









이번 섹션에서는 2일 작업 시나리오에서 엔터프라이즈 온-프레미스 배포를 모니터링, 백업 및 업그레이드하는 데 사용할 수 있는 옵션의 정보를 제공합니다.
개요
- 솔루션 분리: VMware Cloud 운영 팀은 핫픽스 및 업그레이드를 적용할 수 있는 액세스 권한이 없습니다.
- 변경 관리에 대한 제한 사항 때문에 패치 적용 및 업그레이드 주기가 제한됩니다.
- 솔루션 모니터링이 부적절하거나 충분하지 않음: 이 상황은 인프라를 관리할 수 있는 인력이 부족하기 때문에 발생하며 이로 인해 기능 문제가 발생하고, 문제 해결이 더 느려지고, 고객 불만족을 초래할 수 있습니다.
이 접근 방식을 사용하려면 항상 적절한 관리, 운영, 패치 적용을 위해 인력 및 시간에 상당한 투자가 필요합니다. 아래 표에서는 시스템 온-프레미스를 관리할 때 고려해야 하는 몇 가지 요소를 간략하게 설명합니다.
| 시스템 | 설명 | VMware 호스팅 책임 | 온-프레미스 책임 |
|---|---|---|---|
| SD-WAN 오케스트레이션 | 애플리케이션 QoS 및 링크 조종 정책 | 예 | 예 |
| 애플리케이션 및 SD-WAN 장치에 대한 보안 정책 | 예 | 예 | |
| SD-WAN 장치 프로비저닝 및 문제 해결 | 예 | 예 | |
| SD-WAN 경고 및 이벤트 처리 | 예 | 예 | |
| 링크 성능 및 용량 모니터링 | 예 | 예 | |
| 하이퍼바이저 | 모니터링/경고 | 아니요 | 예 |
| 계산 및 메모리 리소싱 | 아니요 | 예 | |
| 가상 네트워킹 및 스토리지 | 아니요 | 예 | |
| 백업 | 아니요 | 예 | |
| 복제 | 아니요 | 예 | |
| 인프라 | CPU, 메모리, 계산 | 아니요 | 예 |
| 스위칭 및 라우팅 | 아니요 | 예 | |
| 모니터링 및 관리 시스템 | 아니요 | 예 | |
| 용량 계획 | 아니요 | 예 | |
| 소프트웨어 업그레이드/패치 적용 | 아니요 | 예 | |
| 애플리케이션/인프라 문제 해결 | 아니요 | 예 | |
| 백업 및 인프라 DR | 백업 인프라 | 아니요 | 예 |
| 백업 체계에 대한 정기적인 테스트 | 아니요 | 예 | |
| DR 인프라 | 아니요 | 예 | |
| DR 테스트 | 아니요 | 예 |
엔터프라이즈 온-프레미스 배포에 대한 2일 작업 시나리오는 아래 두 섹션(1일 작업 및 2일 작업)에 각각 설명되어 있습니다.
1일 작업
보안 권고 구독
VMware 제품에 보고되는 보안 취약성에 대한 VMware 보안 권고 문서 업데이트 적용. 온-프레미스 구성 요소에 작업이 필요한 경우 경고를 받으려면 아래 링크를 구독하십시오.
https://www.vmware.com/security/advisories.html
SASE Orchestrator에서 Cloud-init 비활성화
데이터 소스에는 메타데이터 및 사용자 데이터라는 두 섹션이 있습니다. 메타데이터에는 인스턴스 Id를 포함하여 인스턴스 수명 동안 변경되면 안 되지만 사용자 데이터는 첫 번째 부팅 시 적용되는 구성(메타데이터의 인스턴스 ID)입니다.
처음 부팅한 후에는 SASE Orchestrator 부팅 순서의 속도를 높이기 위해 Cloud-init 파일을 비활성화하는 것이 좋습니다. Cloud-init를 비활성화하려면 다음을 실행합니다.
./opt/vc/bin/cloud_init_ctl -d
"apt purge cloud-init" 명령을 사용하여 cloud-init 파일을 "제거"하지 않는 것이 좋습니다(이 절차는 VMware SD-WAN 컨트롤러에서 문제를 유발하지 않음). cloud-init 파일을 제거하면 일부 필수 SASE Orchestrator 도구와 스크립트(예를 들어 업그레이드 및 백업 스크립트)도 지워집니다. "purge" 명령을 사용하는 경우 다음 명령을 사용하여 파일을 복원할 수 있습니다.
- /opt/vcrepo/pool/main/v/vco-tools 폴더로 이동합니다.
- “sudo dpkg -i vco-tools_3.4.1-R341-20200423-GA-69c0f688bf.deb” 폴더에서 SASE Orchestrator 도구 패키지를 설치합니다. vco-tools 패키지 이름은 릴리스에 따라 변경될 수 있습니다. "ls vco-tools" 명령을 사용하여 올바른 파일 이름을 확인하십시오.
NTP 표준 시간대
SASE Orchestrator 및 게이트웨이 시간대를 "기타/UTC(Etc/UTC)"로 설정해야 합니다.
vcadmin@vco1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vco1-example:~$
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
NTP 오프셋
NTP 오프셋은 15밀리초 이하여야 합니다.
vcadmin@vco1-example:~$ sudo ntpq -p
remote refid st t when poll reach delay offset
jitter
==============================================================================
*ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033
ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000
vcadmin@vco1-example:~$
sudo service ntp stop sudo ntpdate <server> sudo service ntp start
SASE Orchestrator 스토리지
SASE Orchestrator가 초기에 배포되면 3개의 파티션 /, /store, /store2., /store3(버전 4.0 이상)이 생성됩니다. 파티션은 기본 크기로 생성됩니다. 디자인과 일치하도록 기본 크기를 수정하는 방법에 대한 자세한 내용은 “SASE Orchestrator에서 스토리지 증가” 섹션에 나와 있는 지침을 따르십시오.
추가 작업
- 시스템 속성을 구성합니다.
- 초기 운영자 프로필을 설정합니다.
- 운영자 계정을 설정합니다.
- SD-WAN Gateways를 생성합니다.
- SASE Orchestrator를 설정합니다.
- 고객 계정/파트너 계정을 생성합니다.
위 목록의 구성은 이 문서의 범위에서 다루지 않으며 VMware 설명서의 배포 가이드에서 찾을 수 있습니다. 자세한 내용은 VMware SASE Orchestrator 배포 및 모니터링 가이드, “SASE Orchestrator 설치” 섹션에서 찾을 수 있습니다.
2일 작업
SASE Orchestrator 백업
이 섹션에서는 SASE Orchestrator 데이터베이스를 정기적으로 백업하여 활성 및 대기 Orchestrator의 운영자 오류 또는 치명적 장애로부터 복구하는 데 사용할 수 있는 메커니즘을 제공합니다.
재해 복구 기능 또는 DR은 기본 복구 방법입니다. 활성 Orchestrator의 모든 구성이 즉시 복제되기 때문에 거의 0에 가까운 복구 시점 목표를 제공합니다. 재해 복구 기능에 대한 자세한 내용은 다음 섹션을 참조하십시오.
내장 스크립트를 사용하는 백업
SASE Orchestrator는 내장된 구성 백업 메커니즘을 제공하여, 활성 및 대기 Orchestrator 둘 다의 운영자 오류 또는 치명적 장애로부터 복구하기 위해 구성을 정기적으로 백업합니다. 이 메커니즘은 스크립트를 기준으로 하며 /opt/vc/scripts/db_backup.sh에 있습니다.
이 스크립트는 기본적으로 구성 데이터 및 이벤트의 데이터베이스 덤프를 사용하지만 데이터베이스 덤프 프로세스 동안 일부 대규모 모니터링 테이블이 제외됩니다. 이 스크립트가 실행되면 위 스크립트에 대한 입력으로 제공된 로컬 디렉토리 경로에 백업 파일이 생성됩니다.
백업은 두 개의 .gzs 파일, 즉 데이터베이스 스키마 정의를 포함하는 파일 1개와 정의 없이 실제 데이터를 포함하는 파일로 구성됩니다. 관리자는 백업 디렉토리 위치에 백업을 위한 충분한 디스크 공간이 있는지 확인해야 합니다.
모범 사례
- 원격 위치를 마운트하고 백업 스크립트를 구성합니다. 흐름이 백업 중이면 원격 위치에 /store와 동일한 스토리지가 있어야 합니다.
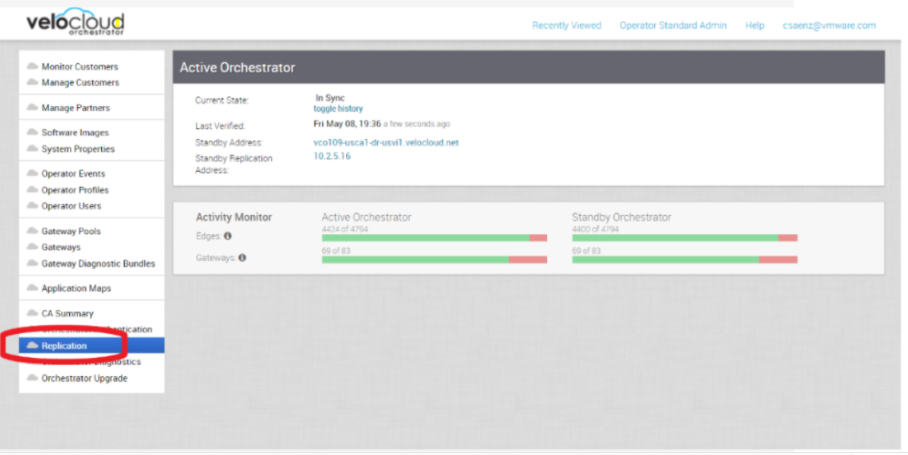
- 백업 스크립트를 사용하기 전에 SASE Orchestrator 복제 페이지에서 DR(재해 복구) 복제 상태를 확인합니다. 동기화되어 있어야 하며 오류가 표시되지 않아야 합니다.
- 그 외에 MySQL 쿼리를 실행하고 복제 지연을 확인합니다.
- SHOW SLAVE STATUS \G
- 위 쿼리에서 seconds_behind_master 필드를 확인합니다. 이상적으로는 0이어야 하지만 10 미만으로도 충분합니다.
- 대규모 SASE Orchestrator의 경우 백업 스크립트 실행을 위해 대기를 사용하는 것이 좋습니다. 두 SASE Orchestrator에서 생성된 백업 간에 차이는 없습니다.
주의 사항- 이 스크립트는 구성 백업만 수행합니다. 흐름 통계 또는 이벤트는 포함되지 않습니다.
- 구성을 복원하려면 지원/엔지니어링 팀의 지원이 필요합니다.
- 스크립트를 실행하는 데 얼마의 시간이 소요됩니까?
백업의 기간은 실제 고객 구성의 규모에 따라 달라집니다. 모니터링 테이블이 백업 작업에서 제외되기 때문에 구성 백업 작업이 빠르게 완료될 것으로 예상됩니다. 수천 개의 SD-WAN Edge와 많은 기록 이벤트를 포함하는 대규모 SASE Orchestrator의 경우 몇 시간까지 걸릴 수 있지만 더 작은 SASE Orchestrator는 몇 분 안에 완료되어야 합니다.
- 백업 스크립트를 실행하기 위한 권장 주기는 무엇입니까?
크기와 초기 백업을 완료하는 데 소요되는 시간에 따라 백업 작업 주기를 결정할 수 있습니다. SASE Orchestrator 리소스에 미치는 영향을 줄이려면 사용량이 적은 시간에 실행되도록 백업 작업을 스케줄링해야 합니다.
- 루트 파일 시스템에 백업을 위한 공간이 충분하지 않으면 어떻게 합니까?
마운트된 다른 볼륨을 사용하여 백업을 저장하는 것이 좋습니다. 참고로, 백업에 루트 파일 시스템을 사용하는 것이 모범 사례는 아닙니다.
- 백업 작업이 성공적으로 완료되었는지 확인하는 방법은 무엇입니까?
스크립트 stdout 및 stderr은 백업 작업의 성공 또는 실패를 결정하기에 충분합니다. 스크립트 호출이 자동화된 경우 종료 코드에서 백업 작업의 성공 또는 실패를 확인할 수 있습니다.
- 구성은 어떻게 복구됩니까?
현재, 고객은 구성 데이터를 복구하기 위해 VMware 지원 서비스와 협의해야 합니다. VMware 지원 서비스는 고객의 구성을 복구하는 데 도움을 줍니다. 고객은 구성이 복원될 때까지 추가 구성 변경을 수행하지 않아야 합니다.
- 이 스크립트를 실행할 경우 정확히 어떤 영향을 미칩니까?
구성의 백업이 성능에 거의 영향을 미치지 않더라도 MySQL 프로세스에 대한 리소스 활용률이 높아집니다. 사용량이 적은 시간에 백업을 실행하는 것이 좋습니다.
- 백업 작업을 실행하는 동안 구성 변경이 허용됩니까?
백업 작업이 실행되는 동안 구성을 변경하는 것이 안전합니다. 그러나 최신 백업을 보장하려면 백업이 실행되는 동안 구성 작업을 수행하지 않는 것이 좋습니다.
- 원래 SASE Orchestrator에서 구성을 복원할 수 있습니까? 아니면 새 SASE Orchestrator가 필요합니까?
예, 사용 가능한 경우 동일한 SASE Orchestrator에서 구성을 복원할 수 있으며 이러한 환경에서 복원하는 것이 좋습니다. 이렇게 하면 복원 작업이 완료된 후 모니터링 데이터가 활용됩니다. 원래 SASE Orchestrator를 복구할 수 없고 대기 Orchestrator가 종료된 경우 새 SASE Orchestrator에서 구성을 복원할 수 있습니다. 이 경우 모니터링 데이터가 삭제됩니다.
- 새 SASE Orchestrator로 구성을 복원해야 하는 경우 어떤 작업을 수행해야 합니까?
해당 단계는 실제 배포에 따라 달라지지만 새 SASE Orchestrator에 권장되는 작업 모음에 대해서는 VMware 지원 서비스에 문의하십시오.
- 새로 복원된 SASE Orchestrator에서 SD-WAN Edges를 다시 등록해야 합니까?
아니요, 필요한 모든 정보는 백업의 일부로 유지되므로 새 SASE Orchestrator에 등록하는 데 SD-WAN Edges가 필요하지 않습니다.
SASE Orchestrator 재해 복구
상태
- 독립형(DR이 구성되어 있지 않음)
- 활성(기본 SASE Orchestrator 서버로 작동하는 DR이 구성되어 있음)
- 대기(비활성 복제 SASE Orchestrator 서버로 작동하는 DR이 구성되어 있음)
- 좀비(DR이 이전에 구성되고 활성 상태였지만 이제 활성 또는 대기로 작동하지 않음)
| 단계 | SASE Orchestrator A 역할 | SASE Orchestrator B 역할 |
|---|---|---|
| 초기(Initial) | 독립형(Standalone) | 독립형(Standalone) |
| 페어링(Pairing) | 액티브 | 대기 |
| 페일오버(Failover) | 좀비(Zombie) | 독립형(Standalone) |
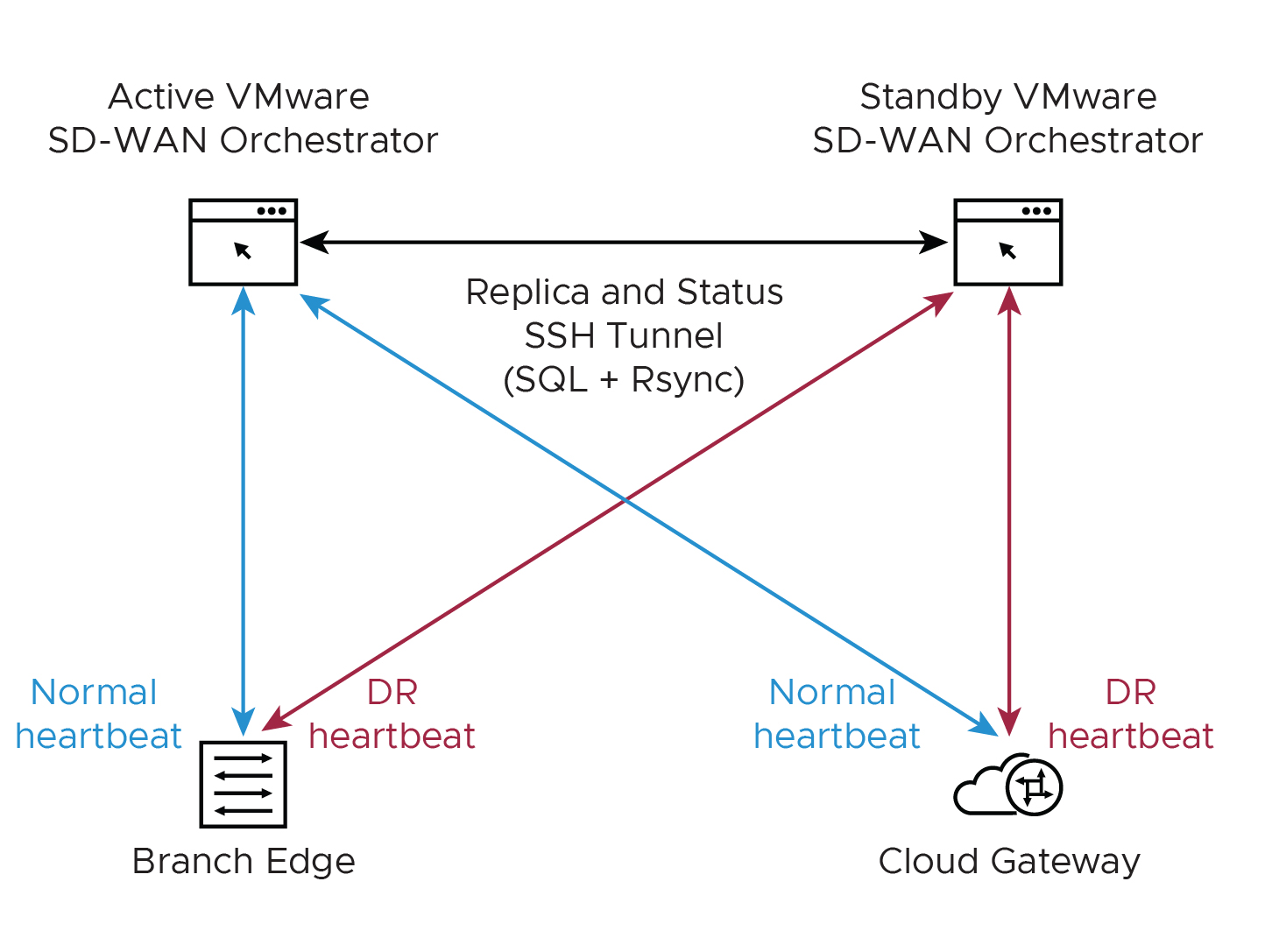
- 지리적으로 분리된 데이터 센터에서 SASE Orchestrator DR을 찾습니다.
- 대기 Orchestrator를 활성 상태로 승격하기 전에 DR 복제 상태가 동기화 상태인지 확인합니다. 이전의 활성 Orchestrator는 더 이상 인벤토리 및 구성을 관리할 수 없습니다.
- 대기 Orchestrator는 이전 활성 Orchestrator와 통신할 수 있는 경우 Orchestrator가 좀비 상태를 시작하도록 지시합니다. 좀비 상태에서 SASE Orchestrator는 이제 활성 상태가 아니며 새로 승격된 SASE Orchestrator와 통신해야 함을 클라이언트(SD-WAN Edges, SD-WAN Gateways, UI/API)에 전달합니다.
- 승격된 대기 Orchestrator가 이전 활성 Orchestrator와 통신할 수 없는 경우 운영자는 가능하면 이전 활성 Orchestrator를 수동으로 강등해야 합니다.
- 자세한 내용은 공식 SASE Orchestrator 설명서 docs.vmware.com의 "SASE Orchestrator 재해 복구 구성" 아래에서 찾을 수 있습니다.
SASE Orchestrator에 대한 업그레이드 절차
- VMware 지원 서비스에서는 업그레이드를 지원합니다. VMware 지원 서비스에 문의하기 전에 다음 정보를 수집하십시오.
- 현재 버전(3.4.2), 대상 버전(3.4.3)과 같은 현재 및 대상 SASE Orchestrator 버전을 제공합니다.
참고: 현재 버전의 경우 이 정보는 도움말(Help) 링크를 클릭하고 정보(About)를 선택하여 SASE Orchestrator의 오른쪽 상단 모서리에서 찾을 수 있습니다.
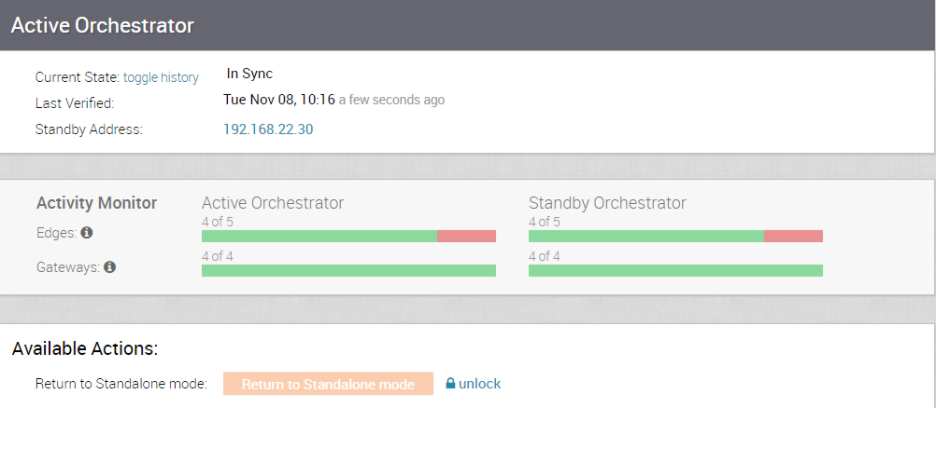
- 아래와 같이 SASE Orchestrator의 복제 대시보드 스크린샷을 제공합니다.
- 하이퍼바이저 유형 및 버전(즉, vSphere 6.7)
- SASE Orchestrator의 명령(명령은 루트 권한으로 실행해야 함(예: 'sudo <command>' 또는 'sudo -i').)
- LVM 레이아웃
- pvdisplay -v
- vgdisplay -v
- lvdisplay -v
- df -h
- cat /etc/fstab
- 메모리 정보
- free -m
- cat /proc/meminfo
- ps -ef
- top -b -n 2
- CPU 정보
- cat /proc/cpuinfo
- /Var/log의 복사본
- tar -czf /store/log-`date +%Y%M%S`.tar.gz --newer-mtime="36 hours ago" /var/log
- 대기 Orchestrator에서:
- sudo mysql --defaults-extra-file=/etc/mysql/velocloud.cnf velocloud -e 'SHOW SLAVE STATUS \G'
- 활성 Orchestrator에서:
- sudo mysql --defaults-extra-file=/etc/mysql/velocloud.cnf velocloud -e 'SHOW MASTER STATUS \G'
- LVM 레이아웃
- 현재 버전(3.4.2), 대상 버전(3.4.3)과 같은 현재 및 대상 SASE Orchestrator 버전을 제공합니다.
- SASE Orchestrator 업그레이드에 대한 지원을 얻으려면 위에 언급한 정보를 참조하고 https://kb.vmware.com/s/article/53907의 VMware SD-WAN 지원에 문의하십시오.
- ESXi 스냅샷 지침은 고객이 업그레이드 후 빠른 롤백 솔루션을 원할 경우 다음 섹션에 제공됩니다.
ESXi 스냅샷
이전 SASE Orchestrator 버전으로의 빠른 롤백을 제공하기 위해 SASE Orchestrator가 업그레이드 되기 전에 ESXi 스냅샷 기능을 사용할 수 있습니다.
ESXi 스냅샷 모범 사례
- 스냅샷으로부터 수행 또는 복원하기 전 데이터베이스 불일치가 발생하지 않도록 하려면 대기 및 활성 Orchestrator의 전원을 꺼야 합니다.
- 데이터베이스 불일치를 방지하려면 모든 스냅샷 관련 작업을 대기 및 활성 Orchestrator에서 수행해야 합니다.
- 업그레이드 프로세스가 성공적으로 수행된 경우 스냅샷을 통합하는 것이 중요합니다. 스냅샷 파일은 더 오랜 기간 동안 유지되는 경우 계속 커집니다. 이로 인해 스냅샷 스토리지 위치에 공간이 부족해지고 시스템 성능에 영향을 줄 수 있습니다.
- 잘못된 경보를 방지하기 위해 스냅샷을 생성하는 동안 SASE Orchestrator에서 경고를 비활성화합니다.
- 72시간 넘게 단일 스냅샷을 사용하지 마십시오.
- 스냅샷을 백업으로 사용하는 것은 권장되지 않습니다.
- ESXi 6.7 및 SASE Orchestrator 버전 3.4.4를 사용하여 기능 검증이 완료되었습니다.
VMware 스냅샷 모범 사례는 KB 문서 https://kb.vmware.com/s/article/1025279에서 찾을 수 있습니다.
ESXi 스냅샷 생성
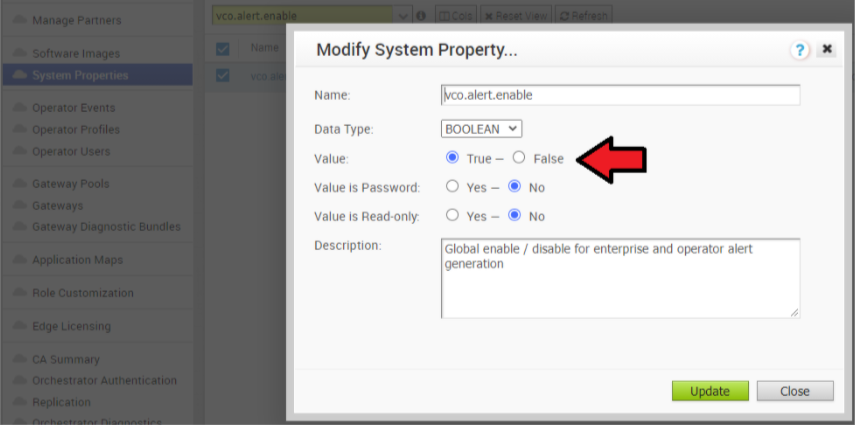
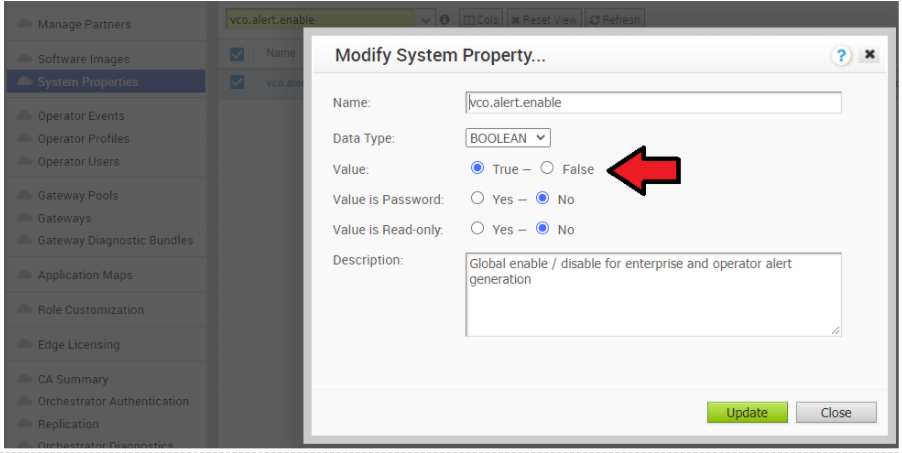
- 활성 Orchestrator에서 경고, 알림 및 모니터링 시스템 속성을 비활성화합니다. 대략적인 기간은 10분입니다.
- 운영자 포털에서 시스템 속성(System Properties)을 클릭합니다. 다음 시스템 속성을 false로 변경합니다.
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
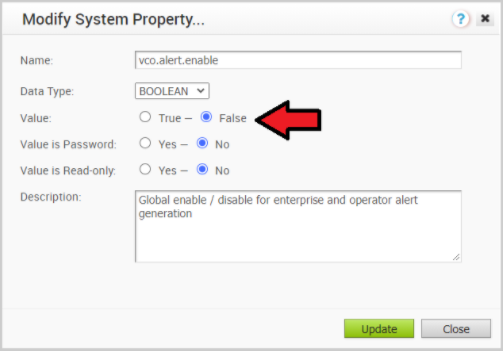
- 운영자 포털에서 시스템 속성(System Properties)을 클릭합니다. 다음 시스템 속성을 false로 변경합니다.
- 대기 Orchestrator에서 경고, 알림, 모니터링 시스템 속성을 비활성화합니다.
- 다음 시스템 속성을 false로 변경합니다.
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- 다음 시스템 속성을 false로 변경합니다.
- 활성 Orchestrator의 전원을 끕니다.
[ESXi/vCenter] → [Orchestrator VM] → [작업(Actions)] → [전원(Power)] → [전원 끄기(Power Off)]로 이동합니다.
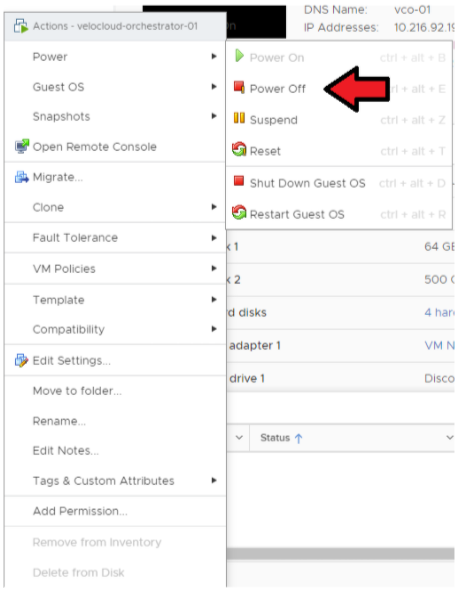
- 대기 Orchestrator의 전원을 끕니다.
ESXi/vCenter → Orchestrator VM → 작업(Actions) → 전원(Power) → 전원 끄기(Power Off)로 이동합니다.
- 활성 Orchestrator의 스냅샷을 생성합니다. 이 단계를 수행하기 전에 VM의 전원이 꺼져 있는지 확인합니다.
ESXi → Orchestrator VM → 작업(Actions) → 전원(Power) → 스냅샷(Snapshots) → 스냅샷 생성(Take Snapshot)으로 이동합니다.
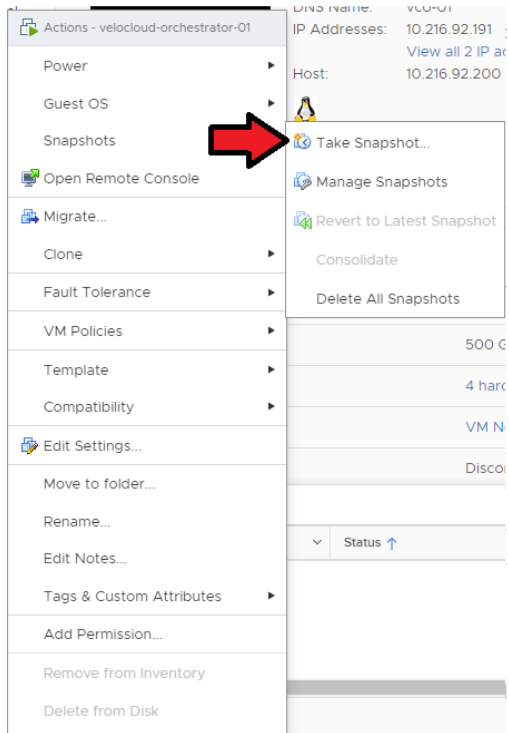
- 대기 Orchestrator의 스냅샷을 생성합니다. 이 단계를 수행하기 전에 VM의 전원이 꺼져 있는지 확인합니다.
ESXi → Orchestrator VM → 작업(Actions) → 전원(Power) → 스냅샷(Snapshots) → 스냅샷 생성(Take Snapshot)으로 이동합니다.
ESXi 스냅샷의 통합
- 활성 및 대기 Orchestrator가 성공적으로 업그레이드되었는지 확인한 후에는 활성 Orchestrator부터 스냅샷을 통합할 수 있습니다.
ESXi → Orchestrator VM → 작업(Actions) → 스냅샷(Snapshots) → 스냅샷 관리자(Snapshot Manager) → 모두 삭제(Delete All)로 이동합니다.
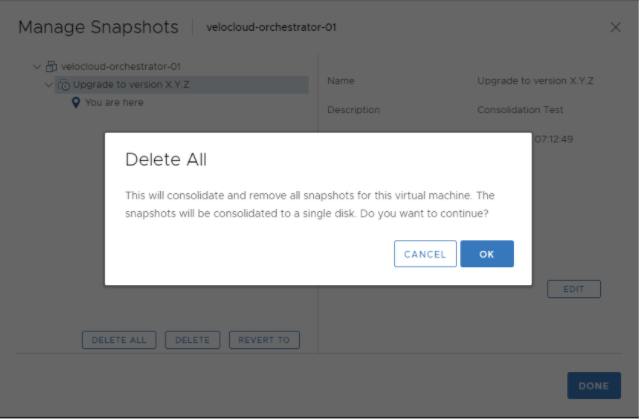
- 대기 Orchestrator에서 스냅샷을 통합합니다.
ESXi → Orchestrator VM → 작업(Actions) → 스냅샷(Snapshots) → 스냅샷 관리자(Snapshot Manager) → 모두 삭제(Delete All)로 이동합니다.
- 활성 Orchestrator 및 대기 Orchestrator에서 경고, 알림 및 모니터링 시스템 속성을 다시 사용하도록 설정합니다.
운영자 포털에서 시스템 속성(System Properties)을 클릭합니다. 다음 시스템 속성을 true로 변경합니다.
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- 모든 스냅샷 삭제(Delete All snapshots)가 vSphere 6.x/7.x에서 작동하지 않는 경우 스냅샷을 통합하려고 시도할 수 있습니다. 자세한 내용은 vSphere 제품 설명서에서 스냅샷 통합 섹션을 참조하십시오.
ESXi 스냅샷에서 복원
- 활성 Orchestrator의 전원을 끕니다.
[ESXi/vCenter] → [Orchestrator VM] → [작업(Actions)] → [전원(Power)] → [전원 끄기(Power Off)]로 이동합니다.
- 대기 Orchestrator의 전원을 끕니다.
[ESXi/vCenter] → [Orchestrator VM] → [작업(Actions)] → [전원(Power)] → [전원 끄기(Power Off)]로 이동합니다.
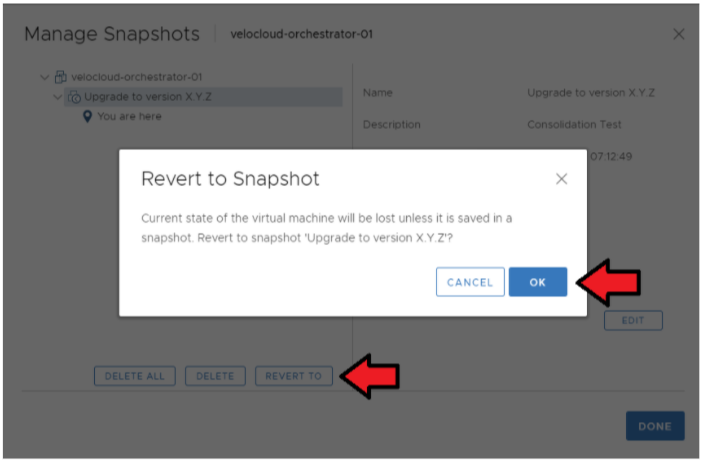
- 활성 Orchestrator의 스냅샷을 복원합니다.
ESXi → Orchestrator VM → 작업(Actions) → 전원(Power) → 스냅샷(Snapshots) → 스냅샷 관리(Manage Snapshots)으로 이동합니다.
VM을 복원할 스냅샷을 선택하고 되돌리기(Revert to)를 선택합니다(아래 이미지 참조).
- 대기 Orchestrator의 스냅샷을 복원합니다.
ESXi → Orchestrator VM → 작업(Actions) → 전원(Power) → 스냅샷(Snapshots) → 스냅샷 관리(Manage Snapshots)로 이동합니다.
VM을 복원할 스냅샷을 선택하고 되돌리기(Revert to)를 선택합니다.
- 활성 Orchestrator 및 대기 Orchestrator에서 경고, 알림, 모니터링 시스템 속성을 다시 사용하도록 설정합니다. 운영자 포털에서 시스템 속성(System Properties)을 클릭합니다. 다음 시스템 속성을 true로 변경합니다.
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
컨트롤러 부 소프트웨어 업그레이드(예: 3.3.2 P3에서 3.4.4로)
소프트웨어 업그레이드 파일에는 게이트웨이 및 시스템 업데이트가 포함되어 있습니다. ‘apt-get update && apt-get –y upgrade’를 실행하지 마십시오.
VMware SD-WAN 컨트롤러의 업그레이드를 진행하기 전에 SASE Orchestrator가 동일한 버전이나 상위 버전보다 먼저 업그레이드되었는지 확인하십시오.
- SD-WAN 컨트롤러 업데이트 패키지를 다운로드합니다.
- 예를 들어, 이미지를 SD-WAN 컨트롤러 스토리지로 업로드합니다(예를 들어 SCP 명령 사용). 이미지를 시스템의 /var/lib/velocloud/software_update/vcg_update.tar 위치에 복사합니다.
- SD-WAN 컨트롤러 콘솔에 연결하고 다음을 실행합니다.
sudo /opt/vc/bin/vcg_software_update
root@VCG:/var/lib/velocloud/software_update# wget -O 'vcg_update.tar' <image location>
Resolving ftpsite.vmware.com (ftpsite.vmware.com)...
Connecting to ftpsite.vmware.com (ftpsite.vmware.com)| <ip address>|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/octet-stream]
Saving to: 'vcg_update.tar'
[ <=> ] 325,939,200 3.81MB/s in 82s
2020-05-23 21:59:27 (3.79 MB/s) - ‘vcg_update.tar’ saved [325939200]
root@VCG:/var/lib/velocloud/software_update# sudo /opt/vc/bin/vcg_software_update
=========== VCG upgrade: Sat May 23 22:08:15 UTC 2020
Upgrading gateway version 3.4.0-106-R340-20200218-GA-c57f8316dd to 3.4.1-39-R341-20200428-GA-44354-44451-596496a88a
Ign file: trusty InRelease
Ign file: trusty Release.gpg
Get: 1 file: trusty Release [2,668 B]
Ign file: trusty/main Translation-en_US
Ign file: trusty/main Translation-en
(...)
Writing extended state information...
Reading package lists...
Building dependency tree...
Reading state information...
Reading extended state information...
Initializing package states...
update-initramfs: Generating /boot/initrd.img-3.13.0-176-generic
Reboot is required. Reboot? (y/n) [y]:
컨트롤러 주 소프트웨어 업그레이드(예: 3.3.2 또는 3.4에서 4.0으로)
- 볼륨 관리의 유연성을 높일 수 있도록 LVM을 기준으로 하는 새 시스템 디스크 레이아웃
- 새 커널 버전
- 새 및 업그레이드된 기본 OS 패키지
- 인터넷 보안 센터 벤치마크에 따라 보안 강화 개선
이러한 변경으로 인해 업그레이드 스크립트를 사용하는 표준 업그레이드 절차가 작동하지 않습니다. 특정 업그레이드 절차가 필요합니다. 아래 제품 설명서에 있습니다. 이 절차는 3.3.2 또는 3.4 게이트웨이 VM을 새 4.0 게이트웨이 VM으로 교체하는 것입니다. 3.3.2 또는 3.4에서 4.0으로 VMware SD-WAN 파트너 게이트웨이 업그레이드 및 마이그레이션 문서를 참조하십시오.
이 업그레이드 절차를 수행하려면 SASE Orchestrator 운영자 계정만 실행할 수 있는 SASE Orchestrator 시스템 속성 구성이 필요합니다. 시스템 속성 변경을 요청하려면 VMware 지원 팀과 함께 지원 티켓을 생성하십시오.
모니터링
- SD-WAN 컨트롤러 모니터링
운영자 포털에서 사용할 수 있는 컨트롤러의 상태 및 사용량 데이터를 모니터링할 수 있습니다.
절차는 다음과 같습니다.
- 운영자 포털에서 게이트웨이(Gateways)를 클릭합니다.
- 게이트웨이(Gateways) 페이지에는 사용 가능한 컨트롤러 목록이 표시됩니다.
- 게이트웨이에 대한 링크를 클릭합니다. 선택한 컨트롤러의 세부 정보가 표시됩니다.
- 모니터링(Monitor) 탭을 클릭하여 선택한 컨트롤러의 사용량 데이터를 봅니다.
선택한 컨트롤러의 모니터링(Monitor) 탭에는 아래 이미지에 표시된 것처럼 다음과 같은 세부 정보가 표시됩니다.
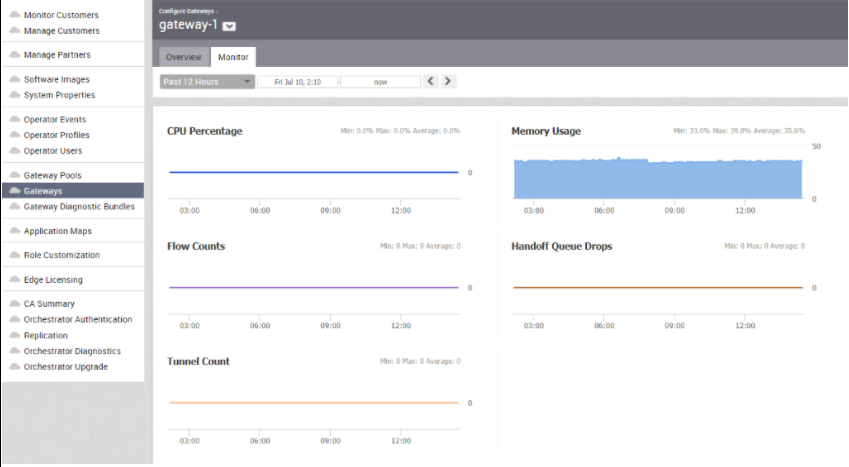
특정 기간을 선택하여 페이지 맨 위에 있는 선택한 기간에 대한 컨트롤러 세부 정보를 볼 수 있습니다.
이 페이지에는 선택한 기간 동안의 최소, 최대 및 평균 값과 함께 다음 매개 변수의 사용량 세부 정보가 그래픽으로 표시됩니다.
| 사용량 | 설명 |
|---|---|
| CPU 백분율(CPU Percentage) | CPU 사용량 비율입니다. |
| 메모리 사용량(Memory Usage) | 메모리 사용량 비율입니다. |
| 흐름 수(Flow Counts) | 트래픽 흐름 수입니다. |
| 핸드오프 대기열 손실 개수(Handoff Queue Drops) | 대기 중인 전달로 인해 손실된 패킷 수입니다. |
| 터널 수(Tunnel Count) | 터널 세션의 수입니다. |
- 모니터링할 SD-WAN Gateway 컨트롤러 권장 값
다음 목록에는 모니터링해야 하는 값과 해당 임계값이 표시됩니다. 아래 목록은 시작점으로 제공되며 모든 내용을 포함하지는 않습니다. 일부 배포의 경우 흐름, 패킷 손실 등과 같은 추가 구성 요소를 평가해야 할 수 있습니다.
주의 임계값에 도달할 때마다 현재 디바이스 크기 조정 구성을 검토하고 필요한 경우 리소스를 더 추가하는 것이 좋습니다. 위험 경보가 트리거되면 VMware 지원 담당자에게 연락하여 솔루션을 확인하고 추가 조언을 제공하는 것이 중요합니다.
표 4. 모니터링할 권장 값 서비스 검사 서비스 검사 설명 주의 임계값 위험 임계값 CPU 로드(CPU Load) 시스템 로드를 확인합니다. 60 80 메모리(Memory) 메모리 활용률 버퍼, 캐시 및 사용된 메모리를 확인합니다. 70 80 터널(Tunnels) 연결된 SD-WAN Edges의 터널 수입니다. 최대 배율의 60% 최대 배율의 80% 참고: 모든 터널의 갑작스러운 손실 또는 비정상적으로 낮은 수량도 문제가 됩니다.
전달 삭제(Handoff Drops) 컨트롤러를 통과하는 트래픽의 혼잡한 특성 때문에 삭제가 가끔 발생할 것으로 예상됩니다. 특정 대기열에서 삭제가 일관되게 발생하면 용량에 문제가 있는 것을 나타낼 수 있습니다. 디스크 공간(Disk Space) 현재 디스크 활용률 40% 사용 가능 20% 사용 가능 컨트롤러 NTP(Controller NTP) 시간 오프셋 확인 5초 오프셋 10초 오프셋
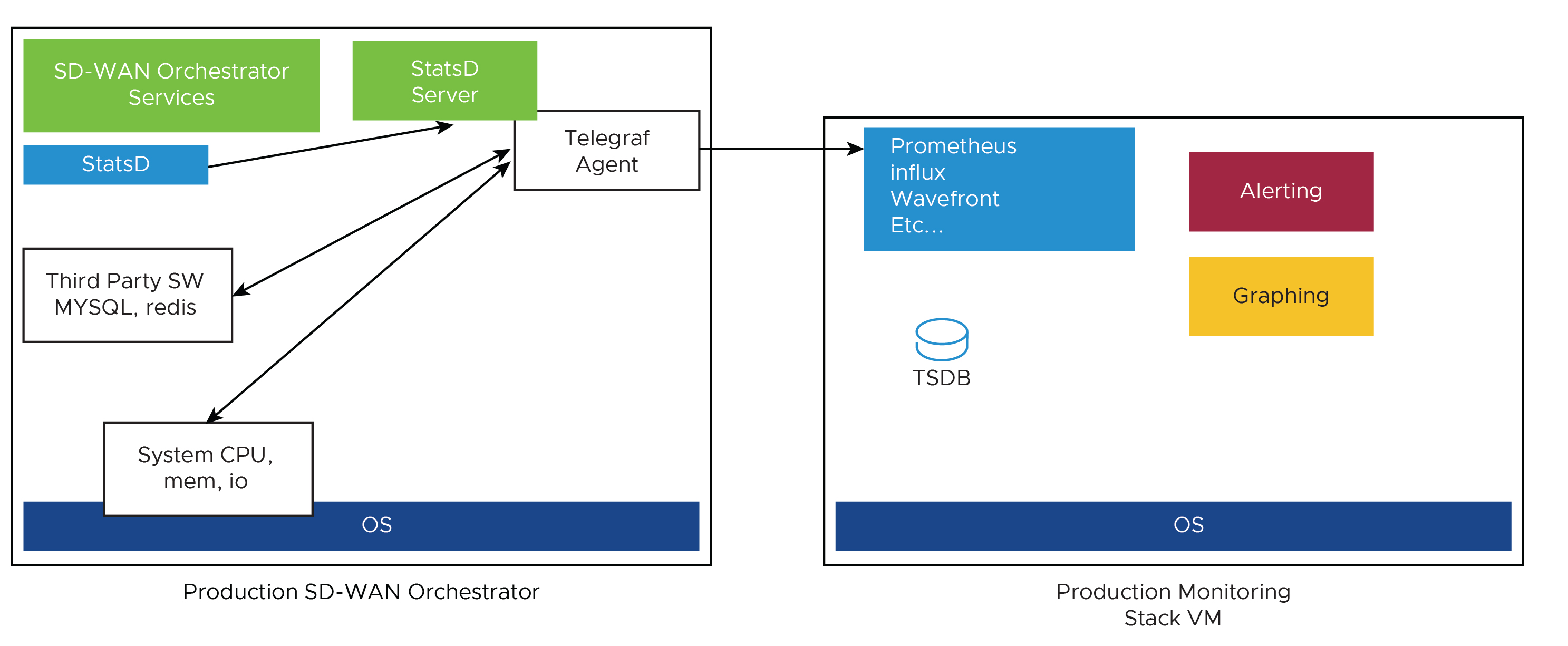
- 모니터링 스택과의 SASE Orchestrator 통합
SASE Orchestrator에는 외부 메트릭 수집기와 시계열 데이터베이스에 연결될 수 있는 기본 제공 시스템 메트릭 모니터링 스택이 제공됩니다. 모니터링 스택을 사용하면 SASE Orchestrator에 대한 상태 조건과 시스템 로드를 쉽게 확인할 수 있습니다.
-
- 모니터링 스택을 사용하도록 설정하려면 Orchestrator에서 다음 명령을 실행합니다.
sudo /opt/vc/scripts/vco_observability_manager.sh enable
- 모니터링 스택의 상태를 확인하려면 다음을 실행합니다.
sudo /opt/vc/scripts/vco_observability_manager.sh status
- 모니터링 스택을 비활성화하려면 다음을 실행합니다.
sudo /opt/vc/scripts/vco_observability_manager.sh disable
- 모니터링 스택을 사용하도록 설정하려면 Orchestrator에서 다음 명령을 실행합니다.
- 메트릭 수집기
Telegraf는 여러 시스템 메트릭을 수집하기 위한 다양한 플러그인을 포함하는 SASE Orchestrator 시스템 메트릭 수집기로 사용됩니다. 다음 메트릭은 기본적으로 사용하도록 설정됩니다.
표 5. 메트릭 수집기 메트릭 이름 설명 지원되는 버전 inputs.cpu CPU 사용량에 대한 메트릭입니다. 3.4/4.0 inputs.mem 메모리 사용량에 대한 메트릭입니다. 3.4/4.0 inputs.net 네트워크 인터페이스에 대한 메트릭입니다. 4.0 inputs.system 시스템 로드 및 가동 시간에 대한 메트릭입니다. 4.0 inputs.processes 상태별로 그룹화된 프로세스의 수입니다. 4.0 inputs.disk 디스크 사용량에 대한 메트릭입니다. 4.0 inputs.diskio 디바이스별 디스크 IO에 대한 메트릭입니다. 4.0 inputs.procstat 특정 프로세스에 대한 CPU 및 메모리 사용량입니다. 4.0 inputs.nginx Nginx의 기본 상태 정보(ngx_http_stub_status_module)입니다. 4.0 inputs.mysql MySQL Server의 통계 데이터입니다. 3.4/4.0 inputs.redis 하나 이상의 redis 서버에서 제공하는 메트릭입니다. 3.4/4.0 inputs.statds API 및 시스템 메트릭. 3.4/4.0(추가 메트릭이 4.0에 포함됨) inputs.filecount 지정된 디렉토리에 있는 파일의 수 및 총 크기입니다. 4.0 inputs.ntpq 표준 NTP 쿼리 메트릭으로, ntpq executable이 필요합니다. 4.0 Inputs.x509_cert SSL 인증서의 메트릭입니다. 4.0 더 많은 메트릭을 사용하도록 설정하거나 사용하도록 설정된 일부 메트릭을 비활성화하려면 다음을 수행하여 SASE Orchestrator의 Telegraf 구성 파일을 편집할 수 있습니다.
sudo vi /etc/telegraf/telegraf.d/system_metrics_input.conf
sudo systemctl restart telegraf
- 시계열 데이터베이스
시계열 데이터베이스를 사용하여 Telegraf에서 수집하는 시스템 메트릭을 저장할 수 있습니다. TSDB(시계열 데이터베이스)는 시계열 데이터에 최적화된 데이터베이스입니다.
- 대시보드 및 경고 에이전트(Dashboard and Alerting Agent)
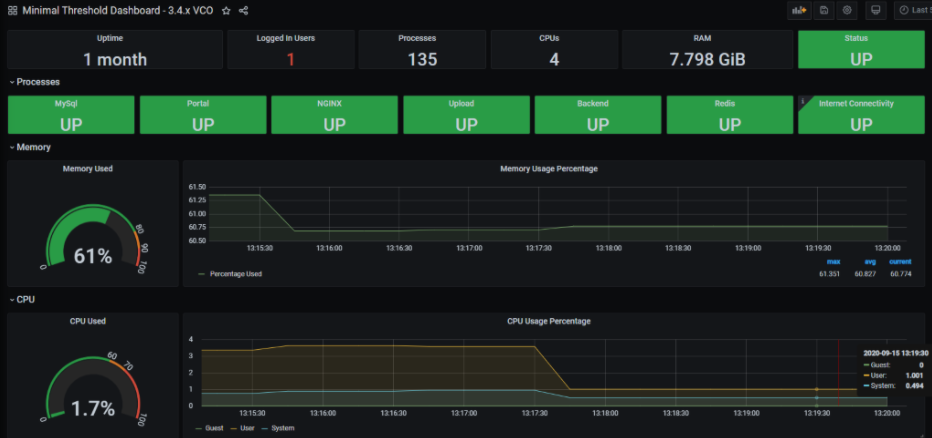
대시보드 및 경고 에이전트(Dashboard and Alerting Agent)를 사용하면 TSDB에 저장된 데이터를 쿼리하고, 시각화하고, 경고하고, 탐색할 수 있습니다. 이 이미지는 솔루션을 모니터링하기 위해 생성할 수 있는 Telegraph(TSDB 및 대시보드 엔진)를 사용하는 대시보드의 예입니다.
- 시계열 데이터베이스 설정
다음 지침에 따라 시계열 데이터베이스를 설정합니다.
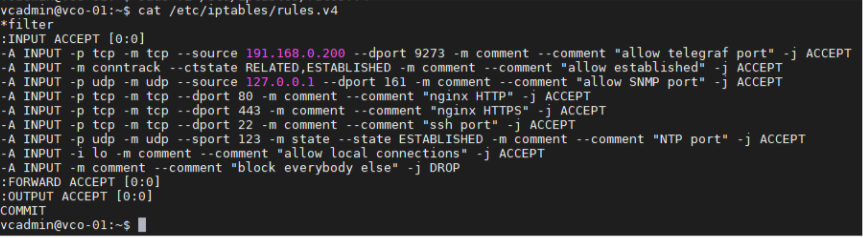
- 외부 모니터링 시스템이 telegraf 포트에 액세스할 수 있도록 하기 위해 iptables 항목을 추가합니다. 보안을 위해 소스 IP 주소를 지정해야 합니다.
- 예: 외부 모니터링 시스템의 IP 주소는 191.168.0.200 Add "-A INPUT -p tcp -m tcp --source 191.168.0.200 --dport 9273 -m comment --comment "allow telegraf port" -j ACCEPT" to /etc/iptables/rules.v4입니다.
- Iptables를 다시 시작합니다.
sudo service iptables-persistent restart(Orchestrator 3.4.x)
sudo systemctl restart netfilter-persistent(Orchestrator 4.x)
- iptables 항목이 추가되었는지 확인합니다.
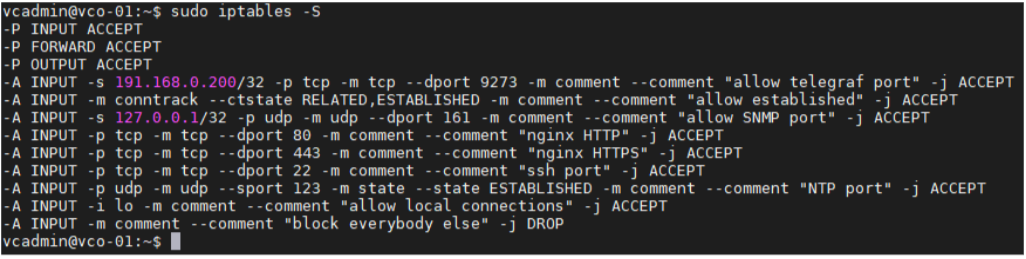
- 예: 외부 모니터링 시스템의 IP 주소는 191.168.0.200 Add "-A INPUT -p tcp -m tcp --source 191.168.0.200 --dport 9273 -m comment --comment "allow telegraf port" -j ACCEPT" to /etc/iptables/rules.v4입니다.
- telegraf 구성에서 시계열 데이터베이스 세부 정보를 추가합니다. 출력 구성 파일을 생성합니다. Prometheus를 사용하는 예는 다음과 같습니다.
/etc/telegraf/telegraf.d/prometheus_out.conf
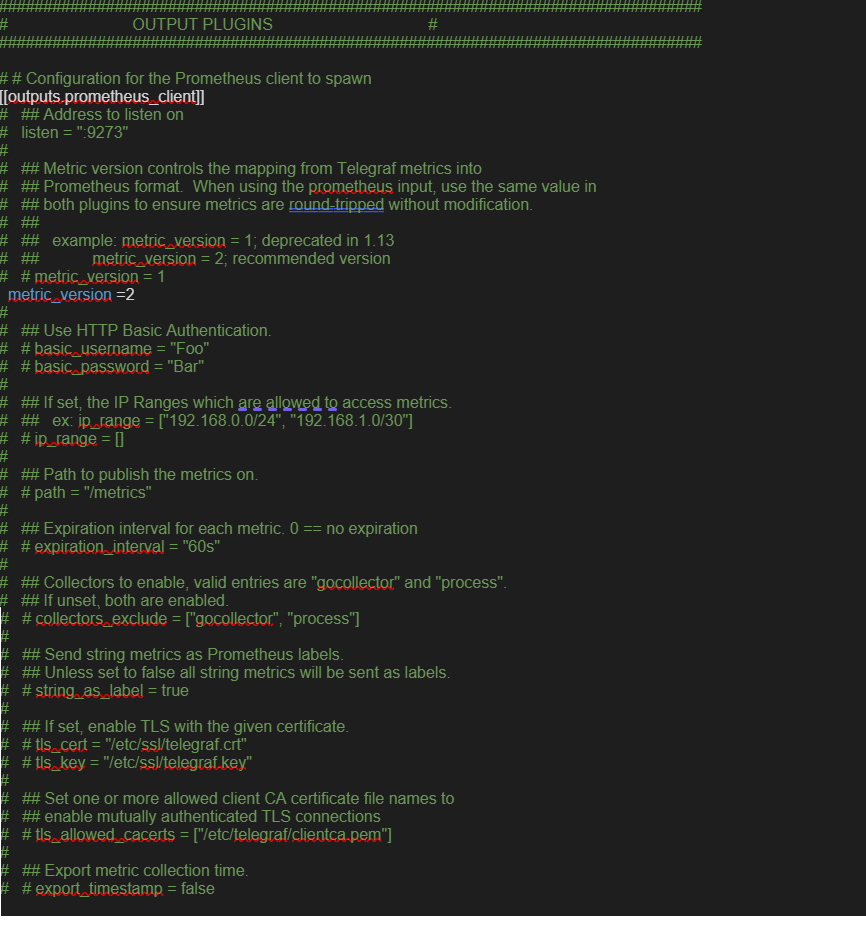
- SASE Orchestrator 모니터링할 권장 값
다음 목록에는 모니터링해야 하는 값과 해당 임계값 목록이 표시됩니다. 아래 목록은 시작점으로 제공되며 모든 내용을 포함하지는 않습니다. 일부 배포의 경우 데이터베이스 트랜잭션, 자동 백업 등과 같은 추가 구성 요소를 평가해야 할 수 있습니다.
주의 임계값에 도달할 때마다 현재 디바이스 크기 조정 구성을 검토하고 필요한 경우 리소스를 더 추가하는 것이 좋습니다. 위험 경보가 트리거되면 VMware 지원 담당자에게 연락하여 솔루션을 확인하고 추가 조언을 제공하는 것이 중요합니다.표 6. 모니터 값 및 임계값 서비스 검사 서비스 검사 설명 주의 임계값 위험 임계값 CPU 로드(CPU Load) 시스템 로드 확인 – Telegraf 입력 플러그인: inputs.cpu. 60 70 메모리(Memory) 메모리 활용률 버퍼, 캐시 및 사용된 메모리 확인 – Telegraf 입력 플러그인: inputs.memory. 70 80 디스크 사용량(Disk Usage) 다른 Orchestrator 파티션 /, /store, /store2 및 /store3의 디스크 활용률(버전 4.0 이상) – Telegraf 입력 플러그인: inputs.disk(버전 4.0 이상). 40% 사용 가능 20% 사용 가능 MySQL Server MySQL 연결 확인 - Telegraf 입력 플러그인: inputs.mysql. 최대 연결의 80% 이상이 mysql.conf(/etc/mysql/my.cnf)에서 정의됩니다. SASE Orchestrator 시간 시간 오프셋 확인 - Telegraf 입력 플러그인: inputs.ntpq(버전 4.0 이상). 5초 오프셋 10초 오프셋 SASE Orchestrator SSL 인증서 인증서 만료 확인 - Telegraf 입력 플러그인: inputs.x509_cert(버전 4.0 이상). 60일 30일 SASE Orchestrator 인터넷(MPLS 전용 토폴로지에 해당되지 않음) 인터넷 액세스를 확인합니다. 응답 시간 > 5초 응답 시간 > 10초 SASE Orchestrator HTTP localhost에서 HTTP가 응답하는지 확인합니다. localhost가 응답하지 않습니다. SASE Orchestrator 총 인증서 수 합계 확인 – mysql 쿼리 예: SELECT count(id) FROM VELOCLOUD_EDGE_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()', 'SELECT count(id) FROM VELOCLOUD_GATEWAY_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()
CRL 총 인증서 수가 5000을 초과하는 경우 DR 복제 상태 대기 Orchestrator가 최신 상태인지 확인합니다. DR SASE Orchestrator가 활성 Orchestrator보다 1000초 미만으로 뒤처져 있는지 검토합니다. Seconds_Behind_Master: mysql 명령: show slave STATUS\G;
DR 복제 SD-WAN Edge 게이트웨이 델타 SD-WAN Edges 및 SD-WAN Gateways가 DR SASE Orchestrator와 통신할 수 있는지 확인합니다. 활성과 대기 Orchestrator 간의 차이 값은 SD-WAN Edges 및 SD-WAN Gateways의 표준 시간대 차이로 인해 발생할 수 있습니다.
활성 Orchestrator와 통신하는 것과 동일한 양의 SD-WAN Edges가 대기 Orchestrator에 도달할 수 있어야 합니다. 이 값은 "복제(replication)" 탭에서 또는 API를 통해 확인할 수 있습니다.
API 모범 사례
- SASE Orchestrator 포털
SASE Orchestrator 포털에서 네트워크 관리자(또는 관리자를 대신하는 스크립트 및 애플리케이션)는 네트워크 및 디바이스 구성을 관리하고 현재 또는 기간별 네트워크 및 디바이스 상태를 쿼리할 수 있습니다. API 클라이언트는 JSON-RPC 인터페이스 또는 REST 유사 인터페이스를 통해 포털과 상호 작용할 수 있습니다. 이러한 인터페이스를 사용하여 이 문서에 설명된 모든 메서드를 호출할 수 있습니다. 액세스를 JSON-RPC 클라이언트 또는 REST 유사 인터페이스만으로 제한하는 포털 기능은 없습니다.
두 인터페이스 모두 HTTP POST 요청을 독점적으로 수락합니다. 둘 다 요청 본문(있는 경우)이 RFC 2616과 호환될 것으로 예상하지만 클라이언트는 Content-Type 요청 헤더(예: Content-Type: application/json)를 사용하는 경우에도 공식적으로 어설션할 수 있습니다.
VMware SD-WAN API에 대한 자세한 내용은 다음에서 찾을 수 있습니다.
- API를 사용하는 엔터프라이즈 및 서비스 제공자에 대한 모범 사례
API를 사용하는 경우의 몇 가지 모범 사례는 다음과 같습니다.
- 가능한 경우 집계 API 호출이 엔터프라이즈별 호출보다 우선되어야 합니다. 예를 들어, 단일 monitoring/getAggregateEdgeLinkMetrics 호출을 사용하여 모든 SD-WAN Edges에서 동시에 전송 통계를 검색할 수 있습니다.
- VMware는 클라이언트가 임의의 지정된 시간에 바로 수행하는 API 호출 수를 적게(2-4 미만으로) 제한하도록 요청합니다. 사용자가 API 호출을 병렬화해야 할 이유가 있다고 느낄 경우 VMware 지원 서비스에 문의하여 대안을 논의해야 합니다.
- 일반적으로 API에 10분보다 더 짧은 간격으로 더 자주 통계 데이터를 폴링하는 것을 권장하지 않습니다. 새 통계 데이터는 5분마다 SASE Orchestrator에 도달합니다. 보고/처리의 지터로 인해 5분 간격으로 폴링하는 클라이언트는 통계가 API 호출 결과에 반영되지 않는 "가양성”을 확인할 수도 있습니다. 사용자는 요청 간격을 10분 이상으로 유지할 경우 최상의 결과를 얻을 수 있다는 것을 알 수 있게 됩니다.
- 동일한 정보를 두 번 쿼리하지 마십시오.
- API 간에 절전 모드를 사용합니다.
- 복잡한 소프트웨어 자동화의 경우 스크립트를 실행하고 CPU/메모리 영향을 평가합니다.그런 다음, 필요에 따라 조정합니다.
SASE Orchestrator Syslog 구성
VMware SASE Orchestrator Syslog 기능은 Orchestrator 프로세스인 포털, 업로드 및 백엔드에 대해 별도로 구성할 수 있습니다.
- 포털: 포털 프로세스는 NGINX에서 다운스트림으로 내부 HTTP 서버로서 실행됩니다. 포털 서비스는 SASE Orchestrator 웹 인터페이스 또는 HTTP/SDK 클라이언트에서 수신되는 API 요청을 주로 동기식으로 처리합니다. 이러한 요청은 인증된 사용자가 SASE Orchestrator에서 제공하는 다양한 서비스를 구성, 모니터링, 관리할 수 있도록 허용합니다.
이 로그는 SASE Orchestrator의 사용자가 수행한 모든 작업이 있기 때문에 AAA 작업에 매우 유용합니다.
로그 파일: /var/log/portal/velocloud.log(모든 정보, 주의 및 오류 로그 기록)
- 업로드: 업로드 프로세스는 NGINX에서 다운스트림으로 내부 HTTP 서버로서 실행됩니다. 업로드 서비스는 SD-WAN Edges 및 SD-WAN Gateways에서 들어오는 요청을 동기식 또는 비동기식으로 처리합니다. 이러한 요청은 주로 SD-WAN Edges 및 SD-WAN Gateways에서 전송되는 활성화, 하트비트, 흐름 통계, 링크 통계, 라우팅 정보로 구성됩니다.
로그 파일: /var/log/upload/velocloud.log(모든 정보, 주의 및 오류 로그 기록)
- 백엔드: 스케줄링되거나 대기 중인 작업을 주로 실행하는 작업 러너입니다. 스케줄링된 작업은 정리, 롤업 또는 상태 업데이트 작업으로 구성됩니다. 대기열에 포함된 작업은 처리 링크 및 흐름 통계로 구성됩니다.
로그 파일: /var/log/backend/velocloud.log(모든 정보, 주의 및 오류 로그 기록)
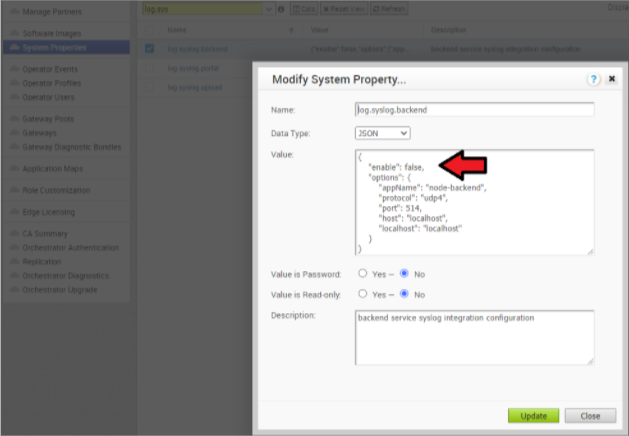
- SASE Orchestrator의 시스템 속성 log.syslog로 이동합니다.<server> (eg log.syslog.portal). SASE Orchestrator → [시스템 속성(System Properties)]으로 이동 → 검색 창에 “log.syslog”를 입력합니다.
- 하나 이상의 서버에 대해 "enable":false 값을 true로 변경합니다. 호스트 IP 및 포트를 구현에 맞게 변경합니다.
SASE Orchestrator에서 스토리지 늘리기
SASE Orchestrator의 스토리지를 늘리기 위한 자세한 내용은 SASE Orchestrator에서 찾아볼 수 있습니다.
https://docs.vmware.com/의 "SASE Orchestrator 설치" 및 "디스크 크기 확장(VMware)"에서 찾을 수 있습니다.
- 모범 사례:
- 동일한 LVM 배포가 대기 Orchestrator에 적용되어 있는지 확인합니다.
- 일단 늘어난 볼륨 크기를 줄이는 것은 권장되지 않습니다. 대신 VMware® vStorage Thin Provisioning을 사용합니다.
- 3.4에서는 디스크 크기를 늘리면 다음과 같은 백분율/값 분포가 사용될 수 있습니다.
- “/” 볼륨: 이 볼륨은 운영 체제에 사용됩니다. 운영 Orchestrator는 일반적으로 140GB로 설정되고 40%~60%가 사용됩니다.
- /store 및 /Store2: 운영 Orchestrator에 적용되는 비율은 /Store의 경우 약 85%이고, /Store2의 경우 약 15%입니다.
- 아래 표에 나와 있는 다음 지침을 4.x 이상 릴리스에 사용해야 합니다.
인스턴스 크기 /store /store2 /store3 /var/log 소형(5000 SD-WAN Edges) 2 TB 500GB 8TB 15GB 중형(10000 SD-WAN Edges) 2 TB 500GB 12TB 20GB 대형(15000 SD-WAN Edges) 2 TB 500GB 16TB 25GB
SASE Orchestrator에서 인증서 관리
SASE Orchestrator는 기본 제공 인증서 서버를 사용하여 모든 SD-WAN Edges 및 SD-WAN 컨트롤러의 전체 PKI 수명주기를 관리합니다. X.509 인증서가 네트워크의 디바이스에 발급됩니다.
CA를 구성하는 자세한 내용은 https://docs.vmware.com/kr/VMware-SD-WAN/index.html의 공식 VMware SD-WAN 운영자 설명서 내 "SASE Orchestrator 설치" 및 "SSL 인증서 설치"에서 찾을 수 있습니다.
- SASE Orchestrator와 SD-WAN Edge/ SD-WAN 컨트롤러 간의 관리부 TLS 1.2 터널.
- SD-WAN Edge 간과 SD-WAN Edge와 SD-WAN 컨트롤러 간의 제어부 및 데이터부 IKEv2/IPsec 터널.
인증서 해지 목록
vcadmin@vcg1-example:~$ openssl crl -in /etc/vc-public/vco-ca-crl.pem -text | grep 'Serial Number' | wc -l 14 vcadmin@vcg1-example:~
지원 상호 작용
고객 지원 조직은 VMware SD-WAN 고객에게 세계 수준의 연중무휴 기술 지원 및 개인화된 지침을 제공합니다.
- 진단 번들
인시던트를 조사하는 동안 SASE Orchestrator 및 SD-WAN 컨트롤러의 진단 번들을 생성할 수 있습니다. 결과 파일은 VMware 지원 팀이 문제에 대한 이벤트를 추가적으로 분석할 수 있도록 지원합니다.
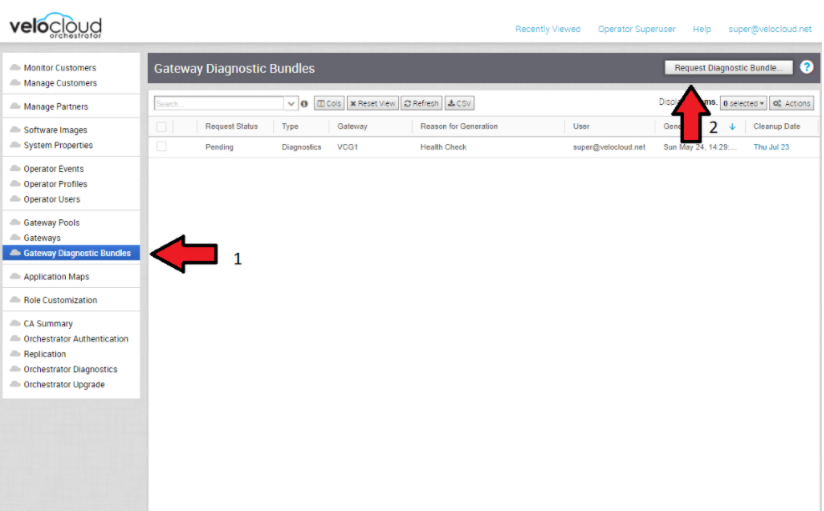
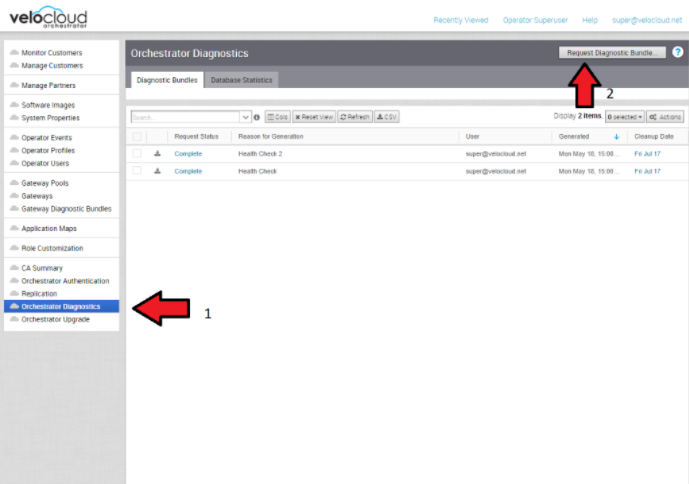
- 지원 서비스와 액세스 공유
경우에 따라 SASE Orchestrator 및 SD-WAN 컨트롤러의 VMware 지원 담당자가 제공하는 지원이 필요할 수 있습니다.
액세스 권한을 부여하는 몇 가지 일반적인 방법은 다음과 같습니다.- 지원되는 원격 세션: 고객은 SSH 점프 서버에 원격 제어 권한을 부여하거나 지원 담당자의 지침을 따릅니다.
- SASE Orchestrator에서 지원 팀 계정 생성. 이를 통해 지원 팀은 고객 상호 작용없이 로그를 수집할 수 있습니다.
- 배스천 호스트를 통해: 지원 엔지니어가 배스천 호스트를 사용하여 온 프레미스 SASE Orchestrator 및 SD-WAN 컨트롤러에 액세스할 수 있도록 SSH 사용 권한 및 키를 구성할 수 있습니다.
문제를 심사하는 데 도움을 얻기 위해 VMware SD-WAN 지원 서비스에 문의하는 경우 아래 표에 설명된 데이터를 포함하십시오.
자세한 내용은 https://kb.vmware.com/s/article/53907 링크에서 찾을 수 있습니다.
| 필수 항목 | 제안 항목 |
|---|---|
| 파트너 케이스 번호 | 문제 시작/중지 |
| 파트너 반품 이메일/전화 | 영향을 받는 흐름 SRC/DST IP |
| SASE Orchestrator URL | 영향을 받는 흐름 SRC/DST 포트 |
| SASE Orchestrator의 고객 이름 | 흐름 경로(E2E, E2GW, Direct) |
| 고객 영향(높음/중간/낮음) | SD-WAN Gateway 이름 |
| SD-WAN Edge 이름 | SASE Orchestrator의 PCAP에 대한 링크 |
| SASE Orchestrator의 진단 번들에 대한 링크 | |
| 간단한 문제 설명 | |
| 분석 및 요청된 지원 |
