









NSX 支援多站台部署,進而您可從一個 NSX Manager 叢集管理所有站台。
- 災難復原
- 作用中/作用中
下圖說明災難復原部署。
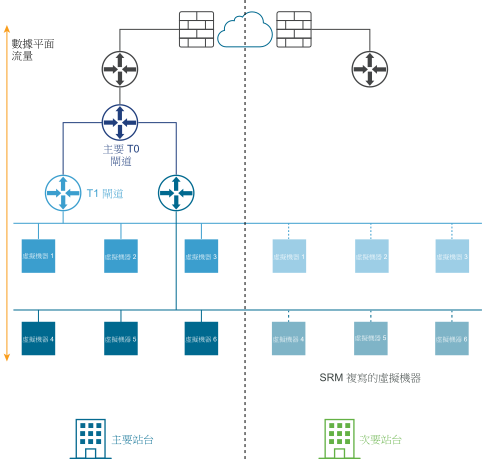
在災難復原部署中,位於主要站台的 NSX 會處理企業的網路。次要站台則會處於待命狀態,以便在主要站台發生災難性失敗時接管。
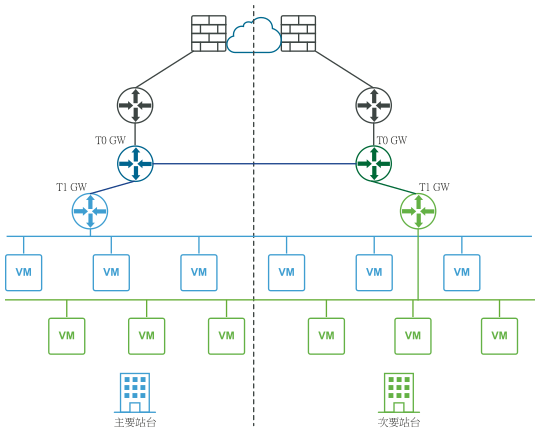
下圖說明作用中/作用中部署。
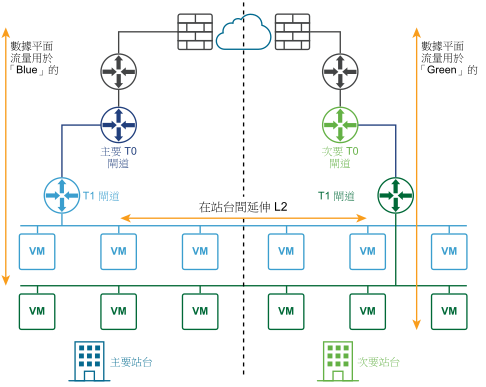
您可以為管理平面和數據平面部署自動或手動/指令碼式復原的兩個站台。
管理平面的自動復原
- 在設定的站台間具有 HA 的延伸 vCenter 叢集。
- 延伸的管理 VLAN。
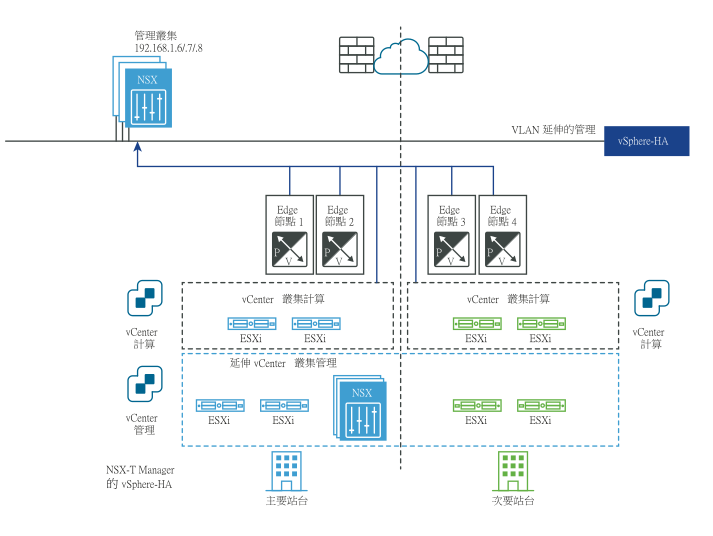
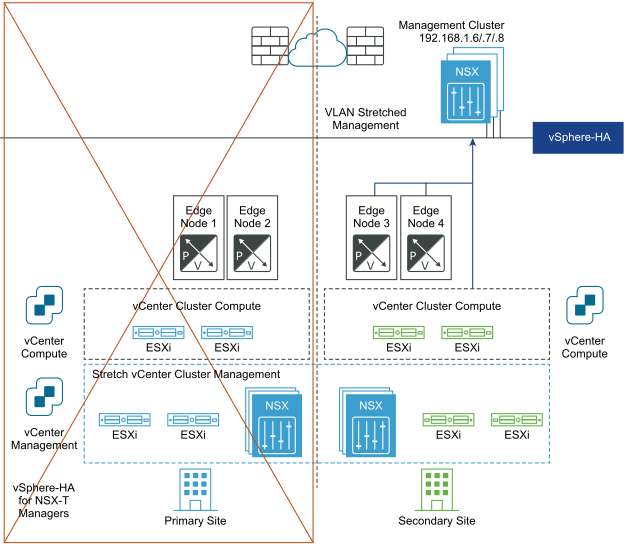
NSX Manager 叢集會部署在管理 VLAN 上,並且實際位於主要站台中。如果主要站台失敗,vSphere HA 將會重新啟動次要站台中的 NSX Manager。所有傳輸節點會自動重新連線至重新啟動的 NSX Manager。此程序需要大約 10 分鐘。在此期間,管理平面無法使用,但數據平面不會受到影響。
下圖說明管理平面的自動復原。
災難之前:
災難復原之後:
數據平面的自動復原
您可以為 Edge 節點設定失敗網域,以實現數據平面的自動復原。您可以將 Edge 叢集內的 Edge 節點分組在不同的失敗網域中。NSX Manager 會自動將任何新的作用中第 1 層閘道置於慣用的失敗網域,以及將待命第 1 層閘道置於另一個網域。請注意,在建立失敗網域前部署的 T1 會保留其原始 Edge 節點放置位置,因而可能無法在您所需的位置執行。若要修正其放置位置,請編輯 T1 並手動為 T1 作用中和 T1 待命選取 Edge 節點。
- Edge 節點之間的最大延遲時間為 10 毫秒。
- 如果無法實現非對稱南北向路由 (例如,在 NSX Edge 節點的北向使用實體防火牆),則第 0 層閘道的 HA 模式必須為作用中/待命,且容錯移轉模式必須為先佔式。
- 如果可以進行非對稱南北向路由 (例如,兩個位置是兩棟建築物,它們之間沒有任何實體防火牆),則第 0 層閘道的 HA 模式可以是作用中/作用中。
Edge 節點可以是虛擬機器或裸機。第 1 層閘道的容錯移轉模式可以是先佔式和非先佔式,但建議設定為先佔式,以確保第 0 層和第 1 層閘道位於同一位置。
- 使用 API 建立兩個站台的失敗網域,例如 FD1A-Preferred_Site1 和 FD2A-Preferred_Site1。
備註: 如果您希望所有的第 1 層 (一些 Edge 節點中的 T1 作用中和其他 Edge 節點中的 T1 待命) 都屬於同一個失敗網域 (FD1A-Preferred_Site1 和 FD2A-Preferred_Site1),您必須先使用先佔式選項建立第 1 層,然後建立設定為
preferred_active_edge_services = true的失敗網域主要站台 (FD1A-Preferred_Site1)。例如,POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - 使用 API,設定延伸到兩個站台的 Edge 叢集。例如,叢集在主要站台中有 Edge 節點 EdgeNode1A 和 EdgeNode1B,而在次要站台中有 Edge 節點 EdgeNode2A 和 EdgeNode2B。作用中的第 0 層和第 1 層閘道將在 EdgeNode1A 和 EdgeNode1B 上執行。待命第 0 層和第 1 層閘道將在 EdgeNode2A 和 EdgeNode2B 上執行。
- 使用 API,將每個 Edge 節點與該站台的失敗網域建立關聯。先呼叫
GET /api/v1/transport-nodes/<transport-node-id>API 以取得有關 Edge 節點的資料。使用 GET API 的結果作為PUT /api/v1/transport-nodes/<transport-node-id>API 的輸入,並適當地設定其他內容 failure_domain_id。例如,GET /api/v1/transport-nodes/<transport-node-id> Response: { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "_revision": 15" "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - 使用 API 設定 Edge 叢集,以根據失敗網域配置節點。先呼叫
GET /api/v1/edge-clusters/<edge-cluster-id>API 以取得有關 Edge 叢集的資料。使用 GET API 的結果作為PUT /api/v1/edge-clusters/<edge-cluster-id>API 的輸入,並適當地設定其他內容 allocation_rules。例如,GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - 使用 API 或 NSX Manager UI 建立第 0 層和第 1 層閘道。
如果整個主要站台失敗,則次要站台中的第 0 層待命和第 1 層待命會自動接管並成為新的作用中閘道。
下圖說明數據平面的自動復原。
災難之前:
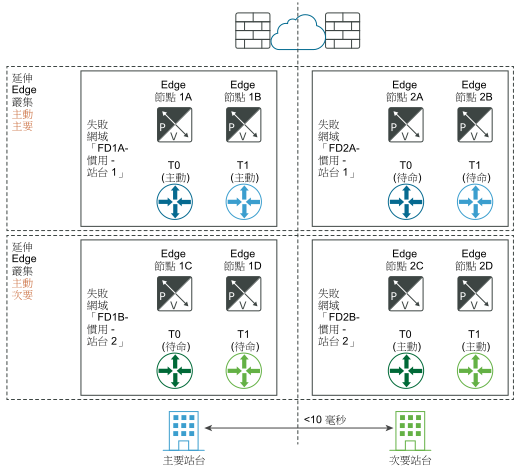
災難復原之後:
如果主要站台中的一個 Edge 節點而非整個站台失敗,請務必注意,上述原則同樣適用。例如,在下圖中,假設「災難之前」,Edge 節點 1B 託管 Tier-1-blue 作用中節點,Edge 節點 2B 託管 Tier-1-blue 待命節點。如果 Edge 節點 1B 失敗,Edge 節點 2B 上的待命節點 Tier-1-blue 將對其進行接管並成為新的 Tier-1-blue 作用中節點。
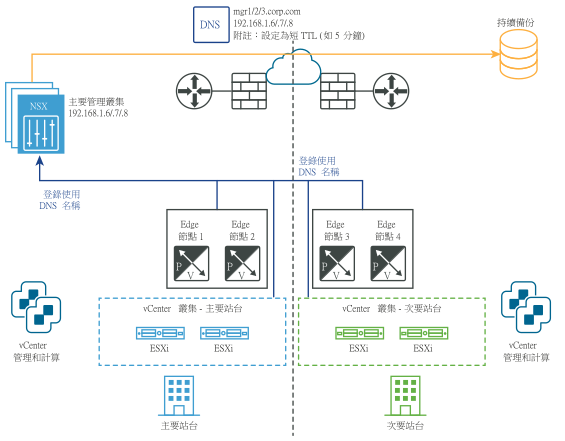
管理平面的手動/指令碼式復原
- NSX Manager 的 DNS 具有短 TTL (例如,5 分鐘)。
- 持續 NSX Manager 備份。
不需要 vSphere HA 和延伸的管理 VLAN。NSX Manager 必須與具有短 TTL 的 DNS 名稱相關聯。所有傳輸節點 (Edge 節點和 Hypervisor) 必須使用其 DNS 名稱連線至 NSX Manager。若要節省時間,您可以選擇性地在次要站台中預先安裝 NSX Manager 叢集。
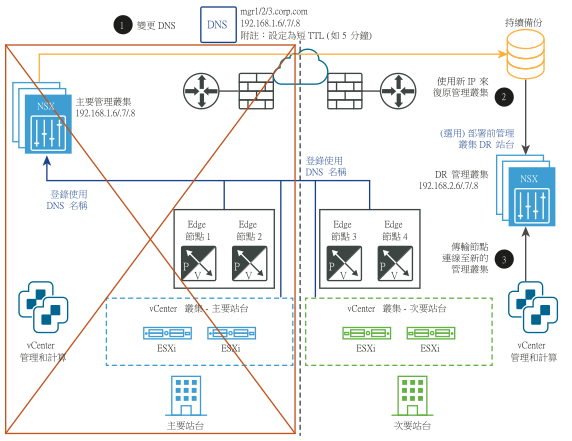
- 變更 DNS 記錄,讓 NSX Manager 叢集具有不同的 IP 位址。
- 從備份還原 NSX Manager 叢集。
- 讓傳輸節點連線至新的 NSX Manager 叢集。
下圖說明管理平面的手動/指令碼式復原。
災難之前:
災難之後:
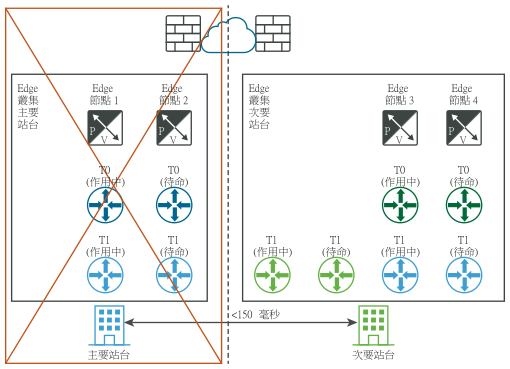
數據平面的手動/指令碼式復原
需求:Edge 節點之間的最大延遲時間為 150 毫秒。
Edge 節點可以是虛擬機器或裸機。每個位置中的第 0 層閘道可以是作用中/待命或作用中/作用中。Edge 節點虛擬機器可以安裝在不同的 vCenter Server 中。不需要 vSphere HA。
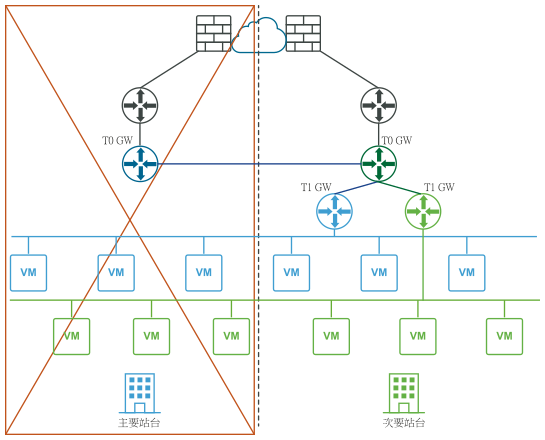
- 對於主要站台 (藍色) 中的所有第 1 層,更新其 Edge 叢集組態以成為 Edge 叢集次要站台。
- 對於主要站台 (藍色) 中的所有第 1 層,將其重新連線至 T0 次要站台 (綠色)。
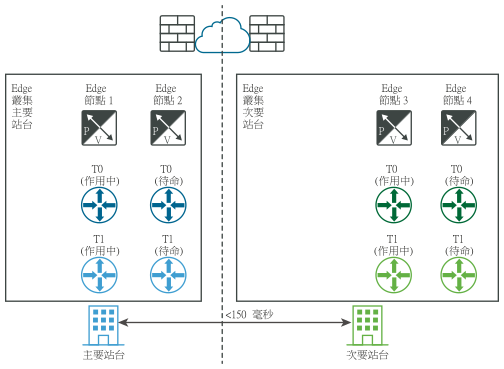
下圖透過邏輯和實體網路視圖,說明數據平面的手動/指令碼式復原。
災難之前 (邏輯和實體視圖):
災難之後 (邏輯和實體視圖):
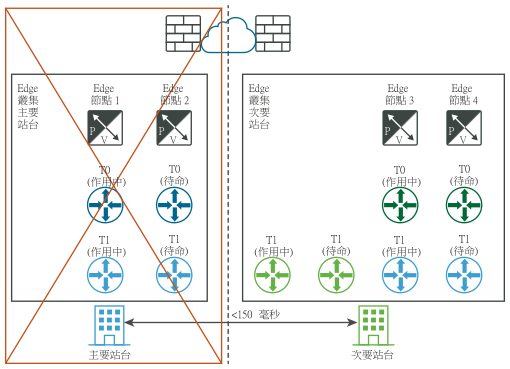
多站台部署需求
- 頻寬必須至少有 1 Gbps,且延遲時間 (RTT) 必須少於 150 毫秒。
- MTU 必須至少為 1600。建議使用 9000。
- 透過自動復原管理平面且在站台之間延伸 VLAN 管理。vSphere HA 跨 NSX Manager 虛擬機器的站台。
- 透過手動/指令碼式復原管理平面且在站台之間延伸 VLAN 管理。用於 NSX Manager 虛擬機器的 VMware SRM。
- 透過手動/指令碼式復原管理平面,而不在站台之間延伸 VLAN 管理。
- 持續 NSX Manager 備份。
- NSX Manager 必須設為使用 FQDN。
- 如果公用 IP 位址是透過 NAT 或負載平衡器之類的服務公開,則必須使用相同的網際網路提供者。
- 對於管理平面的自動復原
- 位置之間的最大延遲為 10 毫秒。
- 第 0 層閘道的 HA 模式必須為作用中/待命,且容錯移轉模式必須為先佔式,以確保沒有非對稱路由。
- 如果可接受非對稱路由 (例如,都會區域中的不同建築物),則第 0 層閘道的 HA 模式可以是作用中/作用中。
- 透過手動/指令碼式復原管理平面
- 位置之間的最大延遲為 150 毫秒。
- CMS 必須支援 NSX 外掛程式。在此版本中,VMware Integrated OpenStack (VIO) 和 vRealize Automation (vRA) 可滿足此需求。
限制
- 無本機出口功能。所有南北向流量均必須在一個站台內進行。
- 計算災難復原軟體必須支援 NSX,例如 VMware SRM 8.1.2 或更新版本。
- 在多站點環境中還原 NSX Manager 時,請在次要/主要站點上執行下列動作:
- 還原程序在 AddNodeToCluster 步驟暫停後,必須先從 UI 頁面中移除現有 VIP 並設定新的虛擬 IP,然後再新增其他管理程式節點。
- 更新 VIP 後,將節點新增至還原的單一節點叢集中。
