









A funcionalidade de recuperação após desastre (DR) do SASE Orchestrator impede a perda de dados armazenados e resume os serviços do SASE Orchestrator em caso de falha do sistema ou da rede.
- O objetivo do tempo de recuperação (RTO) depende, portanto, de uma ação explícita por parte do operador para acionar a promoção do Orchestrator em standby.
- O objetivo do ponto de recuperação (RPO), no entanto, é essencialmente zero, independentemente do tempo de recuperação, porque toda a configuração é instantaneamente replicada. Os dados de monitorização que teriam sido recolhidos durante a falha são colocados em cache nos Edges e Gateways enquanto aguardam a promoção do Orchestrator em standby.
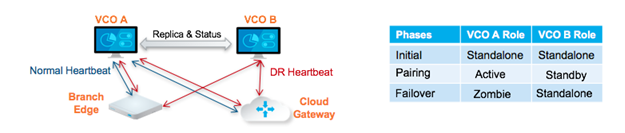
Par ativo/standby
Numa implementação DR do SASE Orchestrator, são configurados dois sistemas do SASE Orchestrator idênticos como um par ativo/standby. O operador pode ver o estado de prontidão da DR através da IU Web em qualquer um dos servidores. Os Edges e os gateways estão cientes de ambos os SASE Orchestrators e, embora recebam alterações de configuração apenas a partir do SASE Orchestrator ativo, enviam periodicamente heartbeats da DR para ambos os sistemas para comunicar a respetiva vista de ambos os servidores e para consultar o estado do sistema DR. Quando o operador aciona uma recuperação automática, os Edges e Gateways são informados da alteração no próximo heartbeat da DR.
Estados da DR
Na vista de um operador, bem como dos Edges e Gateways, um SASE Orchestrator tem um dos quatro estados DR:
| Estado DR | Descrição |
|---|---|
| Autónomo | Nenhuma DR configurada. |
| Ativo | DR configurada, a atuar como o servidor principal do SASE Orchestrator. |
| Standby | DR configurada, a atuar como uma réplica inativa do servidor do SASE Orchestrator. |
| Zombie | DR anteriormente configurada e ativa, mas já não atua como ativa ou em standby. |
Operação de tempo de execução
Quando a DR está configurada, o servidor em standby é executado num modo limitado, bloqueando todas as chamadas da API, exceto as relacionadas com o estado e os heartbeats da DR. Quando o operador invoca uma recuperação automática, o servidor em standby é promovido para se tornar totalmente operacional como um servidor autónomo. O servidor anteriormente ativo passará automaticamente para um estado Zombie se for reativo e visível a partir do servidor em standby promovido. No estado Zombie, os serviços de configuração de gestão estão bloqueados e qualquer contacto nos Edges e gateways que não tenham transitado para o novo SASE Orchestrator ativo são redirecionados para o servidor promovido.
Configurar a replicação do SASE Orchestrator
São necessárias duas instâncias SASE Orchestrator instaladas para iniciar a replicação.
- O Orchestrator em standby selecionado é colocado num estado
STANDBY_CANDIDATE, permitindo que seja configurado pelo servidor ativo. - O servidor ativo recebe o endereço e as credenciais do Orchestrator em standby e entra no estado
ACTIVE_CONFIGURING.
STANDBY_CONFIG_RQST passa de ativo para em standby, os dois servidores são sincronizados através das transições do estado.
- O fuso horário do gateway deve ser definido para Etc/UTC. Utilize o seguinte comando para visualizar o fuso horário de NTP.
vcadmin@vcg1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vcg1-example:~$
Se o fuso horário estiver incorreto, utilize os seguintes comandos para atualizar o fuso horário.
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
- A compensação de NTP deve ser inferior ou igual a 15 milissegundos. Utilize o seguinte comando para visualizar a compensação de NTP.
sudo ntpqvcadmin@vcg1-example:~$ sudo ntpq -p remote refid st t when poll reach delay offset jitter ============================================================================== *ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033 ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000 vcadmin@vcg1-example:~$Se a compensação estiver incorreta, utilize os seguintes comandos para atualizar a compensação de NTP.
sudo systemctl stop ntp sudo ntpdate <server> sudo systemctl start ntp
- Por predefinição, está configurada uma lista de Servidores NTP no ficheiro
/etc/ntpd.conf. Os Orchestrators em que a DR precisa de ser estabelecida devem ter Internet para aceder aos Servidores NTP predefinidos e garantir que a hora está sincronizada em ambos os Orchestrators. Os clientes também podem utilizar o servidor NTP local em execução no seu ambiente para sincronizar a hora.
Configurar o Orchestrator em standby
Para configurar o Orchestrator em espera, execute os seguintes passos:
- No serviço SD-WAN do portal da empresa, clique no separador Orchestrator e, no painel esquerdo, clique no botão Replicação (Replication) para apresentar o ecrã Replicação do Orchestrator (Orchestrator Replication).
- Ative o Orchestrator em standby selecionando o botão de opção Espera (Função de replicação) [Standby (Replication Role)].
- Clique no botão Ativar para espera (Enable for Standby).
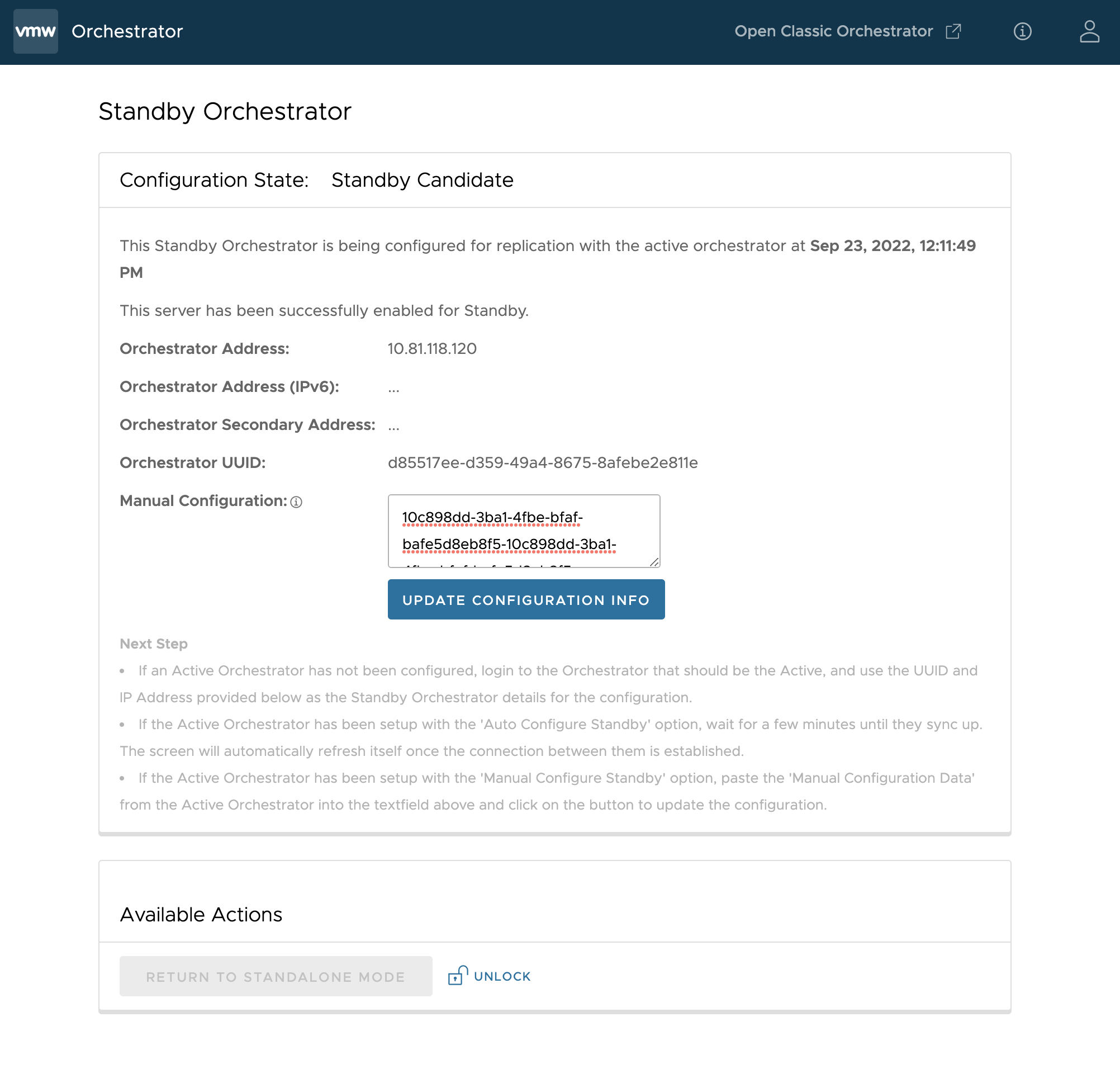
É apresentada a página Orchestrator em standby (Standby Orchestrator).
- Introduza os parâmetros de configuração manual (manual configuration) e clique no botão Atualizar informações de configuração (Update configuration info).
Depois de o Orchestrator em standby ter sido configurado para replicação, configure o Orchestrator ativo de acordo com as instruções abaixo.
Configurar o Orchestrator Ativo
Para configurar o Orchestrator ativo, selecione a função de replicação como ativa e configure o seguinte:
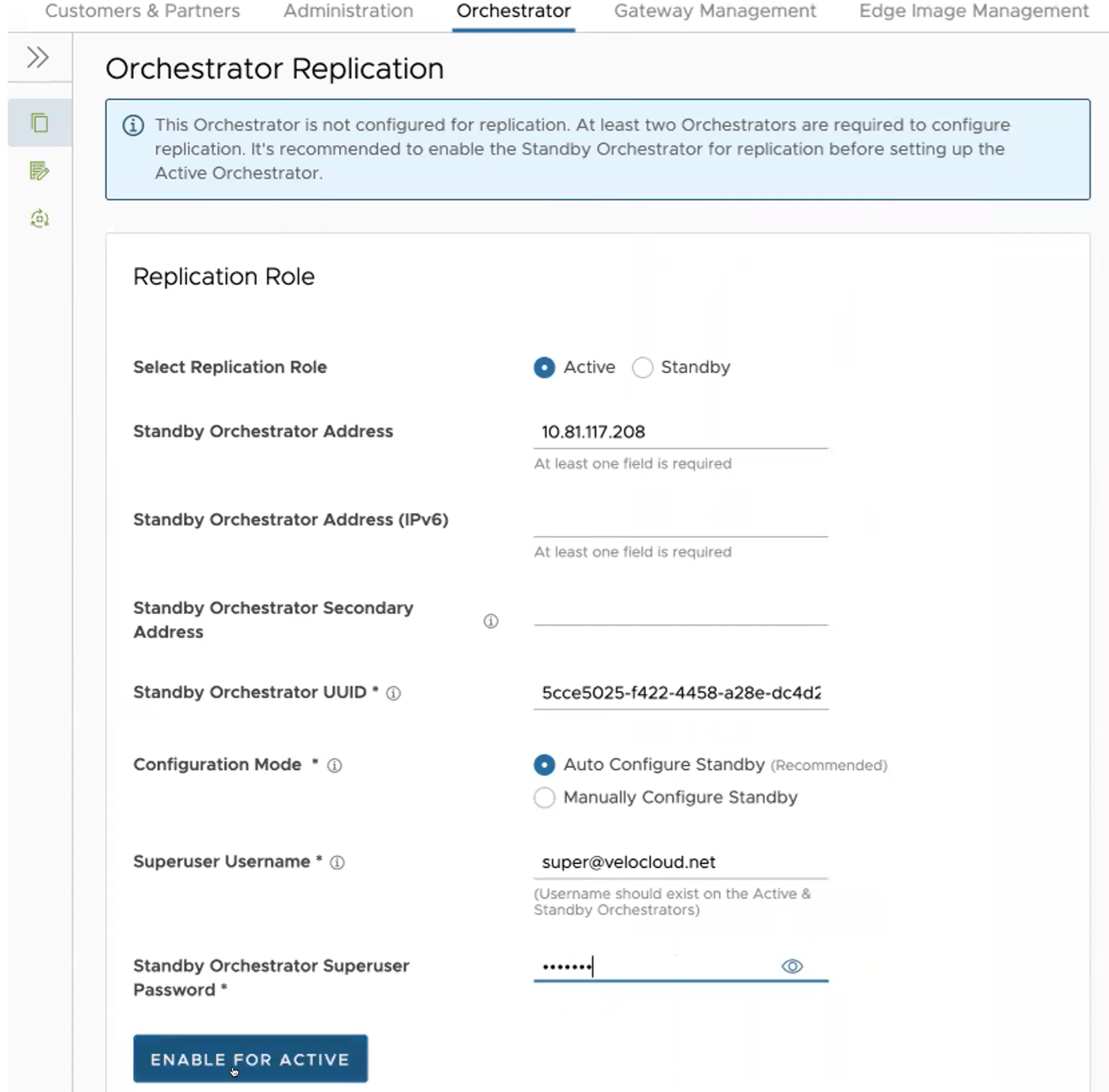
| Opção | Descrição |
|---|---|
| Selecionar função de replicação (Select Replication Role) | Selecione o botão de opção Ativa (Active) para a função de replicação. |
| Endereço do Orchestrator em standby (Standby Orchestrator Address) | Introduza o endereço IP do Orchestrator em standby primário. |
| Endereço do Orchestrator em standby (IPv6) [Standby Orchestrator Address (IPv6)] | Introduza o endereço IPv6 do Orchestrator em standby. |
| Endereço secundário do Orchestrator em standby (Standby Orchestrator Secondary Address) | Introduza o endereço da interface secundária do Orchestrator em standby. Este endereço será utilizado para replicação se o Orchestrator em standby for promovido a ativo. Os utilizadores podem adicionar o endereço IPv4/IPv6 ou FQDN aqui. |
| UUID do Orchestrator em standby (Standby Orchestrator UUID) | Introduza o UUID do Orchestrator em standby. |
| Modo de configuração (Configuration Mode) | Selecione o botão de opção Configurar automaticamente o Standby (Auto Configure Standby) ou Configurar manualmente o Standby (Manually Configure Standby) com base no requisito. Quando configurado manualmente, cole um valor de cadeia de ATIVE VCO para STANDBY_WAIT . |
| Nome de utilizador de superutilizador (Superuser Username) | Introduza o nome a apresentar para o superutilizador do Orchestrator. |
| Palavra-passe de superutilizador do Orchestrator em standby (Standby Orchestrator Superuser Password) | Introduza a palavra-passe para o superutilizador do Orchestrator. |
- Clique no botão Ativar para ativo (Enable for Ative) para ativar a função de replicação.
Quando a configuração estiver concluída, ambos os Orchestrators (em standby e ativo) estarão em sincronização.
Orchestrator em standby em sincronização
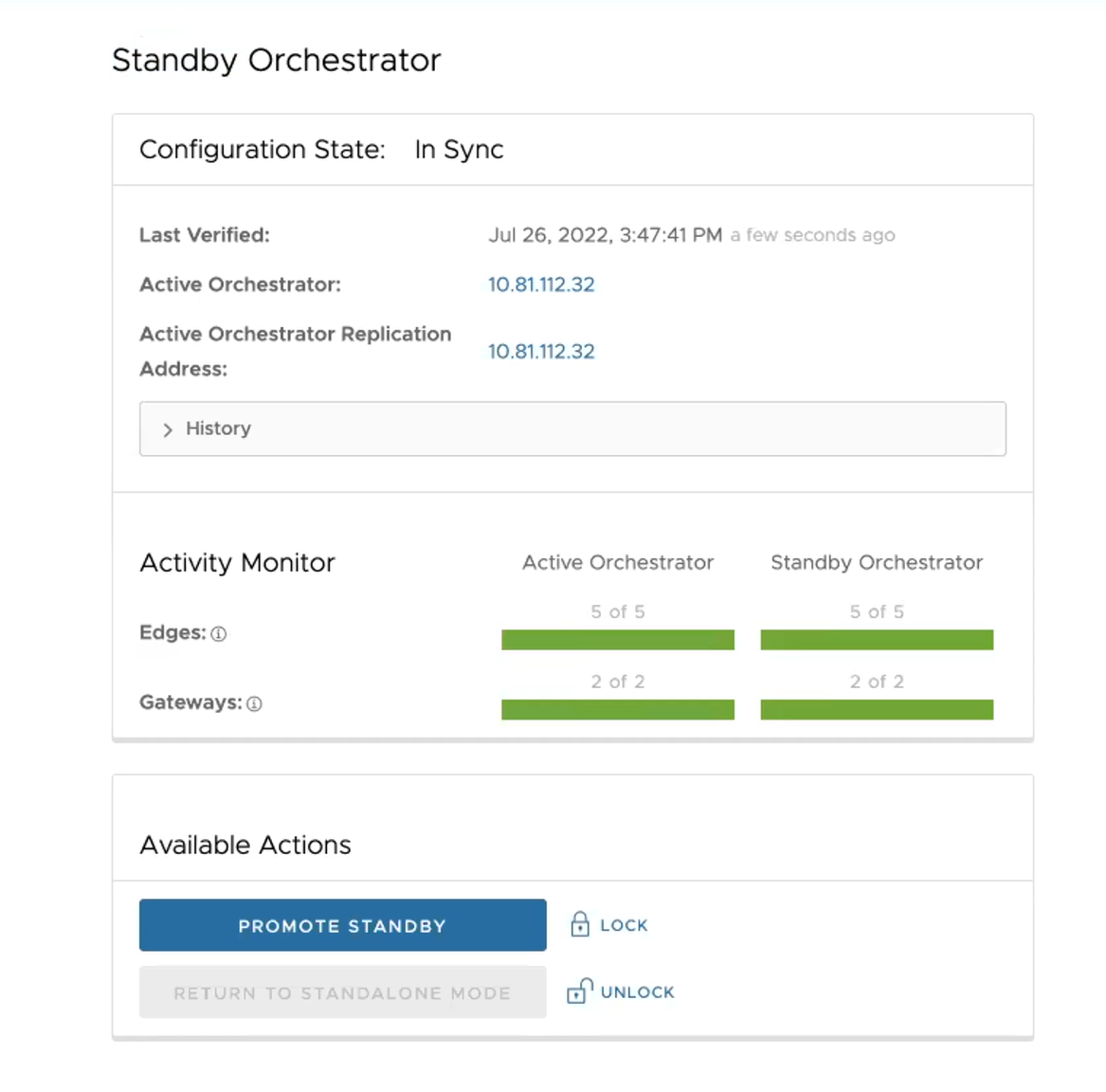
Orchestrator ativo em sincronização
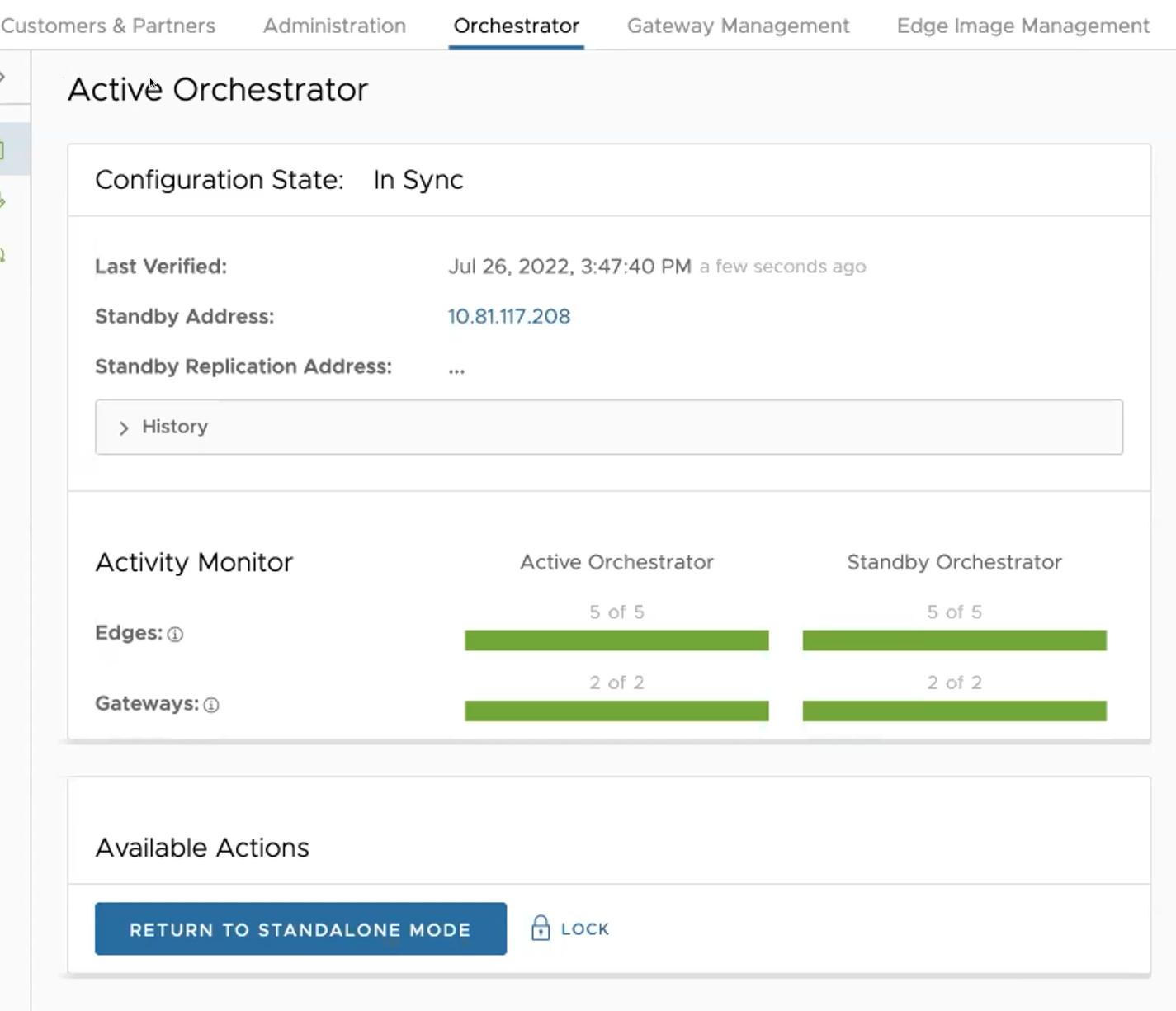
Testar a recuperação automática
Os seguintes cenários de teste de recuperação automática são recuperações automáticas forçadas, para fins de exemplo. Pode executar estas ações na área Ações disponíveis (Available Actions) dos ecrãs Ativo (Active) e Standby.
Promover um Orchestrator em standby
Esta secção descreve como promover um Orchestrator em standby.
Para promover um Orchestrator em standby, execute os passos seguintes:
- Clique na ligação desbloquear (unlock).
- Clique no botão Promover standby (Promote Standby) na área Ações disponíveis (Available Actions) no ecrã do Orchestrator em standby.
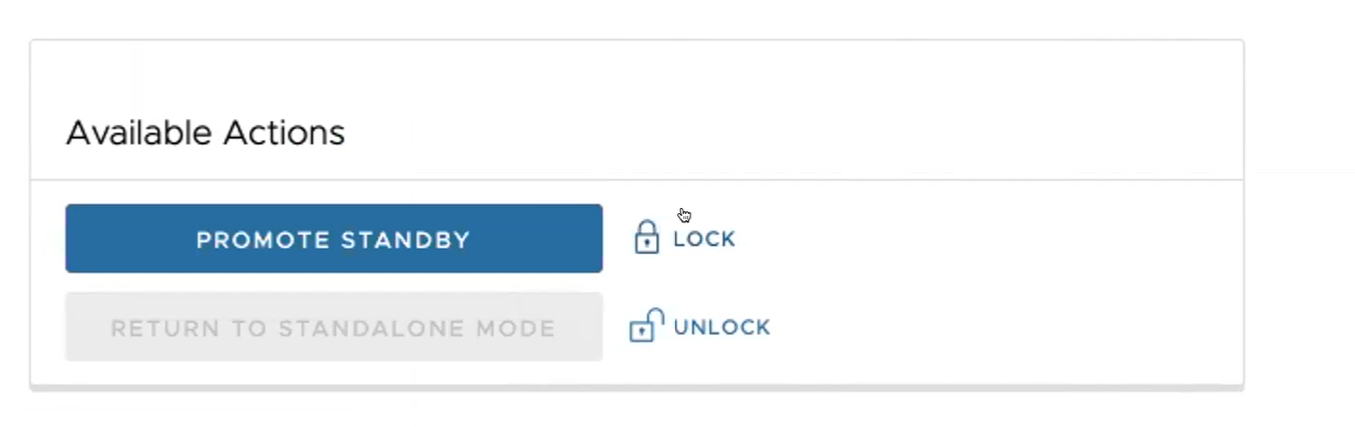
É apresentada a seguinte caixa de diálogo, a indicar que, quando promove o Orchestrator em standby, os administradores deixam de conseguir gerir o SASE Orchestrator com o Orchestrator anteriormente ativo.
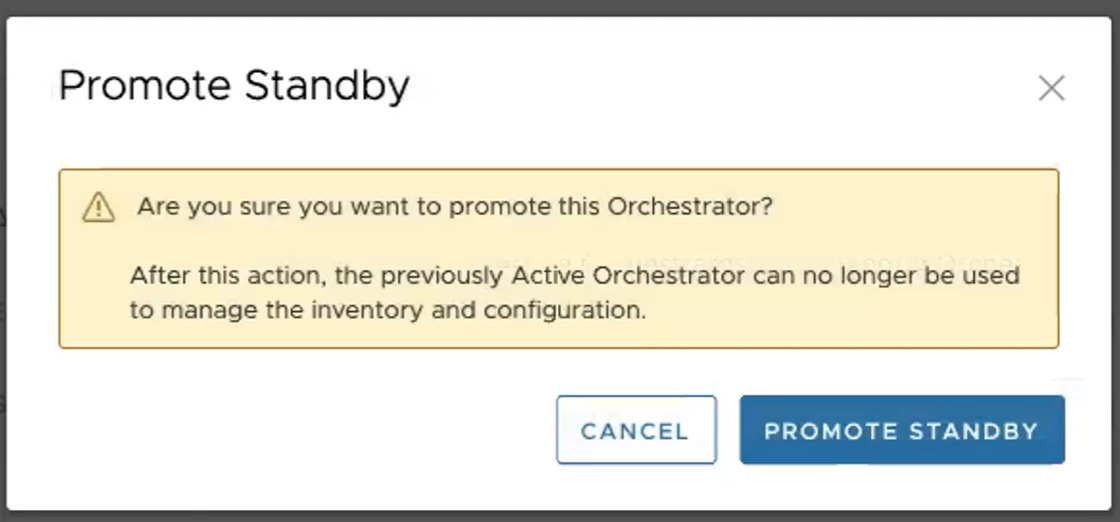
- Clique no botão Promover standby (Promote Standby) para promover o Orchestrator em standby.
- Clique em Forçar promoção do standby (Force Promote Standby) para promover o Orchestrator.
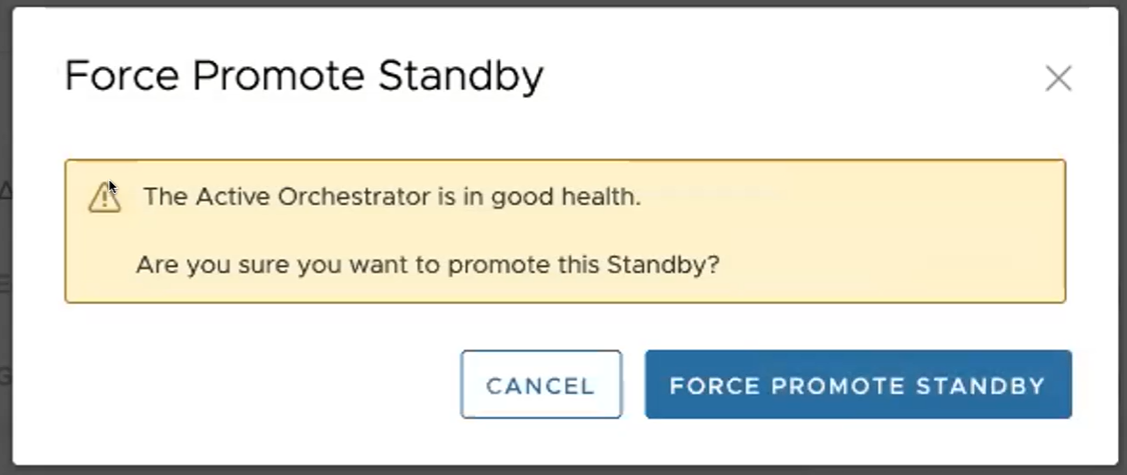
É apresentada uma caixa de diálogo final a indicar que o Orchestrator já não está em standby e será reiniciado no modo autónomo.

Quando promove um Orchestrator em standby, este é reiniciado no modo autónomo.
Se o Orchestrator em standby conseguir comunicar com o Orchestrator anteriormente ativo, instruirá o Orchestrator a entrar num estado Zombie. No estado Zombie, o Orchestrator comunica com os respetivos clientes (Edges, gateways, IU/API) que já não é ativo e que têm de comunicar com o Orchestrator recém-promovido. Se o Orchestrator em standby promovido não puder comunicar com o Orchestrator anteriormente ativo, o operador deverá, se possível, despromover manualmente o Orchestrator anteriormente ativo.
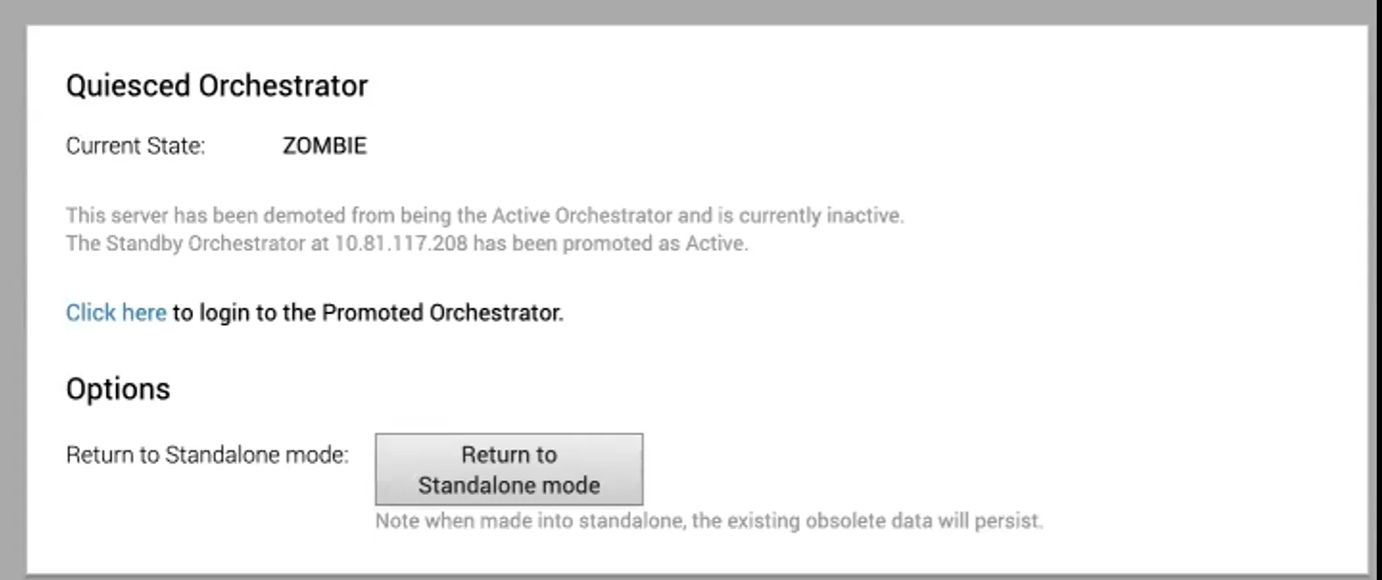
Regressar ao modo autónomo
Para regressar ao modo autónomo do Zombie, clique no botão Regressar ao modo autónomo (Return to Standalone Mode) na área Ações disponíveis (Available Actions) dos ecrãs Orchestrator ativo (Active Orchestrator) ou Orchestrator em standby (Standby Orchestrator).
O Orchestrator pode regressar ao modo autónomo no estado zombie após o tempo especificado na propriedade do sistema “vco.disasterRecovery.zombie.expirySeconds”, predefinido para 1800 segundos.
Resolução de problemas da DR do SASE Orchestrator
Esta secção descreve os estados de falha do sistema. Estes também estão listados na IU, juntamente com uma descrição mais detalhada da falha. Estão disponíveis mais informações no registo VMware.
Falhas recuperáveis
Os seguintes erros são falhas recuperáveis que podem ocorrer após a DR do SASE Orchestrator atingir um estado de sincronização. Se o problema que causa estas falhas for corrigido, a DR do SASE Orchestrator voltará automaticamente ao funcionamento normal.
FAILURE_SYNCING_FILESFAILURE_GET_STANDBY_STATUSFAILURE_MYSQL_ACTIVE_STATUSFAILURE_MYSQL_STANDBY_STATUS
Falhas irrecuperáveis
Durante a configuração da DR do SASE Orchestrator, podem ocorrer as seguintes falhas. A DR do SASE Orchestrator não recuperará automaticamente destas falhas.
FAILURE_ACTIVE_CONFIGURINGFAILURE_LAUNCHING_STANDBYFAILURE_STANDBY_CONFIGURINGFAILURE_COPYING_DBFAILURE_COPYING_FILESFAILURE_SYNC_CONFIGURINGFAILURE_GET_STANDBY_CONFIGFAILURE_STANDBY_CANDIDATEFAILURE_STANDBY_UNCONFIGFAILURE_STANDBY_PROMOTIONFAILURE_ACTIVE_DEMOTION
