瞭解如何將 Telegraf 收集的 主管 度量串流到自訂可觀測性平台。依預設,Telegraf 在 主管 上處於啟用狀態,它採用 Prometheus 格式從 主管 元件 (如 Kubernetes API 伺服器、虛擬機器服務、Tanzu Kubernetes Grid 等) 收集度量。身為 vSphere 管理員,您可以設定可觀察性平台 (如 VMware Aria Operations for Applications、Grafana 等),以檢視和分析收集的 主管 度量。
Telegraf 是以伺服器為基礎的代理程式,用於從不同的系統、資料庫和 IoT 收集和傳送度量。每個 主管 元件都會公開端點,供 Telegraf 進行連線。然後 Telegraf 會將收集的度量傳送到您選擇的可觀察性平台。您可以將 Telegraf 支援的任何輸出外掛程式設定為可觀察性平台,以彙總和分析 主管 度量。如需支援的輸出外掛程式,請參閱 Telegraf 說明文件。
以下元件公開了相應端點,供 Telegraf 連線並收集度量:Kubernetes API 伺服器、etcd、kubelet、Kubernetes 制器管理程式、Kubernetes 排程器、Tanzu Kubernetes Grid、虛擬機器服務、虛擬機器映像服務、NSX Container Plug-in (NCP)、容器儲存區介面 (CSI)、Certificate Manager、NSX 以及各種主機度量 (如 CPU、記憶體和儲存區)。
檢視 Telegraf 網繭和組態
Telegraf 在 主管 上的 vmware-system-monitoring 系統命名空間下執行。若要檢視 Telegraf 網繭和 ConfigMap:
- 使用 vCenter Single Sign-On 管理員帳戶登入 主管 控制平面。
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- 使用下列命令來檢視 Telegraf 網繭:
kubectl -n vmware-system-monitoring get pods
產生的網繭如下所示:telegraf-csqsl telegraf-dkwtk telegraf-l4nxk
- 使用下列命令來檢視 Telegraf ConfigMaps:
kubectl -n vmware-system-monitoring get cm
產生的 ConfigMaps 如下所示:default-telegraf-config kube-rbac-proxy-config kube-root-ca.crt telegraf-config
default-telegraf-configConfigMap 保留預設的 Telegraf 組態,它是唯讀的。當檔案損毀或您希望僅還原為預設值時,您可以將其用作後援選項來還原telegraf-config中的組態。您唯一可以編輯的 ConfigMap 是telegraf-config,其定義了哪些元件將度量傳送到 Telegraf 代理程式以及傳送到哪些平台。 - 檢視
telegraf-configConfigMap:kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
inputs 區段定義了 Telegraf 從中收集度量的
主管 元件的所有端點以及度量本身的類型。例如,下列輸入會將 Kubernetes API 伺服器定義為端點:
[[inputs.prometheus]]
# APIserver
## An array of urls to scrape metrics from.
alias = "kube_apiserver_metrics"
urls = ["https://127.0.0.1:6443/metrics"]
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# Dropping metrics as a part of short term solution to vStats integration 1MB metrics payload limit
# Dropped Metrics:
# apiserver_request_duration_seconds
namepass = ["apiserver_request_total", "apiserver_current_inflight_requests", "apiserver_current_inqueue_requests", "etcd_object_counts", "apiserver_admission_webhook_admission_duration_seconds", "etcd_request_duration_seconds"]
# "apiserver_request_duration_seconds" has _massive_ cardinality, temporarily turned off. If histogram, maybe filter the highest ones?
# Similarly, maybe filters to _only_ allow error code related metrics through?
## Optional TLS Config
tls_ca = "/run/secrets/kubernetes.io/serviceaccount/ca.crt"
alias 內容指示從中收集度量的元件。namepass 內容指定公開且相應地由 Telegraf 代理程式收集的元件度量。
儘管 telegraf-config ConfigMap 已包含多種度量,但您仍然可以定義其他度量。請參閱 Kubernetes 系統元件的度量和 Kubernetes 度量參考。
將可觀察性平台設定為 Telegraf
在 telegraf-config 的 outps 部分中,您可以設定 Telegraf 將其收集的度量串流到的位置。有多個選項可供選取,例如 outputs.file、outputs.wavefront、outputs.prometheus_client 和 outps-https。在 outps-https 部分中,您可以設定要用於彙總和監控 主管 度量的可觀察性平台。您可以將 Telegraf 設定為將度量傳送到多個平台。若要編輯 telegraf-config ConfigMap 並設定可觀察性平台以檢視 主管 度量,請遵循下列步驟:
- 使用 vCenter Single Sign-On 管理員帳戶登入 主管 控制平面。
kubectl vsphere login --server <control planе IP> --vsphere-username [email protected]
- 將
telegraf-configConfigMap 儲存到本機 kubectl 資料夾:kubectl get cm telegraf-config -n vmware-system-monitoring -o jsonpath="{.data['telegraf\.conf']}">telegraf.conf在對
telegraf-configConfigMap 進行任何變更之前,請確保將其儲存在版本控制系統中,以防想要還原為檔案的先前版本。如果要還原為預設組態,可以使用default-telegraf-configConfigMap 中的值。 - 使用文字編輯器 (如 VIM) 在
outputs.http區段中新增所選可觀察性平台的連線設定:vim telegraf.config
您可以直接取消對以下區段的註解並相應地編輯值,也可以根據需要新增新的outputs.http區段。#[[outputs.http]] # alias = "prometheus_http_output" # url = "<PROMETHEUS_ENDPOINT>" # insecure_skip_verify = <PROMETHEUS_SKIP_INSECURE_VERIFY> # data_format = "prometheusremotewrite" # username = "<PROMETHEUS_USERNAME>" # password = "<PROMETHEUS_PASSWORD>" # <DEFAULT_HEADERS>例如,以下是 Grafana 的outputs.http組態範例:[[outputs.http]] url = "http://<grafana-host>:<grafana-metrics-port>/<prom-metrics-push-path>" data_format = "influx" [outputs.http.headers] Authorization = "Bearer <grafana-bearer-token>"
如需有關設定儀表板和使用來自 Telegraf 的度量的詳細資訊,請參閱將度量從 Telegraf 串流到 Grafana。
以下是 VMware Aria Operations for Applications (以前為 Wavefront) 使用範例:[[outputs.wavefront]] url = "http://<wavefront-proxy-host>:<wavefront-proxy-port>"建議透過 Proxy 將度量擷取至 Aria Operations for Applications。如需詳細資訊,請參閱 Wavefront Proxy。
- 將 主管 上的現有
telegraf-config檔案取代為在本機資料夾上編輯過的檔案:kubectl create cm --from-file telegraf.conf -n vmware-system-monitoring telegraf-config --dry-run=client -o yaml | kubectl replace -f -
- 檢查新組態是否已成功儲存:
- 檢視新的 telegraf-config ConfigMap:
kubectl -n vmware-system-monitoring get cm telegraf-config -o yaml
- 檢查所有 Telegraf 網繭是否均已啟動且正在執行:
kubectl -n vmware-system-monitoring get pods
- 如果某些 Telegraf 網繭未執行,請檢查該網繭的 Telegraf 記錄以進行疑難排解:
kubectl -n vmware-system-monitoring logs <telegraf-pod>
- 檢視新的 telegraf-config ConfigMap:
應用程式儀表板的作業範例
以下是儀表板,其中顯示了透過 Telegraf 從 主管 上的 API 伺服器和 etcd 接收的度量摘要:
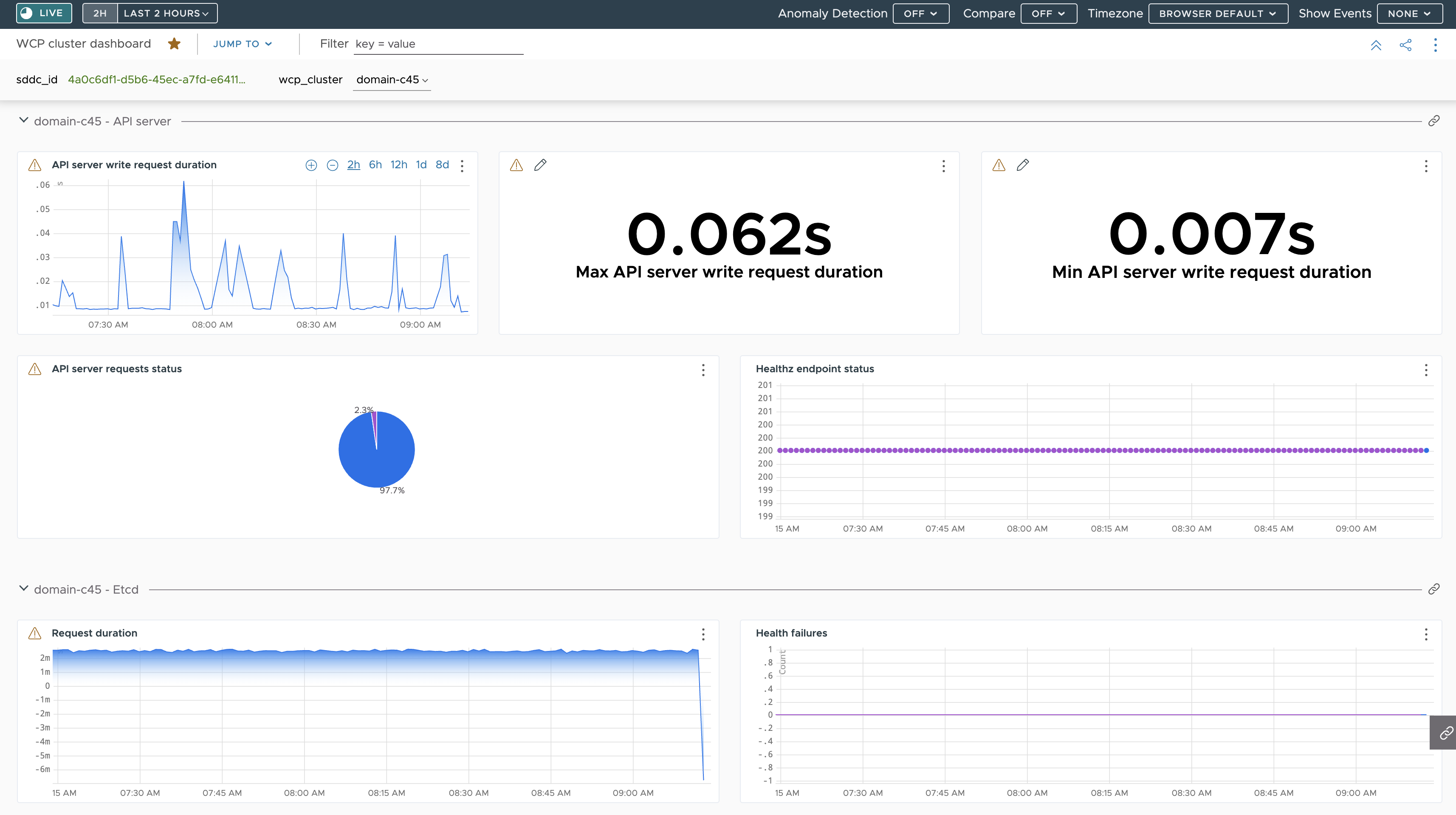
API 伺服器寫入要求持續時間 I 的度量是根據在 telegraf-config ConfigMap 中指定的度量,您可以看到這些度量以綠色反白顯示: