









容量分析可協助您評估您環境中物件的剩餘容量與使用量。歷史資源使用量評估可產生對未來工作負載的預測。您可以根據預測針對基礎結構採購或移轉進行規劃,以避免容量不足和高基礎結構成本的風險。
容量分析使用容量引擎評估歷史趨勢,其中包括使用量尖峰。引擎會選擇適當的預測模型,以預測未來的工作負載。考量的歷史資料量取決於歷史使用量資料量。
容量引擎和計算
容量引擎會使用即時的預測性容量分析,根據需求行為的業界標準統計分析模型,分析歷史使用量並預測未來的工作負載。引擎會將需求和可用容量度量作為輸入,並產生輸出度量,即為剩餘時間、剩餘容量、建議大小,以及建議的總容量,如下圖所示。
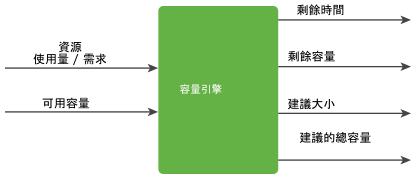
容量引擎的預測範圍為未來的 1 年。引擎每隔 5 分鐘會取用資料點,以確保即時計算輸出度量。
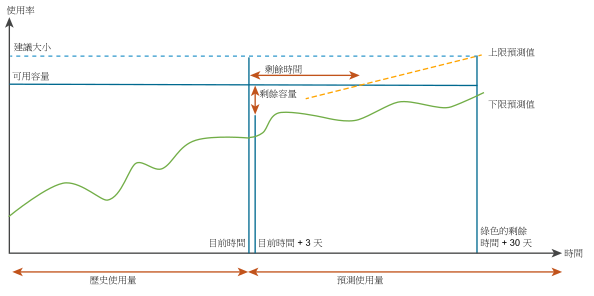
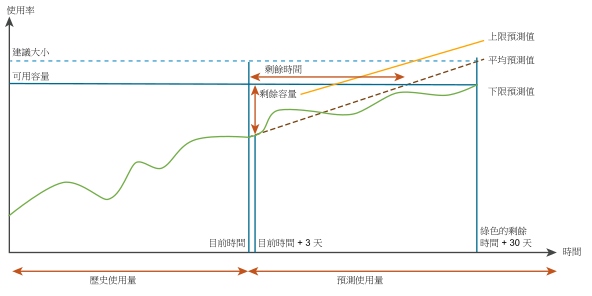
容量引擎會在預測的使用量範圍內,預測未來的工作負載。範圍包括上限預測和下限預測。容量計算是以剩餘時間風險等級基礎。針對保守的風險等級,引擎會考量上限預測;針對積極的風險等級,則會考量上限投預測的平均數和下限預測。如需有關設定風險等級的詳細資訊,請參閱《VMware vRealize Operations Manager 組態指南》之〈設定原則〉一章中的〈容量詳細資料〉。
容量引擎會計算剩餘時間、剩餘容量、建議大小以及建議總容量。
- 剩餘時間
- 到達預測使用量前的剩餘天數超出可用容量的臨界值。可用容量為排除 HA 設定的總容量。
- 剩餘容量
- 現在和未來 3 天間,可用容量和的預測使用量的最大差異。如果預測使用量高於可用容量的 100%,則剩餘容量為 0。
- 建議大小
-
預測期的最大預測使用量,從目前時間到剩餘時間警告臨界值後的 30 天。警告臨界值是剩餘時間為綠色的期間。建議大小會排除 HA 設定。
如果剩餘時間警告臨界值為 120 天,亦即預設值,未來 150 天的建議大小為最大預測使用量。
vRealize Operations Manager 會針對容量引擎所產生的建議大小設定上限,以讓建議維持保守。- vRealize Operations Manager 將高估容量的建議大小上限設為目前配置資源的 50%。
例如,設定了 8 個 vCPU 的虛擬機器以往從未使用超過 10% 的 CPU。建議為最多回收 4 個 vCPU,而非建議回收 7 個 vCPU 。
- vRealize Operations Manager 將低估容量的建議大小上限設為目前配置資源的 100%。
例如,設定了 4 個 vCPU 的虛擬機器過去以來操作溫度一直相當高。建議為最多增加 4 個 vCPU,而非建議增加 8 個 vCPU。
- vRealize Operations Manager 將高估容量的建議大小上限設為目前配置資源的 50%。
- 建議的總容量
-
預測期的最大預測使用量,從目前時間到剩餘時間警告臨界值後的 30 天。建議的總容量包含 HA 設定。
例如,如果剩餘時間警告臨界值為 120 天,亦即預設值,未來 150 天的建議大小為最大預測使用量包含 HA 設定。
備註: 建議的總容量不適用於物件。
下圖顯示保守風險等級的容量計算。
下圖顯示積極風險等級的容量計算。
使用量尖峰
資源的歷史使用量可能會有尖峰,亦即最大使用量期間。預測的未來工作負載會視尖峰類型而定。根據尖峰的頻率,可能為瞬時、持續或定期。
預測模型
容量引擎會使用預測模型產生預測。引擎會不斷修改預測,並選擇最適合歷史資料模式的模型。預測範圍會預測涵蓋未來的資料點 90% 的一般使用模式。預測模型為線性或定期。
趨勢視圖中的預測
預測是根據視圖設定中指定的時間範圍產生,並且預測天數會在預測設定中指定。將根據 3 個主要演算法產生預測。變更點偵測可用於尋找歷程記錄中包含大量變更的部分,線性回歸可用於尋找線性趨勢,循環分析可用於識別週期模式。
歷史資料範圍
視歷史資料範圍而定,容量引擎會擷取一段時間的歷史資料。引擎使用的歷史資料範圍是指數衰減範圍。
指數衰減範圍為無限制大小的範圍,容量引擎在其中會使最近的資料點更為重要。從預測計算起始點開始,引擎會取用所有歷史資料點,並根據其距離的時間遠近採用指數加權。
