









워크로드 클러스터를 특수 하드웨어에 배포
Tanzu Kubernetes Grid vSphere 7.0 이상에서 특정 유형의 GPU 지원 호스트에 워크로드 클러스터를 배포하도록 지원합니다.
GPU 지원 워크로드 클러스터 배포
vSphere 워크로드 클러스터에서 GPU가 있는 노드를 사용하려면 PCI 패스스루 모드를 사용하도록 설정해야 합니다. 이렇게 하면 클러스터가 ESXi 하이퍼바이저를 우회하여 GPU에 직접 액세스할 수 있으며, 이렇게 하면 네이티브 시스템의 GPU 성능과 유사한 수준의 성능을 제공하는 할 수 있습니다. PCI 패스스루 모드를 사용하는 경우 각 GPU 디바이스는 vSphere 클러스터의 VM(가상 시스템) 전용입니다.
참고GPU 지원 노드를 기존 클러스터에 추가하려면
tanzu cluster node-pool set명령을 사용합니다.
사전 요구 사항
- ESXi 호스트에 NVIDIA V100 또는 NVIDIA Tesla T4 GPU 카드가 있습니다.
- vSphere 7.0 업데이트 3 이상. 다음은 7.0u3에 대한 빌드로, 이를 지원하는 데 필요한 최소값입니다.
- Tanzu Kubernetes Grid v1.6 이상.
- Helm, Kubernetes 패키지 관리자. 설치하려면 Helm 설명서에서 Helm 설치를 참조하십시오.
절차
GPU 지원 호스트의 워크로드 클러스터를 생성하려면 다음 단계에 따라 PCI 패스스루를 사용하도록 설정하고, 사용자 지정 시스템 이미지를 구축하고, 클러스터 구성 파일을 생성하고, 릴리스를 Tanzu Kubernetes, 워크로드 클러스터를 배포하고, Helm을 사용하여 GPU 연산자를 설치합니다.
-
GPU 카드가 있는 ESXi 호스트를 vSphere Client를 추가합니다.
-
PCI 패스스루를 사용하도록 설정하고 GPU ID를 다음과 같이 기록합니다.
- vSphere Client에서
GPU클러스터에서 대상 ESXi 호스트를 선택합니다. - 구성(Configure) > 하드웨어(Hardware) > PCI 디바이스(PCI Devices)를 선택합니다.
- 모든 PCI 디바이스(All PCI Devices) 탭을 선택합니다.
- 목록에서 대상 GPU를 선택합니다.
- 패스스루 전환(Toggle Passthrough)을 클릭합니다.
- 일반 정보 에서 디바이스 ID 및 벤더 ID(아래 이미지에 녹색으로 강조 표시됨)를 기록합니다. ID는 동일한 GPU 카드에 대해 동일합니다. 클러스터 구성 파일에는 이러한 파일이 필요합니다.
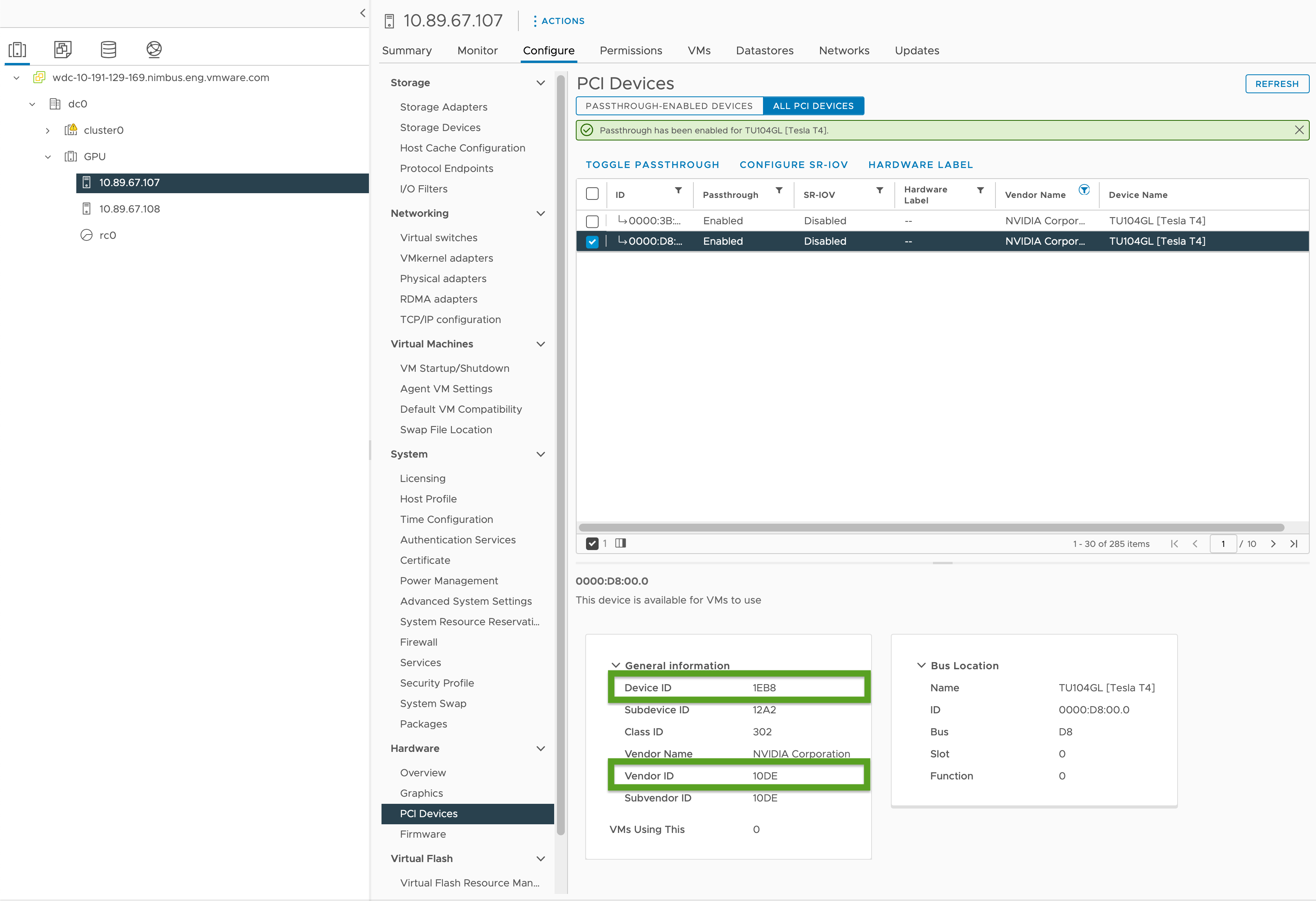
- vSphere Client에서
-
워크로드 클러스터 템플릿에 있는 템플릿을 사용하여 워크로드 클러스터 구성 파일을 생성하고 다음 변수를 포함합니다.
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"여기서:
<VENDOR-ID>및<DEVICE-ID>는 이전 단계에서 기록한 벤더 ID 및 디바이스 ID입니다. 예를 들어, 벤더 ID가10DE이고 디바이스 ID가1EB8이면 값은"0x10DE:0x1EB8"입니다.<GPU-SIZE>는 다음 2개의 전원으로 반올림되는 클러스터에 있는 모든 GPU의 총 프레임버퍼 메모리(GB)입니다.- 예를 들어 40GB GPU 2개가 있는 경우 총 80GB는 128GB로 반올림됩니다. 값을
pciPassthru.64bitMMIOSizeGB=128로 설정합니다. - GPU 카드에 필요한 메모리를 찾으려면 특정 NVIDIA GPU 카드의 설명서를 참조하십시오. NVIDIA 설명서의 대용량 메모리 VM에서 64GB 이상의 MMIO 공간이 필요한 GPU에서 vGPU를 사용하기 위한 요구 사항 표를 참조하십시오.
- 다음 사항도 참조하십시오.
- 예를 들어 40GB GPU 2개가 있는 경우 총 80GB는 128GB로 반올림됩니다. 값을
- NVIDIA Tesla T4 GPU를 사용할 경우
<BOOLEAN>은false이고, NVIDIA V100 GPU를 사용할 경우true입니다. <VSPHERE_WORKER_HARDWARE_VERSION>은 VM을 업그레이드하려는 가상 시스템 하드웨어 버전입니다. GPU 노드에 필요한 최소 버전은 17이어야 합니다.- 업그레이드 중에 Worker 노드에서 사용할 수 있는 추가 PCI 디바이스가 있는 경우
WORKER_ROLLOUT_STRATEGY는RollingUpdate입니다. 그렇지 않으면OnDelete를 사용합니다.
참고
VM당 하나의 GPU 유형만 사용할 수 있습니다. 예를 들어 단일 VM에서 NVIDIA V100 및 NVIDIA Tesla T4를 둘 다 사용할 수는 없지만 벤더 ID 및 디바이스 ID가 동일한 여러 GPU 인스턴스를 사용할 수 있습니다.
tanzuCLI는MachineDeployment의WORKER_ROLLOUT_STRATEGY규격을 업데이트하는 것을 허용하지 않습니다. 사용할 수 없는 PCI 디바이스로 인해 클러스터 업그레이드가 중단되면 VMware는kubectlCLI를 사용하여MachineDeployment전략을 편집할 것을 제안합니다. 롤아웃 전략은spec.strategy.type에서 정의됩니다.GPU 지원 클러스터에 대해 구성할 수 있는 전체 변수 목록은 구성 파일 변수 참조 의 GPU 지원 클러스터를 참조하십시오.
-
다음을 실행하여 워크로드 클러스터를 생성합니다.
tanzu cluster create -f CLUSTER-CONFIG-NAME여기서
CLUSTER-CONFIG-NAME은 이전 단계에서 생성한 클러스터 구성 파일의 이름입니다. -
NVIDIA Helm 저장소를 추가합니다.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
NVIDIA GPU Operator를 설치합니다.
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator여기서
KUBECONFIG는 워크로드 클러스터의kubeconfig이름과 위치입니다. 자세한 내용은 워크로드 클러스터kubeconfig검색을 참조하십시오.이 명령의 매개 변수에 대한 자세한 내용은 NVIDIA 설명서의 GPU Operator 설치를 참조하십시오.
-
NVIDIA GPU Operator가 실행 중인지 확인합니다.
kubectl --kubeconfig=./KUBECONFIG get pods -A출력은 다음과 비슷합니다.
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
GPU 클러스터 테스트
GPU 지원 클러스터를 테스트하려면 Kubernetes 설명서의 cuda-vector-add 예제용 포드 매니페스트를 생성하고 배포합니다. 컨테이너는 GPU를 사용하여 CUDA 계산을 다운로드, 실행, 수행합니다.
-
이름이
cuda-vector-add.yaml인 파일을 생성하고 다음을 추가합니다.apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
파일을 적용합니다.
kubectl apply -f cuda-vector-add.yaml -
실행합니다.
kubectl get po cuda-vector-add출력은 다음과 비슷합니다.
cuda-vector-add 0/1 Completed 0 91s -
실행합니다.
kubectl logs cuda-vector-add출력은 다음과 비슷합니다.
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
워크로드 클러스터를 Edge 사이트에 배포
Tanzu Kubernetes Grid v1.6+는 워크로드 클러스터를 Edge VMware ESXi 호스트에 배포하는 것을 지원합니다. 이러한 방식을 사용하여 중앙 관리 클러스터에서 모두 관리되는 여러 위치에서 많은 Kubernetes 클러스터를 실행할 수 있습니다.
토폴로지: 단일 제어부 노드와 하나 또는 두 개의 호스트만 사용하여 운영 환경에서 Edge 워크로드 클러스터를 실행할 수 있습니다. 그러나 CPU, 메모리, 네트워크 대역폭을 덜 사용하지만 표준 운영 Tanzu Kubernetes Grid 클러스터의 복원력 및 복구 특성은 동일하지 않습니다. 자세한 내용은 VMware Tanzu Edge 솔루션 참조 아키텍처 1.0을 참조하십시오.
로컬 레지스트리: 통신 지연을 최소화하고 복원력을 최대화하려면 각 Edge 클러스터에 자체 로컬 Harbor 컨테이너 레지스트리가 있어야 합니다. 이 아키텍처에 대한 개요는 아키텍처 개요의 컨테이너 레지스트리를 참조하십시오. 로컬 Harbor 레지스트리를 설치하려면 vSphere에 오프라인 Harbor 레지스트리 배포를 참조하십시오.
시간 초과: 또한 Edge 워크로드 클러스터의 관리 클러스터가 기본 데이터 센터에 원격인 경우 관리 클러스터가 워크로드 클러스터 시스템에 연결하기에 충분한 시간을 허용하도록 특정 시간 초과를 조정해야 할 수 있습니다. 이러한 시간 초과를 조정하려면 아래의 지정 지연 시간을 처리하기 위한 Edge 클러스터의 시간 초과 적용을 참조하십시오.
더 높은 지연 시간을 처리하기 위해 Edge 클러스터에 대한 시간 초과 확장
관리 클러스터가 Edge 사이트에서 실행되는 워크로드 클러스터를 원격으로 관리하거나 20개 이상의 워크로드 클러스터를 관리하는 경우 클러스터 API가 일시적으로 오프라인 상태이거나 원격 관리 클러스터와 통신하는 데 12분 이상 소요될 수 있는 시스템을 차단하거나 제거하지 않도록 특정 시간 초과를 조정할 수 있습니다(특히 인프라가 미프로비저닝된 경우).
Edge 클러스터가 제어부와 통신할 수 있는 추가 시간을 제공하기 위해 조정할 수 있는 세 가지 설정이 있습니다.
-
MHC_FALSE_STATUS_TIMEOUT:Ready조건이 12분 넘게False로 유지되는 경우, 가령 기본12m를40m으로 연장하여MachineHealthCheck컨트롤러가 시스템을 다시 생성하지 못하도록 합니다. 시스템 상태 점검에 대한 자세한 내용은 Tanzu Kubernetes 클러스터를 위해 시스템 상태 점검 구성을 참조하십시오. -
NODE_STARTUP_TIMEOUT: 기본20m를 예로 들어60m으로 연장하여MachineHealthCheck컨트롤러가 새 시스템이 클러스터에 가입하지 못하도록 차단하는 것을 방지합니다. 이는 시작하는 데 20분 이상 걸렸기 때문에 비정상으로 간주됩니다. -
etcd-dial-timeout-duration:capi-kubeadm-control-plane-controller-manager매니페스트에서 기본10m를 예로 들어40s로 연장하여 관리 클러스터의etcd클라이언트가 워크로드 클러스터에서etcd상태를 스캔하는 동안 영구적으로 실해하지 않도록 합니다. 관리 클러스터는 시스템 상태의 척도로etcd에 연결하는 기능을 사용합니다. 예:-
터미널에서 다음을 실행합니다.
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
--etcd-dial-timeout-duration값을 변경합니다.- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
또한 다음도 참고할 수 있습니다.
-
capi-kubedm-control-plane-manager: 워크로드 클러스터에서 어떻게든 "분할"이 되면 워크로드 클러스터에서
etcd를 정확하게 모니터링할 수 있도록 새 노드로 반송해야 할 수 있습니다. -
TKG의 Pinniped 구성은 모두 워크로드 클러스터가 관리 클러스터에 연결되어 있다고 가정합니다. 연결이 끊긴 경우 워크로드 포드가 관리 또는 서비스 계정을 사용하여 Edge 사이트의 API 서버와 통신하는지 확인해야 합니다. 그렇지 않으면 관리 클러스터와의 연결이 끊어지면 Edge 사이트가 Pinniped를 통해 로컬 워크로드 API 서버로 인증할 수 없게 됩니다.
