









本節提供在兩天作業案例中監控、備份和升級企業內部部署的可用選項的相關資訊。
概觀
- 解決方案隔離:VMware Cloud Operations 團隊將沒有存取權,無法套用修補程式和升級。
- 變更管理的相關限制會限制修補和升級的頻率。
- 解決方案監控不適當或不足:此情況可能是由於缺少可支援管理基礎結構的人員所致,導致功能方面問題、解決問題較緩慢,以及客戶不滿意。
此方法一律需要在人員和時間方面大量投資,才能正確進行管理、操作和修補。下表概述在管理內部部署系統時必須考量的部分元素。
| 系統 | 說明 | VMware 主控的責任 | 內部部署責任 |
|---|---|---|---|
| SD-WAN Orchestration | 應用程式 QoS 和連結操控原則 | 是 | 是 |
| 應用程式和 SD-WAN 應用裝置的安全性原則 | 是 | 是 | |
| SD-WAN 應用裝置佈建和疑難排解 | 是 | 是 | |
| 處理 SD-WAN 警示與事件 | 是 | 是 | |
| 連結效能與容量監控 | 是 | 是 | |
| Hypervisor | 監控/警示 | 否 | 是 |
| 計算和記憶體資源 | 否 | 是 | |
| 虛擬網路和儲存區 | 否 | 是 | |
| 備份 | 否 | 是 | |
| 複寫 | 否 | 是 | |
| 基礎結構 | CPU、記憶體、計算 | 否 | 是 |
| 交換和路由 | 否 | 是 | |
| 監控與管理系統 | 否 | 是 | |
| 容量計劃 | 否 | 是 | |
| 軟體升級/修補 | 否 | 是 | |
| 疑難排解應用程式/基礎結構問題 | 否 | 是 | |
| 備份和基礎結構 DR | 備份基礎結構 | 否 | 是 |
| 備份機制的定期測試 | 否 | 是 | |
| DR 基礎結構 | 否 | 是 | |
| DR 測試 | 否 | 是 |
企業內部部署的兩天作業案例會在以下兩個小節 (第一天作業和第二天作業) 中分別說明。
第一天作業
訂閱安全性諮詢
VMware 安全性諮詢會記載用於 VMware 產品中所報告安全性漏洞的修復。請訂閱以下連結,以在需要於內部部署元件中採取動作時收到警示。
https://www.vmware.com/security/advisories.html
在 SASE Orchestrator 上停用 cloud-init
data-source 包含兩個區段:meta-data 和 user-data。meta-data 包含執行個體識別碼且在執行個體的存留時間不應變更,而 user-data 是在首次開機時套用的組態 (針對 meta-data 中的執行個體識別碼)。
首次開機後,建議停用 cloud-init 檔案,以加速 SASE Orchestrator 開機順序。若要停用 cloud-init,請執行:
./opt/vc/bin/cloud_init_ctl -d
建議不要使用命令「apt purge cloud-init」來「purge」cloud-init 檔案 (此程序在 VMware SD-WAN 控制器中不會造成問題)。清除 cloud-init 檔案也會清除某些重要的 SASE Orchestrator 工具和指令碼 (例如,升級和備份指令碼)。如果已使用「purge」命令,您可以使用下列命令來還原檔案:
- 移至資料夾 /opt/vcrepo/pool/main/v/vco-tools
- 從該資料夾安裝 SASE Orchestrator 工具套件:「sudo dpkg -i vco-tools_3.4.1-R341-20200423-GA-69c0f688bf.deb」。vco-tools 套件名稱可能會因您的版本而有所變更。請使用命令「ls vco-tools」檢查正確的檔案名稱。
NTP 時區
SASE Orchestrator 和閘道時區必須設定為「Etc/UTC」。
vcadmin@vco1-example:~$ cat /etc/timezone Etc/UTC vcadmin@vco1-example:~$
echo "Etc/UTC" | sudo tee /etc/timezone sudo dpkg-reconfigure --frontend noninteractive tzdata
NTP 偏移
預期 NTP 偏移會 <= 15 毫秒。
vcadmin@vco1-example:~$ sudo ntpq -p
remote refid st t when poll reach delay offset
jitter
==============================================================================
*ntp1-us1.prod.v 74.120.81.219 3 u 474 1024 377 10.171 -1.183 1.033
ntp1-eu1-old.pr .INIT. 16 u - 1024 0 0.000 0.000 0.000
vcadmin@vco1-example:~$
sudo service ntp stop sudo ntpdate <server> sudo service ntp start
SASE Orchestrator 儲存區
當 SASE Orchestrator 初次部署時,系統會建立三個磁碟分割:/、/store、/store2、/store3 (4.0 版及更高版本)。磁碟分割會以預設大小建立。請遵循標題為〈增加 SASE Orchestrator 中的儲存區〉一節中的指示,以取得修改預設大小以符合設計的準則。
其他工作
- 設定系統內容。
- 設定初始操作員設定檔。
- 設定操作員帳戶。
- 建立 SD-WAN 閘道。
- 設定 SASE Orchestrator。
- 建立客戶帳戶/合作夥伴帳戶。
上述清單中的組態已超出本文件的範圍,這部份可在 VMware 說明文件的部署指南中找到。可以在《VMware SASE Orchestrator 部署和監控指南》中標題為〈安裝 SASE Orchestrator〉一節中,找到詳細指示。
第二天作業
SASE Orchestrator 備份
本節提供可用機制以定期備份 SASE Orchestrator 資料庫,進而從操作員錯誤或作用中和待命 Orchestrator 的災難性失敗中復原。
請注意,災難復原功能或 DR 是慣用的復原方法。它提供近乎為零的復原點目標,因為作用中 Orchestrator 上的所有組態會立即複寫。如需有關災難復原功能的更多詳細資料,請參閱下一節。
使用內嵌式指令碼進行備份
SASE Orchestrator 提供內建的組態備份機制可定期備份組態,以從操作員錯誤或作用中和待命 Orchestrator 的災難性失敗中復原。該機制是使用指令碼驅動的,位於 /opt/vc/scripts/db_backup.sh。
該指令碼基本上會取得組態資料和事件的資料庫傾印,同時在資料庫傾印程序期間排除一些大型監控資料表。執行指令碼後,即會在提供作為上述指令碼輸入的本機目錄路徑中建立備份檔案。
備份包含兩個 .gzs 檔案,其中一個包含資料庫架構定義,而另一個包含不具定義的實際資料。管理員應確保備份目錄位置具有足夠的磁碟空間可用於備份。
最佳做法
- 掛接遠端位置並將備份指令碼設定至該位置。如果也要備份流程,則遠端位置應具有與 /store 相同的儲存區。
- 使用備份指令碼之前,請從 SASE Orchestrator 複寫頁面檢查災難復原 (DR) 複寫狀態。它們應處於同步狀態,且不應顯示任何錯誤。
- 另外,執行 MySQL 查詢並檢查複寫延隔。
- SHOW SLAVE STATUS \G
- 在上述查詢中,查看欄位 seconds_behind_master。理想情況下,它應為零,但低於 10 也會有足夠的效果。
- 對於大型的 SASE Orchestrator,建議對備份指令碼執行使用「待命」。從這兩個 SASE Orchestrator 產生的備份之間沒有任何差異。
須知- 指令碼僅會取得組態的備份;不會包含流量統計資料或事件。
- 還原組態需要支援/工程團隊的協助。
- 執行指令碼需要多久時間?
備份的持續時間取決於實際客戶組態的規模。由於已從備份作業中排除監控資料表,因此預期組態備份作業將會快速完成。對於具有上千個 SD-WAN Edge 和大量歷史事件的大型 SASE Orchestrator,最多可能需要一小時,而較小的 SASE Orchestrator 應可在幾分鐘內完成。
- 執行備份指令碼的建議頻率為何?
根據規模和完成初始備份所耗費的時間,可以判斷備份作業頻率。應將備份作業排程在離峰時間執行,以減少對 SASE Orchestrator 資源的影響。
- 如果根檔案系統沒有足夠空間可用於備份,該怎麼辦?
建議使用其他已掛接的磁碟區來儲存備份。請注意,將根檔案系統用於備份並非最佳做法。
- 如何驗證備份作業是否已成功完成?
指令碼 stdout 和 stderr 應該足以判斷備份作業的成功或失敗。如果指令碼叫用自動化,結束代碼可以判斷備份作業的成功或失敗。
- 如何復原組態?
目前 VMware 需要客戶與 VMware 支援人員合作來復原組態資料。VMware 支援人員將協助復原客戶的組態。在設定還原之前,客戶應避免進行任何其他的組態變更。
- 執行此指令碼的確切影響為何?
即使組態的備份應該會對效能有極小的影響,MySQL 程序的資源使用率仍會增加。建議在離峰時段執行備份。
- 執行備份作業期間是否允許進行任何組態變更?
執行備份作業時,可以安全地變更組態。不過,若要確保最新的備份,建議在執行備份時不要執行任何組態作業。
- 可以在原始 SASE Orchestrator 上還原組態,還是需要在新的 SASE Orchestrator 進行?
可以這樣做,但如果可用,則理想上應該在相同的 SASE Orchestrator 上還原組態。這可確保在還原作業完成後使用監控資料。如果無法復原原始的 SASE Orchestrator,且待命 Orchestrator 已關閉,則可以在新的 SASE Orchestrator 上還原組態。在此執行個體中,監控資料將會遺失。
- 如果需要將組態還原到新的 SASE Orchestrator,應採取什麼動作?
請連絡 VMware 支援人員,以取得新 SASE Orchestrator 上建議的一組動作,因為步驟會因實際部署而有所不同。
- SD-WAN Edge 是否必須在新還原的 SASE Orchestrator 上重新登錄?
否,SD-WAN Edge 不需要在新的 SASE Orchestrator 上進行登錄,因為所有需要的資訊已保留為備份的一部分。
SASE Orchestrator 災難復原
狀態
- 獨立 (Standalone) (未設定 DR)
- 作用中 (已設定 DR,且作為主要 SASE Orchestrator 伺服器)。
- 待命 (已設定 DR,且作為非作用中複本 SASE Orchestrator 伺服器)。
- 廢止 (Zombie) 先前曾設定並作用中,但現已不再以作用中或待命運作的 DR。
| 階段 | SASE Orchestrator A 角色 | SASE Orchestrator B 角色 |
|---|---|---|
| 初始 (Initial) | 獨立 (Standalone) | 獨立 (Standalone) |
| 配對 (Pairing) | 作用中 | 待命 |
| 容錯移轉 (Failover) | 廢止 (Zombie) | 獨立 (Standalone) |
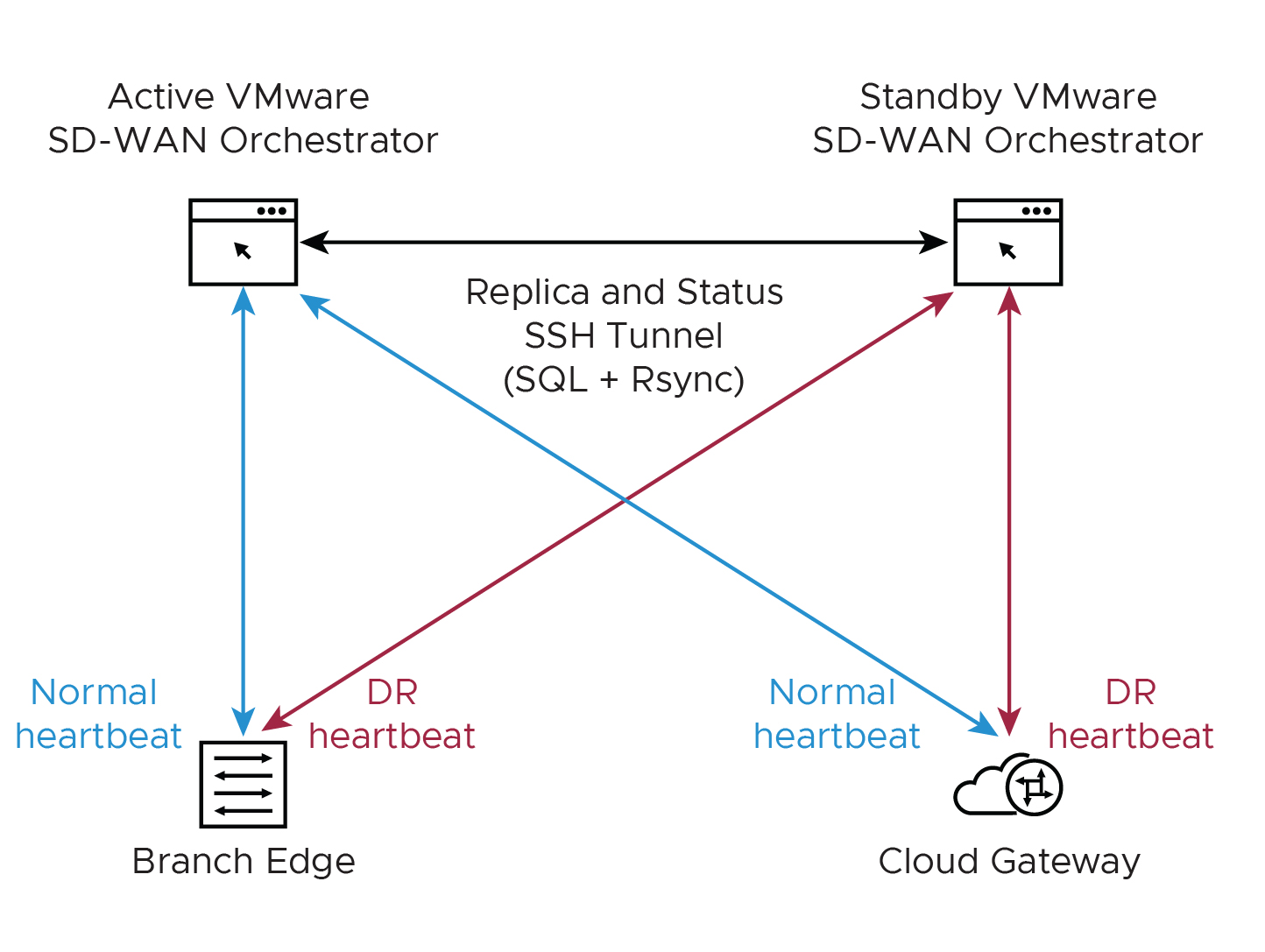
- 在地理位置區隔的資料中心中尋找 SASE Orchestrator DR。
- 在將待命 Orchestrator 升級為作用中 Orchestrator 之前,請確認 DR 複寫狀態為「同步中」。先前的作用中 Orchestrator 將不再可管理詳細目錄和組態。
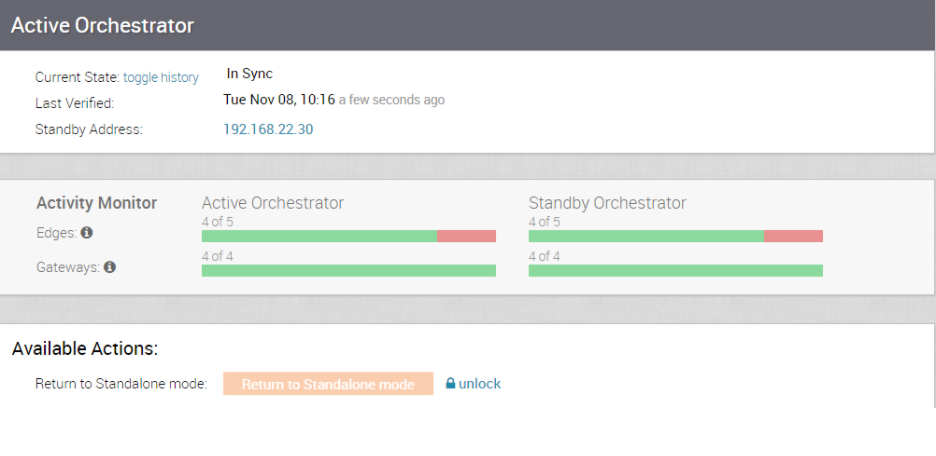
- 如果待命 Orchestrator 可以與先前作用中的 Orchestrator 進行通訊,則會指示該 Orchestrator 進入「廢止」狀態。在「廢止」狀態中,SASE Orchestrator 會告知其用戶端 (SD-WAN Edge、SD-WAN 閘道、UI/API) 它已不再處於作用中,且用戶端必須與新升級的 SASE Orchestrator 進行通訊。
- 如果已升級的待命 Orchestrator 無法與先前作用中 Orchestrator 進行通訊,則操作員應盡可能手動降級先前作用中 Orchestrator。
- 您可以在官方 SASE Orchestrator 說明文件 docs.vmware.com 的〈設定 SASE Orchestrator 災難復原〉下找到詳細指示。
SASE Orchestrator 的升級程序
- VMware 支援將協助進行升級。在連絡 VMware 支援之前請收集以下資訊。
- 提供目前和目標的 SASE Orchestrator 版本,例如:目前版本 (即 3.4.2),目標版本 (3.4.3)。
備註: 對於目前版本,在 SASE Orchestrator 的右上角按一下 [說明 (Help)] 連結,然後選擇 [關於 (About)],即可找到此資訊。
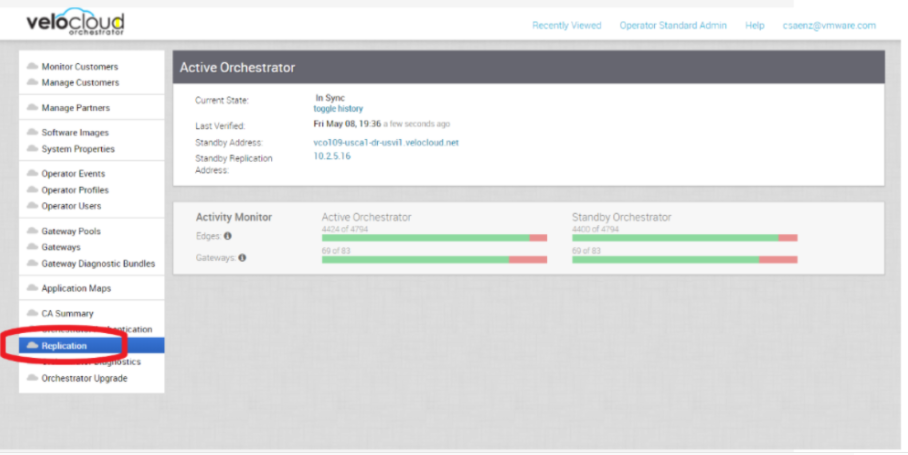
- 提供 SASE Orchestrator 的複寫儀表板螢幕擷取畫面,如下所示。
- Hypervisor 類型和版本 (例如 vSphere 6.7)
- 來自 SASE Orchestrator 的命令 (命令必須以根使用者身分執行,例如「sudo <command>」或「sudo -i」)。
- LVM 組態
- pvdisplay -v
- vgdisplay -v
- lvdisplay -v
- df -h
- cat /etc/fstab
- 記憶體資訊
- free -m
- cat /proc/meminfo
- ps -ef
- top -b -n 2
- CPU 資訊
- cat /proc/cpuinfo
- /var/log 複本
- tar -czf /store/log-`date +%Y%M%S`.tar.gz --newer-mtime="36 hours ago" /var/log
- 從待命 Orchestrator:
- sudo mysql --defaults-extra-file=/etc/mysql/velocloud.cnf velocloud -e 'SHOW SLAVE STATUS \G'
- 從作用中 Orchestrator:
- sudo mysql --defaults-extra-file=/etc/mysql/velocloud.cnf velocloud -e 'SHOW MASTER STATUS \G'
- LVM 組態
- 提供目前和目標的 SASE Orchestrator 版本,例如:目前版本 (即 3.4.2),目標版本 (3.4.3)。
- 請透過 https://kb.vmware.com/s/article/53907 連絡 VMware SD-WAN 支援,並提供上述資訊,以獲得升級 SASE Orchestrator 的協助。
- 在下一節提供 ESXi 快照準則,以防客戶在升級後需要快速復原解決方案。
ESXi 快照
SASE Orchestrator 升級之前,可以使用 ESXi 快照功能,以便能快速復原至先前的 SASE Orchestrator 版本。
ESXi 快照最佳做法
- 必須先將待命和作用中 Orchestrator 關閉電源,然後才能從快照執行或還原,以避免任何資料庫的不一致。
- 所有與快照相關的工作必須在待命和作用中 Orchestrator 中完成,以避免任何資料庫的不一致。
- 如果升級程序成功,則有必要將快照整併。保留較長的一段時間後,快照檔案會繼續成長。這可能會導致快照儲存位置耗盡空間並影響系統效能。
- 建立快照時停用 SASE Orchestrator 中的警示,以避免誤報。
- 請勿使用單一快照超過 72 小時。
- 不建議將快照用作備份。
- 功能驗證是使用 ESXi 6.7 和 SASE Orchestrator 3.4.4 版來完成。
您可以在以下知識庫文章中找到 VMware 快照的最佳做法:https://kb.vmware.com/s/article/1025279
建立 ESXi 快照
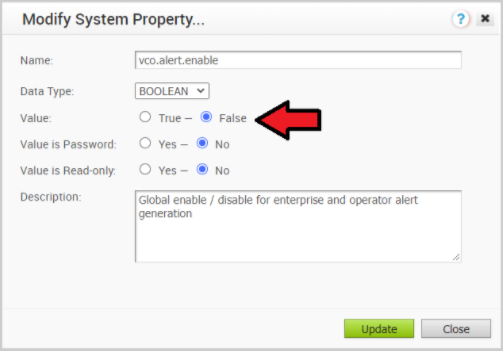
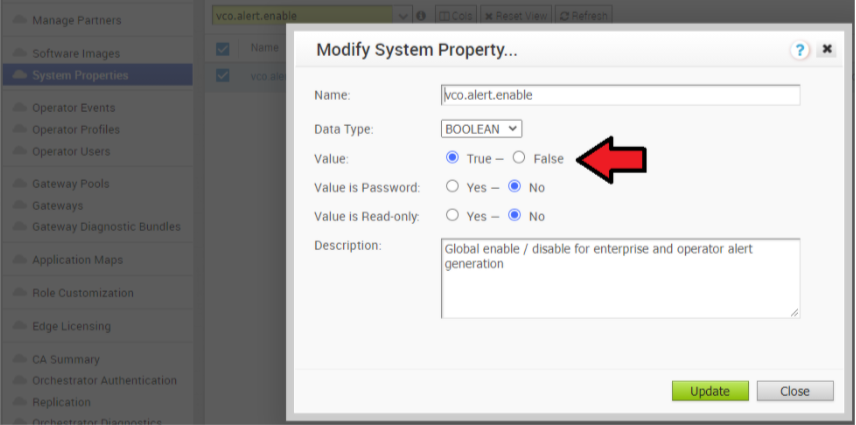
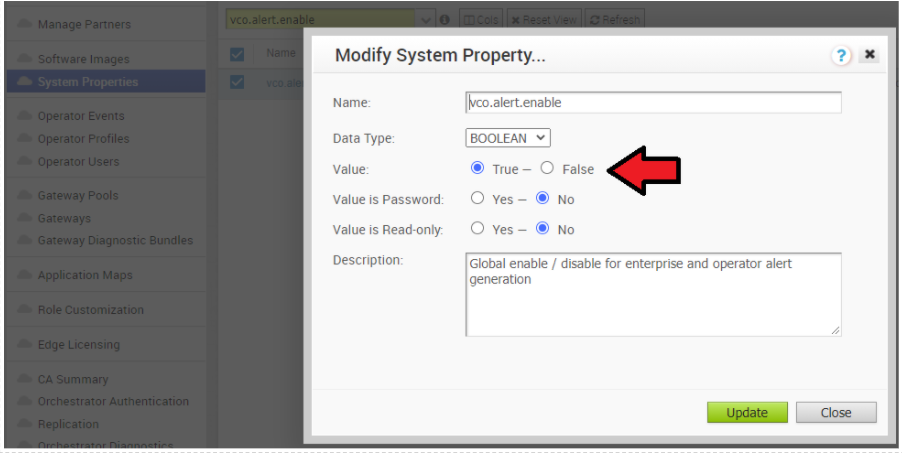
- 在作用中 Orchestrator 上停用警示、通知和監控系統內容。持續期間約為 10 分鐘。
- 在操作員入口網站中,按一下系統內容 (System Properties)。將下列系統內容變更為 false。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- 在操作員入口網站中,按一下系統內容 (System Properties)。將下列系統內容變更為 false。
- 在待命 Orchestrator 上停用警示、通知和監控系統內容。
- 將下列系統內容變更為 false。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- 將下列系統內容變更為 false。
- 關閉作用中 Orchestrator 的電源。
移至 [ESXi/vCenter] → [Orchestrator 虛擬機器 (Orchestrator VM)] → [動作 (Actions)] → [電源 (Power)] → [關閉電源 (Power Off)]。
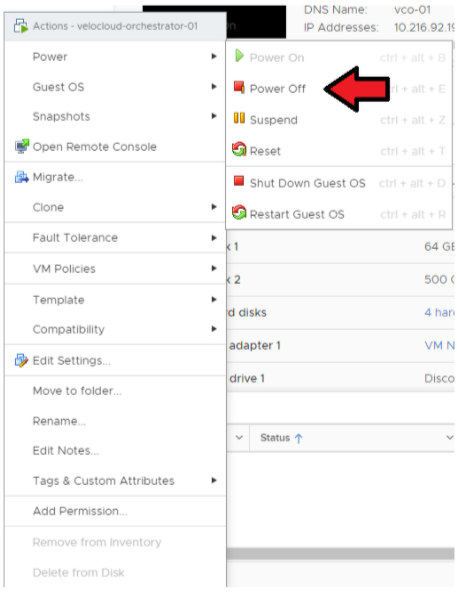
- 關閉待命 Orchestrator 的電源。
移至 ESXi/vCenter → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 關閉電源 (Power Off)
- 建立作用中 Orchestrator 的快照。執行此步驟之前,請確認已關閉虛擬機器的電源。
移至 ESXi → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 快照 (Snapshots) → 建立快照 (Take Snapshot)。
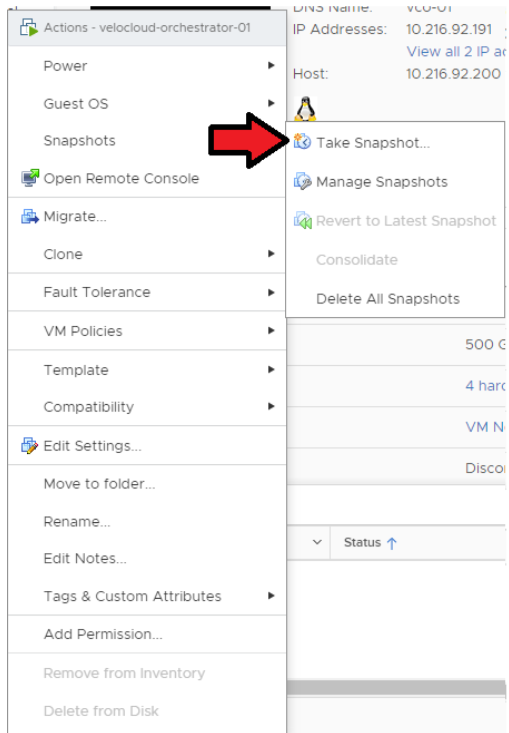
- 建立待命 Orchestrator 的快照。執行此步驟之前,請確認已關閉虛擬機器的電源。
移至 ESXi → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 快照 (Snapshots) → 建立快照 (Take Snapshot)。
ESXi 快照的整併
- 確認在作用中和待命 Orchestrator 上成功升級後,您可以從作用中 Orchestrator 開始整併快照。
移至 ESXi → Orchestrator 虛擬機器 (Orchestrator VM) → Actions (動作) → Snapshots (快照) → 快照管理員 (Snapshot Manager) → 全部刪除 (Delete All)。
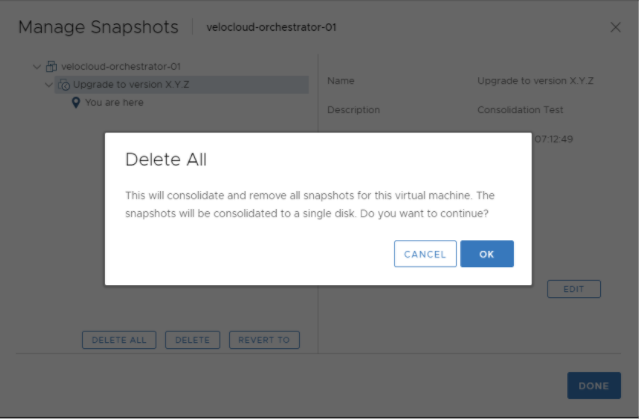
- 在待命 Orchestrator 中整併快照。
移至 ESXi → Orchestrator 虛擬機器 (Orchestrator VM) → Actions (動作) → Snapshots (快照) → 快照管理員 (Snapshot Manager) → 全部刪除 (Delete All)。
- 在作用中 Orchestrator 和待命 Orchestrator 上重新啟用警示、通知和監控系統內容。
在操作員入口網站中,按一下 系統內容 (System Properties)。將下列系統內容變更為 true。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
- 如果 [刪除所有快照 (Delete All snapshots)] 不適用於 vSphere 6.x/7.x,您可以嘗試整併快照。如需詳細資訊,請參閱 vSphere 產品說明文件中的〈整併快照〉一節。
從 ESXi 快照還原
- 關閉作用中 Orchestrator 的電源。
移至 ESXi/vCenter → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 關閉電源 (Power Off)。
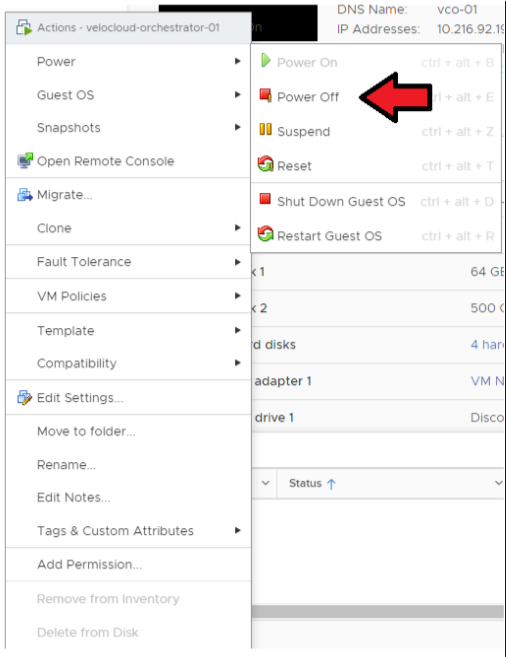
- 關閉待命 Orchestrator 的電源。
移至 ESXi/vCenter → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 關閉電源 (Power Off)。
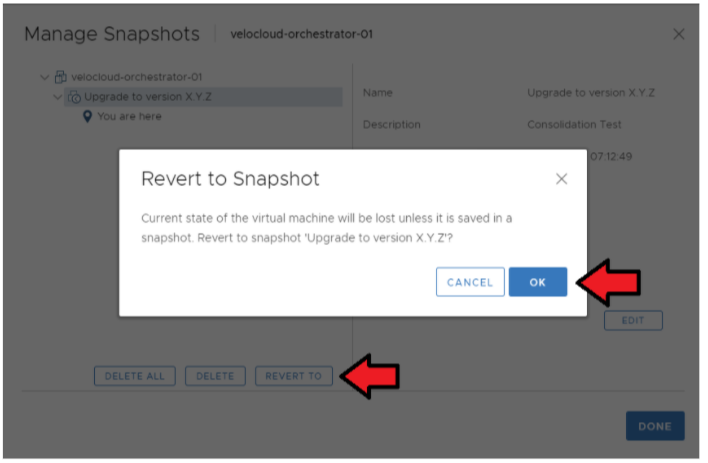
- 還原作用中 Orchestrator 的快照。
移至 ESXi → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 快照 (Snapshots) → 管理快照 (Manage Snapshots)。
選取您想要還原虛擬機器的快照 → [還原為 (Revert to)] (請參閱下圖)。
- 還原待命 Orchestrator 的快照。
移至 ESXi → Orchestrator 虛擬機器 (Orchestrator VM) → 動作 (Actions) → 電源 (Power) → 快照 (Snapshots) → 管理快照 (Manage Snapshots)。
選取您想要還原虛擬機器的快照 → [還原為 (Revert to)]。
- 在作用中 Orchestrator 和待命 Orchestrator 上重新啟用警示、通知和監控系統內容。在操作員入口網站中,按一下系統內容 (System Properties)。將下列系統內容變更為 true。
- vco.alert.enable
- vco.notification.enable
- vco.monitor.enable
控制器次要軟體升級 (例如從 3.3.2 P3 至 3.4.4)
軟體升級檔案包含閘道和系統更新。請勿執行「apt-get update && apt-get -y upgrade」。
在繼續執行 VMware SD-WAN 控制器升級之前,請確保已將 SASE Orchestrator 升級至相同或更高版本。
- 下載 SD-WAN 控制器更新套件。
- 將映像上傳至 SD-WAN 控制器儲存區 (例如,使用 SCP 命令)。將映像複製到系統上的下列位置:/var/lib/velocloud/software_update/vcg_update.tar。
- 連線至 SD-WAN 控制器主控台並執行:
sudo /opt/vc/bin/vcg_software_update
root@VCG:/var/lib/velocloud/software_update# wget -O 'vcg_update.tar' <image location>
Resolving ftpsite.vmware.com (ftpsite.vmware.com)...
Connecting to ftpsite.vmware.com (ftpsite.vmware.com)| <ip address>|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [application/octet-stream]
Saving to: 'vcg_update.tar'
[ <=> ] 325,939,200 3.81MB/s in 82s
2020-05-23 21:59:27 (3.79 MB/s) - ‘vcg_update.tar’ saved [325939200]
root@VCG:/var/lib/velocloud/software_update# sudo /opt/vc/bin/vcg_software_update
=========== VCG upgrade: Sat May 23 22:08:15 UTC 2020
Upgrading gateway version 3.4.0-106-R340-20200218-GA-c57f8316dd to 3.4.1-39-R341-20200428-GA-44354-44451-596496a88a
Ign file: trusty InRelease
Ign file: trusty Release.gpg
Get: 1 file: trusty Release [2,668 B]
Ign file: trusty/main Translation-en_US
Ign file: trusty/main Translation-en
(...)
Writing extended state information...
Reading package lists...
Building dependency tree...
Reading state information...
Reading extended state information...
Initializing package states...
update-initramfs: Generating /boot/initrd.img-3.13.0-176-generic
Reboot is required. Reboot? (y/n) [y]:
控制器主要軟體升級 (例如,從 3.3.2 或 3.4 到 4.0)
- 以 LVM 為基礎的新系統磁碟組態,可在大量管理中提供更多的彈性
- 新的核心版本
- 新的和升級的基礎作業系統套件
- 根據網際網路安全性中心的基準,改善了安全性強化
由於這些變更,使用升級指令碼的標準升級程序無法正常運作。需要特定的升級程序。它位於以下產品手冊中。此程序的目的是要將 3.3.2 或 3.4 閘道虛擬機器取代為新的 4.0 閘道虛擬機器。請參閱下列文件:VMware SD-WAN 合作夥伴閘道升級以及從 3.3.2 或 3.4 移轉至 4.0
此升級程序需要 SASE Orchestrator 系統內容組態,只有 SASE Orchestrator 操作員帳戶可執行此操作。請向 VMware 支援團隊提出支援申請單,以要求系統內容變更。
監控
- SD-WAN 控制器監控
您可以監控操作員入口網站中的可用控制器的狀態和使用量資料。
程序如下所示:
- 在操作員入口網站中,按一下閘道 (Gateways)。
- 閘道 (Gateways) 頁面會顯示可用控制器的清單。
- 按一下閘道的連結。所選控制器的詳細資料隨即顯示。
- 按一下 [監控 (Monitor)] 索引標籤,以檢視所選控制器的使用量資料。
所選控制器的 [監控 (Monitor)] 索引標籤會顯示如下圖所示的詳細資料。
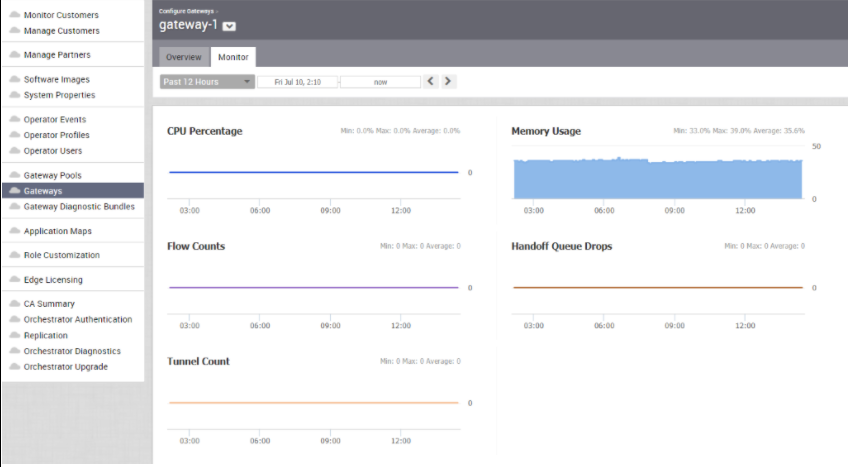
您可以選擇特定期間以在頁面頂端於所選期間檢視控制器的詳細資料。
此頁面會以圖形顯示下列參數在所選持續時間內的使用量詳細資料,以及最小值、最大值和平均值。
| 使用量 | 說明 |
|---|---|
| CPU 百分比 (CPU Percentage) | CPU 使用率百分比 (Percentage of usage of CPU) |
| 記憶體使用量 (Memory Usage) | 記憶體使用量百分比 (Percentage of usage of memory) |
| 流量計數 (Flow Counts) | 流量的計數 |
| 遞交佇列捨棄數 (Handoff Queue Drops) | 由於已排入佇列遞交而捨棄的封包計數 |
| 通道計數 (Tunnel Count) | 通道工作階段的計數 |
- SD-WAN 閘道控制器建議的監控值
下列清單顯示應監控的值及其臨界值。提供下列清單可作為起點,並非詳盡資訊。部分部署可能需要評估其他元件,例如流量、封包遺失等。
一旦達到警告臨界值,建議您檢閱目前的裝置規模組態,並視需要新增更多資源。觸發嚴重警示時,請務必連絡 VMware 支援代表,以查看解決方案並提供進一步建議。
表 4. 要監控的建議值 服務檢查 服務檢查說明 警告臨界值 嚴重臨界值 CPU 負載 (CPU Load) 檢查系統負載。 60 80 記憶體 檢查記憶體使用量緩衝區、快取和已使用的記憶體。 70 80 通道 來自已連線 SD-WAN Edge 的通道數目。 最大規模的 60% 最大規模的 80% 附註:所有通道突然遺失或異常低的數量也應該是一項顧慮。
遞交捨棄 (Handoff Drops) 由於流量經過控制器期間會出現忙碌的本質,因此可預期偶爾會出現捨棄。 特定佇列若持續出現捨棄則可能表示有容量問題。 磁碟空間 (Disk Space) 目前磁碟使用量 40% 可用 20% 可用 控制器 NTP (Controller NTP) 檢查時間偏移 5 秒的偏移 10 秒的偏移
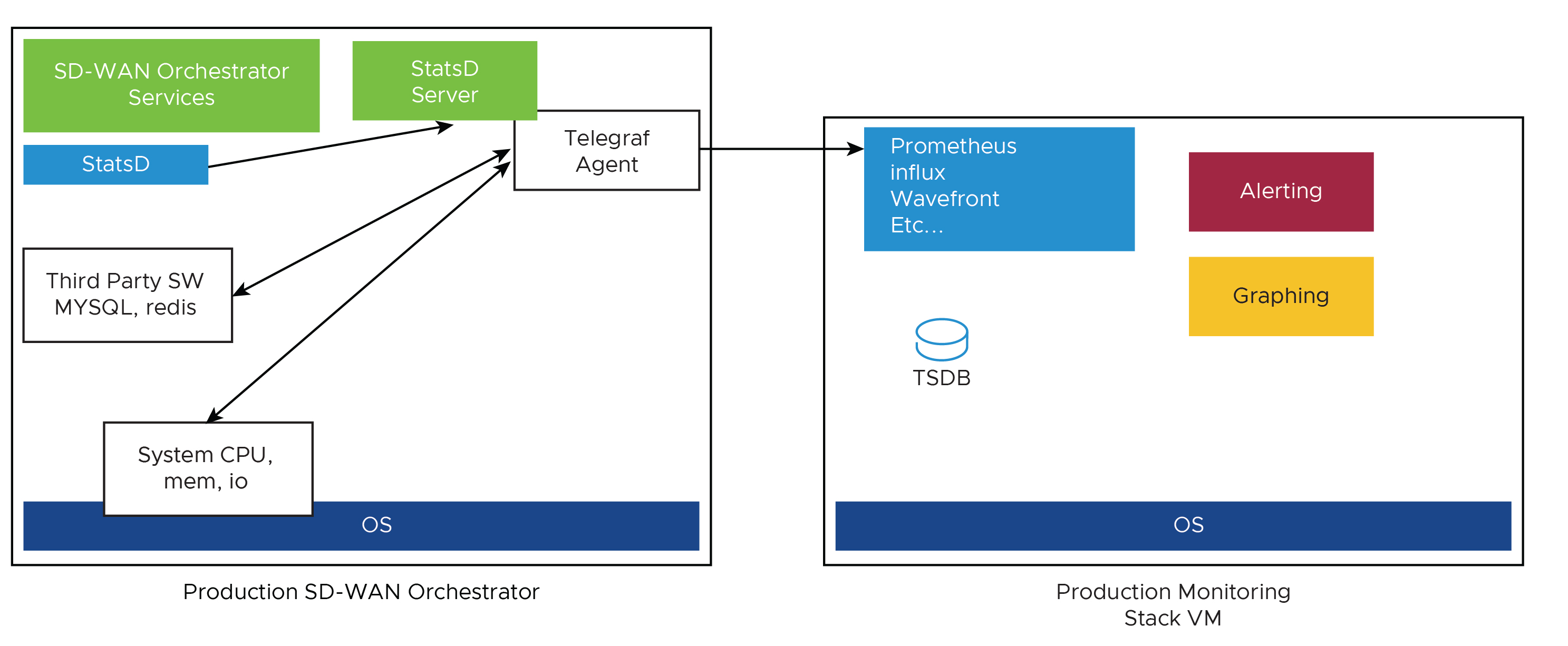
- SASE Orchestrator 與監控堆疊整合
SASE Orchestrator 隨附內建的系統度量監控堆疊,其可以連結至外部度量收集器和時間序列資料庫。您可以使用監控堆疊快速檢查 SASE Orchestrator 的健全狀況條件和系統負載。
-
- 若要啟用監控堆疊,請在 Orchestrator 上執行下列命令:
sudo /opt/vc/scripts/vco_observability_manager.sh enable
- 若要檢查監控堆疊的狀態,請執行:
sudo /opt/vc/scripts/vco_observability_manager.sh status
- 若要停用監控堆疊,請執行:
sudo /opt/vc/scripts/vco_observability_manager.sh disable
- 若要啟用監控堆疊,請在 Orchestrator 上執行下列命令:
- 度量收集器
Telegraf 會用作 SASE Orchestrator 系統度量收集器,其中包括用於收集不同系統度量的許多外掛程式。依預設會啟用下列度量。
表 5. 度量收集器 度量名稱 說明 支援的版本 inputs.cpu 有關 CPU 使用率的度量。 3.4/4.0 inputs.mem 有關記憶體使用量的度量。 3.4/4.0 inputs.net 有關網路介面的度量。 4.0 inputs.system 有關系統負載和運作時間的度量。 4.0 inputs.processes 按狀態分組的程序數目。 4.0 inputs.disk 有關磁碟使用量的度量。 4.0 inputs.diskio 有關按裝置統計磁碟 IO 的度量。 4.0 inputs.procstat 特定程序的 CPU 和記憶體使用量。 4.0 inputs.nginx Nginx 的基本狀態資訊 (ngx_http_stub_status_module)。 4.0 inputs.mysql 來自 MySQL 伺服器的統計資料。 3.4/4.0 inputs.redis 來自一或多個 redis 伺服器的度量。 3.4/4.0 inputs.statds API 和系統度量。 3.4/4.0 (4.0 中包含其他度量) inputs.filecount 指定目錄中檔案的數目和大小總計。 4.0 inputs.ntpq 標準 NTP 查詢度量,需要 ntpq 可執行檔。 4.0 Inputs.x509_cert 來自 SSL 憑證的度量。 4.0 若要啟用更多度量或停用某些已啟用的度量,您可以在 SASE Orchestrator 上編輯 Telegraf 組態檔,方法為:
sudo vi /etc/telegraf/telegraf.d/system_metrics_input.conf
sudo systemctl restart telegraf
- 時間序列資料庫
時間序列資料庫可用於儲存 Telegraf 所收集的系統度量。時間序列資料庫 (TSDB) 是針對時間序列資料最佳化的資料庫。
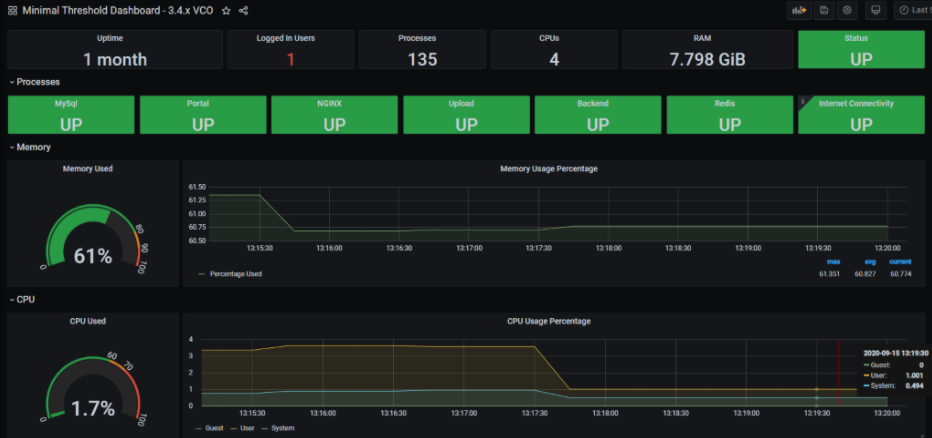
- 儀表板和警示代理程式
儀表板和警示代理程式可讓您查詢、視覺化、警示,以及探索儲存在 TSDB 中的資料。此影像是使用可建立以用於監控解決方案之 Telegraph (TSDB 和儀表板引擎) 的儀表板範例。
- 時間序列資料庫設定
依照下列指示來設定時間序列資料庫。
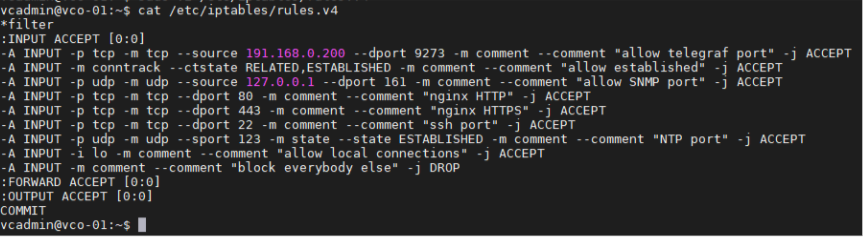
- 新增 iptables 項目,以允許外部監控系統存取 Telegraf 連接埠。基於安全性理由,應指定來源 IP 位址。
- 範例。外部監控系統的 IP 位址為 191.168.0.200 將「-A INPUT -p tcp -m tcp --source 191.168.0.200 --dport 9273 -m comment --comment "allow telegraf port" -j ACCEPT」新增至 /etc/iptables/rules.v4
- 重新啟動 iptables。
sudo service iptables-persistent restart (Orchestrator 3.4.x)
sudo systemctl restart netfilter-persistent (Orchestrator 4.x)
- 確保已新增 iptables 項目。
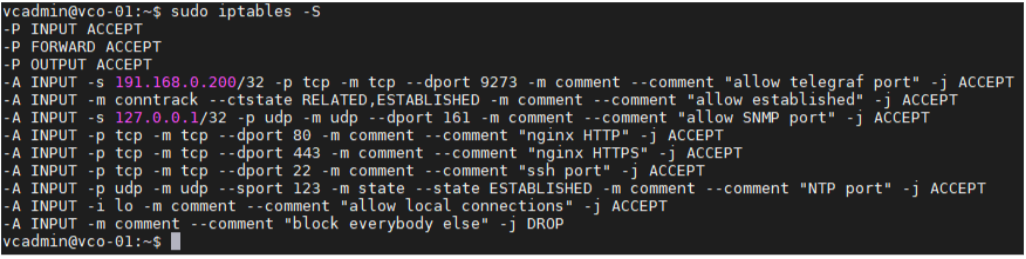
- 範例。外部監控系統的 IP 位址為 191.168.0.200 將「-A INPUT -p tcp -m tcp --source 191.168.0.200 --dport 9273 -m comment --comment "allow telegraf port" -j ACCEPT」新增至 /etc/iptables/rules.v4
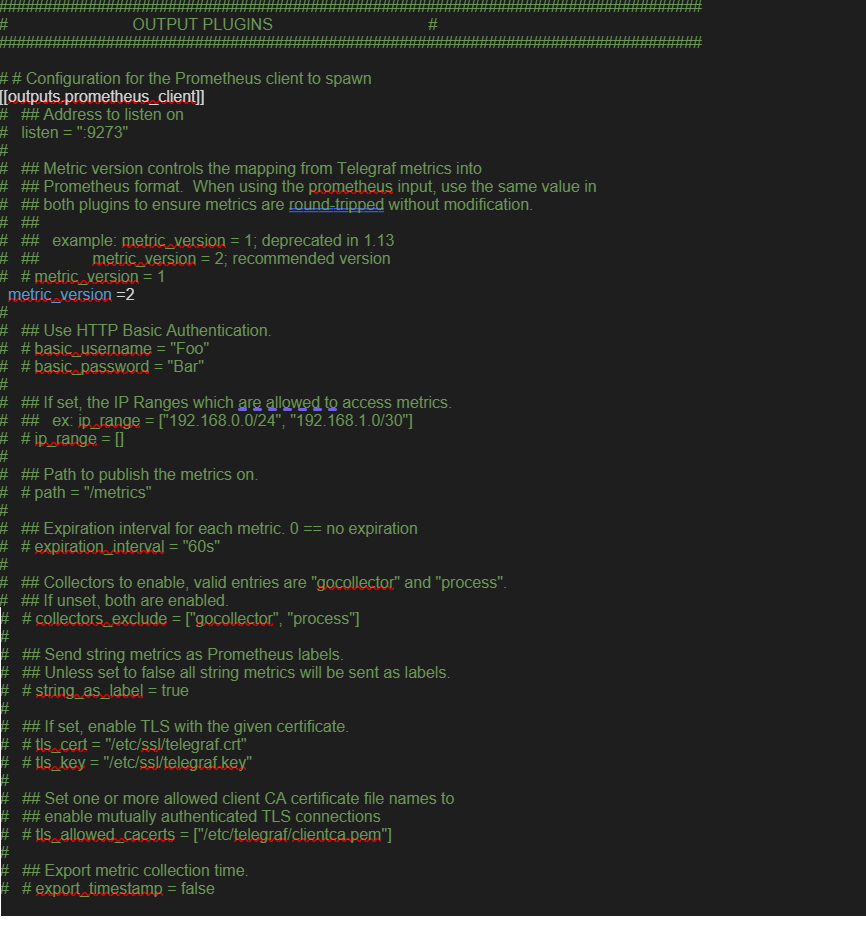
- 在 Telegraf 組態中新增時間序列資料庫詳細資料。建立輸出組態檔。使用 prometheus 的範例如下所示:
/etc/telegraf/telegraf.d/prometheus_out.conf
- SASE Orchestrator 建議的監控值
下列清單顯示應監控的值的清單及其臨界值。提供下列清單可作為起點,因為並不詳盡。部分部署可能需要評估其他元件,例如資料庫交易、自動備份等。
一旦達到警告臨界值,建議您檢閱目前的裝置規模組態,並視需要新增更多資源。觸發嚴重警示時,請務必連絡 VMware 支援代表,以查看解決方案並提供進一步建議。表 6. 監控值和臨界值 服務檢查 服務檢查說明 警告臨界值 嚴重臨界值 CPU 負載 (CPU Load) 檢查系統負載 - Telegraf 輸入外掛程式:inputs.cpu。 60 70 記憶體 檢查記憶體使用量緩衝區、快取和已使用的記憶體 - Telegraf 輸入外掛程式:inputs.memory。 70 80 磁碟使用量 (Disk Usage) 不同 Orchestrator 磁碟分割,/、/store、/store2 和 /store3 (4.0 版及更高版本) 中的磁碟使用量 - Telegraf 輸入外掛程式:inputs.disk (4.0 版及更高版本)。 40% 可用 20% 可用 MySQL Server 檢查 MySQL 連線 - Telegraf 輸入外掛程式:inputs.mysql。 超出 mysql.conf (/etc/mysql/my.cnf) 中定義連線上限的 80% SASE Orchestrator 時間 檢查時間偏移 - Telegraf 輸入外掛程式:inputs.ntpq (4.0 版及更高版本)。 5 秒的偏移 10 秒的偏移 SASE Orchestrator SSL 憑證 檢查憑證到期 - Telegraf 輸入外掛程式:inputs.x509_cert (4.0 版及更高版本)。 60 天 30 天 SASE Orchestrator 網際網路 (不適用於僅限 MPLS 的拓撲) 檢查網際網路存取。 回應時間 > 5 秒 回應時間 > 10 秒 SASE Orchestrator HTTP 確保 localhost 上的 HTTP 有回應。 localhost 沒有回應。 SASE Orchestrator 總憑證數 檢查總計 - 範例 mysql 查詢: SELECT count(id) FROM VELOCLOUD_EDGE_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()', 'SELECT count(id) FROM VELOCLOUD_GATEWAY_CERTIFICATE WHERE validFrom <= NOW() AND validTo >=NOW()
CRL 總計憑證計數超過 5000 時 DR 複寫狀態 (DR Replication Status) 確認待命 Orchestrator 處於最新狀態。 檢閱 DR SASE Orchestrator 在作用中 Orchestrator 後方不超過 1000 秒。 Seconds_Behind_Master:從 mysql 命令:show slave STATUS\G;
DR 複寫 SD-WAN Edge 閘道差異 確認 SD-WAN Edge 和 SD-WAN 閘道 可以與 DR SASE Orchestrator 通訊。 作用中和待命 Orchestrator 之間的值不同,可能是因為 SD-WAN Edge 和 SD-WAN 閘道 上的時區具有差異。
與作用中 Orchestrator 通訊的相同數量的 SD-WAN Edge 應該能夠連線至待命 Orchestrator。可以在 [複寫 (replication)] 索引標籤上或透過 API 檢查此值。
API 最佳做法
- SASE Orchestrator 入口網站
SASE Orchestrator 入口網站允許網路管理員 (或代表其運作的指令碼和應用程式) 來管理網路和裝置的組態,以及查詢目前或歷史網路及裝置狀態。API 用戶端可以透過 JSON-RPC 介面或類似 REST 的介面與入口網站進行互動。您可以使用任一介面叫用本文件中所述的所有方法。沒有任何入口網站功能屬於限制 JSON-RPC 用戶端或類似 REST 用戶端才能存取。
這兩個介面僅接受 HTTP POST 要求。兩者也會預期要求本文 (如果存在) 採用 JSON 格式以與 RFC 2616 一致,用戶端也可能會在使用內容類型要求標頭 (例如,內容類型:application/json) 的情況下正式進行判斷。
您可以在此處找到有關 VMware SD-WAN API 的詳細資訊:
- 使用 API 的企業和服務提供者的最佳做法
使用 API 時的一些最佳做法是:
- 若可能,應針對企業特定的 API 優先使用彙總 API 呼叫。例如,對 monitoring/getAggregateEdgeLinkMetrics 的單一呼叫可能用來在所有 SD-WAN Edge 之間並行擷取傳輸統計資料。
- VMware 要求用戶端將任何指定時間內傳遞的 API 呼叫數目限制在不超過一定數量 (例如 <2-4)。如果使用者認為有理由並行處理 API 呼叫,則 VMware 會要求使用者連絡 VMware 支援,以討論替代解決方案。
- 我們通常不建議以高於每隔 10 分鐘的頻率輪詢 API 以取得統計資料。新的統計資料每 5 分鐘抵達 SASE Orchestrator 一次。由於報告/處理中的抖動,每 5 分鐘輪詢一次的用戶端可能會發現「誤報」的情況,其中的統計資料未在 API 呼叫的結果中反映。使用者傾向於在持續期間內使用 10 分鐘或更長的要求間隔來尋找最佳結果。
- 避免重複查詢相同資訊。
- 在 API 之間使用睡眠。
- 對於複雜的軟體自動化,請執行您的指令碼,並評估 CPU/記憶體影響。然後視需要調整。
SASE Orchestrator Syslog 組態
VMware SASE Orchestrator Syslog 功能可針對下列 Orchestrator 程序獨立設定:入口網站、上傳和後端。
- 入口網站:入口網站程序會以來自 NGINX 的內部 HTTP 伺服器下游形式執行。入口網站服務會處理來自 SASE Orchestrator Web 介面或來自 HTTP/SDK 用戶端的傳入 API 要求,主要以同步方式進行處理。這些要求會允許經驗證的使用者設定、監控和管理 SASE Orchestrator 所提供的各種服務。
此記錄對 AAA 活動非常有用,因為它具有 SASE Orchestrator 中使用者採取的所有動作。
記錄檔:/var/log/portal/velocloud.log (記錄所有資訊、警告和錯誤記錄)
- 上傳:上傳程序會以來自 NGINX 的內部 HTTP 伺服器下游形式執行。上傳服務會處理來自 SD-WAN Edge 和 SD-WAN 閘道 的傳入要求 (可能同步或非同步)。這些要求主要由 SD-WAN Edge 和 SD-WAN 閘道 所傳送的啟動、活動訊號、流量統計資料、連結統計資料和路由資訊所組成。
記錄檔:/var/log/upload/velocloud.log (記錄所有資訊、警告和錯誤記錄)
- 後端:工作執行程式,主要執行排程或排入佇列的工作。排程的工作由清理、彙總或狀態更新活動所組成。排入佇列的工作由處理連結和流量統計資料所組成。
記錄檔:/var/log/backend/velocloud.log (記錄所有資訊、警告和錯誤記錄)
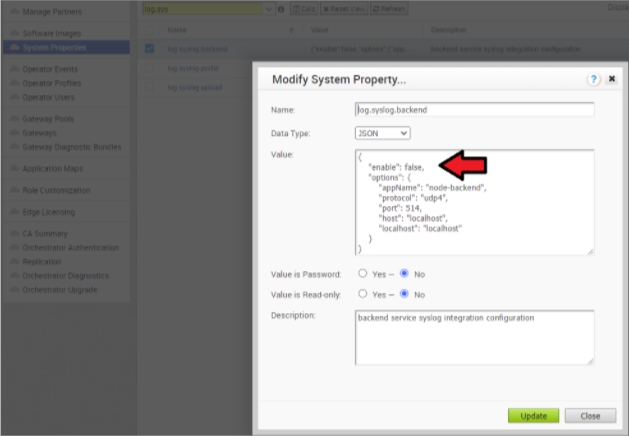
- 導覽至 SASE Orchestrator 中的系統內容 log.syslog.<server> (例如 log.syslog.portal)。移至 [SASE Orchestrator] → [系統內容 (System Properties)] → 在搜尋列中輸入「log.syslog」
- 為一或多個伺服器將「enable」:false 值變更為 true。根據您的實作相應地變更主機 IP 和連接埠。
增加 SASE Orchestrator 中的儲存區
增加 SASE Orchestrator 中儲存區的詳細指示,可以在 SASE Orchestrator
說明文件中找到,網址:https://docs.vmware.com/,位於〈安裝 SASE Orchestrator〉和〈擴充磁碟大小 (VMware)〉下方
- 最佳做法:
- 確保將相同的 LVM 分配套用至待命 Orchestrator。
- 不建議在增加磁碟區大小後將其縮減。請改為使用精簡佈建。
- 在 3.4 中,增加磁碟大小時,可能會使用下列百分比/值分配:
- 「/」磁碟區:此磁碟區用於運作中的系統。生產 Orchestrator 通常設定為 140 GB,並具有 40% 到 60% 的使用量。
- /store 和 /store2:在生產 Orchestrator 中套用的比例接近 85% 用於 /store,而 15% 用於 /store2。
- 表格中的下列準則應該用於 4.x 版及更高版本。
執行個體大小 /store /store2 /store3 /var/log 小型 (5000 個 SD-WAN Edge) 2 TB 500GB 8TB 15GB 中型 (10000 個 SD-WAN Edge) 2 TB 500GB 12TB 20GB 大型 (15000 個 SD-WAN Edge) 2 TB 500GB 16TB 25GB
在 SASE Orchestrator 中管理憑證
SASE Orchestrator 使用內建的憑證伺服器來管理所有 SD-WAN Edge 和 SD-WAN 控制器的整體 PKI 生命週期。對網路中的裝置發出 x.509 憑證。
您可以在官方 VMware SD-WAN 操作員說明文件網站 (https://docs.vmware.com/tw/VMware-SD-WAN/index.html) 上的〈安裝 SASE Orchestrator〉和〈安裝 SSL 憑證〉下方,找到設定 CA 的詳細指示。
- SASE Orchestrator 和 SD-WAN Edge SD-WAN 控制器之間的管理平面 TLS 1.2 通道。
- SD-WAN Edge 之間以及 SD-WAN Edge 與 SD-WAN 控制器之間的控制和資料平面 IKEv2/IPSec 通道。
憑證撤銷清單
vcadmin@vcg1-example:~$ openssl crl -in /etc/vc-public/vco-ca-crl.pem -text | grep 'Serial Number' | wc -l 14 vcadmin@vcg1-example:~
支援互動
我們的客戶支援組織為 VMware SD-WAN 客戶提供全天候、全年無休的世界級技術協助和個人化準則。
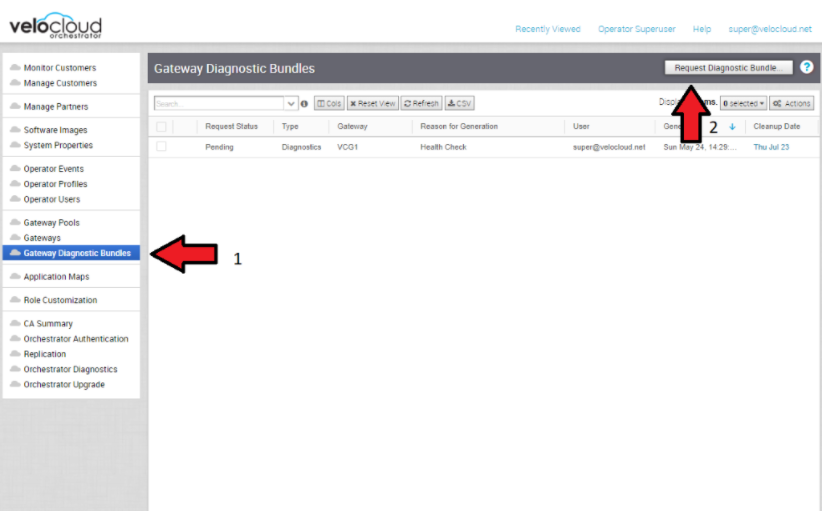
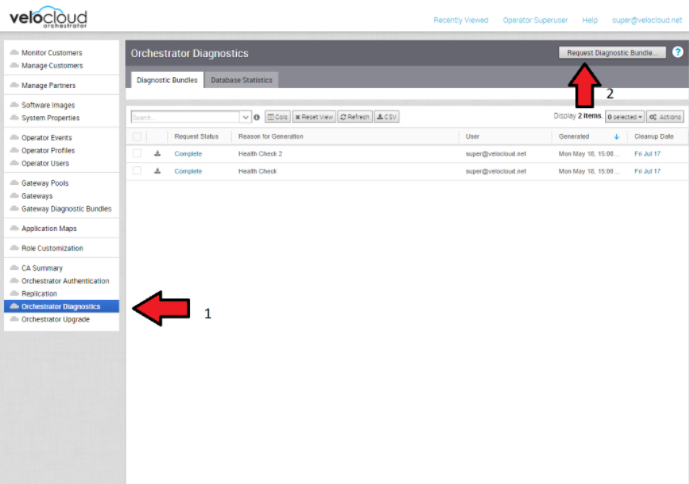
- 診斷服務包
調查事件時,可以建立 SASE Orchestrator 和 SD-WAN 控制器的診斷服務包。產生的檔案將協助 VMware 支援團隊進一步分析問題的相關事件。
- 與支援人員共用存取權
有時候,您可能需要 VMware 支援代表提供 SASE Orchestrator 和 SD-WAN 控制器的相關協助。
授與存取權的一些常見方式如下:- 支援人員的遠端工作階段:客戶會將遠端控制授與 SSH 跳躍伺服器,或遵循支援代表的指示。
- 在 SASE Orchestrator 中建立支援團隊的帳戶。這可協助支援團隊收集記錄而不需要與客戶互動。
- 透過堡壘主機:可以設定 SSH 權限和金鑰,以允許支援工程師使用堡壘主機存取內部部署的 SASE Orchestrator 和 SD-WAN 控制器。
連絡 VMware SD-WAN 支援以協助分級問題時,請納入下表所述的資料。
您可以在下列連結中找到詳細資訊:https://kb.vmware.com/s/article/53907
| 必要 | 建議 |
|---|---|
| 合作夥伴案例編號 | 問題開始/停止 |
| 合作夥伴回覆電子郵件/電話 | 受影響的流程 SRC/DST IP |
| SASE Orchestrator URL | 受影響的流程 SRC/DST 連接埠 |
| SASE Orchestrator 中的客戶名稱 | 流量路徑 (E2E、E2GW、直接) |
| 客戶影響 (高/中/低) | SD-WAN 閘道名稱 |
| SD-WAN Edge 名稱 | SASE Orchestrator 中 PCAP 的連結 |
| SASE Orchestrator 中診斷服務包的連結 | |
| 簡短問題陳述 | |
| 分析與要求的協助 |
