A funcionalidade de recuperação após desastre (DR) do SASE Orchestrator impede a perda de dados armazenados e resume os serviços do SASE Orchestrator em caso de falha do sistema ou da rede.
- O objetivo do tempo de recuperação (RTO) depende, portanto, de uma ação explícita por parte do operador para acionar a promoção do Orchestrator em espera.
- O objetivo do ponto de recuperação (RPO), no entanto, é essencialmente zero, independentemente do tempo de recuperação, porque toda a configuração é instantaneamente replicada. Os dados de monitorização que teriam sido recolhidos durante a falha são colocados em cache nos Edges e gateways enquanto aguardam a promoção do Orchestrator em espera..
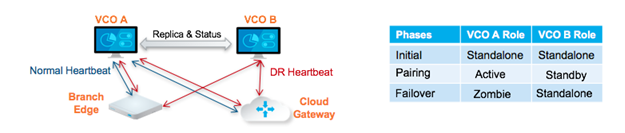
Par ativo/standby
Numa implementação DR do SASE Orchestrator, são configurados dois sistemas do SASE Orchestrator idênticos como um par ativo/standby. O operador pode ver o estado de prontidão da DR através da IU Web em qualquer um dos servidores. Os Edges e os gateways estão cientes de ambos os SASE Orchestrators e, embora recebam alterações de configuração apenas a partir do SASE Orchestrator ativo, enviam periodicamente heartbeats da DR para ambos os sistemas para comunicar a respetiva vista de ambos os servidores e para consultar o estado do sistema DR. Quando o operador aciona uma recuperação automática, os Edges e gateways são informados da alteração no próximo heartbeat da DR.
Estados da DR
Na vista de um operador, bem como de Edges e gateways, um SASE Orchestrator tem um dos quatro estados DR:
| Estado DR | Descrição |
|---|---|
| Autónomo | Nenhuma DR configurada. |
| Ativo | DR configurada, a atuar como o servidor principal do SASE Orchestrator. |
| Standby | DR configurada, a atuar como uma réplica inativa do servidor do SASE Orchestrator. |
| Zombie | DR anteriormente configurada e ativa, mas já não atua como ativa ou em espera. |
Operação de tempo de execução
Quando a DR está configurada, o servidor em standby é executado num modo limitado, bloqueando todas as chamadas da API, exceto as relacionadas com o estado e os heartbeats da DR. Quando o operador invoca uma recuperação automática, o servidor em standby é promovido para se tornar totalmente operacional como um servidor autónomo. O servidor anteriormente ativo passará automaticamente para um estado Zombie se for reativo e visível a partir do servidor em standby promovido. No estado Zombie, os serviços de configuração de gestão estão bloqueados e qualquer contacto nos Edges e gateways que não tenham transitado para o novo SASE Orchestrator ativo são redirecionados para o servidor promovido.