









SASE Orchestrator 災難復原 (DR) 功能可在系統或網路失敗時防止已儲存的資料遺失,並恢復 SASE Orchestrator 服務。
- 因此,復原時間目標 (RTO) 將取決於操作員觸發待命升級時執行的明確動作。
- 但無論復原時間為何,復原點目標 (RPO) 本質上皆為零,因為所有組態都會立即複寫。系統會將中斷期間收集的監控資料快取到等待進行待命升級的 Edge 和閘道上。
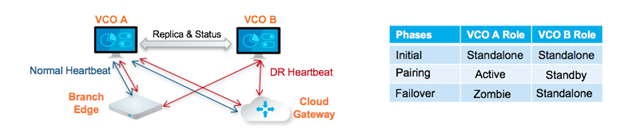
作用中/待命配對
在 SASE Orchestrator DR 部署中,會將兩個相同的 SASE Orchestrator 系統設定為作用中/待命配對。操作員可透過任一伺服器上的 Web UI 檢視 DR 的整備狀態。Edge 和閘道都可辨識 SASE Orchestrator,且只有在接收到作用中 SASE Orchestrator 的組態變更時,才會定期將 DR 活動訊號傳送至兩個系統,以報告它們對兩個伺服器的觀點,並查詢 DR 系統狀態。當操作員觸發容錯移轉時,Edge 和閘道將會在其下一個 DR 活動訊號中獲知此變更。
DR 狀態
就操作員以及 Edge 和閘道的觀點而言,SASE Orchestrator 的 DR 狀態會是下列四種狀態之一:
| DR 狀態 | 說明 |
|---|---|
| 獨立 (Standalone) | 未設定 DR。 |
| 作用中 | 已設定 DR,且作為主要 SASE Orchestrator 伺服器。 |
| 待命 | 已設定 DR,且作為非作用中複本 SASE Orchestrator 伺服器。 |
| 廢止 (Zombie) | 先前曾設定並啟用 DR,但現已不再是作用中或待命系統。 |
執行階段作業
已設定 DR 時,待命伺服器會以有限的模式執行並封鎖所有 API 呼叫,但與 DR 狀態和 DR 活動訊號有關呼叫的除外。當操作員叫用容錯移轉時,待命伺服器會升級成為具備完整功能的獨立伺服器。如果先前作用中的伺服器有回應,且可從已升級的待命伺服器檢視,則會自動轉換為「廢止」狀態。在「廢止」狀態下會封鎖管理組態服務,且尚未轉換至新的作用中 SASE Orchestrator 的 Edge 和閘道若發出任何聯繫,都會重新導向至已升級的伺服器。
設定 SASE Orchestrator 複寫
若要起始複寫,則必須要有兩個已安裝的 SASE Orchestrator 執行個體。
- 選取的待命伺服器會置於
STANDBY_CANDIDATE狀態,使其可由作用中伺服器設定。 - 然後系統會為作用中伺服器指定待命伺服器的位址和認證,使其進入
ACTIVE_CONFIGURING狀態。
STANDBY_CONFIG_RQST 時,兩個伺服器會透過狀態轉換進行同步。
- 閘道時區必須設定為 Etc/UTC。使用下列命令來檢視 NTP 時區。
vcadmin@vcg1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vcg1-example:~$
如果時區不正確,請使用下列命令來更新時區。
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
- NTP 偏移必須小於或等於 15 毫秒。使用下列命令來檢視 NTP 偏移。
sudo ntpqvcadmin@vcg1-example:~$ sudo ntpq -p remote refid st t when poll reach delay offset jitter ============================================================================== *ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033 ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000 vcadmin@vcg1-example:~$如果偏移不正確,請使用下列命令來更新 NTP 偏移。
sudo systemctl stop ntp sudo ntpdate <server> sudo systemctl start ntp
- 依預設,NTP 伺服器清單會設定在
/etc/ntpd.conf檔案中。需要建立 DR 的 Orchestrator 必須具有網際網路才能存取預設的 NTP 伺服器,並且確保兩個 Orchestrator 上的時間是同步中。客戶也可以使用其環境中執行的本機 NTP 伺服器來同步時間。
設定待命 Orchestrator
若要設定待命 Orchestrator,請執行下列步驟:
- 在企業入口網站的 SD-WAN 服務中,按一下 Orchestrator 索引標籤,然後從左側窗格中按一下複寫 (Replication) 按鈕,以顯示 Orchestrator 複寫 (Orchestrator Replication) 畫面。
- 藉由選取待命 (Standby) (複寫角色) 選項按鈕來啟用待命 Orchestrator。
- 按一下啟用待命 (Enable for Standby) 按鈕。
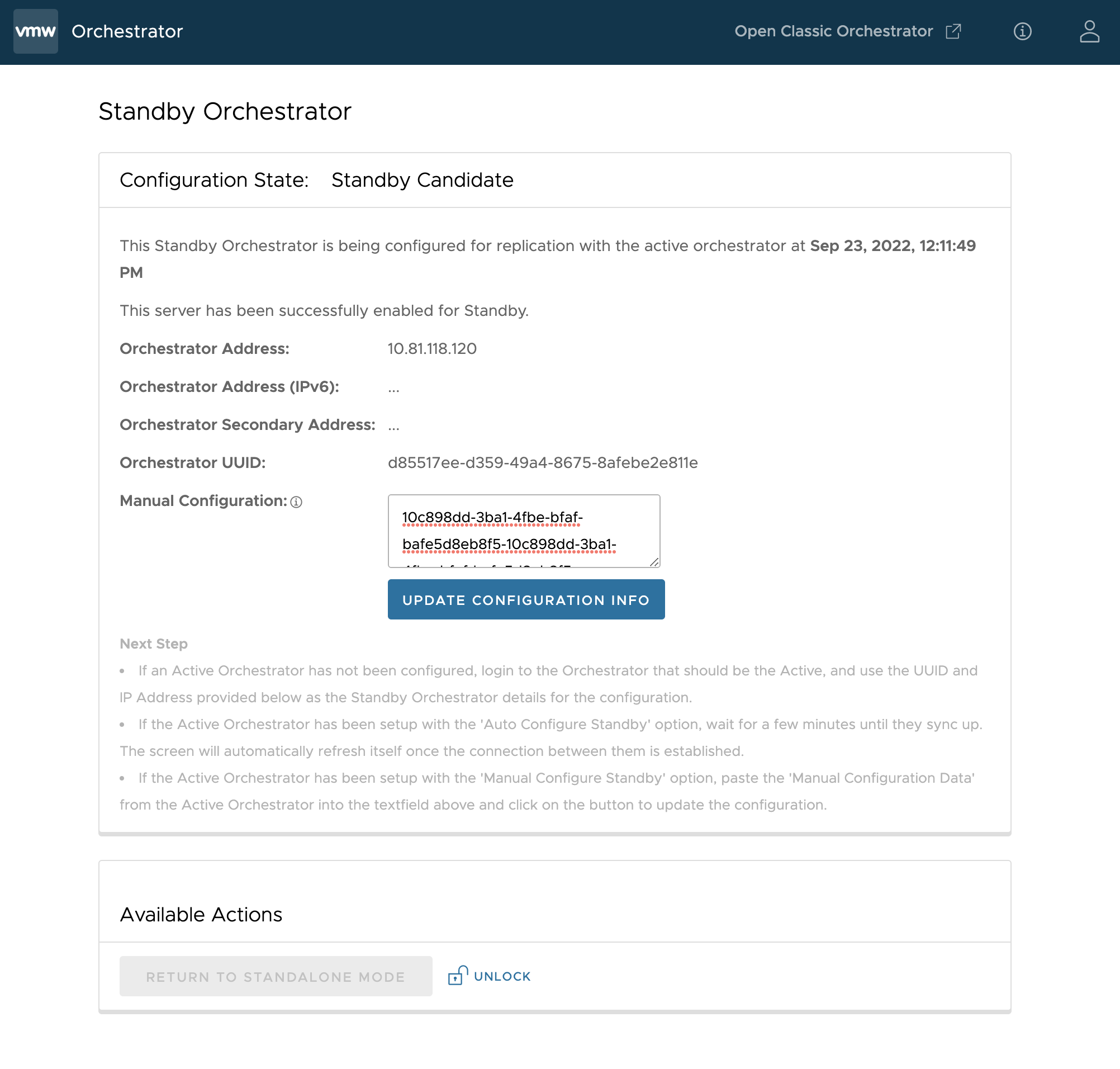
[待命 Orchestrator (Standby Orchestrator)] 頁面隨即出現。
- 輸入手動設定 (manual configuration) 參數,然後按一下更新組態資訊 (Update configuration info) 按鈕。
為待命 Orchestrator 設定複寫後,請根據以下指示設定作用中 Orchestrator。
設定作用中 Orchestrator
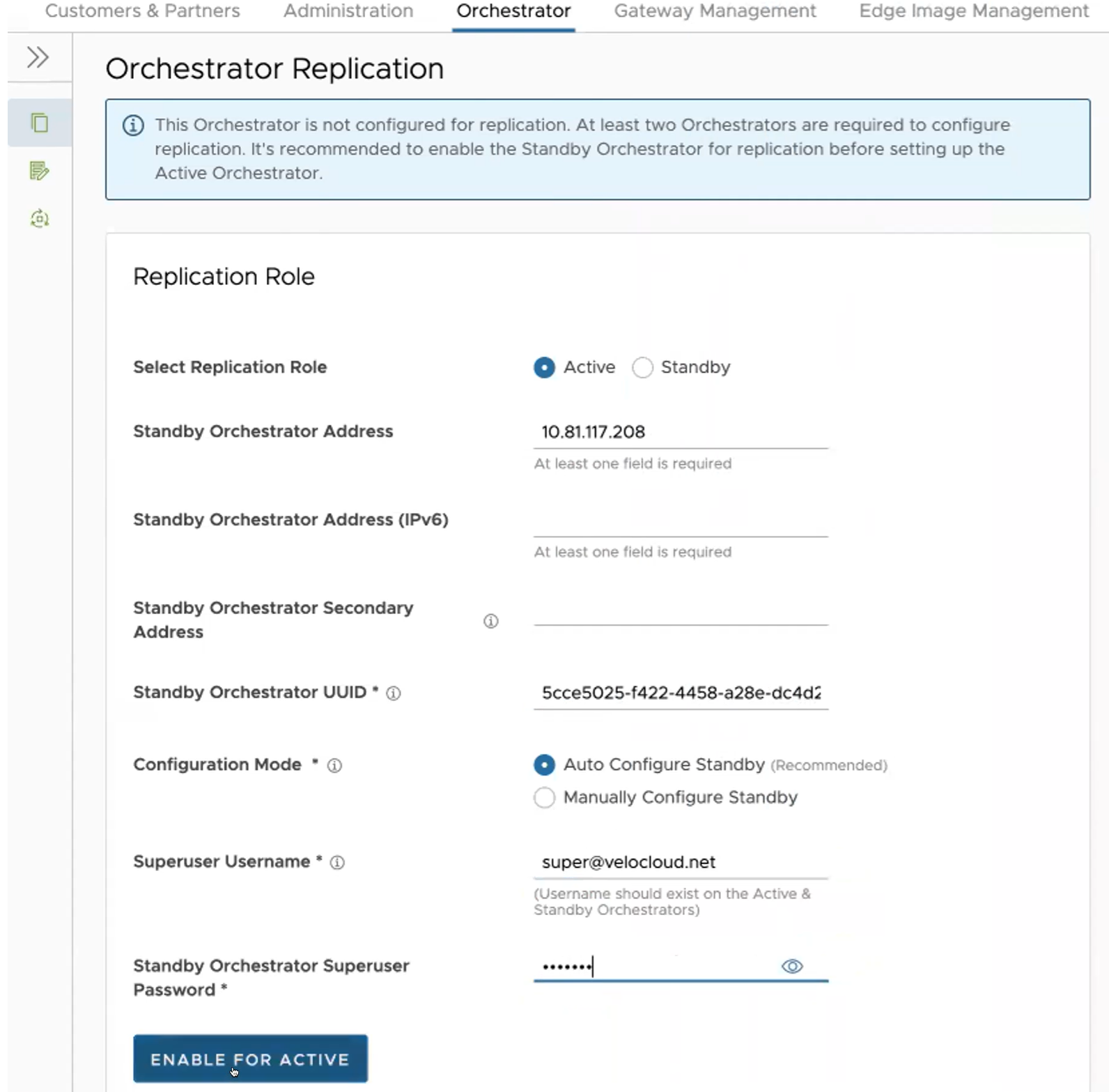
若要設定作用中 Orchestrator,請為複寫角色選取 [作用中 (Active)],然後設定下列項目:
| 選項 | 說明 |
|---|---|
| 選取複寫角色 (Select Replication Role) | 為複寫角色選取作用中 (Active) 選項按鈕。 |
| 待命 Orchestrator 位址 (Standby Orchestrator Address) | 輸入主要的待命 Orchestrator IP 位址。 |
| 待命 Orchestrator 位址 (IPv6) (Standby Orchestrator Address (IPv6)) | 輸入待命 Orchestrator IPv6 位址。 |
| 待命 Orchestrator 次要位址 (Standby Orchestrator Secondary Address) | 輸入待命 Orchestrator 次要介面的位址。如果待命 Orchestrator 已升級為作用中 Orchestrator,此位址會用於複寫。使用者可以在此處新增 Ipv4/Ipv6 或 FQDN 位址。 |
| 待命 Orchestrator UUID (Standby Orchestrator UUID) | 輸入待命 Orchestrator 的 UUID。 |
| 組態模式 (Configuration Mode) | 根據需求選取自動設定待命 (Auto Configure Standby) 或手動設定待命 (Manually Configure Standby) 選項按鈕。 手動設定時,請將字串值從 ACTIVE VCO 貼到 STANDBY_WAIT 。 |
| 超級使用者的使用者名稱 (Superuser Username) | 輸入 Orchestrator 超級使用者的顯示名稱。 |
| 待命 Orchestrator 超級使用者密碼 (Standby Orchestrator Superuser Password) | 輸入 Orchestrator 超級使用者的密碼。 |
- 按一下啟用以開始作用 (Enable for Active) 按鈕,以啟用複寫角色。
當組態完成時,這兩個 Orchestrator (待命和作用中) 會保持同步。
待命 Orchestrator 保持同步
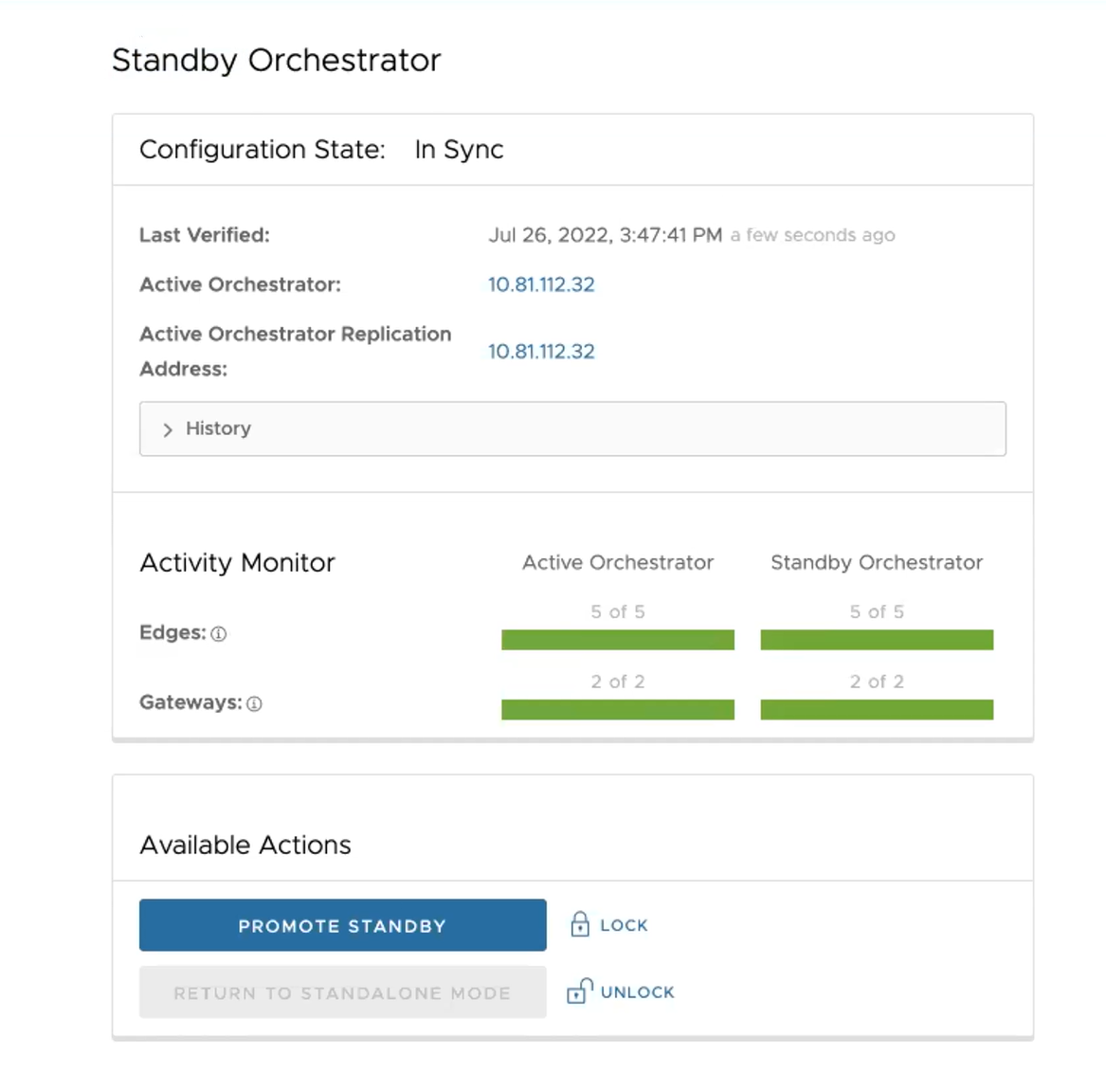
作用中 Orchestrator 保持同步
測試容錯移轉
下列測試容錯移轉案例是為了範例解說而強制執行的容錯移轉。您可以在作用中 (Active) 和待命 (Standby) 畫面的可用的動作 (Available Actions) 區域中執行這些動作。
升級待命 Orchestrator
本節說明如何升級待命 Orchestrator。
若要升級待命 Orchestrator,請執行下列步驟:
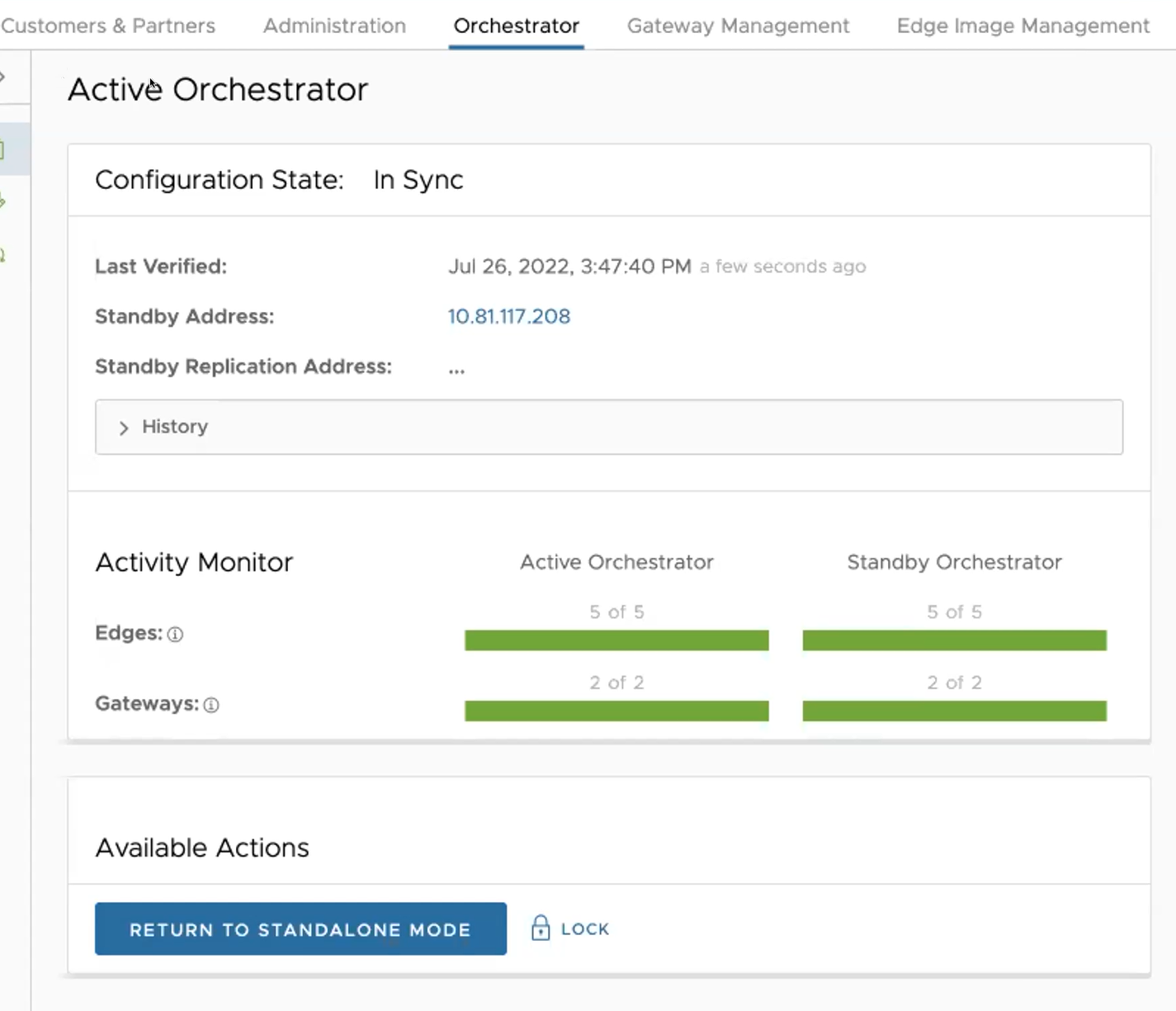
- 按一下解除鎖定 (unlock) 連結。
- 在待命 Orchestrator (Standby Orchestrator) 畫面上的可用的動作 (Available Actions) 區域中,按一下升級待命 (Promote Standby) 按鈕。
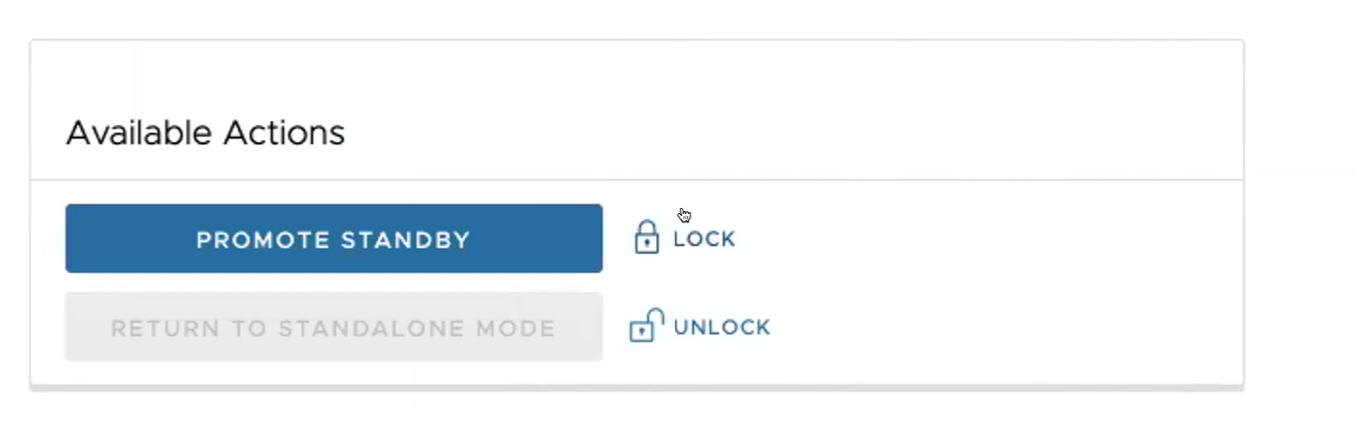
此時會出現下列對話方塊,指出當您升級待命 Orchestrator 時,管理員再也無法使用先前作用中的 Orchestrator 來管理 SASE Orchestrator。
- 按一下升級待命 (Promote Standby) 按鈕,以升級待命 Orchestrator。
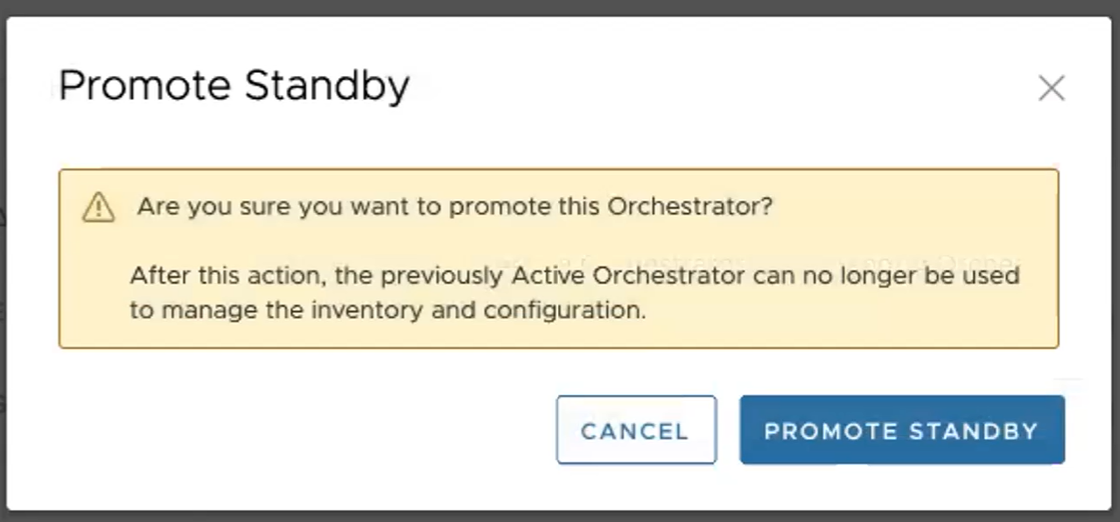
- 按一下強制升階待命 (Force Promote Standby),以升級 Orchestrator。
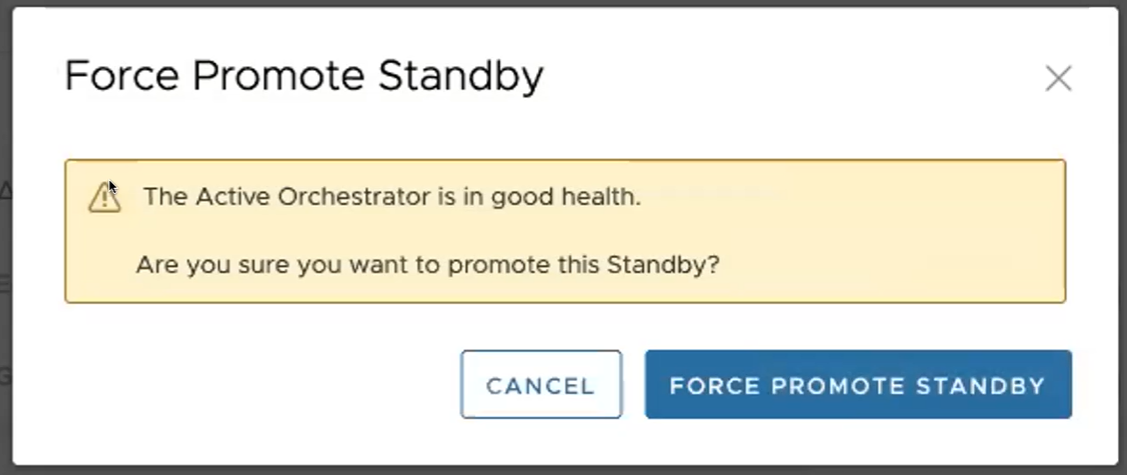
此時會出現最後的對話方塊,指出 Orchestrator 已不再是待命 Orchestrator,且會以獨立模式重新啟動。

當您升級待命 Orchestrator 時,它會以獨立模式重新啟動。
如果待命 Orchestrator 可以與先前作用中的 Orchestrator 進行通訊,則會指示該 Orchestrator 進入「廢止」狀態。在「廢止」狀態中,Orchestrator 會告知其用戶端 (Edge、閘道、UI/API) 它已不再處於作用中狀態,且用戶端必須與新升級的 Orchestrator 進行通訊。如果已升級的待命 Orchestrator 無法與先前作用中的 Orchestrator 進行通訊,則操作員應盡可能手動降級先前作用中的 Orchestrator。
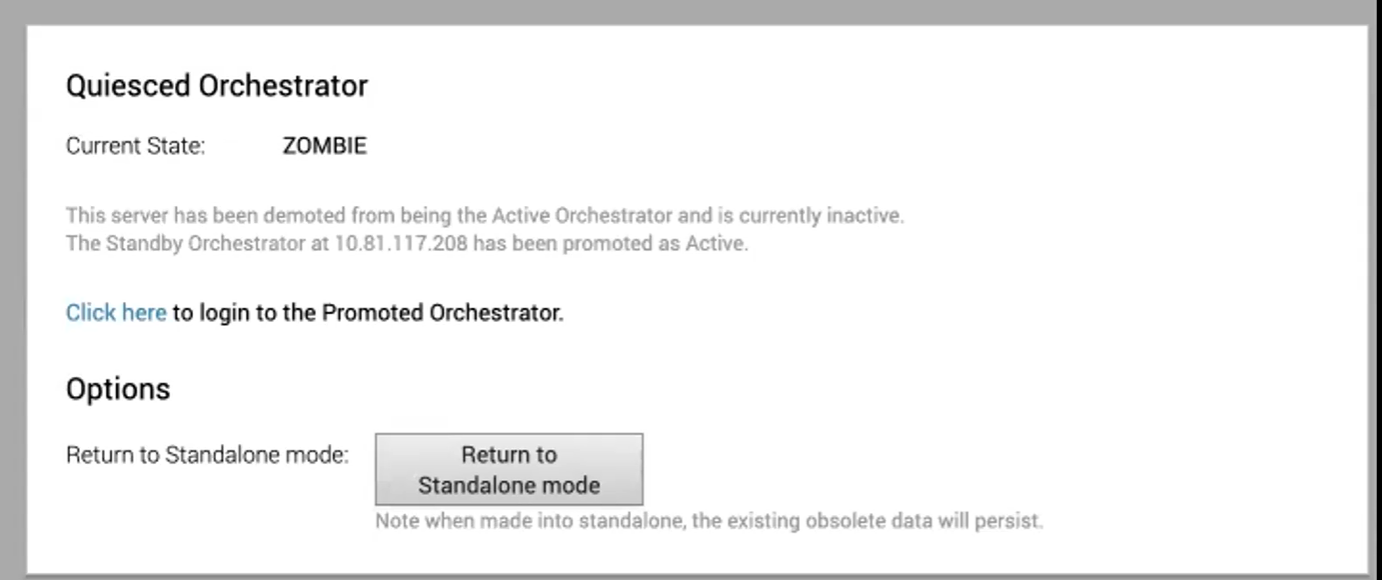
回復為獨立模式
若要將「廢止」回復為獨立模式,請在作用中 Orchestrator (Active Orchestrator) 或待命 Orchestrator (Standby Orchestrator) 畫面的 [可用的動作 (Available Actions)] 區域中按一下回復為獨立模式 (Return to Standalone Mode) 按鈕。
在系統內容「vco.disasterRecovery.zombie.expirySeconds」(預設為 1800 秒) 中指定的時間經過後,Orchestrator 可以從「廢止」狀態回到獨立模式。
對 SASE Orchestrator DR 進行疑難排解
本節說明系統的失敗狀態。這些狀態也會列在 UI 中,並隨附失敗的詳細說明。VMware 記錄會提供其他資訊。
可復原的失敗
下列錯誤是 SASE Orchestrator DR 達到同步狀態後可能會發生的可復原失敗。如果導致這些失敗的問題獲得修正,SASE Orchestrator DR 即會自動回復為正常運作。
FAILURE_SYNCING_FILESFAILURE_GET_STANDBY_STATUSFAILURE_MYSQL_ACTIVE_STATUSFAILURE_MYSQL_STANDBY_STATUS
無法復原的失敗
在 SASE Orchestrator DR 的設定期間可能會發生下列失敗。發生這些失敗後,SASE Orchestrator DR 不會自動復原。
FAILURE_ACTIVE_CONFIGURINGFAILURE_LAUNCHING_STANDBYFAILURE_STANDBY_CONFIGURINGFAILURE_COPYING_DBFAILURE_COPYING_FILESFAILURE_SYNC_CONFIGURINGFAILURE_GET_STANDBY_CONFIGFAILURE_STANDBY_CANDIDATEFAILURE_STANDBY_UNCONFIGFAILURE_STANDBY_PROMOTIONFAILURE_ACTIVE_DEMOTION
