The behavior of the NSX Advanced Load Balancer after a failure in a GSLB deployment depends on where the failure is.
The failure can occur:
At a leader site or in one of the followers
For the entire site or only for the NSX Advanced Load Balancer Controller
Follower Site Failures
In our follower-site failure examples, we focus on infrastructure deployed in Santa Clara, Chicago, and New York.
Issue |
Resolution |
|---|---|
Full-Site Failure |
A full-site failure occurs at the NY-1 follower site, as shown below.
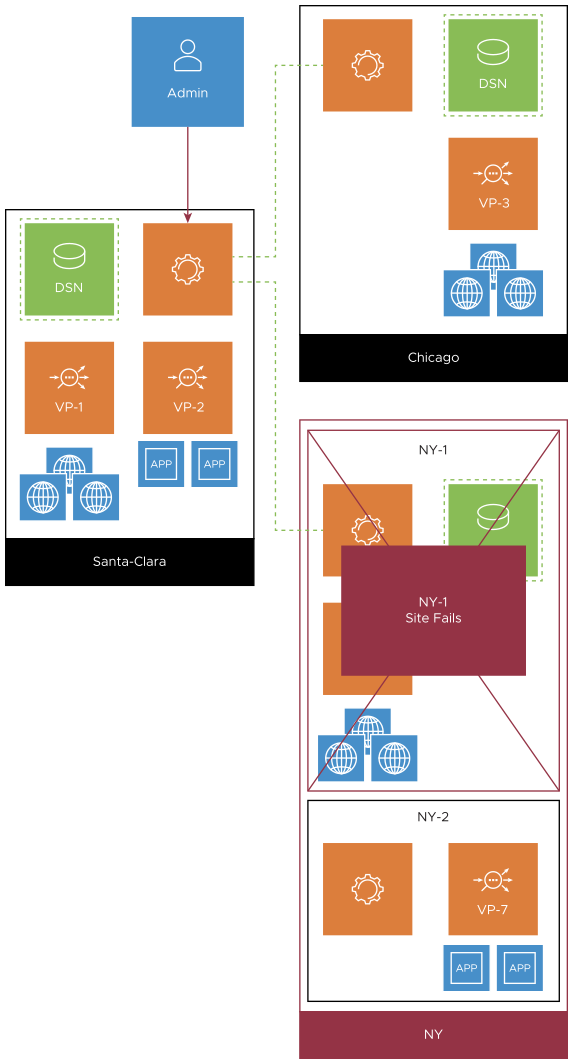
|
Partial-site Failure |
If only the NSX Advanced Load Balancer Controller at the NY-1 site fails, the SEs continue to serve applications in headless mode.
|
Follower Site Recovery |
The following holds true for either full-site or partial-site failures.
|
Leader Site Failures
Issue |
Resolution |
|---|---|
Full-Site Failure |
A full-site failure occurs at the Santa Clara leader site, as shown below. 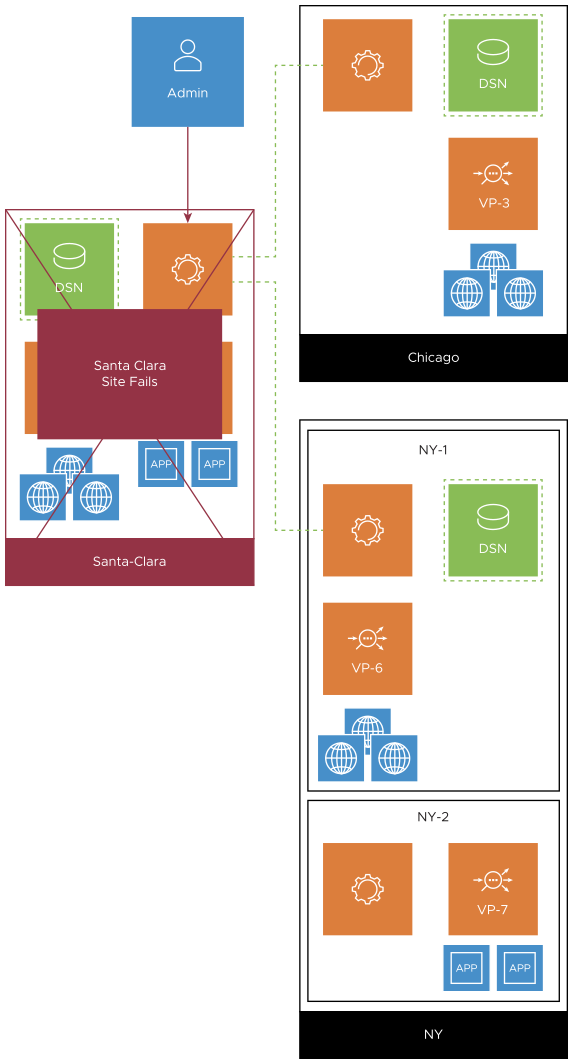
|
Partial-Site Failure |
If only the NSX Advanced Load Balancer Controller at the Santa Clara site fails, the site’s SEs continue to serve applications in headless mode.
|
Leader Site Change
A new leader is designated in neither of the above leader-site failure scenarios. The re-election process is not automatic. Instead, an optional and manual operation can be initiated at any active follower site, either to restore the ability to lead or for site maintenance. Both Chicago and NY-1 qualify as potential leaders if Santa Clara’s Controller is down. From either follower site the steps would be:
A GSLB administrator logs into the follower site's Controller and commands it to become the new leader. Until it becomes the leader, it is the leader-designate.
A take-over message is propagated to all other NSX Advanced Load Balancer sites, apprising them of the change in command.
If the old leader (Santa Clara) comes back up, it assumes the role of a follower due to the take-over message queued for transmission while it was down.
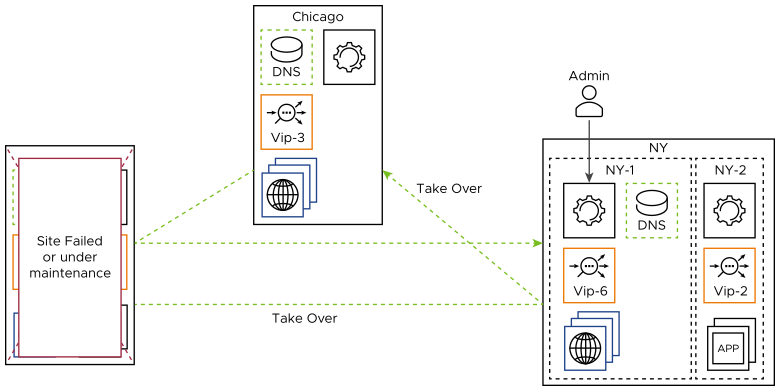
GSLB followers trust all configuration commands from their leader. Although the command to become a leader might be considered a configuration command, it is highly privileged and never sent from another site. Rather, it requires an admin with the appropriate credentials to log into the Controller being promoted to the leadership role.
For more information, see Detaching GSLB Site from Unresponsive Leader Site.
Network Partitioning
Network partitioning occurs due to failures or outages in the internet or VPN infrastructure between the sites. In the case of network failure, each site updates the GS member state based on control-plane and data-plane health monitors. Both parts of the network act as independent and exclusive subnetworks.
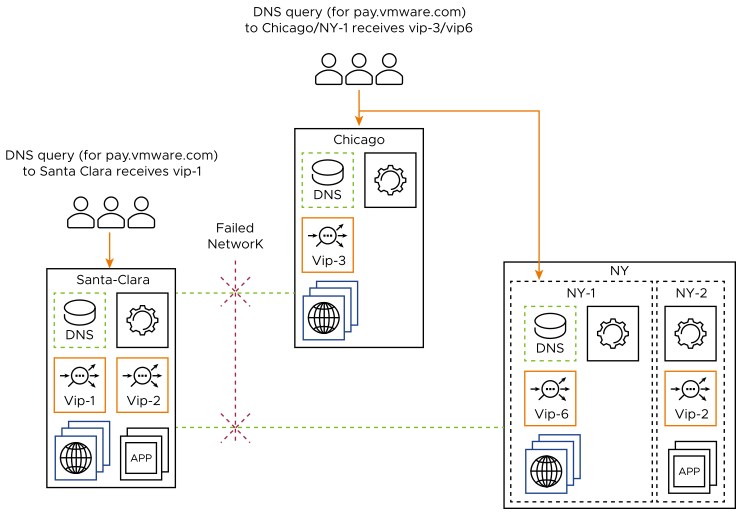
Hence, each site responds to DNS queries using only the member virtual services to which it has connectivity. In the above example, DNS queries to Santa Clara would be resolved to lead clients to vip-1, whereas DNS queries to Chicago or NY-1 would lead clients to either vip-3 or vip-6.
Santa Clara remains the leader during the network outage, notwithstanding its inability to access the other two NSX Advanced Load Balancer sites. No new leader is automatically elected on the other network partition, nor is it required that there be a leader.
When an active site within such a leaderless partition is promoted to the leadership role, the UUID of that site’s Controller and the Gslb.view_id parameter generated are shared with other followers within the partition. If a network repair causes a leader outside the partition to re-attempt GSLB configuration changes on sites within the partition, those attempts will be rejected due to the view_id clash. This prevents the confusion that would otherwise arise from followers obeying configuration commands from more than one leader.
Site Configuration Errors
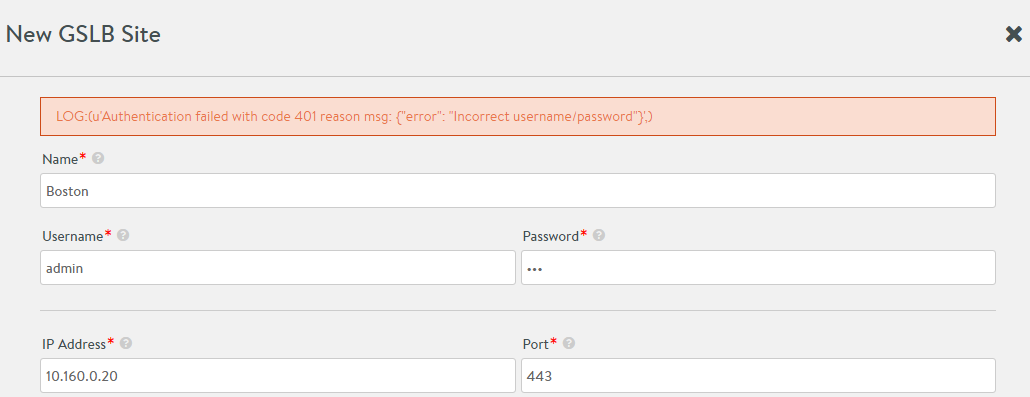
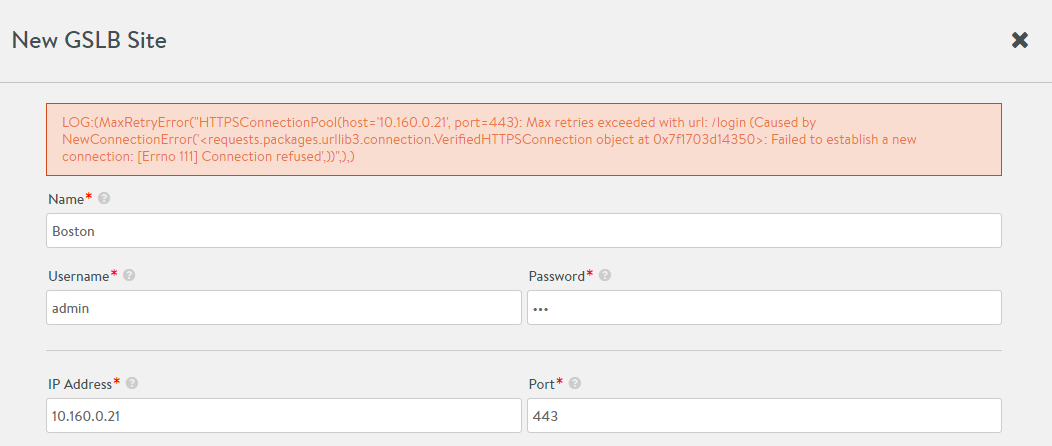
Errors in site configuration related to IP address and credentials show up when the site information is saved. Some sample error screens are as follows:
Authentication Failure
Max Retry Login Failure
Redress
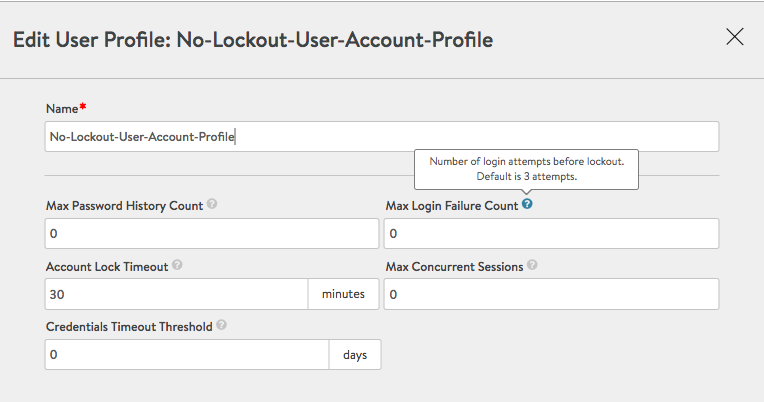
When defining a new GSLB configuration or adding a GSLB site to an existing configuration, one specifies account credentials to be associated with the site. It is a best practice to define the same GSLB administrative account (for example, gslbadmin) for all participating GSLB sites. By associating with that account (for example, No-Lockout-User-Account-Profile as shown below), one can eliminate max retry login failures.
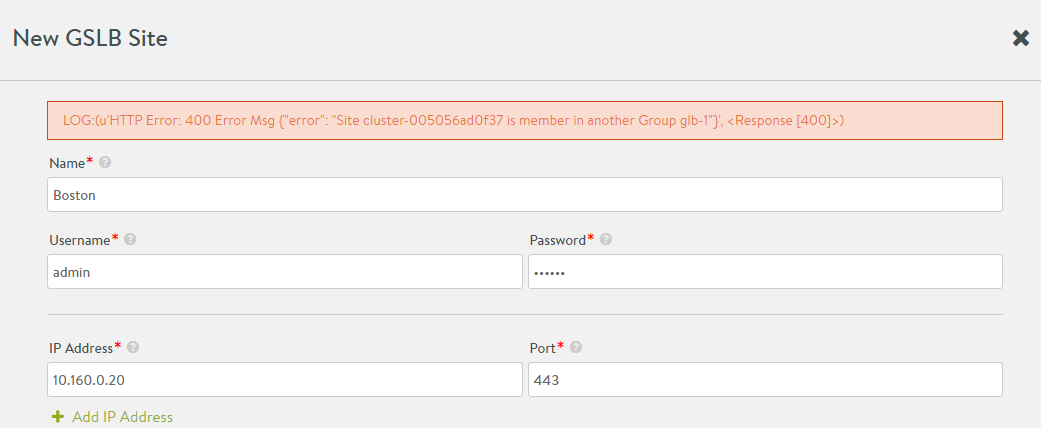
HTTP 400 Error