









叢集爭用儀表板是vSphere叢集效能的主要儀表板。專為 VMware 管理員或架構設計師設計。進行監控和疑難排解均可使用。一旦判定出現效能問題,請使用叢集使用量儀表板,檢視爭用是否由高使用量所致。
設計考量
此儀表板已納入標準作業程式 (SOP)。其設計為日常使用而設計,因此視圖會設定為顯示過去 24 小時的資料。儀表板提供所選資料中心內虛擬機器的效能度量。
叢集的使用量未顯示在叢集爭用儀表板中。您必須區分這兩個概念:使用量與爭用。效能和容量是分別由兩個個別團隊管理的不同概念。CPU 和記憶體亦分別顯示。您可能在其中一邊遇到問題,而另一邊沒有任何問題。CPU 較常發生問題,因為記憶體往往會有較低的過量使用比率。
若要檢視所有效能管理儀表板的常見設計考慮事項,請參閱 效能儀表板。
如何使用儀表板
- 平均叢集效能 (%)。
- 此為您整體 IaaS 的主要 KPI。它會描繪每 5 分鐘您 IaaS 的執行情況,提供給您整體效能的趨勢視圖。
- 度量本身只是叢集 KPI/效能 (%) 度量的平均值。此效能度量因此會計算叢集中所有執行中虛擬機器的虛擬機器效能/已違反的 KPI 數目度量平均值。因此,100% 的值表示叢集中每個執行中的虛擬機器均提供良好的服務。
- 由於此 KPI 會考慮環境中每個正在執行的虛擬機器,因此這應該是穩定的數目。實際生活中的類比是股票市場指數。雖然個別股票可能易變動,但整體指數在每次 5 分鐘的間隔內相對穩定。
- 度量的相對移動與度量的絕對值同樣重要。您的絕對數字有上限,無法隨意調高,但是如果長時間沒有人不滿,則無緊急業務理由來改善。
- 叢集效能。
- 列出所有叢集,依過去一週內效能最低的叢集排序。您可以變更此期間。
- 最差的效能會顯示期間內的最低數字。由於 vRealize Operations 每 5 分鐘會收集一次資料,因此一週內有 12 x 24 x 7 = 2016 的資料點。此資料行會顯示這 2016 個資料點中最差的點。
- 在 2016 個資料點中的單一數字可能是極端值,有時候必須用另一個數字彌補。合理選擇是這些數字的平均值。若要讓平均效能降低,許多準則也要降低。等待平均效能會導致作業延遲,以及抱怨增加。針對效能監控,第 95 個百分位的摘要較平均值佳。
- 您的叢集應以 100% 運作,並按照計畫執行其功能。
- 從表格中選擇叢集。
- 所有健全狀況圖均會顯示所選叢集的 KPI。
- 針對效能,請務必顯示效能問題的深度和廣度。影響一或兩個虛擬機器的問題,需要不同於影響叢集中所有虛擬機器問題的疑難排解方式。
- 報告任何虛擬機器計數器中最差的情況,便顯示出問題深度。因此會顯示所有執行中虛擬機器的虛擬機器 CPU 就緒、虛擬機器記憶體爭用和虛擬機器磁碟延遲的最高值。如果最差的數字狀態良好,則無需檢視其餘的虛擬機器。
- 具有數千個虛擬機器的大型叢集可能會有單一虛擬機器發生效能不佳的情況,而 99.9% 的虛擬機器母體情況正常。深度計數器可能不會報告多數虛擬機器狀況正常。只會報告情況最差的虛擬機器。這種時候就需要加入廣度計數器。
- 廣度計數器報告出現效能問題的虛擬機器母體百分比。臨界值應嚴格設定,因為其目標是提供提早警告並啟用主動作業。
注意事項
當叢集使用量較低時,叢集中的虛擬機器可能發生效能不佳的情況。其中一個主要原因是叢集使用量會查看提供者層 (ESXi),而效能則查看個別取用者 (虛擬機器)。下表顯示各種可能的原因。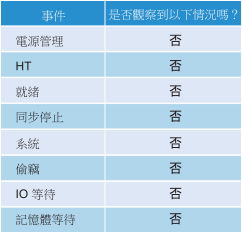
從效能管理的角度來看,vSphere 叢集是資源的最小邏輯建構區塊。雖然資源集區和虛擬機器主機相似性可提供較小的扇形區,但它們在運作上很複雜,而且無法提供承諾的 IaaS 服務品質。資源集區無法提供不同的服務等級。例如,您的 SLA 表示金級比銀級快兩倍,因為它收取的費用提高至 200%。資源集區可為金級提供兩倍以上的共用率。無法提前判定這些額外的共用率是否代表半數的 CPU 已就緒。
特定設定 (例如 DRS 自動化層級) 以及存在許多資源集區可能會影響效能。請考慮新增內容 Widget 以顯示所選叢集的相關內容,以及新增顯示資源集區的關聯性 Widget。
針對具有許多叢集的大型環境,新增分組以使清單更易於管理。依服務類別進行分組,您便可以專注於重要的叢集。
