Telegraf에서 수집한 감독자 메트릭을 사용자 지정 관찰 가능성 플랫폼으로 스트리밍하는 방법을 알아봅니다. Telegraf는 감독자에서 기본적으로 사용하도록 설정되며 Kubernetes API 서버, VM 서비스, Tanzu Kubernetes Grid 등과 같은 감독자 구성 요소에서 Prometheus 형식의 메트릭을 수집합니다. vSphere 관리자는 수집된 감독자 메트릭을 보고 분석하도록 VMware Aria Operations for Applications, Grafana 등과 같은 관찰 가능성 플랫폼을 구성할 수 있습니다.
Telegraf는 다양한 시스템, 데이터베이스 및 IoT에서 메트릭을 수집하고 전송하기 위한 서버 기반 에이전트입니다. 각 감독자 구성 요소는 Telegraf가 연결되는 끝점을 노출합니다. 그런 다음 Telegraf는 수집된 메트릭을 원하는 관찰 가능성 플랫폼으로 전송합니다. Telegraf가 지원하는 출력 플러그인을 감독자 메트릭을 집계하고 분석하기 위한 관찰 가능성 플랫폼으로 구성할 수 있습니다. 지원되는 출력 플러그인은 Telegraf 설명서를 참조하십시오.
다음 구성 요소는 Telegraf가 연결하고 메트릭을 수집하는 끝점을 노출합니다. Kubernetes API 서버, etcd, kubelet, Kubernetes 컨트롤러 관리자, Kubernetes 스케줄러, Tanzu Kubernetes Grid, VM 서비스, VM 이미지 서비스, NCP(NSX Container Plug-in), CSI(Container Storage Interface), 인증서 관리자, NSX 및 CPU, 메모리, 스토리지와 같은 다양한 호스트 메트릭.
Telegraf 포드 및 구성 보기
Telegraf는 감독자의 vmware-system-monitoring 시스템 네임스페이스에서 실행됩니다. Telegraf 포드 및 ConfigMaps를 보려면:
- vCenter Single Sign-On 관리자 계정으로 감독자 제어부에 로그인합니다.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- 다음 명령을 사용하여 Telegraf 포드를 봅니다.
kubectl -n vmware-system-monitoring get pods
결과 포드는 다음과 같습니다.telegraf-csqsl telegraf-dkwtk telegraf-l4nxk
- 다음 명령을 사용하여 Telegraf ConfigMaps를 봅니다.
kubectl -n vmware-system-monitoring get cm
결과 ConfigMaps는 다음과 같습니다.default-telegraf-config kube-rbac-proxy-config kube-root-ca.crt telegraf-config
default-telegraf-configConfigMap은 기본 Telegraf 구성을 보유하며 읽기 전용입니다. 파일이 손상되었거나 기본값으로 복원하려는 경우 폴백 옵션으로 사용하여telegraf-config의 구성을 복원할 수 있습니다. 편집할 수 있는 유일한 ConfigMap은telegraf-config이며, Telegraf 에이전트에 메트릭을 전송하는 구성 요소와 플랫폼에 대해 정의합니다. telegraf-configConfigMap을 봅니다.kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
inputs 섹션은 Telegraf가 메트릭은 물론 메트릭 유형을 수집하는
감독자 구성 요소의 모든 끝점을 정의합니다. 예를 들어 다음 입력은 Kubernetes API 서버를 끝점으로 정의합니다.
[[inputs.prometheus]]
# APIserver
## An array of urls to scrape metrics from.
alias = "kube_apiserver_metrics"
urls = ["https://127.0.0.1:6443/metrics"]
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# Dropping metrics as a part of short term solution to vStats integration 1MB metrics payload limit
# Dropped Metrics:
# apiserver_request_duration_seconds
namepass = ["apiserver_request_total", "apiserver_current_inflight_requests", "apiserver_current_inqueue_requests", "etcd_object_counts", "apiserver_admission_webhook_admission_duration_seconds", "etcd_request_duration_seconds"]
# "apiserver_request_duration_seconds" has _massive_ cardinality, temporarily turned off. If histogram, maybe filter the highest ones?
# Similarly, maybe filters to _only_ allow error code related metrics through?
## Optional TLS Config
tls_ca = "/run/secrets/kubernetes.io/serviceaccount/ca.crt"
alias 속성은 메트릭이 수집되는 구성 요소를 나타냅니다. namepass 속성은 Telegraf 에이전트에서 각각 노출되고 수집되는 구성 요소 메트릭을 지정합니다.
telegraf-config ConfigMap에는 이미 광범위한 메트릭이 포함되어 있지만 그래도 추가 메트릭을 정의할 수 있습니다. Kubernetes 시스템 구성 요소에 대한 메트릭 및 Kubernetes 메트릭 참조를 참조하십시오.
Telegraf에 대한 관찰 가능성 플랫폼 구성
telegraf-config의 outps 섹션에서는 Telegraf가 수집한 메트릭을 스트리밍하는 위치를 구성합니다. outputs.file, outputs.wavefront, outputs.prometheus_client 및 outps-https와 같은 몇 가지 옵션이 있습니다. outps-https 섹션에서는 감독자 메트릭의 집계 및 모니터링에 사용할 관찰 가능성 플랫폼을 구성할 수 있습니다. 둘 이상의 플랫폼에 메트릭을 보내도록 Telegraf를 구성할 수 있습니다. telegraf-config ConfigMap을 편집하고 감독자 메트릭을 보기 위한 관찰 가능성 플랫폼을 구성하려면 다음 단계를 수행합니다.
- vCenter Single Sign-On 관리자 계정으로 감독자 제어부에 로그인합니다.
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
telegraf-configConfigMap을 로컬 kubectl 폴더에 저장합니다.kubectl get cm telegraf-config -n vmware-system-monitoring -o jsonpath="{.data['telegraf\.conf']}">telegraf.conf이전 버전의 파일로 복원할 경우를 대비하여 변경하기 전에
telegraf-configConfigMap을 버전 제어 시스템에 저장해야 합니다. 기본 구성으로 복원하려는 경우default-telegraf-configConfigMap의 값을 사용할 수 있습니다.- VIM과 같은 텍스트 편집기를 사용하여 선택한 관찰 가능성 플랫폼의 연결 설정으로
outputs.http섹션을 추가합니다.vim telegraf.config
다음 섹션의 주석 처리를 직접 제거하고 그에 따라 값을 편집하거나 필요에 따라 새outputs.http섹션을 추가할 수 있습니다.#[[outputs.http]] # alias = "prometheus_http_output" # url = "<PROMETHEUS_ENDPOINT>" # insecure_skip_verify = <PROMETHEUS_SKIP_INSECURE_VERIFY> # data_format = "prometheusremotewrite" # username = "<PROMETHEUS_USERNAME>" # password = "<PROMETHEUS_PASSWORD>" # <DEFAULT_HEADERS>예를 들어 Grafana에 대한outputs.http구성은 다음과 같습니다.[[outputs.http]] url = "http://<grafana-host>:<grafana-metrics-port>/<prom-metrics-push-path>" data_format = "influx" [outputs.http.headers] Authorization = "Bearer <grafana-bearer-token>"
Telegraf에서 대시보드를 구성하고 메트릭을 사용하는 방법에 대한 자세한 내용은 Telegraf에서 Grafana로 메트릭 스트리밍을 참조하십시오.
그리고 다음은 VMware Aria Operations for Applications (이전 Wavefront)의 예입니다.[[outputs.wavefront]] url = "http://<wavefront-proxy-host>:<wavefront-proxy-port>"메트릭을 Aria Operations for Applications에 수집할 때 권장되는 방법은 프록시를 사용하는 것입니다. 자세한 내용은 Wavefront 프록시을 참조하십시오.
- 감독자의 기존
telegraf-config파일을 로컬 폴더에서 편집한 파일로 교체합니다.kubectl create cm --from-file telegraf.conf -n vmware-system-monitoring telegraf-config --dry-run=client -o yaml | kubectl replace -f -
- 새 구성이 성공적으로 저장되었는지 확인합니다.
- 새 telegraf-config ConfigMap을 살펴봅니다.
kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
- 모든 Telegraf 포드가 가동되어 실행 중인지 확인합니다.
kubectl -n vmware-system-monitoring get pods
- 일부 Telegraf 포드가 실행되고 있지 않은 경우 해당 포드에 대한 Telegraf 로그를 확인하여 문제를 해결합니다.
kubectl -n vmware-system-monitoring logs <telegraf-pod>
- 새 telegraf-config ConfigMap을 살펴봅니다.
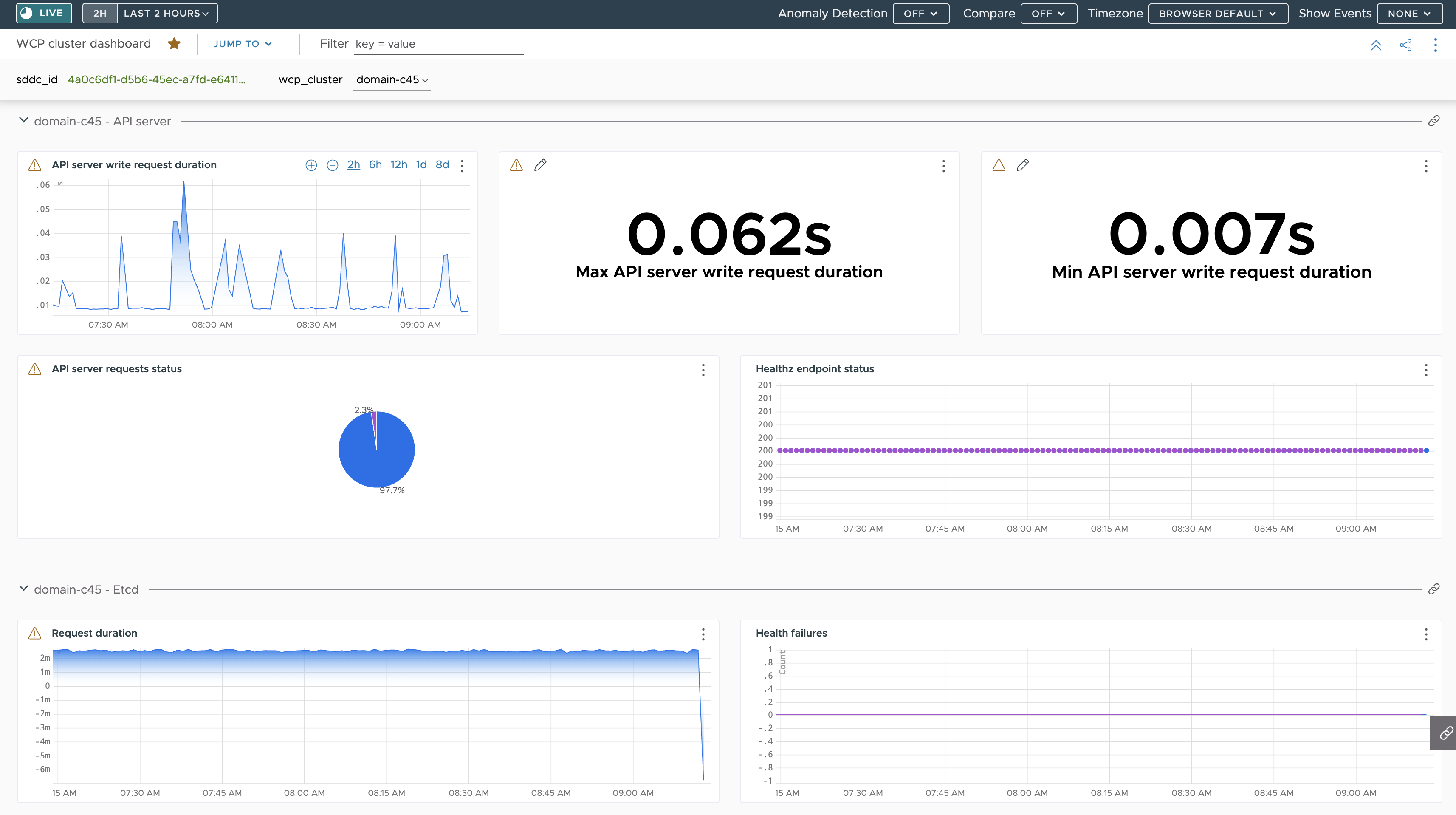
예시 Operations for Applications 대시보드
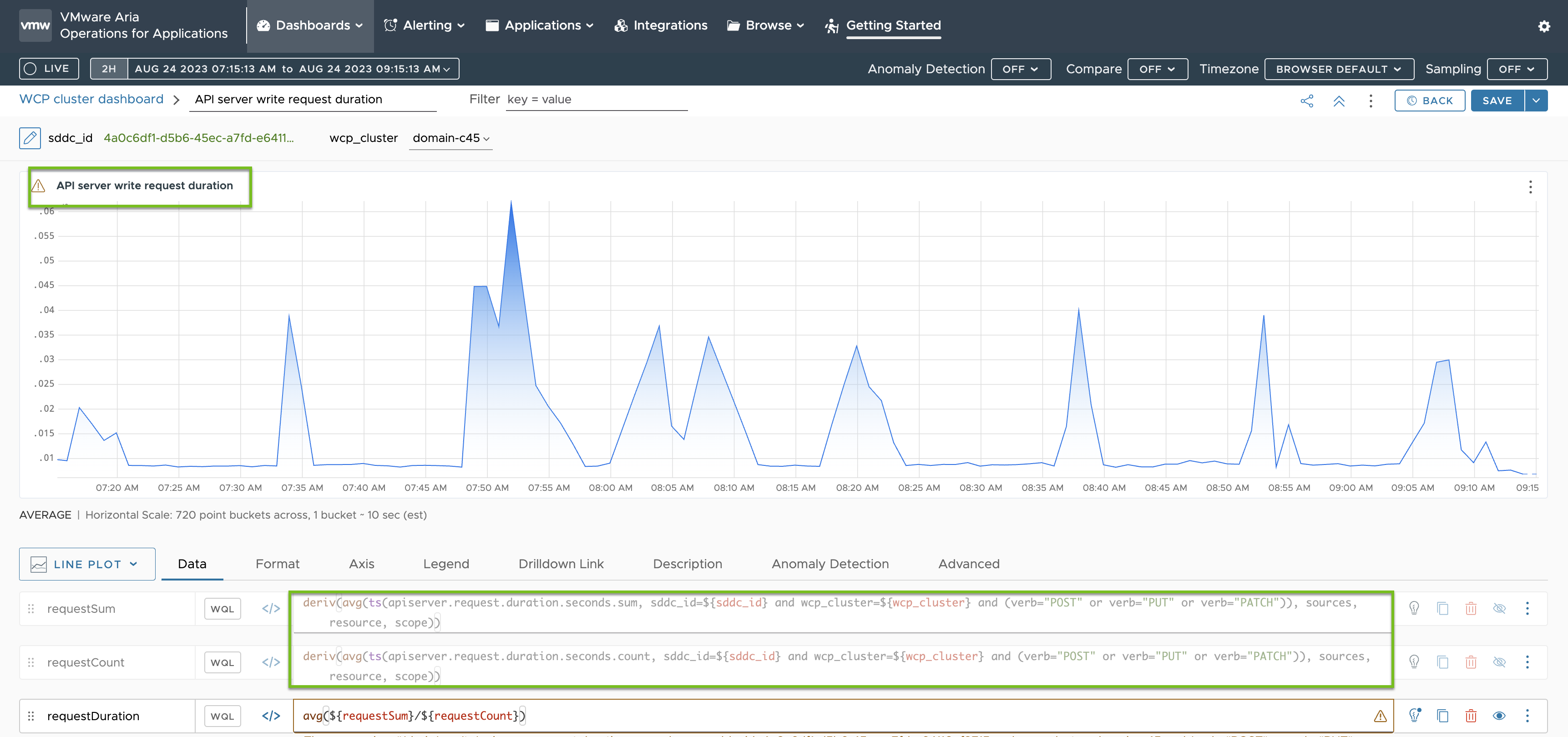
다음은 Telegraf를 통해 감독자의 API 서버 및 etcd에서 수신된 메트릭에 대한 요약을 보여주는 대시보드입니다.
API 서버 쓰기 요청 기간에 대한 메트릭은 녹색으로 강조 표시된 것처럼 telegraf-config ConfigMap에 지정된 메트릭을 기반으로 합니다.