









If your cloud administrator has set up Private AI Automation Services in VMware Aria Automation, you can request AI workfloads using the Automation Service Broker catalog.
Private AI Automation Services support two catalog items in Automation Service Broker that users with the respective permissions can access and request.
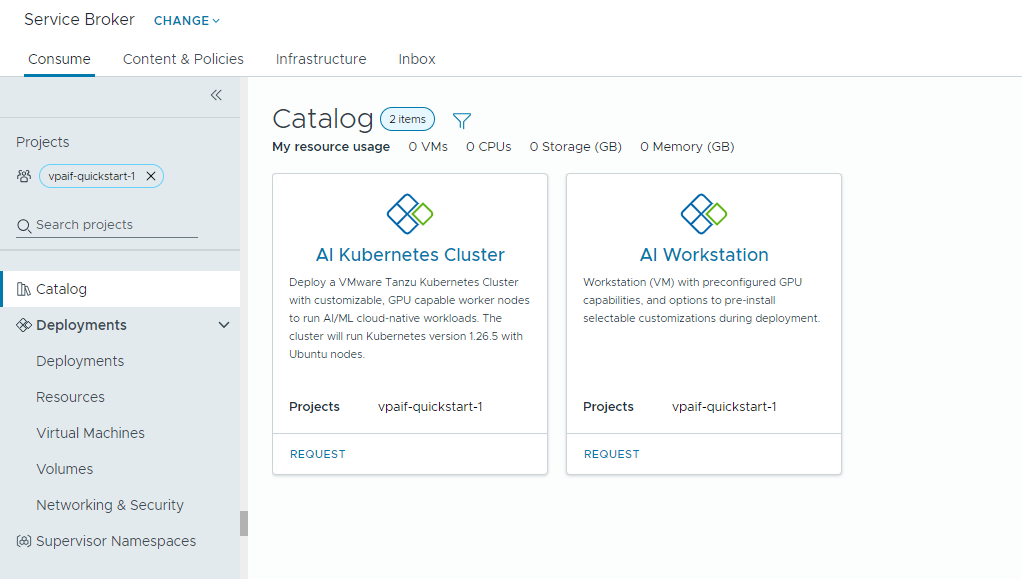
- AI Workstation – a GPU-enabled virtual machine that can be configured with desired vCPU, vGPU, memory, and AI/ML software from NVIDIA.
- AI Kubernetes Cluster – a GPU-enabled Tanzu Kubernetes cluster that can be configured with an NVIDIA GPU operator.
Before you begin
- Verify that Private AI Automation Services are configured for your project and you have permissions to request AI catalog items.
Remember that all values here are use case samples. Your account values depend on your environment.
Deploy a deep learning virtual machine to a VI workload domain
As a data scientist, you can deploy a single GPU software-defined development environment from the self-service Automation Service Broker catalog. You can customize the GPU-enabled virtual machine with machine parameters to model development requirements, specify the AI/ML software configurations to meet training and inference requirements, and specify the AI/ML packages from the NVIDIA NGC registry via a portal access key.
Procedure
Deploy an AI-enabled Tanzu Kubernetes cluster
As a DevOps engineer, you can request a GPU-enabled Tanzu Kubernetes cluster, where worker nodes can run AI/ML workloads.
The TKG cluster contains an NVIDIA GPU operator, which is a Kubernetes operator that is responsible for setting up the proper NVIDIA driver for the NVIDIA GPU hardware on the TKG cluster nodes. The deployed cluster is ready-to-use for AI/ML workloads without needing additional GPU-related setup.
Procedure
- Locate the AI Kubernetes Cluster card and click Request.
- Select a project.
- Enter a name and description for your deployment.
- Select the number of control pane nodes.
Setting Sample value Node count 1 VM class cpu-only-medium - 8 CPUs and 16 GB Memory The class selection defines the resources available within the virtual machine.
- Select the number of work nodes.
Setting Description Node count 3 VM class a100-medium - 4 vGPU (64 GB), 16 CPUs and 32 GB Memory - Click Submit.
Results
The deployment contains a supervisor namespace, a TKG cluster with three work nodes, multiple resources inside the TKG cluster, and a carvel application which deploys the GPU-operator application.
Monitor your Private AI deployments
You use the Deployments page to manage your deployments and the associated resources, making changes to deployments, troubleshooting failed deployments, making changes to the resources, and destroying unused deployments.
To manage your deployments, select .
For more information, see How do I manage my Automation Service Broker deployments.
