데이트합니다.
- 기본 사이트(파란색)의 모든 Tier-1에 대해 T0 보조(녹색)에 다시 연결합니다.
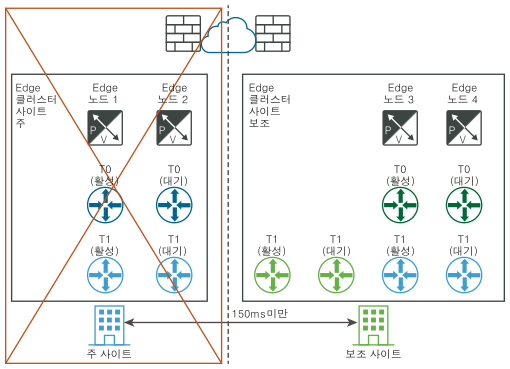
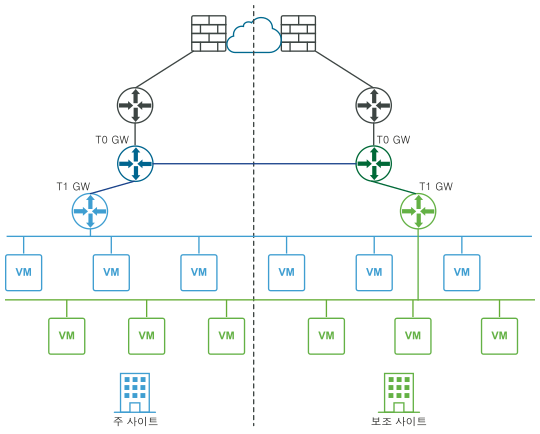
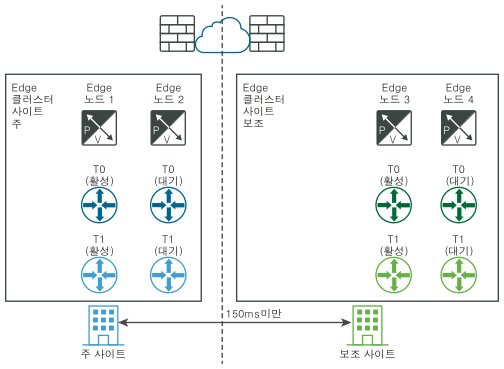
다음 다이어그램은 논리적 네트워크 보기와 물리적 네트워크 보기를 모두 사용하는 데이터부의 수동/스크립팅된 복구를 보여 줍니다.
재해 전(논리적 및 물리적 보기):
재해 후(논리적 및 물리적 보기):
다중 사이트 배포에 대한 요구 사항
- 대역폭은 1Gbps 이상이어야 하고 지연 시간(RTT)은 150ms 미만이어야 합니다.
- MTU는 1,600 이상이어야 합니다. 9,000이 권장됩니다.
- VLAN 관리가 사이트 간에 확장된 관리부의 자동 복구 사용. NSX Manager VM의 사이트 간 vSphere HA
- 사이트 간에 확장된 VLAN 관리가 있는 관리부의 수동/스크립팅된 복구 사용. NSX Manager VM에 대한 VMware SRM.
- 사이트 간에 확장된 VLAN 관리가 없는 관리부의 수동/스크립팅된 복구 사용.
- 연속 NSX Manager 백업.
- NSX Manager는 FQDN을 사용하도록 설정되어야 합니다.
- 공용 IP 주소가 NAT 또는 로드 밸런서와 같은 서비스를 통해 노출되는 경우 동일한 인터넷 제공자를 사용해야 합니다.
- 관리부의 자동 복구 사용
- 위치 간 최대 지연 시간은 10밀리초입니다.
- Tier-0 게이트웨이에 대한 HA 모드는 활성-대기 상태여야 하며 페일오버 모드는 비대칭 라우팅이 없도록 선점형이어야 합니다.
- 비대칭 라우팅을 허용할 수 있는 경우(예: 대도시 지역의 다른 건물) Tier-0 게이트웨이에 대한 HA 모드가 활성-활성일 수 있습니다.
- 관리부의 수동/스크립팅된 복구 사용
- 위치 간 최대 지연 시간은 150밀리초입니다.
- CMS는 NSX 플러그인을 지원해야 합니다. 이 릴리스에서는 VIO(VMware Integrated Openstack) 및 vRA(vRealize Automation)가 이 요구 사항을 충족합니다.
제한 사항
- 로컬 송신 기능이 없습니다. 모든 North-South 트래픽이 한 사이트 내에서 발생해야 합니다.
- 계산 재해 복구 소프트웨어는 NSX(예: VMware SRM 8.1.2 이상)를 지원해야 합니다.
- 다중 사이트 환경에서 NSX Manager를 복원하는 경우 보조/기본 사이트에서 다음을 수행합니다.
- 복원 프로세스가 AddNodeToCluster 단계에서 일시 중지된 후에는 먼저 기존 VIP를 제거하고, 추가 관리자 노드를 추가하기 전에 UI 페이지에서 새 가상 IP를 설정해야 합니다.
- VIP가 업데이트된 후 복원된 단일 노드 클러스터에 새 노드를 추가합니다.
