









创建 VMware Cloud Director 设备部署时,可以包含数据库 HA 集群,以便为 VMware Cloud Director 数据库提供故障切换功能。
VMware Cloud Director 设备包括一个嵌入式 PostgreSQL 数据库。嵌入式 PostgreSQL 数据库包括复制管理器 (repmgr) 工具套件,可为 PostgreSQL 服务器集群提供高可用性 (HA) 功能。
您可以将 VMware Cloud Director 设备部署为主单元、备用单元或 VMware Cloud Director 应用程序单元。请参见使用 vSphere Client 部署 VMware Cloud Director 设备、使用 VMware OVF Tool 部署 VMware Cloud Director 设备或#GUID-D35B3629-FCA2-40A6-8009-1A6CF8120F30。
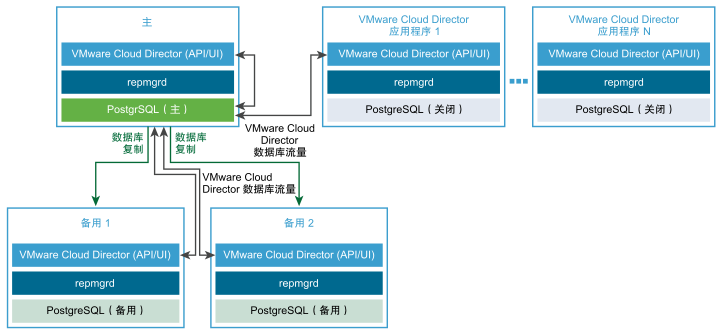
要为 VMware Cloud Director 数据库配置 HA,创建服务器组时,可以通过部署 VMware Cloud Director 设备的一个主实例和两个备用实例来配置数据库 HA 集群。您可以通过部署额外的应用程序单元来横向扩展服务器组。请参见 VMware Cloud Director 设备数据库 HA 集群 图。
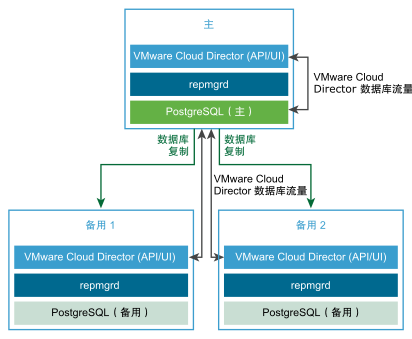
创建具有数据库 HA 的 VMware Cloud Director 设备部署
- 将 VMware Cloud Director 设备部署为主单元。
主单元是 VMware Cloud Director 服务器组中的第一个成员。嵌入式数据库配置为 VMware Cloud Director 数据库。数据库名称是
vcloud,数据库用户是vcloud。 - 验证该主单元是否已启动且正在运行。
- 要验证 VMware Cloud Director 服务运行状况,请使用系统管理员凭据登录到 VMware Cloud Director Service Provider Admin Portal,网址为 https://primary_eth0_ip_address/provider。
- 要验证 PostgreSQL 数据库运行状况,请以 root 身份登录到设备管理用户界面,网址为 https://primary_eth1_ip_address:5480。
主节点必须处于运行状态。
- 将 VMware Cloud Director 设备的两个实例部署为备用单元。
嵌入式数据库是在主数据库的复制模式下配置的。
注: 在初始备用设备部署之后,复制管理器开始将其数据库与主设备数据库同步。在此期间, VMware Cloud Director 数据库以及 VMware Cloud Director UI 不可用。 - 验证 HA 集群中的所有单元是否都处于运行状态。
- (可选)将 VMware Cloud Director 设备的一个或多个实例部署为 VMware Cloud Director 应用程序单元。
不使用嵌入式数据库。VMware Cloud Director 应用程序单元将连接到主数据库。
Automatic”。请参见
VMware Cloud Director 设备 API。新单元的默认故障切换模式为“
Manual”。如果集群节点之间的故障切换模式不一致,则集群故障切换模式为“
Indeterminate”。“
Indeterminate”模式可能会导致这些节点与支持旧主单元的节点之间的集群状态不一致。要查看集群故障切换模式,请参见
查看 VMware Cloud Director 设备集群运行状况和故障切换模式。
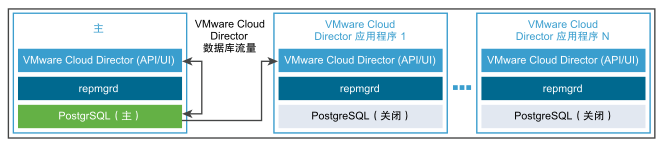
创建不具有数据库 HA 的 VMware Cloud Director 设备部署
- 将 VMware Cloud Director 设备部署为主单元。
主单元是 VMware Cloud Director 服务器组中的第一个成员。嵌入式数据库配置为 VMware Cloud Director 数据库。数据库名称是
vcloud,数据库用户是vcloud。 - 验证该主单元是否已启动且正在运行。
- 要验证 VMware Cloud Director 服务运行状况,请使用系统管理员凭据登录到 VMware Cloud Director Service Provider Admin Portal,网址为 https://primary_eth0_ip_address/provider。
- 要验证 PostgreSQL 数据库运行状况,请以 root 身份登录到设备管理用户界面,网址为 https://primary_eth1_ip_address:5480。
主节点必须处于运行状态。
- (可选)将 VMware Cloud Director 设备的一个或多个实例部署为 VMware Cloud Director 应用程序单元。
不使用嵌入式数据库。VMware Cloud Director 应用程序单元将连接到主数据库。
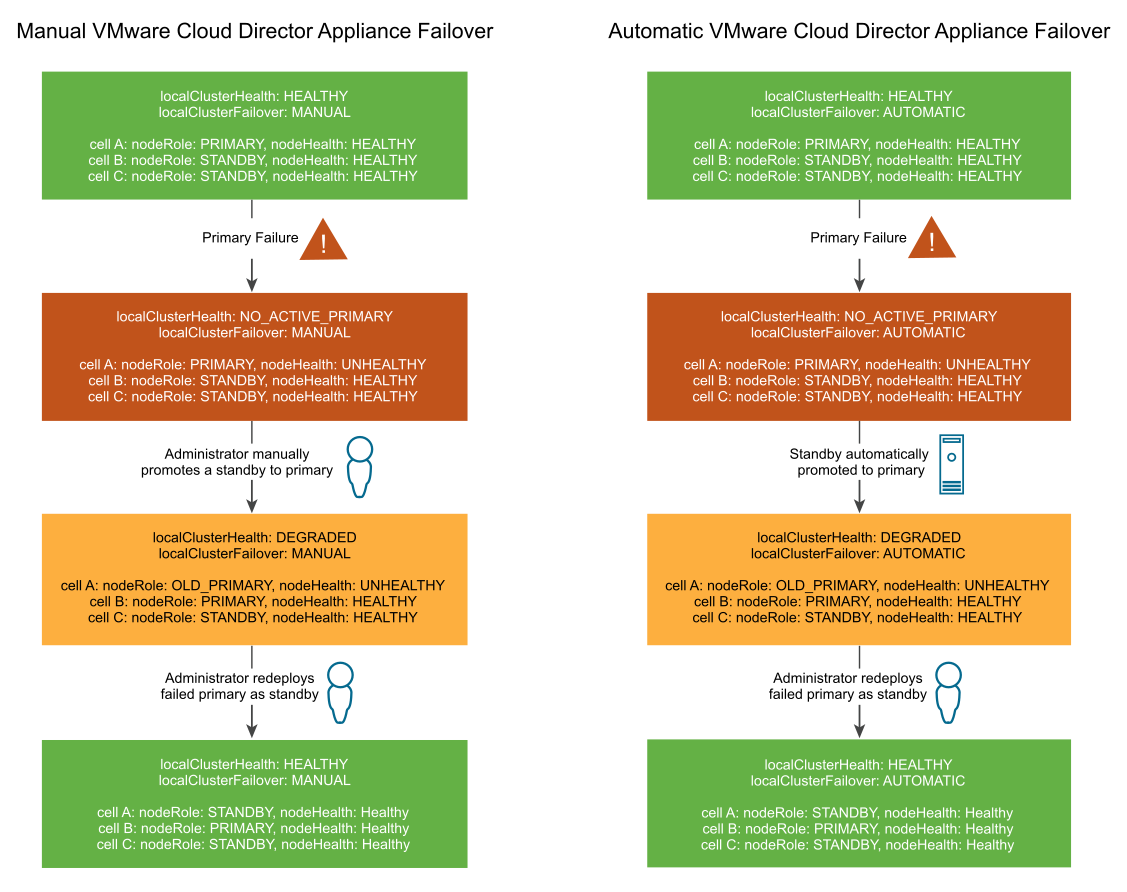
VMware Cloud Director 设备自动故障切换
如果主数据库服务出现故障,可以将 VMware Cloud Director 自动故障切换到新的主单元。
使用自动故障切换功能,在主数据库服务出于任何原因而无法执行其功能时,管理员无需启动故障切换操作。默认情况下,故障切换模式设置为“手动”。可以使用 VMware Cloud Director 设备 API 将故障切换模式设置为“自动”或“手动”。请参见《VMware Cloud Director 设备 API 架构参考》。
Automatic”。请参见
VMware Cloud Director 设备 API。新单元的默认故障切换模式为“
Manual”。如果集群节点之间的故障切换模式不一致,则集群故障切换模式为“
Indeterminate”。“
Indeterminate”模式可能会导致这些节点与支持旧主单元的节点之间的集群状态不一致。要查看集群故障切换模式,请参见
查看 VMware Cloud Director 设备集群运行状况和故障切换模式。
如果您的环境中至少有两个活动备用单元,则在主数据库发生故障时,将自动启动数据库故障切换。故障切换后,必须至少有一个活动的备用单元才能更新新的主数据库。在正常情况下,VMware Cloud Director 设备部署必须始终至少有两个活动备用单元。如果短期内只有一个活动备用单元(例如,由于主单元发生故障提升了其中一个备用单元),则必须尽快将发生故障的旧主单元替换为新的备用单元。
当具有活动主单元和至少两个活动备用单元时,集群被视为处于 Healthy 状态。如果有一个活动主单元以及只有一个活动备用单元,则集群将处于 Degraded 状态。如果集群处于 Degraded 状态时出现其他数据库故障,则在另一个备用单元联机之前,主单元不可更新。当主数据库不可更新时,VMware Cloud Director 不可用,因为 VMware Cloud Director 单元无法更新数据库,直到至少有一个活动备用单元处理来自主数据库的流式复制。无论激活手动故障切换还是自动故障切换,Healthy 和 Degraded 集群的概念都相同。
主数据库出现故障后,主数据库的状态为 No_Active_Primary。对于手动 VMware Cloud Director 设备故障切换,管理员必须手动将备用单元提升为主单元,并将发生故障的主单元重新部署为备用单元。对于自动设备故障切换,VMware Cloud Director 会自动将备用单元提升为主单元,管理员需要手动将发生故障的主单元重新部署为备用单元。
自动防护出现故障的 VMware Cloud Director 主单元
如果主单元发生故障后提升了新的主单元,VMware Cloud Director 会自动防护旧的主单元,以防止其重新启动。
在发生故障切换的情况下,如果提升新的主单元后失败的主数据库重新启动,VMware Cloud Director 会自动防护旧的主单元。此自动化操作可防止出现裂脑情况,这种情况下两个活动数据库会彼此分离。防护自动化将停止并停用旧主节点上的 vpostgres 服务。之后,您可以将发生故障的主节点重新部署为备用单元,以将集群运行状况还原为“Healthy”。
有关查看集群运行状况和故障切换模式的详细信息,请参见查看 VMware Cloud Director 设备集群运行状况和故障切换模式。
