









Starting from VMware Private AI Foundation with NVIDIA for VMware Cloud Foundation 5.2.1, as an MLOps engineer, you can distribute ML models across deep learning VMs and TKG clusters by using a central Harbor container registry.
Using a central model gallery for your ML models has the following benefits:
- Distribute models within your organization that you validated on a deep learning VM. Models on the Internet could contain malicious code or could be tuned for malicious behavior.
- Distribute models for continuous delivery across organizations or promoting it between platforms or environments.
- Maintain model integrity in your controlled environment.
- By using the Harbor project access capabilities, you can restrict access to sensitive data that is used to train and tune a model.
- Store metadata in the Open Container Initiative (OCI) format describing the contents and dependencies of your ML models. In this way, you can identify the platforms that can run a target model.
You can use Harbor to store models from the NVIDIA NGC catalog, Hugging Face, and another ML model catalog.
What Is a Model Gallery?
A model gallery in VMware Private AI Foundation with NVIDIA is a Harbor project with the following configuration:
| Mode Gallery Entity | Harbor or OCI Entity | Requirements |
|---|---|---|
| Model gallery | Project with configured user access | Must have a unique name in the Habor registry. |
| Model | OCI repository | Must have a unique name in the project according to the OCI format. |
| Revision | OCI artifact | Immutable manifest that is identified by content digest. If the same model data is pushed multiple times, only one revision is stored. If the model data changes, each push operation creates a new revision. You can tag a model revision. Unlike in a container ecosystem, although supported, the |
| File | OCI layer and blob | - |
For example, Harbor uses the following format for an example Llama model revision:
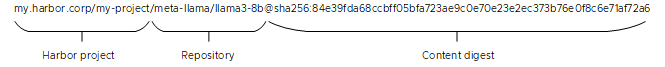
Pushing to and Pulling Models from a Model Gallery
In VMware Private AI Foundation with NVIDIA, you can use a deep learning VM to validate and fine tune models, downloaded from a public container registry or from a container registry in your organization. Then, you use the pais command line utility on the VM to push to and pull models from and across model galleries in Harbor.
Updating the pais Command Line Utility in Deep Learning VMs
You can download new versions and hot fixes of the pais CLI from the Broadcom Support portal. To update the pais CLI in your deep learning VMs from a local package repository.
- Download the pais binary file from the VMware Private AI Services CLI download group on the Broadcom Support portal in the current user directory on the deep learning VM.
- Set execution permissions on the pais file.
chmod 755 ./pais
- Verify that the version of the binary file is the expected one.
./pais --version
- Back up the active pais version in the /usr/local/bin directory.
mv /usr/local/bin /usr/local/bin/pais-backup
- Replace the active version of the pais binary file with the downloaded one.
sudo mv ./pais /usr/local/bin/pais
Before You Begin Storing ML Models in VMware Private AI Foundation with NVIDIA
Storing ML models in Harbor requires the use of deep learning VMs that you can deploy by using VMware Aria Automation or request from your cloud administrator or DevOps engineer.
- Verify that VMware Private AI Foundation with NVIDIA is configured up to this step of the deployment workflow. See Preparing VMware Cloud Foundation for Private AI Workload Deployment.
-
Verify that you have access to a Harbor registry with read-write permissions to a project in Harbor. See Setting Up a Private Harbor Registry in VMware Private AI Foundation with NVIDIA.
-
If your organization uses VMware Aria Automation for AI development, verify that the following prerequisites are in place:
- Verify that your cloud administrator has set up the VMware Aria Automation catalog for private AI application deployment according to Add Private AI items to the Automation Service Broker catalog.
- Verify the your cloud administrator has assigned the user role that is required for deploying deep learning VMs.
Example Workflow: Validate and Upload an ML Model to a Model Gallery
As an MLOps engineer, you validate ML models that are onboarded against the security, privacy, and technical requirements of your organization. You can then upload the models to a dedicated model gallery for use by AI application developers or MLOps engineers for automated CI/CD based deployment of model runtimes.
Procedure
What to do next
Example Workflow: Deploy an ML Model to Run Inference
After an ML model is validated and uploaded to the model gallery in your Harbor registry, an MLOps engineer can run that model for inference on a deep learning VM running a Triton Inference Server from NVIDIA NGC catalog.
