









集群争用仪表板是 vSphere 集群性能的主要仪表板。它专为 VMware 管理员或架构师而设计。它可用于监控和故障排除。确定存在性能问题后,请使用集群利用率仪表板查看争用是否由高利用率导致。
设计注意事项
此仪表板作为标准操作程序 (SOP) 的一部分使用。它是为日常使用而设计的,因此视图设置为显示过去 24 小时的数据。仪表板可为所选数据中心的虚拟机提供性能衡量指标。
集群的利用率未显示在集群争用仪表板中。您必须区分两个概念:利用率和争用。性能和容量是由两个单独的团队管理的不同概念。同时还会单独显示 CPU 和内存。可能其中一个存在问题,而另一个没有任何问题。CPU 更常见,因为内存的超额分配比率往往较低。
要查看所有性能管理仪表板中的常见设计注意事项,请参见性能仪表板。
如何使用仪表板
- 平均集群性能 (%)。
- 这是整个 IaaS 的主要 KPI。它每 5 分钟绘制一次 IaaS 的性能,让您了解整体性能的趋势视图。
- 该衡量指标本身只是“集群 KPI/性能 (%)”衡量指标的平均值。此性能衡量指标进而计算集群中所有正在运行的虚拟机的“虚拟机性能/违反的 KPI 数量”衡量指标的平均值。因此,值 100% 表示集群中每个正在运行的虚拟机的需求都能得到充分满足。
- 由于此 KPI 将考虑环境中每个正在运行的虚拟机,因此数值应该稳定。用现实生活中的股票行情指数做个类比。虽然个别股票可能会波动,但总体而言,该指数应在 5 分钟的时间内相对稳定。
- 衡量指标的相对移动与衡量指标的绝对值同样重要。绝对数值可能没有您想要的那么高,但如果长期没有投诉,那么就没有迫切的业务理由来改进它。
- 集群性能。
- 它列出了所有集群,并按过去一周中性能最低的集群排序。您可以更改此时间段。
- 最差的性能显示该时间段内的最低数值。由于 vRealize Operations 每 5 分钟收集一次数据,每周有 2016 (12 x 24 x 7) 个数据点。此列显示了这 2016 个数据点中最差的点。
- 2016 个数据点中可能有一个数字为离群值,有时需要用另一个数字来补充。合理的选择是这些数值的平均值。要使平均性能较低,许多标准必须较低。等待平均值会导致操作延迟,并导致投诉增加。对于性能监控,第 95 百分位比平均值更好。
- 您的集群应 100% 运行,并按计划工作。
- 从表中选择集群。
- 所有运行状况图表都显示所选集群的 KPI。
- 对于性能而言,显示性能问题的深度和广度非常重要。影响一个或两个虚拟机的问题所需的故障排除与影响集群中所有虚拟机的问题不同。
- 深度是通过报告任何虚拟机计数器中最差的值来显示。因此,将显示所有正在运行的虚拟机的虚拟机 CPU 就绪、虚拟机内存争用和虚拟机磁盘延迟的最高值。如果最差数值良好,则无需查看其余虚拟机。
- 具有数千个虚拟机的大型集群可能有一个虚拟机的性能较差,而 99.9% 的虚拟机正常。深度计数器可能不会报告大多数虚拟机正常。它仅报告最差情况。这就是广度计数器的用处。
- 广度计数器报告出现性能问题的虚拟机数量的百分比。应设置严格的阈值,因为目标是提供预警并启用主动操作。
注意事项
集群中的虚拟机可能出现性能不佳的情况,而集群利用率较低。一个主要原因是集群利用率考虑提供者层 (ESXi),而性能考虑使用者 (VM)。下表显示了各种可能的原因。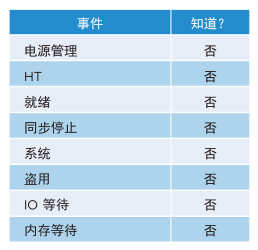
从性能管理的角度来看,vSphere 集群是资源中最小的逻辑构造块。虽然资源池和虚拟机主机关联性可以提供较小的扇区,但其在操作上非常复杂,而且无法提供承诺的 IaaS 服务质量。资源池无法提供不同的服务等级。例如,您的 SLA 指明金牌比银牌快两倍,因为其价格高出 200%。资源池可为金级提供两倍的份额。无法预确定是否将这些额外份额转换为 CPU 就绪的一半。
某些设置(如 DRS 自动化级别和存在多个资源池)可能会影响性能。考虑添加属性小组件以显示所选集群的相关属性,并添加关系小组件以显示资源池。
对于具有多个集群的大型环境,请添加一个分组以使该列表更易于管理。按服务等级对其进行分组,以便将更多精力集中在关键集群上。
