









Redis is a data structure store and so you can use it as a database. In Redis, there can be multiple databases identified by a number and the number of the default database is 0.
Jedis jedis = getPool().getResource();
jedis.select(3); //Selects database with index 3
jedis.set("plugin:tutorial", "Using another database");
You can add to the plug-in the option to select a database that is different from the default one using either of the two available methods.
| Method | Description |
|---|---|
| Expose database index as part of the scripting API. | When a user calls a set method, for example, they can pass the database index as an extra function argument. |
Present a new inventory object, Database, that wraps the index. |
You must move all current methods from the Connection to the Database model object. |
The following diagram displays the model of the second method.
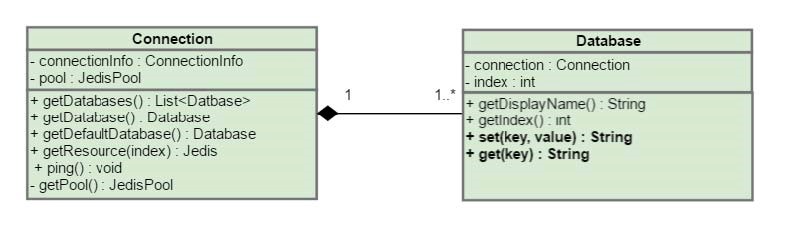
You define the Database object in the model package. The Database object that you invoke instead of get, set, or other methods, includes the following code.
package com.vmware.o11n.plugin.redis.model;
import com.vmware.o11n.sdk.modeldriven.extension.ExtensionMethod;
import org.springframework.util.Assert;
import redis.clients.jedis.Jedis;
public class Database {
private final Connection connection;
private final int index;
public Database(Connection connection, int index) {
Assert.notNull(connection, "Connection cannot be null.");
Assert.isTrue(index >= 0, "Index must be a positive number.");
this.connection = connection;
this.index = index;
}
public String getDisplayName() {
return "db" + index;
}
public int getIndex() {
return index;
}
@ExtensionMethod
public String ping() {
try (Jedis jedis = connection.getResource(index)) {
return jedis.ping();
}
}
@ExtensionMethod
public String set(String key, String value) {
try (Jedis jedis = connection.getResource(index)) {
return jedis.set(key, value);
}
}
@ExtensionMethod
public String get(String key) {
try (Jedis jedis = connection.getResource(index)) {
return jedis.get(key);
}
}
}
The Connection object also requires some changes. Some of them include removing methods, such as get, set, and append.
@Component
@Qualifier(value = "connection")
@Scope(value = "prototype")
public class Connection implements Findable {
private static final int DEFAULT_REDIS_DATABASE_INDEX = 0;
/*
* The connectionInfo which stands behind this live connection.
*/
private ConnectionInfo connectionInfo;
private Map<Integer, Database> databases = null;
...
public List<Database> getDatabases() {
if (databases == null) {
databases = new HashMap<>(16);
//Issue a call to Redis, to see how many databases are configured, default is 16
List<String> configs = getResource(DEFAULT_REDIS_DATABASE_INDEX).configGet("databases");
int numberOfInstances = Integer.parseInt(configs.get(1));
for (int index = 0; index < numberOfInstances; index++) {
databases.put(index, new Database(this, index));
}
}
return new ArrayList<>(databases.values());
}
@ExtensionMethod
public Database getDatabase(int index) {
return getDatabases().get(index);
}
@ExtensionMethod
public Database getDefaultDatabase() {
return getDatabase(DEFAULT_REDIS_DATABASE_INDEX);
}
...
}
The modified Connection model initializes a map of database instances. You can find a database by its index. The getDatabases() method invokes a configuration command against the Redis instance and retrieves the count of the supported database instances. By default, the number of supported instances is 16.
You use CustomMapping to add a relation between a Connection object and a Database object.
@Override
public void define() {
//@formatter:off
...
wrap(Database.class).
andFind().
using(DatabaseFinder.class).
withIcon("database.png");
...
relate(Connection.class).
to(Database.class).
using(ConnectionHasDatabases.class).
as("databases");
//@formatter:on
}
}
Finder implementation and a new
Relater implementation.
public class DatabaseFinder implements ObjectFinder<Database> {
@Autowired
private ConnectionRepository connectionRepository;
@Override
public Database find(PluginContext ctx, String type, Sid id) {
Connection connection = connectionRepository.findLiveConnection(id);
if (connection != null) {
return connection.getDatabase((int) id.getLong("dbid", 0));
}
return null;
}
@Override
public List<FoundObject<Database>> query(PluginContext ctx, String type, String query) {
//Return null for now
return null;
}
@Override
public Sid assignId(Database obj, Sid relatedObject) {
return relatedObject.with("dbid", obj.getIndex());
}
}
Although the finder of the Database object is similar to ConnectionFinder, some major differences exist between these finders. While the Connection object is related to the root of the inventory tree and does not have a parent object, the Database object is a child object of the Connection object. When you invoke the assignId method, the relatedObject argument is the ID of the parent object, or the ID of the Connection object. You can track a child object by the ID of its parent object.
The relatedObject.with("dbid", obj.getIndex()); implementation creates a new ID based on the connection ID. The Database object ID includes the Connection object ID and the index of the database instance. By using this method, you identify a single database instance among all Connection objects.
The following diagram shows the relations between several layers of objects and their corresponding IDs.
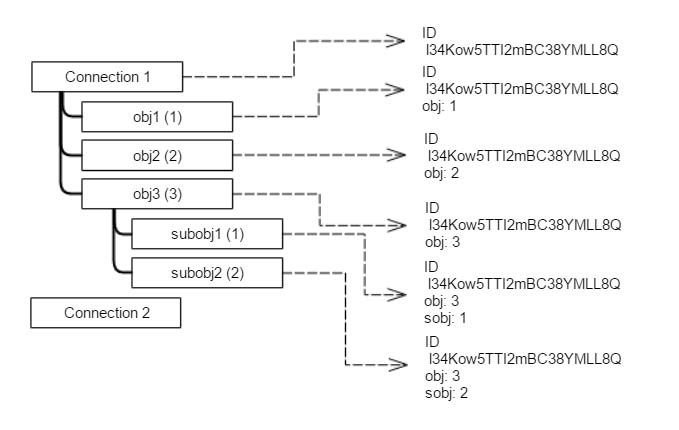
For example, Connection 1 has an ID l34Kow5TTI2mBC38YMLL8Q. Connection 1 also has sub objects: obj1, obj2, and obj3, whose natural IDs are 1, 2, and 3 respectively. obj3 has a set of subobjects, namely subobj1 and subobj2.
There are three types of objects, so you need three finders – for Connections, for obj and for subobj objects.
The assignId method for the connection returns only the ID of the connection. The assignId method for the finder of the first-level objects, obj, returns the ID of the connection and the ID of the obj. The assignId method for the finder of the subobj objects returns the ID of the parent object and the ID of the subobject.
A structure, similar to a map, stores the values of the ID for each object.
Connection object.
Defining the finder of the Database object is not enough to show the database objects in the inventory tree. By using CustomMapping, you must define the parent object of the Database object and pass it to the Automation Orchestrator platform. By introducing the ConnectionHasDatabase class, you can find a set of databases for a certain connection.
public class ConnectionHasDatabases implements ObjectRelater<Database> {
@Autowired
private ConnectionRepository connectionRepository;
@Override
public List<Database> findChildren(PluginContext ctx, String relation, String parentType, Sid parentId) {
Connection connection = connectionRepository.findLiveConnection(parentId);
if (connection != null) {
return connection.getDatabases();
}
return Collections.emptyList();
}
}
Similarly to using the ConnectionFinder class, when you know the ID of the Connection object, which is a parent object, you can use ConnectionRepository to find the connection instance. To retrieve the result, you must invoke the getDatabases() method.
If you run the workflow from the Wrap the Client section, you receive the following error message: TypeError: Cannot find function set in object DynamicWrapper (Instance) : [RedisConnection]-[class com.vmware.o11n.plugin.redis_gen.Connection_Wrapper] -- VALUE :.
connection.defaultDatabase.set("plugin:tutorial", "Testing redis connection - success");
var result = connection.defaultDatabase.get("plugin:tutorial");
System.log(result);
The modified workflow uses the same Redis:Connection connection parameter but retrieves the default database.
Writing to the file system
Using the file system to store data is not recommended, because the data is not synchronized between Automation Orchestrator nodes and is not automatically migrated.
If you need to write data for testing purposes, such as checking which node is running the current script, place all files in a folder dedicated to your plug-in under /var/run/vco. Ensure that you include the short name of your plug-in in the name of the folder.
Keep in mind that the customer might have additional restrictions and this might not work on all Automation Orchestrator installations.
Releasing new versions of the plug-in
When a new version of the same plug-in is released, keep in mind the following to ensure that you customer's content is compatible with the new version.
- Workflow IDs, scripting action categories, and names must not be changed. They are used as unique identifiers and changing them introduces entirely new workflows or actions when the customer upgrades.
- Avoid breaking changes. If you need to add a new parameter to an action or a workflow, make sure that the action or workflow continues to work without that new parameter.
- Avoid removing API scriptable objects or methods in such objects.
- Update the versions of any workflows and actions that you changed.
- If you need to introduce significant changes, where possible, keep the old workflows, actions or scriptable objects, and mark them as Deprecated in the description, while adding new ones with the changes.
