









將工作負載叢集部署到專用硬體
Tanzu Kubernetes Grid 支援在 vSphere 7.0 及更新版本上將工作負載叢集部署到特定類型且啟用了 GPU 的主機。
部署啟用了 GPU 的工作負載叢集
若要在 vSphere 工作負載叢集中,使用具有 GPU 的節點,必須啟用 PCI 傳遞模式。這允許叢集略過 ESXi 主管直接存取 GPU,從而提供類似於原生系統上的 GPU 效能的效能層級。使用 PCI 傳遞模式時,每個 GPU 裝置都專用於 vSphere 工作負載叢集中虛擬機器 (VM)。
附註若要將啟用了 GPU 的節點新增到現有叢集,請使用
tanzu cluster node-pool set命令。
必要條件
- 具有 NVIDIA V100 或 NVIDIA Tesla T4 GPU 卡的 ESXi 主機。
- vSphere 7.0 Update 3 及更新版本。以下列出 7.0u3 的組建編號,這是支援此功能所需的最低版本。
- Tanzu Kubernetes Grid v1.6+。
- Helm,這是 Kubernetes 套件管理程式。若要安裝,請參閱 Helm 說明文件中的安裝 Helm。
程序
若要建立工作負載叢集,且其中含有啟用了 GPU 的主機,請遵循以下步驟,來啟用 PCI 傳遞、建置自訂機器映像、建立叢集組態檔和 Tanzu Kubernetes 版本、部署工作負載叢集,以及使用 Helm 來安裝 GPU Operator。
-
將具有 GPU 卡的 ESXi 主機新增到 vSphere Client。
-
啟用 PCI 傳遞,並記錄 GPU 識別碼,如下所示:
- 在 vSphere Client 中,選取
GPU叢集中的目標 ESXi 主機。 - 選取設定 (Configure) > 硬體 (Hardware) > PCI 裝置 (PCI Devices)。
- 選取所有 PCI 裝置索引標籤。
- 從清單中選取目標 GPU。
- 按一下切換傳遞 (Toggle Passthrough)。
- 在 [一般資訊 (General Information)] 下,記錄 [裝置識別碼 (Device ID)] 和 [廠商識別碼 (Vendor ID)] (在下圖中以綠色反白顯示)。相同的 GPU 卡會有相同的識別碼。對於叢集組態檔,您將需要這些。
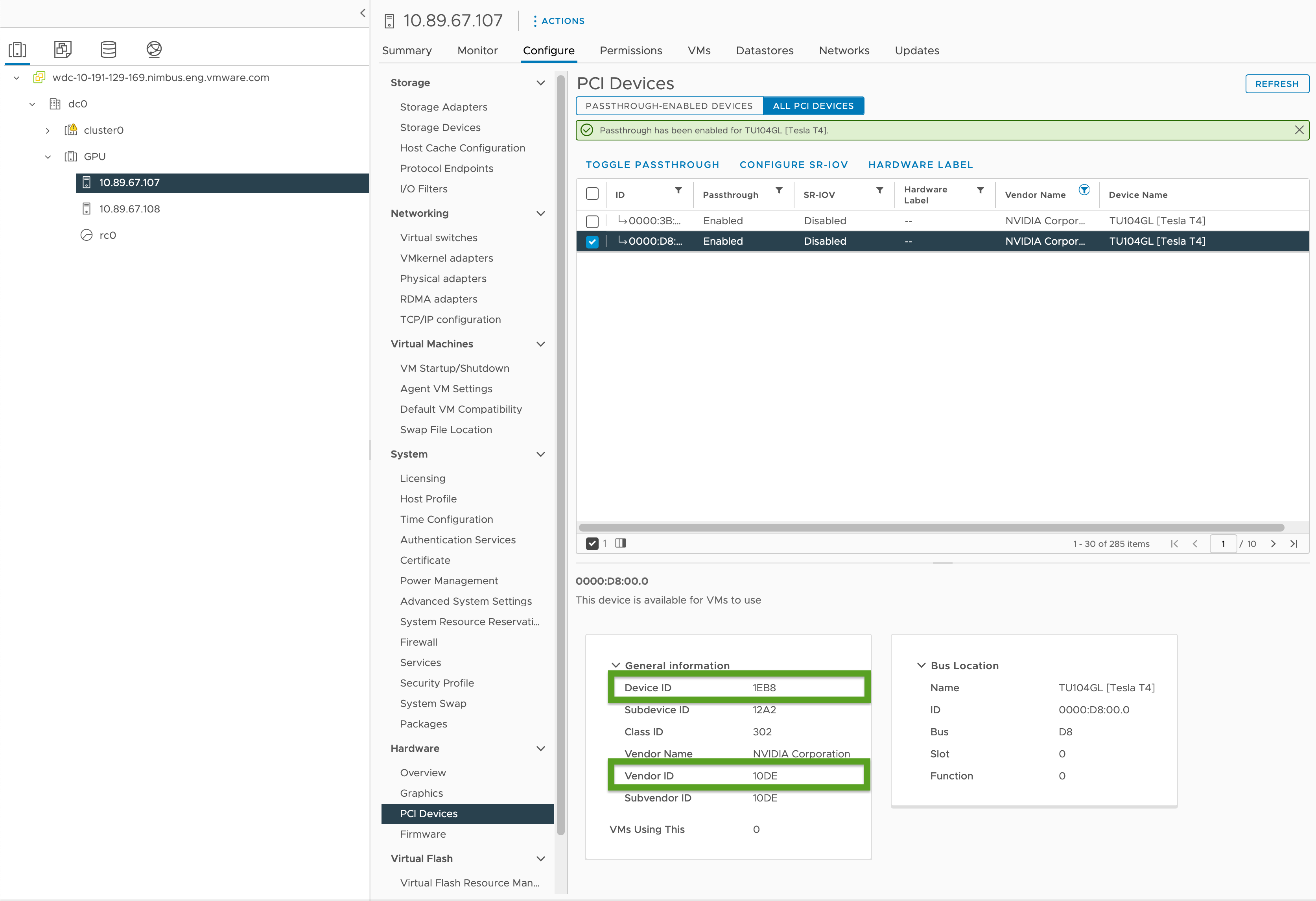
- 在 vSphere Client 中,選取
-
使用工作負載叢集範本中的範本來建立工作負載叢集組態檔,並包含以下變數:
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"其中:
<VENDOR-ID>和<DEVICE-ID>是您在上一個步驟中記錄的廠商識別碼和裝置識別碼。例如,如果廠商識別碼為10DE,裝置識別碼為1EB8,則值為"0x10DE:0x1EB8"。<GPU-SIZE>是叢集中所有 GPU 的框架緩衝區記憶體 GB 總計,且會四捨五入到下一個更高的 2 的乘冪。- 例如,對於兩個 40 GB GPU,緩衝區記憶體總計為 80 GB,四捨五入為 128 GB;因此,請將該值設定為
pciPassthru.64bitMMIOSizeGB=128。 - 若要找出 GPU 卡所需的記憶體,請參閱 NVIDIA GPU 卡特定的說明文件。請參閱 NVIDIA 說明文件中的資料表在需要 64 GB 或以上 MMIO 空間的 GPU 上使用 vGPU 與大型記憶體虛擬機器的需求。
- 另請參閱:
- 例如,對於兩個 40 GB GPU,緩衝區記憶體總計為 80 GB,四捨五入為 128 GB;因此,請將該值設定為
- 如果您使用的是 NVIDIA Tesla T4 GPU,則
<BOOLEAN>為false;如果使用的是 NVIDIA V100 GPU,則為true。 <VSPHERE_WORKER_HARDWARE_VERSION>是我們要虛擬機器升級到的虛擬機器硬體版本。GPU 節點所需的最低版本應為 17。- 如果有額外的 PCI 裝置可在升級期間供工作節點使用,則
WORKER_ROLLOUT_STRATEGY為RollingUpdate,否則請使用OnDelete。
附註
每個虛擬機器只能使用一種 GPU 類型。例如,不能在單一虛擬機器上同時使用 NVIDIA V100 和 NVIDIA Tesla T4,但可以使用具有相同廠商識別碼和裝置識別碼的多個 GPU 執行個體。
tanzuCLI 不允許更新MachineDeployment上的WORKER_ROLLOUT_STRATEGY規格。如果叢集升級因 PCI 裝置無法使用而停滯,VMware 建議使用kubectlCLI 來編輯MachineDeployment策略。推出策略定義在spec.strategy.type中。如需可以設定給啟用了 GPU 的叢集的完整變數清單,請參閱〈組態檔變數參考〉中的啟用了 GPU 的叢集。
-
透過執行以下命令,來建立工作負載叢集:
tanzu cluster create -f CLUSTER-CONFIG-NAME其中
CLUSTER-CONFIG-NAME是您在先前的步驟中建立的叢集組態檔的名稱。 -
新增 NVIDIA Helm 存放庫。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
安裝 NVIDIA GPU Operator:
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator其中,
KUBECONFIG是工作負載叢集kubeconfig的名稱和位置。如需詳細資訊,請參閱擷取工作負載叢集kubeconfig。如需此命令中的參數的相關資訊,請參閱 NVIDIA 說明文件中的安裝 GPU Operator。
-
確定 NVIDIA GPU Operator 正在執行:
kubectl --kubeconfig=./KUBECONFIG get pods -A輸出類似於:
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
測試 GPU 叢集
若要測試啟用了 GPU 的叢集,請為 Kubernetes 說明文件中的 cuda-vector-add 範例建立網繭資訊清單,並進行部署。容器將下載、執行並使用 GPU 來執行 CUDA 計算。
-
建立一個名為
cuda-vector-add.yaml的檔案,並新增以下內容:apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
套用檔案:
kubectl apply -f cuda-vector-add.yaml -
執行:
kubectl get po cuda-vector-add輸出類似於:
cuda-vector-add 0/1 Completed 0 91s -
執行:
kubectl logs cuda-vector-add輸出類似於:
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
將工作負載叢集部署到 Edge 網站
Tanzu Kubernetes Grid v1.6+ 支援將工作負載叢集部署到 Edge VMware ESXi 主機。如果希望在不同的位置執行多個 Kubernetes 叢集,這些叢集全部由中央管理叢集管理,則可以使用此方法。
拓撲:您可以在具有單一控制平面節點且僅具有一或兩個主機的生產環境中,執行 Edge 工作負載叢集。但是,儘管這使用的 CPU、記憶體和網路頻寬較少,但卻沒有標準生產 Tanzu Kubernetes Grid 叢集的彈性和復原特性。如需詳細資訊,請參閱 VMware Tanzu Edge 解決方案參考架構 1.0。
本機登錄:為了盡可能地減少通訊延遲及提高彈性,每個 Edge 叢集應具有自己的本機 Harbor 容器登錄。如需此架構的概觀,請參閱〈架構概觀〉中的容器登錄。要安裝本機 Harbor 登錄,請參閱 vSphere 上的部署離線 Harbor 登錄。
逾時:此外,當 Edge 工作負載叢集的管理叢集位於遠端的主要資料中心時,您可能需要調整特定的逾時,讓管理叢集有足夠的時間與工作負載叢集機器連線。若要調整這些逾時,請參閱下面的延長 Edge 叢集的逾時以處理較高的延遲。
指定本機虛擬機範本
如果您的 Edge 工作負載叢集使用自己的隔離儲存區,而不是共用 vCenter 儲存區,則必須將其從本機儲存區中擷取節點虛擬機器範本映像作為 OVA 檔。
附註您無法使用
tanzu cluster upgrade升級使用本機虛擬機器範本的 Edge 工作負載叢集的 Kubernetes 版本。但可以按照《升級工作負載叢集》主題中的升級具有本機虛擬機器範本的 Edge 叢集升級叢集。
要為叢集指定單一虛擬機器範本或特定於 worker 節點和控制平面機器部署的不同範本,請執行以下操作:
-
建立叢集組態檔案,並按照 建立基於類別的叢集中所述的兩步驟程序的步驟 1 產生叢集資訊清單。
-
確保叢集的虛擬機器範本:
- 具有 TKG 的有效 Kubernetes 版本。
- 具有與 TKr 的
spec.osImages屬性相符的有效 OVA 版本。 - 上傳到本機 vCenter 並具有有效的清單路詳細目錄徑,例如
/dc0/vm/ubuntu-2004-kube-v1.27.5+vmware.1-tkg.1。
-
編輯清單中的
Cluster物件規格,如下所示,具體取決於您是定義叢集範圍的虛擬機器範本還是多個虛擬機器範本:-
叢集範圍的虛擬機器範本:
- 在
annotations之下,將run.tanzu.vmware.com/resolve-vsphere-template-from-path設為空字串。 - 在
vcenter區塊的spec.topology.variables下,將template設為虛擬機器範本的詳細目錄路徑。 -
例如:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...其中,
VM-TEMPLATE是叢集的虛擬機器範本的路徑。
- 在
-
每個
machineDeployment的多個虛擬機器範本:- 在
annotations之下,將run.tanzu.vmware.com/resolve-vsphere-template-from-path設為空字串。 - 在
variables.overrides中,針對每個machineDeployments區塊的spec.topology.worker和controlplane之下,為vcenter新增一行,以將template設為虛擬機器範本的詳細目錄路徑。 -
例如:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...其中,
VM-TEMPLATE是machineDeployment的虛擬機器範本的路徑。
- 在
-
-
按照建立以類別為基礎的叢集中所述的程序的步驟 2,使用修改後的組態檔建立叢集。
延長 Edge 叢集的逾時以處理更久的延遲
如果您的管理叢集會從遠端來管理在 Edge 網站上執行的工作負載叢集,或管理超過 20 個工作負載叢集,則可以調整特定的逾時,以便叢集 API 不會封鎖或刪除可能暫時離線或需要超過 12 分鐘才能與其遠端管理叢集通訊的機器 (尤其是當您的基礎結構佈建不足時)。
您可以調整三項設定,讓您的 Edge 叢集有額外的時間來與其控制平面進行通訊:
-
MHC_FALSE_STATUS_TIMEOUT:將預設12m延長至例如40m,以防止MachineHealthCheck控制器重建機器 (如果其Ready條件維持False超過 12 分鐘)。如需有關機器健全狀況檢查的詳細資訊,請參閱設定 Tanzu Kubernetes 叢集的機器健全狀況檢查。 -
NODE_STARTUP_TIMEOUT:將預設20m延長至例如60m,以防止MachineHealthCheck控制器因為新機器啟動時間超過 20 分鐘,被視為狀況不良,而封鎖新機器加入叢集。 -
etcd-dial-timeout-duration:例如,在capi-kubeadm-control-plane-controller-manager資訊清單中,將預設10m延長到40s,以阻止管理叢集上的etcd用戶端在掃描工作負載叢集上etcd的健全狀況時提前失敗。管理叢集會根據它能否與etcd連線,作為機器健全狀況的衡量標準。例如:-
在終端機中執行:
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
變更
--etcd-dial-timeout-duration的值:- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
此外,您需要注意:
-
capi-kubedm-control-plane-manager:如果它以某種方式與工作負載叢集「分離」,您可能需要將它退回到新節點,以便它可以適當地監控工作負載叢集中的
etcd。 -
TKG 中的 Pinniped 組態都會假設工作負載叢集已連線到管理叢集。萬一連線中斷,您應該確定工作負載網繭正在使用管理帳戶或服務帳戶,與 Edge 站台上的 API 伺服器進行通訊。否則,一旦與管理叢集中斷連線,會干擾 Edge 站台,使其無法透過 Pinniped 對其本機工作負載 API 伺服器進行驗證。
