效能是為了確保工作負載取得必要的資源,而效能管理則很大程度上是一種消除做法。此方法將對每一層進行分割,並確定該層是否會導致任何效能問題。必須使用單一度量來指出某個特定層是否正在執行。此主要度量恰當地稱為關鍵效能指標 (KPI)。
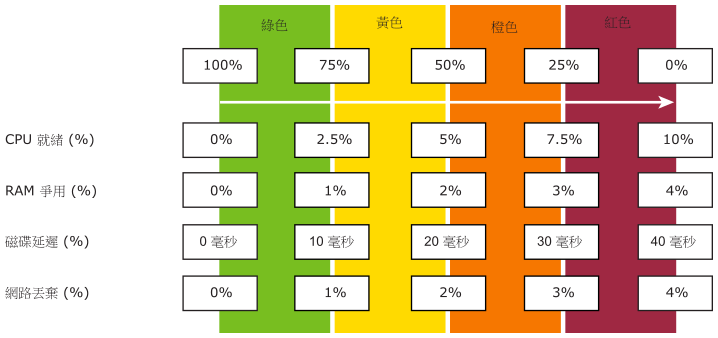
每個度量 (例如磁碟延遲) 有四個範圍:綠色、黃色、橙色和紅色。
為了簡化監控,範圍對應至 0–100%。綠色對應至 75–100%,紅色對應至 0-25%。將 100% 分為四個相等的範圍,以便每個範圍都有適當的大小區段。
透過以上技術,可以組合具有不同單位的度量。其中每個對應至相同的區段,即一個百分比。
將度量正確對應至四個範圍的邏輯需要五個度量,而不是四個。例如,在磁碟延遲中:
-
如果是 41 毫秒,則為 0% (紅色),因為紅色的上限為 40 毫秒。
-
如果是 35 毫秒,則為 12.5%,因為它介於 30 毫秒到 40 毫秒之間,並且是紅色。
-
如果是 30 毫秒,則為 25%,因為它在紅色和橙色的邊界。
將每個度量轉換為 0–100% 範圍後,使用平均值 (而非尖峰值) 得出 KPI 度量。可使用平均值避免任何度量主導 KPI 值。如果有任何度量對您的作業至關重要,則可以對其使用警示。使用平均值可反映實際情況,因為每個度量的佔比相同。
這些儀表板使用 KPI 在取用者層顯示 Horizon 工作階段的效能以及在 Horizon 基礎結構層顯示工作負載的彙總效能。這些儀表板專為 Horizon 架構設計人員或主管管理員而設計。提供了桌面平台即服務的資料中心部分的整體效能。
效能管理角度的 Horizon
為了進行效能監控和疑難排解,Horizon 類似於用戶端/伺服器架構,其中用戶端透過 WAN 網路。網路和資料中心元件彼此獨立,它們使用不同的度量集,並且必須作為一個實體進行監控。他們有自己的修復動作集。在大型企業中,網路由單獨的團隊所擁有。
Management Pack for Horizon 會單獨進行監控,以提供 KPI。

用戶端元件是效能監控的最後一個焦點,因為它本質上會像電視一樣運作。它會顯示傳輸的像素並接受簡單輸入。此外,用戶端的問題往往已隔離。但是,網路和資料中心中斷可能會影響許多使用者。
效能疑難排解的三個程序
效能管理中的三個不同程序包括:
-
規劃。可在此設定效能目標。對 vSAN 進行架構設計時,您要考慮多少毫秒的磁碟延遲?在虛擬機器層級 (而非 vSAN 層級) 測量的 10 毫秒是好的開始。
-
監控。可在此比較計劃與實際情況。事實是否與您的架構預期目標相符?如果不相符,則必須進行修正。
-
疑難排解。當事實比計劃差時執行此動作,而不是具有抱怨時執行。您不想花時間進行疑難排解,因此最好主動執行。

效能管理的兩個度量
效能的主要計數器為爭用。大多數客戶會關注使用量,因為他們擔心如果利用量很高,就會發生錯誤。這是爭用問題。爭用以不同形式呈現。它可以是佇列、延遲、捨棄、中止或內容切換。
請勿將超高使用量指標與效能問題混淆。僅由於 ESXi 主機呈現佔用、壓縮和交換情況,並不意味著您的虛擬機器存在記憶體效能問題。您根據主機為虛擬機器提供多好的服務來測量主機效能。雖然這與 ESXi 使用量有關,但效能度量不是以使用量為根據,它是根據爭用度量。
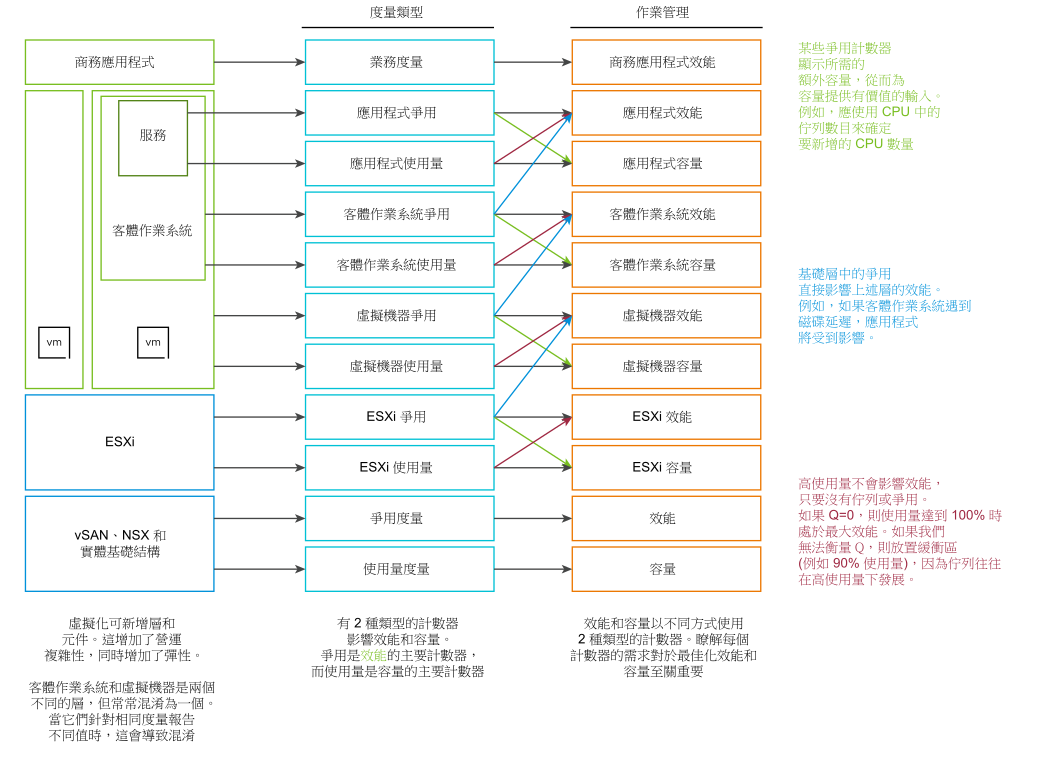
當叢集使用量較低時,叢集中的虛擬機器可能發生效能不佳的情況。其中一個主要原因是叢集使用量會查看提供者層 (ESXi),而效能則查看個別取用者 (虛擬機器)。

從效能管理的角度來看,vSphere 叢集是資源的最小邏輯建構區塊。雖然資源集區和虛擬機器主機相似性可提供較小的扇形區,但它們在運作上很複雜,而且無法提供承諾的 IaaS 服務品質。資源集區無法提供不同的服務等級。例如,您的 SLA 指出頂級桌面比一般桌面快兩倍,因為它收取的費用為 200%。資源集區可為頂級桌面提供兩倍以上的共用率。無法提前確定這些轉換為半數 CPU 就緒的共用率。
深度和廣度
主動監控需要從多個角度進行瞭解。如果某個使用者因效能問題而碰到問題時,您接下來的問題如下:
-
有多糟糕?您想要測量問題的深度。
-
有多少使用者受到影響?您想要測量問題的廣度。
第二個問題的答案會影響疑難排解的過程。是孤立事件還是普遍存在的事件?如果是孤立事件,則可以更密切地關注受影響的物件。如果是普遍存在的問題,則可以關注受影響物件之間共用的一般區域 (例如叢集、資料存放區、資源集區和主機)。
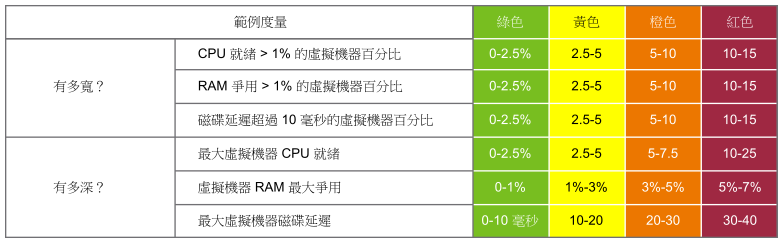
請注意,您是否沒有問什麼是平均效能?因為,在此案例中,平均值為時已晚。當平均效能不佳時,可能會影響總人數的一半。
當成員計數較大時,Count() 得到的結果比 Percentage() 更佳。例如,在具有 10 萬使用者的 VDI 環境中,五個使用者受到影響,即為 0.005%。使用計數可以更輕鬆地監控,因為它會轉換為實際情況。
整體流程
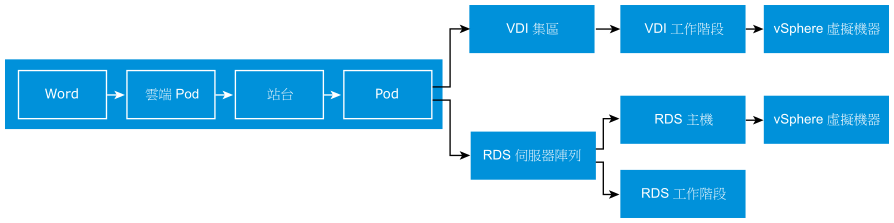
Management Pack for Horizon 儀表板未設計為孤立形式。它們會形成流程,並在您向下切入時傳遞內容。下列範例從鳥瞰視圖顯示如何向下切入至支援工作階段的基礎虛擬機器。第一個儀表板涵蓋了 Horizon 環境中的所有 Pod。您可以從中向下切入至 RDS 伺服器陣列或 VDI 集區。在每個分支中,您可以向下切入至個別工作階段。
設計考量事項
所有效能儀表板共用相同的設計原則。它們特意設計為類似,因為每個儀表板的外觀不同,因此會令人混淆。儀表板具有相同的目標。
儀表板會自上而下設計,並顯示 [摘要] 和 [詳細資料] 區段。
-
[摘要] 區段通常放置在儀表板的頂端。可提供整體情況。
-
[詳細資料] 區段置於 [摘要] 區段下方。可讓您深入瞭解特定物件。例如,如果是虛擬機器效能,則可以取得特定虛擬機器的效能詳細資料。
此外,此 [詳細資料] 區段還設計了快速內容切換功能,因為您可能會在效能疑難排解期間檢查多個物件的效能。例如,[RDS 主機效能] 儀表板可為您提供所有 RDS 主機特定資訊,您不需要變更螢幕就能查看 KPI。您可以從一個 RDS 主機移至另一個主機,不需要開啟多個視窗,就能檢視詳細資料。
從使用者介面角度來看,儀表板使用漸進式披露將資訊超載降至最低,確保網頁快速載入。只要您的瀏覽器工作階段保持作用中狀態,它就會記住您上次選取的項目。
用色彩表示含義
當使用不同的臨界值時,儀表板使用色彩來表達含義。
| 計數器 | 已使用的臨界值 |
|---|---|
| KPI | 綠色:75% - 100% 黃色:50% - 75% 橙色:25% - 50% 紅色:0% - 25% 相應地,臨界值集為 25%、50% 和 75%。 |
| 紅色範圍內的內容計數。例如,具有紅色 KPI 的 VDI 工作階段計數。 |
預期此項始終為 0,因為具有 KPI 值的 VDI 工作階段都不應在紅色範圍內。相應地,臨界值集為 1、2 和 3。 如果您想要在計數為 1 時顯示紅色,則可以將其設為 0.1、0.2 或 1。 |
預期數字顯示在綠色區域內 (75%-100%)。平均值可能不是 100%,但目標是在綠色範圍內。
用資料表表示見解
資料表只是一個清單,其中每個資料列代表一個物件,而每個資料行均顯示單一值。這會列出數百個資料列,並且能夠篩選和排序。每個儲存格值也可以採用色彩編碼。
資料表適用於提供詳細資料。但是,總而言之,主要問題是在每個儲存格只能有一個值的情況下如何隨著時間提供見解。如何深入瞭解過去的情況?例如,如何查看過去 1 週內的效能?過去七天有數千個資料點,您挑選哪一個?
VMware Aria Operations 8.2 中提供了幾個可能的選項
-
目前數字。對於顯示目前情況非常有用。但是,這並不會顯示五分鐘前發生的情況。
-
某個時段的平均值。平均值是一個延遲指標。當平均值不佳時,大約 50% 的數字可能不佳。
-
某個時段的最差值。這可能過於極端,因為它只取一個尖峰值。在某些案例中,數百個資料點中有一個數字可能為極端值。非常適用於尖峰偵測,但需要對其進行補充。
-
第 95 個百分位。這是介於平均值和最差值之間的良好中間點。針對效能監控,第 95 個百分位的摘要較平均值佳。
同時使用最差值和第 95 個百分位數字,從第 95 個百分位開始。如果這些數字相隔很多,表示最差值可能為極端值。
為提高可見度,請考慮新增第 98 個百分位,以補充第 95 個和最差值。
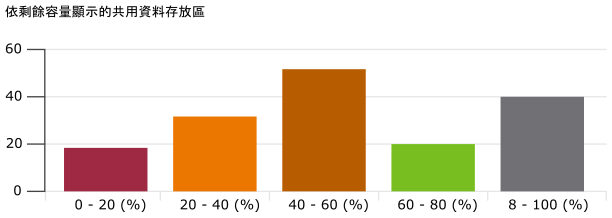
用橫條圖表示見解
分佈圖有許多形狀,而橫條圖則是最熟悉的一種。它可用於提供有關大型資料集的見解。例如,vSphere 共用資料存放區將依其剩餘容量顯示。它們分為五個值區,從最低剩餘容量到最高剩餘容量。將為每個值區指定一種色彩來表達含義。容量超過 80% 將指定為灰色,因為大量未使用的容量表示資源浪費。