









VMware Cloud on AWS Autoscaler 服務可監控 SDDC 基礎結構的健全狀況,偵測早期故障和實際故障,並透過在故障發生之前或之後取代主機來自動修復基礎結構。
AWS 基礎結構很可靠,但即使在最可靠的基礎結構中也難免會出現故障。AWS 架構可靠性支柱討論了雲端可靠性的設計原則。VMware Cloud on AWS 透過抽象化基礎結構並利用 vCenter Server 和 ESXi 的預測性故障分析功能,擴充了這些原則,可在發生故障時提供回應式修復,並提供可防止故障影響工作負載的預測性修復。
大多數自動修復程序是在背景中執行的,並且執行時不會影響現有的工作負載。自動修復可監控系統的健全狀況,並在必要時快速地將硬體新增到 SDDC,從而在發生故障或偵測到健全狀況問題時將新主機插入到叢集中,並將工作負載虛擬機器從已發生故障或即將發生故障的硬體中撤除。此外,由於所有
VMware Cloud on AWS SDDC 都使用 VMware
vSAN 和 vSphere HA,因此受主機故障影響的工作負載會自動重新放置並重新啟動。
備註: 無需為用於自動修復或計劃的維護的額外主機付費。
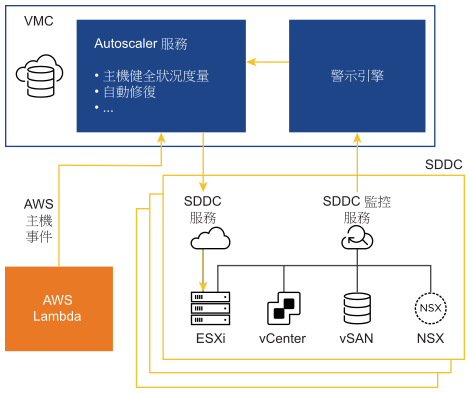
自動修復高層級架構
自動修復架構包括由 AWS 和 VMware 提供的元件。
- AWS 會向 VMware 傳送主機層級資訊,最主要的是 AWS 計劃的維護事件。Autoscaler 服務會接收這些通知,並自動修復 SDDC 內的任何問題。
- SDDC 層級的監控服務會接收來自基礎 VMware Cloud on AWS 元件的通知。
回應式修復
回應式自動修復可監控硬體故障和軟體故障,並嘗試透過多種方式修復問題。自動修復是一個內部程序,並且在不斷提升。VMware Cloud on AWS 使用者無權存取工作流程或其組態,但為了協助您更好地瞭解該工作流程,下列內容概述了目前涉及的步驟。
- 1:監控
- VMware Cloud on AWS 持續監控 SDDC 中每台主機的健全狀況。偵測到故障時,將一個事件傳送至自動修復。
- 2:等待暫時性事件
- 某些偵測到的故障可能是暫時的。例如,由於暫時性的連線問題,監控系統無法連線到主機。自動修復會等待 5 分鐘,以確定問題是否是暫時的。如果是,自動修復會返回而不執行任何動作。
- 3:新增主機
- 如果錯誤在 5 分鐘後仍未解決,自動修復會開始將新主機新增到 SDDC。以此方式預先新增主機可確保主機在需要時可用。請注意,在取代 SDDC 中的故障主機之前,不會向您收取該主機的費用。
- 4:確定故障類型並採取動作
- 主機可能會由於不同的原因發生故障,因此需要採取不同的動作。例如,仍與 vCenter Server 連線的主機上的 vSAN 磁碟故障可透過軟重新開機進行修復,而 PSOD 主機需要硬重新開機。
- 5:檢查主機健全狀況
- 下一步是檢查修復動作是否修正了主機。如果失敗的主機在軟重新開機或硬重新開機後變得狀況良好,自動修復可避免 SDDC 進一步中斷。它會收集並採取任何其他必要的動作,從而移除在步驟 3 中預先新增的新主機。
- 6:取代主機
- 如果失敗的主機無法恢復,則 Autoscaler 會移除失敗的主機,並將其取代為步驟 3 中新增的主機。將會觸發 vSphere HA 和 vSAN,並且將計算原則標籤附加至新主機。
預先修復
除了回應式修復外,Autoscaler 還會監控數個獨立源,以嘗試在故障發生之前發現故障。如果該服務確定主機可能會遇到硬體故障,則會觸發不中斷的搶先計劃的維護事件。在計劃的維護完成之前,主機仍可能會發生故障,但透過預先起始主機取代,可以最大限度地降低影響。在計劃的維護期間:
- 向叢集新增新主機。將標籤從要取代的主機複製到此新主機。
- 將失敗的主機置於維護模式並執行完整資料撤除。這會將任何虛擬機器和/或 vSAN 資料不中斷地移至叢集內的其他主機。
- 從叢集中移除失敗的主機。
Autoscaler 事件
當 Autoscaler 服務收到故障事件時,它會確定故障類型,然後執行適當的動作。SDDC 活動記錄包括所有 Autoscaler 活動,但不顯示觸發相關活動的故障事件。
- vCenter Server 事件。
-
- 為了檢查主機連線狀態而觸發事件
- ESXi 主機中斷連線或沒有回應時,會觸發事件。
- DAS 事件
-
- vSphere HA 事件:當與主節點沒有通訊或 HA 關閉時,會建立事件。(FDM)
- 當主機出現故障時,HA 系統會報告主機故障。
- vSAN 個事件
-
- 主機發生磁碟故障時。
- vSAN 主機中斷連線時。
- EDRS 事件 (非故障)
- 升級:停用 EDRS。維護活動經常需要額外主機,此主機將作為維護事件的一部分新增。在任何計劃維護期間停用 EDRS,以防止這些活動觸發縮小/擴充事件。
- AWS 事件
-
- 計劃的維護事件。來自 AWS 的通知,指出已偵測到執行個體健全狀況問題,應撤除該執行個體。
- 個人健全狀況儀表板 (PHD)。一個事件流,有助於瞭解各種硬體元件並有助於 VMware 預先發現硬體故障。
- 系統狀態檢查。監控執行個體所依賴的 AWS 系統的健全狀況。此檢查報告只有 AWS 才能修正的問題。在多數情況下,這些問題是暫時性的,無需採取任何動作。
- 執行個體狀態檢查。監控每個執行個體的軟體和網路組態。此檢查透過定期向 NIC 發出 ARP 請求來監控執行個體的可用性。除了報告 EC2 層的執行個體可用性之外。執行個體狀態檢查還會監控基礎硬體使用量,並報告網路問題、記憶體耗盡、檔案系統損毀和核心錯誤等。與系統狀態檢查不同,執行個體狀態檢查需要 VMware 互動才能解決。
- SDDC 事件
- vCenter Server 主機健全狀況。
