









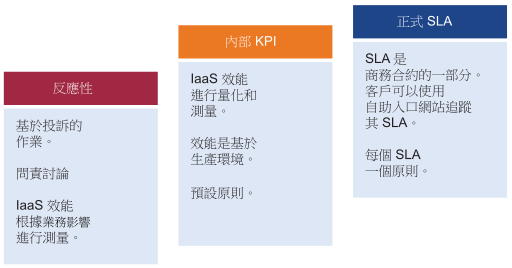
效能旨在確保工作負載取得必要資源。可使用關鍵效能指標 (KPI) 來識別與工作負載相關的效能問題。使用這些 KPI 來定義與服務層相關聯的 SLA。這些儀表板使用 KPI 在取用者層顯示工作負載的效能,以及提供者層的工作負載彙總效能。
SLA 是您與客戶簽訂的正式商務合約。通常,SLA 介於 IaaS 提供者 (基礎結構團隊) 與 IaaS 客戶 (應用程式團隊或業務單位) 之間。正式 SLA 需要營運轉型,例如,它需要的不只是技術改革,您可能需要查看合約、價格 (非成本)、處理程序和人員。KPI 涵蓋 SLA 度量和提供早期警告的其他度量。如果您沒有 SLA,則從內部 KPI 開始。您必須瞭解並分析 IaaS 的實際效能。如果您沒有自己的臨界值,請使用 vRealize Operations 中的預設設定,因為已選取那些臨界值來支援主動作業。
效能管理的三個程序
- 規劃。設定效能目標。當您設計 vSAN 架構時,必須知道您想要多少磁碟延遲 (以毫秒為單位)。在虛擬機器層級 (而非 vSAN 層級) 測量的 10 毫秒是好的開始。
- 監控。比較計畫與實際執行情況。事實是否與您的架構預期目標相符?如果不是,您必須修正此問題。
- 疑難排解。當事實與計畫不符時,您必須主動修正,而不是任由問題發生再去投訴。
- 爭用:這是主要指標。
- 組態:檢查版本不相容性。
- 可用性:檢查是否有軟錯誤。vMotion 關閉時間、鎖定。這需要 Log Insight。
- 使用量:最後檢查此項。如果前三個參數顯示良好,則可以略過此項。
效能管理的三個層面
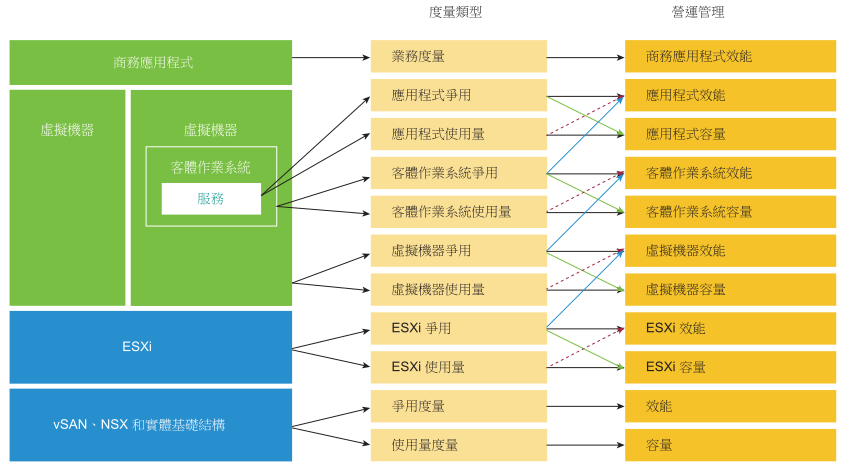
企業應用程式有三個主要領域。這些領域中的每一個都有自己的一組團隊。每個團隊都有一組獨特的責任,並且需要相關聯的技能組合。這三個領域由業務、應用程式和 IaaS 組成。請參閱下圖,以瞭解三個層面以及在每一層上詢問的一般問題。
效能管理在很大程度上是一項消除工作。此方法會切分每一層,並確定該層面是否會導致效能問題。因此,必須使用單一度量來指出某個特定層是否正在執行。此主要度量恰當地稱為關鍵效能指標 (KPI)。
上層取決於其下層,因此,基礎結構層通常是爭用的來源。因此,首先關注底層,因為它充當其上層的基礎。好的方面是,此層通常是一個水平層,無論其上執行的是什麼商務應用程式,都會提供一組通用基礎結構服務。
效能管理的兩個度量
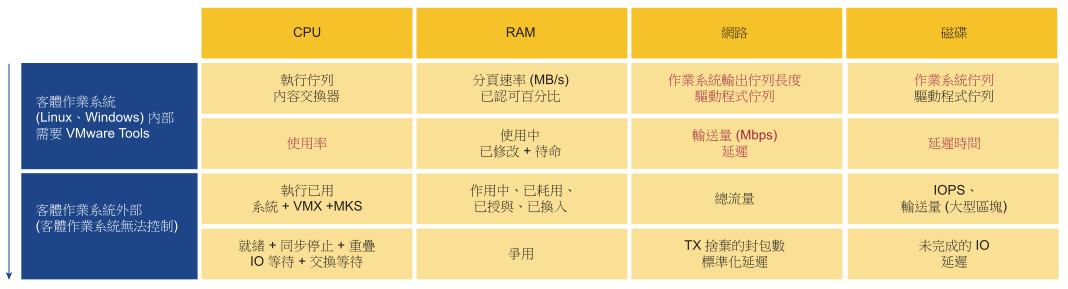
效能的主要計數器是爭用。大多數客戶會關注使用量,因為他們擔心如果利用量很高,就會發生錯誤。這就是爭用。不同形式的爭用資訊清單,像是佇列、延遲、捨棄、取消以及內容交換。
但是,請勿將超高使用率指示器與效能問題混淆。如果 ESXi 主機遇到佔用、壓縮和交換的問題,它並不表示您的虛擬機器有效能問題。您根據主機為虛擬機器提供多好的服務來測量主機效能。當效能與 ESXi 主機使用量相關時,效能指標不是以使用量為根據,而是以爭用度量為基礎。
| 基礎結構組態 | 虛擬機器和客體作業系統組態 |
|---|---|
ESXi 設定
|
虛擬機器:限制、共用率和保留
|
網路
|
大小:NUMA 效果。跨越 NUMA 節點的虛擬機器。 |
叢集設定
|
快照。IO 處理速度翻倍。 虛擬機器驅動程式。 |
vSAN
|
Windows 或 Linux 程序乒乓式執行、程序失控和作業系統層級佇列。 |
從效能管理的角度來看,vSphere 叢集是資源的最小邏輯建構區塊。雖然資源集區和虛擬機器主機相似性可提供較小的扇形區,但它們在運作上很複雜,而且無法提供承諾的 IaaS 服務品質。資源集區無法提供不同的服務等級。例如,您的 SLA 表示金級比銀級快兩倍,因為它收取的費用提高至 200%。資源集區可為金級提供兩倍以上的共用率。無法提前判定這些額外的共用率是否代表半數的 CPU 已就緒。
虛擬機器效能
對有些使用者來說 KPI 計數器可能偏向技術面,因此 vRealize Operations 包括一個起始行讓他們開始使用。您可以在分析環境後調整臨界值。由於大多數客戶都沒有基準,因此,此分析是一種不錯的做法。剖析需要進階版本。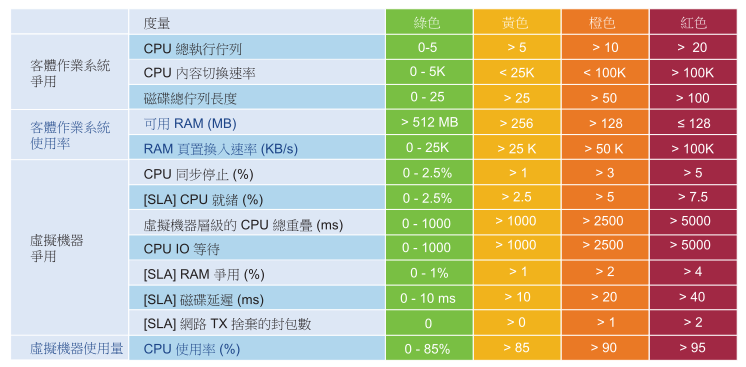
效能度量
| IaaS | 虛擬機器計數器 | 臨界值 |
|---|---|---|
| CPU | 就緒 | 2.5% |
| RAM | 爭用 | 1% |
| 磁碟 | 延遲時間 | 10 毫秒 |
| 網路 | TX 丟棄的封包 | 0 |
此表是嚴格臨界值範例。將使用高效能標準,因為它是針對基礎結構團隊耗用量的內部 KPI。這不是經客戶確認的外部正式 SLA。內部 KPI 和外部 SLA 之間必須有一段緩衝時間,以便作業團隊收到提早警告,並且有時間在違反外部 SLA 之前做出回應。高標準也適用於從關鍵任務點到開發環境的各個方面。如果將標準設定為效能最低的環境,則無法將其套用至更重要的開發。
單一臨界值可用於保持簡單作業。這表示生產效能預期比開發環境具有更高的分數。在其他所有條件相同的情況下,開發環境的效能預期會比生產環境差。單一臨界值可協助說明不同服務類別所提供之服務品質 (QoS) 的差異。例如,如果您支付的費用較少,則效能會降低,如果支付一半的價格,則效能預期會達到一半。
資料表中提到的四個 IaaS 元素 (CPU、RAM、磁碟和網路) 會在每個收集週期進行評估。收集時間設定為五分鐘,因為這是監控的適當平衡。如果 SLA 基於一分鐘,則太過接近,會導致成本增加或臨界值降低。
設計考量
所有效能儀表板共用相同的設計原則。他們特意設計得很相似,因為如果每個儀表板彼此不同,卻有相同的目標,這著實會產生混淆。
儀表板設計不同的兩個區段:摘要和詳細資料。
- 摘要區段通常放置在儀表板的頂端,提供整體概況。
- 詳細資料區段置於摘要區段下方。它可讓您深入瞭解特定物件。例如,您可以取得任何特定虛擬機器的詳細效能報告。
在詳細資料區段中,使用快速內容交換功能,在效能疑難排解期間檢查多個物件的效能。舉例來說,如果查看虛擬機器效能,您可以在不變更畫面的情況下,查看虛擬機器特定的資訊和 KPI。您可以從一個虛擬機器移至另一個虛擬機器,不需要開啟多個視窗,就能檢視詳細資料。
儀表板使用累進披露法將資訊超載降至最低,確保網頁載入快速。此外,如果瀏覽器工作階段仍存在,介面會記住您最後選擇的項目。
許多效能和容量儀表板共用了類似的配置,因為這些作業的支柱之間有共用的通用性。
