









You can trigger a failover and switchover when using a multi-site configuration.
A failover or switchover performs the following tasks: 1. Redirects traffic from primary to secondary foundation 1. Promotes original follower to be the leader 1. Reconfigures replication
These operations redirect traffic from your primary to your secondary foundation, and promote your secondary foundation’s former follower to be the new leader. Failover discards your primary foundation’s former leader. Switchover reconfigures that former leader as a new follower to your secondary foundation’s newly-promoted leader.
For information about when to trigger a failover or switchover, see About Failover and Switchover.
Before you trigger a failover or switchover, you must verify that the follower service instance is healthy. See Verify Follower Health.
The procedures in this topic assume that you created the leader service instance in the primary foundation and the follower service instance in the secondary foundation.
Verify follower health
Before you trigger a failover or switchover, you must verify that the follower service instance is healthy. If your follower service instance is unhealthy, contact Support.
To verify the service instance:
-
Log in to the deployment for your secondary foundation by running:
cf login SECONDARY-API-URLWhere
SECONDARY-API-URLis the API endpoint for your secondary foundation. -
Record the GUID of the follower service instance by running:
cf service SERVICE-INSTANCE-NAME --guidWhere
SERVICE-INSTANCE-NAMEis the name of the follower service instance.
For example:$ cf service secondary-db --guid 12345678-90ab-cdef-1234-567890abcdef
- Obtain the credentials and IP address needed to SSH into the Ops Manager VM by following the procedure in Gather Credential and IP Address Information.
-
SSH into the Ops Manager VM by following the procedure in Log in to the Ops Manager VM with SSH.
-
From the Ops Manager VM, log in to your BOSH Director by following the procedure in SSH Into the BOSH Director VM.
-
View the health of the service instance by running:
bosh -d service-instance_GUID instanceFor example:
$ bosh -d service-instance_12345678-90ab-cdef-1234-567890abcdef instance Using environment 'https://10.0.0.6:25555' as client 'admin' Task 21409. Done Deployment 'service-instance_12345678-90ab-cdef-1234-567890abcdef' Instance Process State AZ IPs mysql/1373022d-4eab-46d3-8fd1-a12067edf597 running z2 10.0.17.14 1 instances Succeeded -
Ensure that the service instance is
running. If the service instance isfailing, contact Support.
Select your promoted leader topology
Failover and switchover operations promote your secondary foundation’s follower service instance into a leader. (We call a promoted follower “leader” whether or not it is configured to have a “follower”.) That follower is a service instance created with a multi‑site replication plan.
During follower promotion, you may optionally update it to a HA Cluster plan. See Select a multi-site leader topology for more information.
Note Updating to an HA cluster requires more time than keeping the existing multi‑site replication plan type.
Trigger a failover
Only trigger a failover if you do not need to recover the leader service instance.
To trigger a failover:
- Promote the follower
- Promote the follower
- Delete or purge the former leader
- Create a new follower
- Reconfigure multi-site replication
Promote the follower
Note: This procedure only applies to a multi-site follower service instance. If you try promoting any other service instance to a leader, you will receive an error message similar to:
Updating service instance nonfollower-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: 1 error occurred: * the configuration parameter 'initiate-failover' is not a valid option
To promote the follower service instance to leader:
-
Log in to the deployment for your secondary foundation by running:
cf login SECONDARY-API-URLWhere
SECONDARY-API-URLis the API endpoint for your secondary foundation. -
Promote the follower service instance to leader by running one of these two commands, based the selection you made above in Select your promoted leader topology:
- To keep your service instance on its existing single-VM multi‑site replication topology, run the following command:
cf update-service SECONDARY-INSTANCE \ -c '{"initiate-failover":"promote-follower-to-leader"}'For example:
$ cf update-service secondary-db \ -c '{"initiate-failover":"promote-follower-to-leader"}'
Updating service instance secondary-db as admin... OK -
To scale up your service instance to a three-VM HA cluster topology, run the following command:
cf update-service SECONDARY-INSTANCE \ -c '{"initiate-failover":"promote-follower-to-leader"} \ -p HA-PLAN-NAME'Where HA-PLAN-NAME is the name of a plan configured in your second foundation’s Operations Manager with a HA Cluster topology.
For example:
$ cf update-service secondary-db \ -c '{"initiate-failover":"promote-follower-to-leader"} \ -p configured-ha-plan
Updating service instance secondary-db as admin... OK -
If this command fails, do one of the following:
- If you have unapplied local transactions on the follower service instance, wait for the transactions to be applied and run the command again. The error message looks like the following:
Updating service instance secondary-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: Promotion of follower failed - has 1 transactions still unapplied
- If the leader service instance is still reachable and in read-write mode, follow the procedure in Trigger a Switchover instead. The error message looks like the following:
Updating service instance secondary-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: Promotion of follower failed - the leader is still writable
- If you have unapplied local transactions on the follower service instance, wait for the transactions to be applied and run the command again. The error message looks like the following:
-
Watch the progress of the service instance update by running:
watch cf servicesWait for the
last operationfor your instance to show asupdate succeeded.
For example:$ watch cf services
Getting services in org my-org / space my-space as admin... OK name service plan bound apps last operation secondary-db p.mysql db-pxc-single-node-small update succeeded -
Reconfigure your global DNS load balancer to direct all traffic to apps in your secondary foundation. See Configure Your GLB.
Delete or purge the former leader
When you do a failover, you cannot manually recover the leader service instance. After you promote the follower service instance to leader, you remove the former leader service instance. Otherwise, the service instance can recover in read-write mode.
The way you remove the service instance depends on whether its VMs and responsiveness have been lost or not.
To remove the former leader service instance:
-
Log in to the deployment for your primary foundation by running:
cf login PRIMARY-API-URLWhere
PRIMARY-API-URLis the API endpoint for the primary foundation. -
Do one of the following:
- If a multi‑site replication follower VM is lost or your follower is otherwise non-responsive, purge the service instance by doing the procedure Purge a Service Instance in Using VMware SQL with MySQL for Tanzu Application Service.
If the foundation is lost, you purge the service instance after following the steps to recover the foundation's Cloud Controller database in Restoring Deployments from Backup with BBR.
-
If your service instance is still responsive:
-
Remove all app bindings by following the procedure Unbind an App from a Service Instance in Using VMware SQL with MySQL for Tanzu Application Service.
-
Delete the service keys from the former leader service instance.
-
Delete the service instance by following the procedure Delete a Service Instance in Using VMware SQL with MySQL for Tanzu Application Service.
-
- If a multi‑site replication follower VM is lost or your follower is otherwise non-responsive, purge the service instance by doing the procedure Purge a Service Instance in Using VMware SQL with MySQL for Tanzu Application Service.
Create a new follower
To reconfigure multi-site replication between two instances, a new follower without any data must be created in the primary foundation.
To create a follower:
-
Log in to the deployment for your primary foundation by running:
cf login PRIMARY-API-URLWhere
PRIMARY-API-URLis the API endpoint for the primary foundation. -
Create a service instance using the multi‑site replication plan:
- Follow the procedure in Create a Service Instance in Using VMware SQL with MySQL for Tanzu Application Service.
- Do not name your service instance
followerbecause, if in the future you trigger a failover or switchover, this instance can no longer be the follower.
Reconfigure multi-site replication
The follower in the primary foundation needs to catch up to the newly promoted leader in the secondary foundation.
Reconfigure multi-site replication so that the primary foundation follower receives the data from the secondary foundation leader.
To reconfigure, follow the procedure in Reconfigure multi-site replication.
Trigger a Switchover
To trigger a switchover:
Note: This procedure only applies to configured multi-site service instances. If you try promoting other service instances to be read-only or a multi-site leader, you will receive an error message similar to:
Updating service instance non-mutisite-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: 1 error occurred: * the configuration parameter 'initiate-failover' is not a valid option
Make the leader read-only
-
Log in to the deployment for your primary foundation by running:
cf login PRIMARY-API-URLWhere
PRIMARY-API-URLis the API endpoint for the primary foundation. -
Set your leader to read-only.
- If your leader is an HA service instance, set it to read-only and downscale it to a single node by running:
cf update-service PRIMARY-INSTANCE \ -c '{"initiate-failover":"make-leader-read-only"}' \ -p MULTI-SITE-REPLICATION-PLANwhere MULTI-SITE-REPLICATION-PLAN is the name of a service plan configured with the multi‑site replication topology.
For example:
$ cf update-service primary-db \ -c '{"initiate-failover":"make-leader-read-only"}' \ -p multi-site-single-node-plan
Updating service instance primary-db as admin... OK- If your leader is a single-node multi‑site replication service instance, set it to read-only by running:
cf update-service PRIMARY-INSTANCE \ -c '{"initiate-failover":"make-leader-read-only"}'For example:
$ cf update-service primary-db \ -c '{"initiate-failover":"make-leader-read-only"}'
Updating service instance primary-db as admin... OK-
The service instance can be made writable again by running:
cf update-service --wait PRIMARY-INSTANCE -c '{"multisite": "make-leader-writeable"}''For example:
$ cf update-service --wait primary-node -c '{"multisite": "make-leader-writeable"}'
Updating service instance primary-node as admin... OK -
To determine whether your leader was created from a multi‑site replication or a HA cluster plan, run
cf servicesand look in the “plan” column. Consult your platform operator if you are unsure which plans correspond to which service instance type.
-
Watch the progress of the service instance update by running:
watch cf servicesWait for the
last operationfor your instance to show asupdate succeeded.
Promote the follower
-
Log in to the deployment for your secondary foundation by running:
cf login SECONDARY-API-URLWhere
SECONDARY-API-URLis the API endpoint for your secondary foundation. -
Promote the follower service instance to leader by running one of these two commands, based the selection you made above in Select your promoted leader topology:
-
To keep your service instance on its existing single-VM multi‑site replication topology, run the following command:
cf update-service SECONDARY-INSTANCE \ -c '{"initiate-failover":"promote-follower-to-leader"}'For example:
$ cf update-service secondary-db \ -c '{"initiate-failover":"promote-follower-to-leader"}'
Updating service instance secondary-db as admin... OK -
To scale up your service instance to a three-VM HA cluster topology, run the following command:
cf update-service SECONDARY-INSTANCE \ -c '{"initiate-failover":"promote-follower-to-leader"} \ -p HA-PLAN-NAME'Where HA-PLAN-NAME is the name of a plan configured in your second foundation’s Operations Manager with a HA Cluster topology.
For example:
$ cf update-service secondary-db \ -c '{"initiate-failover":"promote-follower-to-leader"} \ -p configured-ha-plan
Updating service instance secondary-db as admin... OK -
If this command fails, do one of the following:
- If you have unapplied local transactions on the follower service instance, wait for the transactions to be applied and then run the command again. The error message might look like the following:
Updating service instance secondary-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: Promotion of follower failed - has 1 transactions still unapplied
- If the leader service instance is still reachable and in read-write mode, verify that you successfully completed the above steps in Make the leader read-only. The error message might look like the following:
Updating service instance secondary-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: Promotion of follower failed - the leader is still writable
- If you have unapplied local transactions on the follower service instance, wait for the transactions to be applied and then run the command again. The error message might look like the following:
-
Watch the progress of the service instance update by running:
watch cf servicesWait for the
last operationfor your instance to show asupdate succeeded.
Reconfigure multi-site replication
To establish a connection between the service instances in the primary and secondary foundations, you must reconfigure replication. Reconfiguring replication is similar to the procedure in Configure multi‑site replication except the primary foundation service instance becomes the new follower and the secondary foundation service instance becomes the new leader.
To successfully trigger a switchover, the follower dataset must be a subset of the leader dataset. This means that multi-site replication has not written new data exclusively to the follower. The follower must also be no more than 3 days behind the leader.
If your follower instance does not satisfy these requirements, you must create a new multi‑site replication service instance and reconfigure replication using this new, empty instance as the follower.
Workflow for reconfiguring multi-site replication
The following diagram describes the workflow for reconfiguring multi-site replication:
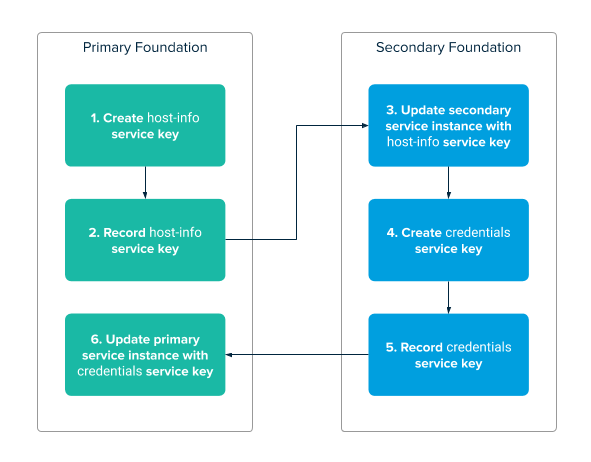
The steps shown in the diagram are:
- Create host-info service key.
- Record host-info service key.
- Update secondary service instance with host-info service key.
- Create credentials service key.
- Record credentials service key.
- Update primary service instance with credentials service key.
Procedure for reconfiguring multi-site replication
To reconfigure replication for the service instances:
-
Log in to the deployment for your primary foundation by running:
cf login PRIMARY-API-URL -
Create a host-info service key for the service instance in your primary foundation:
cf create-service-key PRIMARY-INSTANCE SERVICE-KEY \ -c '{"replication-request": "host-info"}'Where:
PRIMARY-INSTANCEis the name of the follower service instance in the primary foundation.SERVICE-KEYis a name you choose for the host-info service key.
For example:
$ cf create-service-key primary-db host-info \ -c '{"replication-request": "host-info" }'
Creating service key host-info for service instance primary-db as admin... OK -
View the
replication-credentialsfor your host-info service key by running:cf service-key PRIMARY-INSTANCE SERVICE-KEYWhere:
PRIMARY-INSTANCEis the name of the follower service instance in the primary foundation.SERVICE-KEYis the name of the host-info service key you created in previous step.
For example:
$ cf service-key primary-db host-info-key
Getting key host-info-key for service instance primary-db as admin... { "credentials": { "replication": { "peer-info": { "hostname": "878f5fb3-fcc5-43cd-8c1f-3018e9f277ad.mysql.service.internal", "ip": "10.0.19.12", "system_domain": "sys.primary-domain.com", "uuid": "878f5fb3-fcc5-43cd-8c1f-3018e9f277ad" }, "role": "leader" } } }Caution
This procedure assumes you are using cf CLI v8 or greater. Earlier cf CLI versions do not include the top-level
credentialsJSON key in theircf service-keyresponse. -
Record the output of the previous command, and remove the top-level
credentialskey. -
Log in to the deployment for your secondary foundation by running:
cf login SECONDARY-API-URL -
Update your secondary foundation service instance with the host-info service key by running:
cf update-service SECONDARY-INSTANCE -c HOST-INFOWhere:
SECONDARY-INSTANCEis the name of the secondary service instance you created in step 2 of Creating multi-site replication service instances.HOST-INFOis the output you recorded in step 4 above.
For example:
$ cf update-service secondary-db -c '{ "replication":{ "peer-info":{ "hostname": "878f5fb3-fcc5-43cd-8c1f-3018e9f277ad.mysql.service.internal", "ip": "10.0.18.12", "system_domain": "sys.primary-domain.com", "uuid": "878f5fb3-fcc5-43cd-8c1f-3018e9f277ad" }, "role": "leader" } }'
Updating service instance secondary-db as admin... OK -
Monitor the progress of the service instance update by running:
watch cf servicesWait for the
last operationfor your instance to show asupdate succeeded. -
Create a credentials service key for your secondary foundation service instance by running:
cf create-service-key SECONDARY-INSTANCE SERVICE-KEY-NAME \ -c '{"replication-request": "credentials"}'Where:
SECONDARY-INSTANCEis the name of the service instance in the secondary foundation.SERVICE-KEY-NAMEis a name you choose for the credentials service key.
For example:
$ cf create-service-key secondary-db cred-key \ -c '{"replication-request": "credentials" }'
Creating service key cred-key for service instance secondary-db as user@example.com... OKThe
-cflag is different than the one in step 2. -
View the
replication-credentialsfor your credentials service key by running:cf service-key SECONDARY-INSTANCE SERVICE-KEY-NAMEWhere:
SECONDARY-INSTANCEis the name of the service instance in the secondary foundation.SERVICE-KEY-NAMEis the name of the credentials service key you created in step 7.
For example:
$ cf service-key secondary-db cred-key
Getting key cred-key for service instance secondary as admin... { "credentials": { "replication": { "credentials": { "password": "a22aaa2a2a2aaaaa", "username": "6bf07ae455a14064a9073cec8696366c" }, "peer-info": { "hostname": "zy98xw76-5432-19v8-765u-43219t876543.mysql.service.internal", "ip": "10.0.17.12", "system_domain": "sys.secondary-domain.com", "uuid": "zy98xw76-5432-19v8-765u-43219t876543", "ports": { "mysql": 3306, "agent": 8443, "backup": 8081 }, }, "role": "follower" } } }Caution
This procedure assumes you are using cf CLI v8 or greater. Earlier cf CLI versions do not include the top-level
credentialsJSON key in theircf service-keyresponse. -
Record the output of the previous command, and remove the top-level
credentialskey. -
Log in to the deployment for your primary foundation by running:
cf login PRIMARY-API-URL -
Update the primary foundation service instance with the credentials service key by running:
cf update-service PRIMARY-INSTANCE -c CREDENTIALSWhere:
PRIMARY-INSTANCEis name of the service instance in the primary foundation.CREDENTIALSis the output you recorded in the previous step.
For example:
$ cf update-service primary-db -c '{"replication": { "credentials": { "password": "a22aaa2a2a2aaaaa", "username": "6bf07ae455a14064a9073cec8696366c" }, "peer-info": { "hostname": "zy98xw76-5432-19v8-765u-43219t876543.mysql.service.internal", "ip": "10.0.17.12", "ports": { "agent": 8443, "backup": 8081, "mysql": 3306 }, "system_domain": "sys.secondary-domain.com", "uuid": "zy98xw76-5432-19v8-765u-43219t876543" }, "role": "follower" } }'
Updating service instance primary-db as admin... OK -
Watch the progress of the service instance update by running:
watch cf servicesWait for the
last operationfor your instance to show asupdate succeeded.
You now have a multi-site replication successfully configured, where the new leader is in your secondary foundation and the new follower is in the primary foundation.
If this command fails and you get one of the following errors, you must create a new multi‑site replication service instance in your primary foundation and reconfigure replication using this new empty instance as the follower.- If your follower service instance is more than 3 days behind leader, you get error message similar to the following:
$ cf update-service primary-db -c /tmp/credentials-key.json Updating service instance primary-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: Establishing Replication Failed - follower is too far behind Leader to start replication Leader GTIDs offering: "487e6056-6e93-11ea-8c96-42010a010806:5-9" Follower GTIDs missed: "487e6056-6e93-11ea-8c96-42010a010806:1-9" Try again with an empty instance or contact your operator to troubleshoot
- If your follower has a divergent dataset from the leader, you get error message similar to the following:
$ cf update-service primary-db -c /tmp/credentials-key.json Updating service instance primary-db as admin... FAILED Server error, status code: 502, error code: 10001, message: Service broker error: Establishing Replication Failed - the follower has divergent data Leader GTIDs applied: "bd2ff185-6947-11ea-80d8-42010a000808:1-20" Follower GTIDs applied: "c1abd2a4-6947-11ea-8099-42010a010807:1-15" Try again with an empty instance or contact your operator to troubleshoot
In either case, you must create a new multi‑site replication service instance and reconfigure replication using this new empty instance as the follower.
- If your follower service instance is more than 3 days behind leader, you get error message similar to the following:
- Reconfigure your global DNS load balancer to direct traffic to the correct foundations of your choice. See Configure Your GLB.
