









Para permitir que os desenvolvedores implantem cargas de trabalho de AI / ML em clusters TKGS, como Administrador do vSphere, configure o ambiente do vSphere with Tanzu para oferecer suporte a hardware de GPU NVIDIA.
Fluxo de trabalho do administrador do vSphere para a implantação de cargas de trabalho de AI / ML em clusters TKGS
| Etapa | Ação | Link |
|---|---|---|
| 0 | Revise os requisitos do sistema. |
Consulte o Etapa 0 do administrador: revisar os requisitos do sistema. |
| 1 | Instale o dispositivo de GPU NVIDIA compatível em ESXi hosts. |
Consulte o Etapa do administrador 1: instalar o dispositivo de GPU NVIDIA compatível em ESXi hosts. |
| 2 | Defina as configurações de gráficos do dispositivo ESXi para operações vGPU. |
Consulte o Etapa 2 do administrador: configurar cada ESXi host para operações vGPU. |
| 3 | Instale o NVIDIA vGPU Manager (VIB) em cada host ESXi. |
Consulte o Admin Etapa 3: instalar o driver NVIDIA Host Manager em cada ESXi host. |
| 4 | Verifique a operação do driver NVIDIA e o modo de virtualização da GPU. |
Consulte o Etapa 4 do administrador: verificar se os ESXi hosts estão prontos para operações NVIDIA vGPU. |
| 5 | Ative o gerenciamento de carga de trabalho no cluster configurado por GPU. O resultado é um Cluster de Supervisor em execução em hosts ESXi habilitados para vGPU. |
|
| 6 | Crie uma biblioteca de conteúdo para versões do Tanzu Kubernetes e preencha a biblioteca com o OVA do Ubuntu com suporte que é necessário para cargas de trabalho vGPU. |
Consulte o Etapa 6 do administrador: criar uma biblioteca de conteúdo para a versão do Ubuntu do Tanzu Kubernetes. |
| 7 | Crie uma classe de VM personalizada com um determinado perfil vGPU selecionado. |
Consulte Etapa 7 do administrador: criar uma classe de VM personalizada com o perfil vGPU |
| 8 | Crie e configure um Namespace do vSphere para clusters de GPU TKGS: adicione um usuário com permissões de edição e armazenamento para volumes persistentes. |
Consulte Admin Etapa 8: Criar e Configurar um Namespace do vSphere para o Cluster de GPU TKGS |
| 9 | Associe a Biblioteca de Conteúdo ao OVA do Ubuntu e a Classe de VM personalizada para vGPU com o Namespace do vSphere que você criou para o TGKS. |
Consulte Admin Etapa 9: associar a biblioteca de conteúdo e a classe de VM ao Namespace do vSphere |
| 10 | Verifique se o Cluster de Supervisor está provisionado e acessível para o Operador de Cluster. |
Consulte Etapa 10 do administrador: verificar se o cluster de supervisor está acessível |
Etapa 0 do administrador: revisar os requisitos do sistema
| Requisito | Descrição |
|---|---|
| Infraestrutura do vSphere |
vSphere 7 Update3 Patch 1 mensal ESXi compilação vCenter Server compilação |
| Gerenciamento de carga de trabalho |
Versão do Namespace do vSphere
|
| Cluster de Supervisor |
Versão Supervisor Cluster
|
| TKR Ubuntu OVA | Tanzu Kubernetes release Ubuntu
|
| NVIDIA vGPU Host Driver |
Baixe o VIB do site do NGC . Para obter mais informações, consulte a documentação do driver de software vGPU https://www.nvidia.com/en-us/drivers/vgpu-software-driver/. Por exemplo:
|
| NVIDIA License Server para vGPU |
FQDN fornecido pela sua organização |
Etapa do administrador 1: instalar o dispositivo de GPU NVIDIA compatível em ESXi hosts
Para implantar cargas de trabalho de AI / ML no TKGS, instale um ou mais dispositivos de GPU NVIDIA compatíveis em cada ESXi host que compõe o vCenter Cluster em que o Workload Management (Workload Management) será ativado.
Para visualizar dispositivos NVIDIA GPU compatíveis, consulte o VMware Guia de compatibilidade .
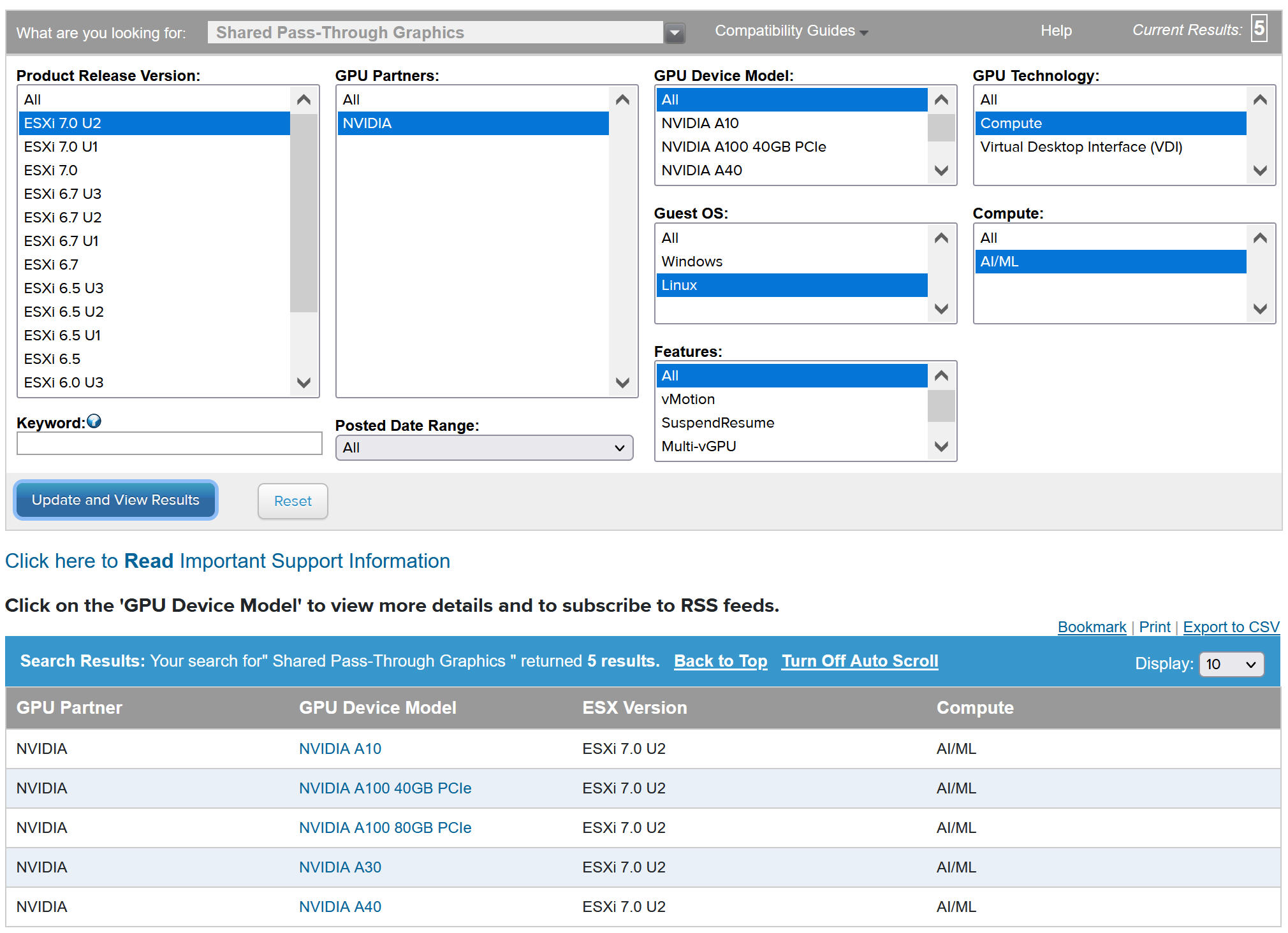
O dispositivo de GPU NVIDA deve oferecer suporte aos perfis mais recentes de vGPU do NVIDIA AI Enterprise (NVAIE). Consulte a documentação de GPUs compatíveis com software de GPU virtual NVIDIA para obter orientação.
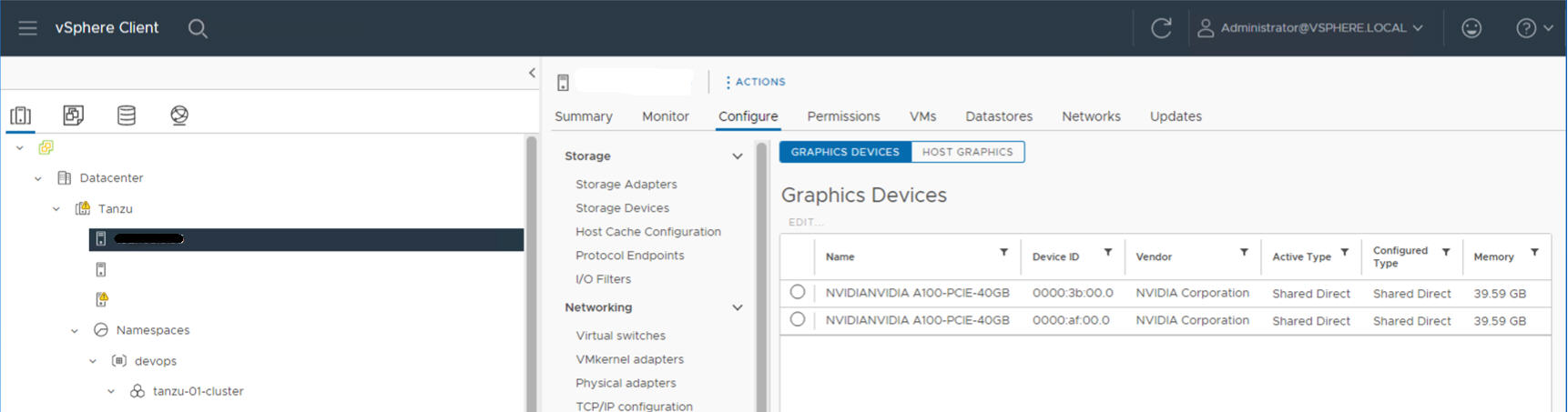
Por exemplo, o host ESXi a seguir tem dois dispositivos NVIDIA GPU A100 instalados.
Etapa 2 do administrador: configurar cada ESXi host para operações vGPU
Configure cada host ESXi para vGPU ativando o Shared Direct e o SR-IOV.
Habilitar o Shared Direct em cada ESXi host
Para que a funcionalidade NVIDIA vGPU seja desbloqueada, ative o modo Shared Direct (Shared Direct) em cada ESXi host que compõe o vCenter Cluster onde o Workload Management (Workload Management) será ativado.
- Faça logon no vCenter Server usando o vSphere Client.
- Selecione um host ESXi no vCenter Cluster.
- Selecione .
- Selecione o dispositivo acelerador de GPU NVIDIA.
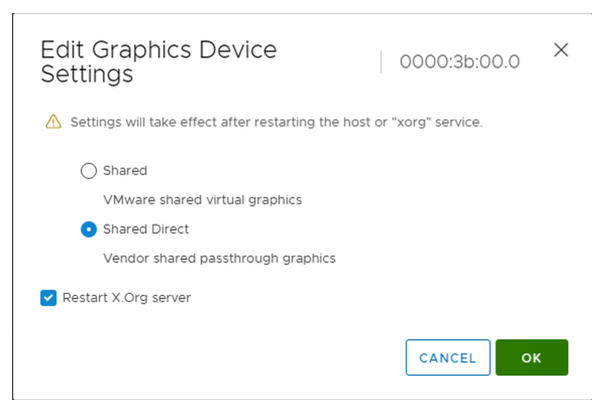
- Edite as configurações do dispositivo gráfico.
- Selecione Shared Direct (Shared Direct).
- Selecione Restart X.Org server (Restart X.Org).
- Clique em OK (OK) para salvar a configuração.
- Clique com o botão direito do mouse no host ESXi e coloque-o no modo de manutenção.
- Reinicie o host.
- Quando o host estiver em execução novamente, tire-o do modo de manutenção.
- Repita esse processo para cada ESXi host no cluster do vCenter em que o Workload Management (Workload Management) será ativado.
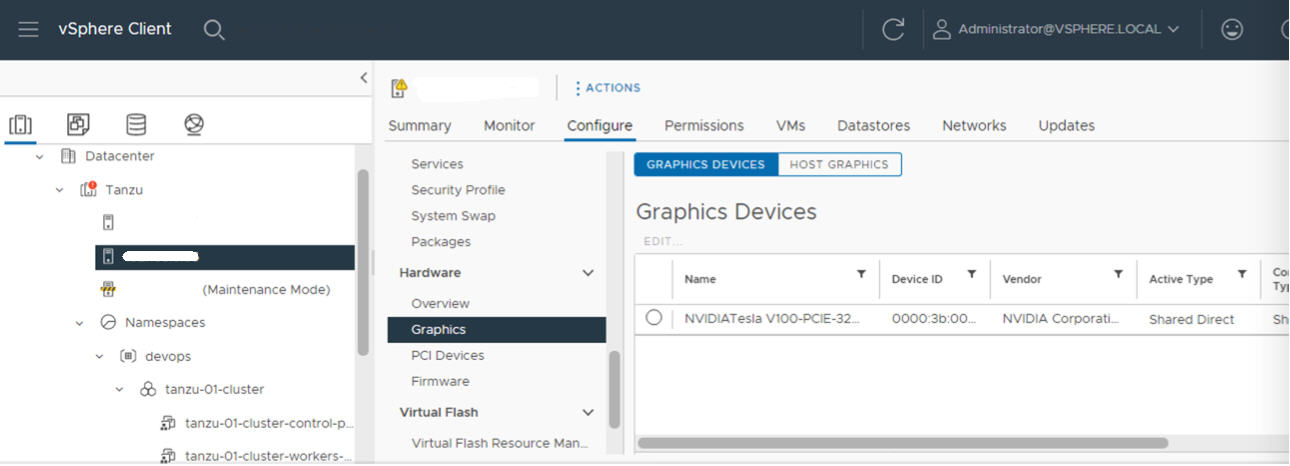
Ativar o SR-IOV BIOS for NVIDIA GPU A30 and A100 Devices
Se você estiver usando os dispositivos NVIDIA A30 ou A100 GPU, que são necessários para a GPU de várias instâncias ( modo MIG ), deverá ativar o SR-IOV no o host ESXi. Se o SR-IOV não estiver habilitado, as VMs do nó do cluster Tanzu Kubernetes não poderão ser iniciadas. Se isso ocorrer, você verá a seguinte mensagem de erro no painel Recent Tasks do vCenter Server, onde o Workload Management está ativado.
Could not initialize plugin libnvidia-vgx.so for vGPU nvidia_aXXX-xx. Failed to start the virtual machine. Module DevicePowerOn power on failed.
Para habilitar o SR-IOV, faça login no host ESXi usando o console da web. Selecione . Selecione o dispositivo GPU NVIDIA e clique em Configure SR-IOV (Configure SR-IOV). A partir daqui, você pode ativar o SR-IOV. Para obter orientação adicional, consulte Single Root I / O Virtualization (SR-IOV) na documentação do vSphere.
Admin Etapa 3: instalar o driver NVIDIA Host Manager em cada ESXi host
Os componentes do driver do gerenciador de host NVIDIA vGPU são empacotados em um pacote de instalação do vSphere (VIB). O NVAIE VIB é fornecido a você pela sua organização por meio do programa de licenciamento NVIDIA GRID. VMware não fornece NVAIE VIBs nem os disponibiliza para download. Como parte do programa de licenciamento NVIDIA, sua organização configura um servidor de licenciamento. Consulte o NVIDIA Guia de início rápido do software de GPU virtual para obter mais informações.
esxcli system maintenanceMode set --enable true esxcli software vib install -v ftp://server.domain.example.com/nvidia/signed/NVIDIA_bootbank_NVIDIA-VMware_ESXi_7.0_Host_Driver_460.73.02-1OEM.700.0.0.15525992.vib esxcli system maintenanceMode set --enable false /etc/init.d/xorg restart
Etapa 4 do administrador: verificar se os ESXi hosts estão prontos para operações NVIDIA vGPU
- SSH no host ESXi, entre no modo shell e execute o comando
nvidia-smi. A NVIDIA System Management Interface é um utilitário de linha de comando fornecido pelo gerenciador de host NVIDA vGPU. A execução desse comando retorna as GPUs e os drivers no host. - Execute o seguinte comando para verificar se o driver NVIDIA está instalado corretamente:
esxcli software vib list | grep NVIDA. - Verifique se o host está configurado com o GPU compartilhado direto e se o SR-IOV está ativado (se você estiver usando dispositivos NVIDIA A30 ou A100).
- Usando o vSphere Client, no host do ESXi que está configurado para GPU, crie uma nova máquina virtual com um dispositivo PCI incluído. O perfil NVIDIA vGPU deve aparecer e ser selecionável.

Etapa 5 do administrador: habilitar o gerenciamento de carga de trabalho no vCenter Cluster configurado com vGPU
Agora que os hosts ESXi estão configurados para oferecer suporte ao vGPU NVIDIA, crie um vCenter Cluster que inclua esses hosts. Para oferecer suporte ao gerenciamento de carga de trabalho (Workload Management), o vCenter Cluster deve atender a requisitos específicos, incluindo armazenamento compartilhado, alta disponibilidade e DRS totalmente automatizado.
A ativação do gerenciamento de carga de trabalho (Workload Management) também requer a seleção de uma pilha de rede, seja uma rede vSphere nativa ou uma rede NSX-T Data Center. Se você usar a rede vDS, precisará instalar um balanceador de carga, seja NSX Advanced ou HAProxy.
| Tarefa | Instruções |
|---|---|
| Crie um vCenter Cluster que atenda aos requisitos para ativar o Workload Management (Workload Management) | Pré-requisitos para configurar o vSphere with Tanzu em um cluster |
| Configure a rede para o Supervisor Cluster, o NSX-T ou o vDS com um balanceador de carga. | Configurando NSX-T Data Center para vSphere with Tanzu. Configurando o vSphere Networking e o NSX Advanced Load Balancer para vSphere with Tanzu. Configurando o vSphere Networking e o balanceador de carga do HA Proxy para vSphere with Tanzu. |
| Ative o gerenciamento de carga de trabalho (Workload Management) |
Ative o gerenciamento de carga de trabalho com NSX-T Data Center rede. Habilitar o gerenciamento de carga de trabalho com o vSphere Networking. |
Etapa 6 do administrador: criar uma biblioteca de conteúdo para a versão do Ubuntu do Tanzu Kubernetes
Quando o gerenciamento de carga de trabalho estiver ativado em um vCenter Cluster configurado por GPU, a próxima etapa será criar uma biblioteca de conteúdo para a imagem OVA da versão do Tanzu Kubernetes.
NVIDIA vGPU requer o sistema operacional Ubuntu. VMware fornece um Ubuntu OVA para tais fins. Não é possível usar a versão PhotonOS Tanzu Kubernetes para clusters vGPU.
| Tipo de biblioteca de conteúdo | Descrição |
|---|---|
| Crie uma Biblioteca de Conteúdo Assinado e sincronize automaticamente o OVA do Ubuntu com o seu ambiente. | Criar, proteger e sincronizar uma biblioteca de conteúdo assinada para o Tanzu Kubernetes releases |
| Crie uma Biblioteca de Conteúdo Local e carregue manualmente o OVA do Ubuntu para o seu ambiente. | Criar, proteger e sincronizar uma biblioteca de conteúdo local para o Tanzu Kubernetes releases |

Etapa 7 do administrador: criar uma classe de VM personalizada com o perfil vGPU
A próxima etapa é criar uma classe de VM personalizada com um perfil vGPU. O sistema usará essa definição de classe ao criar os nós do cluster Tanzu Kubernetes.
- Faça logon no vCenter Server usando o vSphere Client.
- Selecione Workload Management .
- Selecione Serviços .
- Selecione VM Classes .
- Clique em Create VM Class .
- Na guia Configuration , configure a classe de VM personalizada.
Campo de configuração Descrição Nome Insira um nome autodescritivo para a classe de VM personalizada, como vmclass-vgpu-1 . Contagem de vCPU 2 Reserva de recursos de CPU Opcional, OK para deixar em branco Memória 80 GB , por exemplo Reserva de recursos de memória 100% (obrigatório quando os dispositivos PCI são configurados em uma classe de VM) Dispositivos PCI Sim Observação: Selecionar Sim para dispositivos PCI informa ao sistema que você está usando um dispositivo GPU e altera a configuração de classe de VM para oferecer suporte à configuração vGPU.Por exemplo:
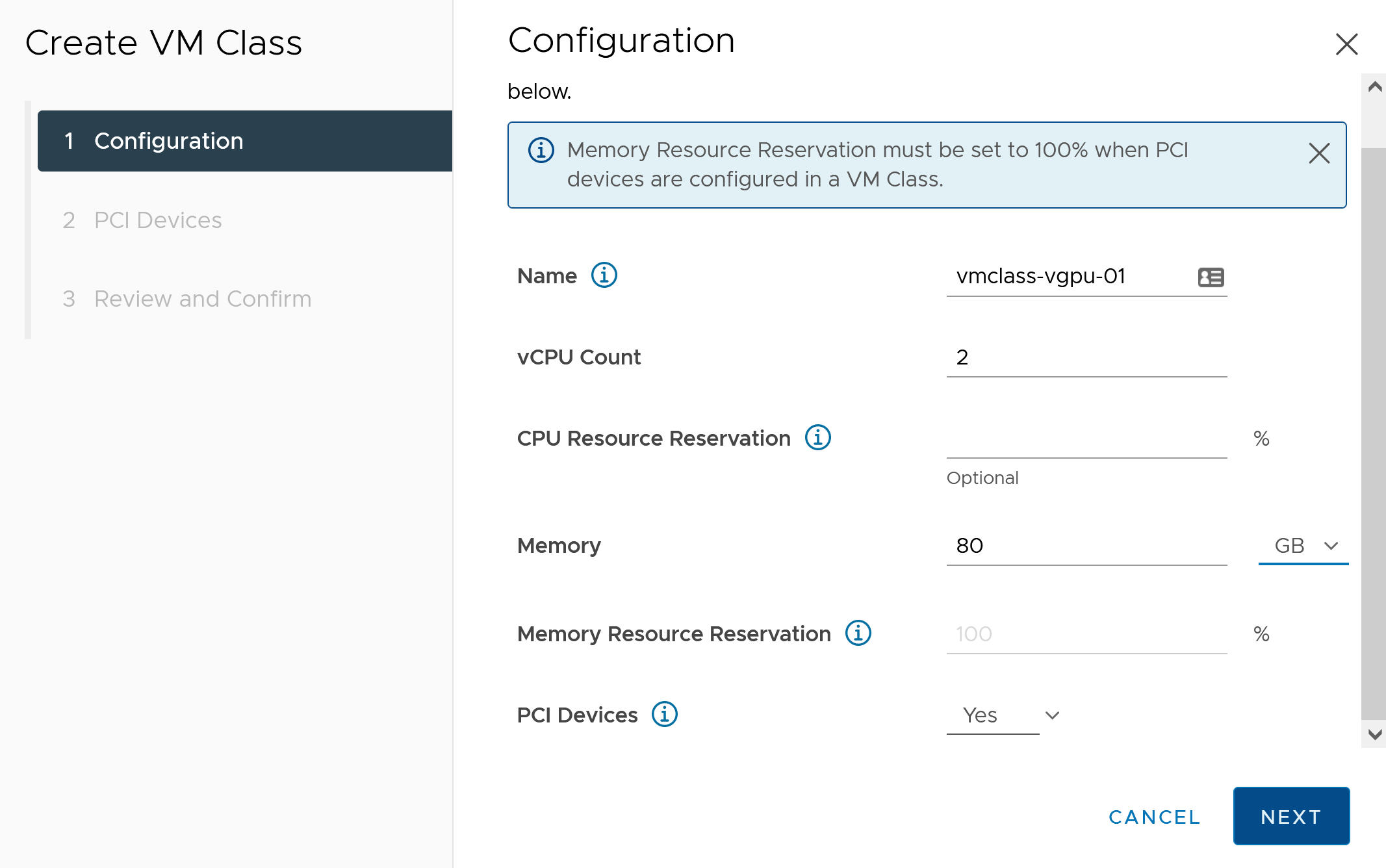
- Clique em Avançar.
- Na guia Dispositivos PCI , selecione a opção .
- Configure o modelo NVIDIA vGPU.
NVIDIA vGPU Field Descrição Modelo Selecione o modelo de dispositivo de hardware de GPU NVIDIA dentre os disponíveis no menu . Se o sistema não mostrar nenhum perfil, nenhum dos hosts no cluster tem dispositivos PCI compatíveis. Compartilhamento de GPU Essa configuração define como o dispositivo GPU é compartilhado entre as VMs habilitadas para GPU. Existem dois tipos de implementações de vGPU: Time Sharing (Time Sharing) e Multi-Instance GPU Sharing .
No modo de compartilhamento de tempo, o agendador vGPU instrui a GPU a realizar o trabalho para cada VM habilitada para vGPU em série por um período de tempo com a meta de melhor esforço de balanceamento de desempenho entre vGPUs.
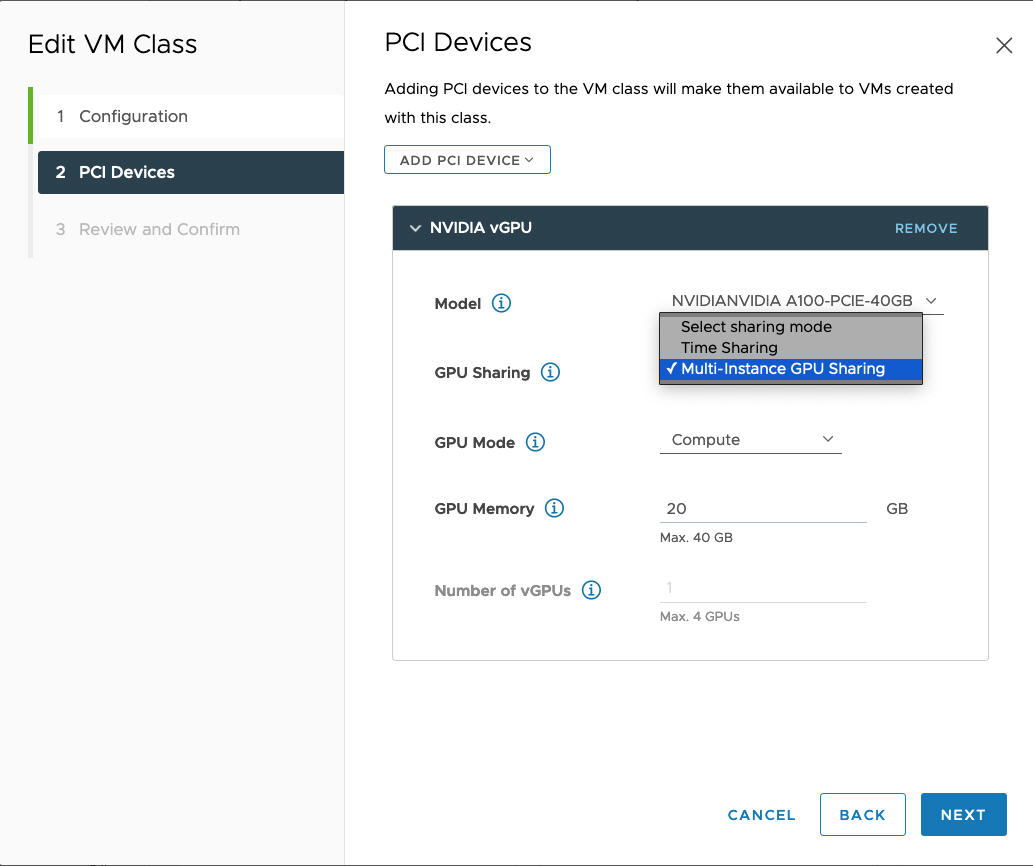
O modo MIG permite que várias VMs ativadas para vGPU sejam executadas em paralelo em um único dispositivo de GPU. O modo MIG é baseado em uma arquitetura de GPU mais recente e só é compatível com dispositivos NVIDIA A100 e A30. Se você não vir a opção MIG, o dispositivo PCI selecionado não é compatível.
Modo GPU Processamento Memória GPU 8 GB (GB), por exemplo Número de vGPUs 1 (1), por exemplo Por exemplo, aqui está um perfil NVIDIA vGPU configurado no modo de compartilhamento de tempo:
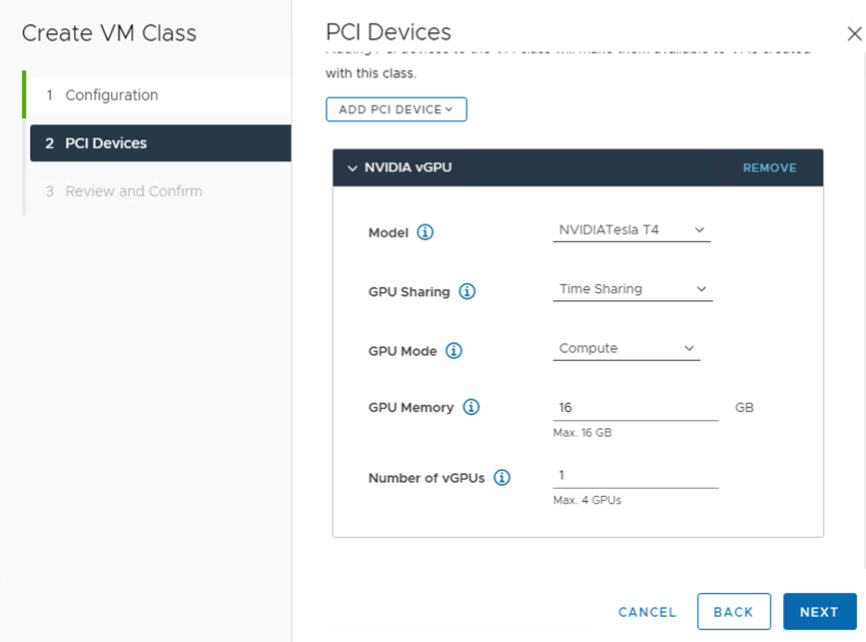
Por exemplo, aqui está um perfil NVIDIA vGPU configurado no modo MIG com dispositivo GPU compatível:
- Clique em Avançar.
- Revise e confirme suas seleções.
- Clique em Concluir.
- Verifique se a nova classe de VM personalizada está disponível na lista de classes de VM.
Admin Etapa 8: Criar e Configurar um Namespace do vSphere para o Cluster de GPU TKGS
Crie um Namespace do vSphere para cada cluster de GPU TKGS que você planeja provisionar. Configure o namespace adicionando um usuário do vSphere SSO com permissões de edição e anexe uma política de armazenamento para volumes persistentes.
Para fazer isso, consulte Criar e configurar um vSphere Namespace.
Admin Etapa 9: associar a biblioteca de conteúdo e a classe de VM ao Namespace do vSphere
| Tarefa | Descrição |
|---|---|
| Associe a Biblioteca de Conteúdo ao OVA do Ubuntu para vGPU com o Namespace do vSphere onde você provisionará o cluster TKGS. | Consulte o Configure um vSphere Namespace para Tanzu Kubernetes releases. |
| Associe a classe de VM personalizada ao perfil vGPU com o namespace do vSphere onde você provisionará o cluster TKGS. | Consulte o Associar uma classe de VM a um namespace no vSphere with Tanzu. |
Etapa 10 do administrador: verificar se o cluster de supervisor está acessível
A última tarefa de administração é verificar se o Supervisor Cluster está provisionado e disponível para uso pelo operador de cluster para provisionar um cluster TKGS para cargas de trabalho de AI / ML.
- Baixe e instale o Kubernetes CLI Tools for vSphere.
Consulte o Baixe e instale o Kubernetes CLI Tools for vSphere.
- Conecte-se ao Supervisor Cluster.
Consulte o Conecte-se ao Supervisor Cluster como um usuário do vCenter Single Sign-On.
- Forneça ao operador do cluster o link para baixar o Kubernetes CLI Tools for vSphere e o nome do Namespace do vSphere.
