









클러스터 경합 대시보드는 vSphere 클러스터 성능에 대한 기본 대시보드입니다. VMware 관리자나 설계자를 위해 설계되었습니다. 모니터링 및 문제 해결 모두에 사용할 수 있습니다. 성능 문제가 있다고 판단되면 클러스터 활용률 대시보드를 사용하여 경합이 높은 활용률로 인해 발생하는지 확인합니다.
설계 시 고려 사항
이 대시보드는 표준 운영 절차(SOP)의 일부로 사용됩니다. 매일 사용하도록 설계되었으므로 보기는 최근 24시간 동안의 데이터를 표시하도록 설정됩니다. 대시보드는 선택한 데이터 센터의 가상 시스템에 대한 성능 메트릭을 제공합니다.
클러스터 활용률은 클러스터 경합 대시보드에 표시되지 않습니다. 두 가지 개념(활용률 및 경합)을 구분해야 합니다. 성능 및 용량은 두 개별 팀에서 관리하는 다른 개념입니다. CPU와 메모리도 별도로 표시됩니다. 다른 쪽에 문제가 없어도 한쪽에 문제가 있을 수 있습니다. 메모리의 오버 커밋 비율이 더 낮은 경향이 있으므로 CPU가 더 일반적입니다.
모든 성능 관리 대시보드 간의 공통 설계 고려 사항을 보려면 성능 대시보드을(를) 참조하십시오.
대시보드 사용 방법
- 평균 클러스터 성능(%)입니다.
- 이는 전체 IaaS에 대한 기본 KPI입니다. 이는 IaaS가 5분마다 수행되는 방식을 보여 주기 때문에 전반적인 성능의 추세 보기를 제공합니다.
- 메트릭 자체는 단순히 클러스터 KPI/성능(%) 메트릭의 평균입니다. 이 성능 메트릭은 클러스터에 있는 모든 실행 중인 VM에서 메트릭 위반의 VM 성능/KPI 수를 평균으로 계산합니다. 따라서 100%의 값이면 클러스터에서 실행 중인 모든 VM이 잘 처리됨을 의미합니다.
- 이 KPI는 환경에서 실행 중인 모든 VM을 고려하기 때문에 숫자는 안정적이어야 합니다. 실생활의 유추는 증권 시장 인덱스입니다. 개별 주식은 불안할 수 있지만 전체 인덱스는 5분 주기로 상대적으로 안정적어어야 합니다.
- 메트릭의 상대적 이동은 메트릭의 절대 값만큼 중요합니다. 절대 값은 사용자가 원한 만큼 높지 않을 수 있지만 오랜 시간 동안 불만이 없는 경우 이를 개선하기 위한 긴급한 비즈니스 정당성이 없습니다.
- 클러스터 성능입니다.
- 지난 한 주 동안 가장 적게 작동하는 클러스터를 기준으로 정렬된 모든 클러스터를 나열합니다. 기간은 변경할 수 있습니다.
- 최악의 성능에는 해당 기간 동안 가장 낮은 숫자가 표시됩니다. vRealize Operations는 5분마다 데이터를 수집하므로 일주일에 2016개(12 x 24 x 7)의 데이터 지점이 있습니다. 이 열에는 2016개의 데이터 지점 중 최악의 지점이 표시됩니다.
- 2016개의 데이터 지점 중 단일 숫자는 다른 수를 통해 보완되어야 할 필요가 있는 이상 값이 될 수 있는 경우가 있습니다. 논리적 선택은 이러한 숫자의 평균입니다. 평균 성능이 낮은 경우에는 많은 수의 기준이 낮아야 합니다. 평균을 기다리면 작업에 지연이 발생하고 불만이 증가합니다. 성능 모니터링에 대해 95번째 백분위 수는 평균보다 더 나은 요약입니다.
- 클러스터는 100%로 작동하고 계획된 대로 기능을 수행해야 합니다.
- 표에서 클러스터를 선택합니다.
- 모든 상태 차트에는 선택한 클러스터의 KPI가 표시됩니다.
- 성능에 대해 성능 문제의 깊이와 폭을 모두 표시하는 것이 중요합니다. 하나 또는 두 개의 VM에 영향을 미치는 문제에는 클러스터의 모든 VM에 영향을 미치는 문제와 다른 문제 해결이 필요합니다.
- 깊이는 모든 VM 카운터 중에서 최악을 보고하여 표시됩니다. 따라서 실행 중인 모든 VM 간의 VM CPU 준비, VM 메모리 경합 및 VM 디스크 지연 시간의 가장 높은 값이 표시됩니다. 최악의 수가 양호하면 VM의 나머지 부분을 볼 필요가 없습니다.
- 수천 개의 VM이 포함된 대형 클러스터의 경우 VM 집단의 99.9%가 양호하지만 단일 VM이 성능 문제를 겪고 있을 수 있습니다. 깊이 카운터는 대부분의 VM이 정상임을 보고하지 않을 수 있습니다. 최악만 보고합니다. 여기에서 폭 카운터가 등장합니다.
- 폭 카운터는 성능 문제가 발생한 VM 집단의 백분율을 보고합니다. 임계값은 초기 주의를 제공하고 사전 작업을 사용하도록 설정하는 것이 목표이므로 엄격한 것으로 설정됩니다.
참고 사항
클러스터의 VM이 성능이 저하되는 반면 클러스터 활용률이 낮을 수 있습니다. 한 가지 주요한 이유는 클러스터 활용률이 제공자 계층(ESXi)을 확인하는 반면, 성능은 개별 소비자(VM)를 확인하기 때문입니다. 다음 표에는 다양한 가능한 이유가 나와 있습니다.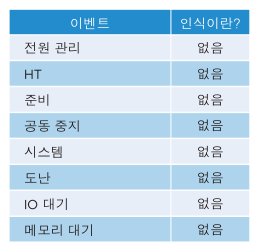
성능 관리 관점에서 vSphere 클러스터는 리소스의 가장 작은 논리적 구축 블록입니다. 리소스 풀 및 VM 호스트 선호도는 더 작은 조각을 제공할 수 있지만, 운영면에서 복잡하며 IaaS 서비스의 약속된 품질을 제공할 수 없습니다. 리소스 풀은 구별된 서비스 클래스를 제공할 수 없습니다. 예를 들어, SLA는 골드가 200% 더 청구되기 때문에 실버보다 두 배 더 빠르다고 명시합니다. 리소스 풀은 골드에 두 배 더 많은 공유를 제공할 수 있습니다. 해당 추가 공유가 CPU 준비의 절반으로 해석되는지 여부는 솔직히 확인할 수 없습니다.
DRS 자동화 수준과 같은 특정 설정이 지정되고 리소스 풀이 많으면 영향을 줄 수 있습니다. 선택한 클러스터의 관련 속성을 표시하기 위해 속성 위젯을, 리소스 풀을 표시하기 위해 관계 위젯을 추가하는 것을 고려하십시오.
많은 클러스터를 포함하는 대규모 환경에서는 목록을 보다 쉽게 관리할 수 있도록 그룹화를 추가합니다. 서비스 클래스별로 그룹화하면 중요한 클러스터에 더 집중할 수 있습니다.
