









AWS Best Practice Policies
This article discusses the best practice policies for AWS accounts in Tanzu CloudHealth.
Financial Governance
Identify Offending Services
You can have greater control over your costs by benchmarking the cost of each AWS service month over month. If you have a large number of assets, this task can get overwhelming. So a best practice is to manage by exception. Start by identifying those services that changed by more that 20%.
Sample Service Cost Increase Policy: This policy alerts stakeholders when the Total Cost of your AWS bill increases by more than a certain percentage within the specified time interval.
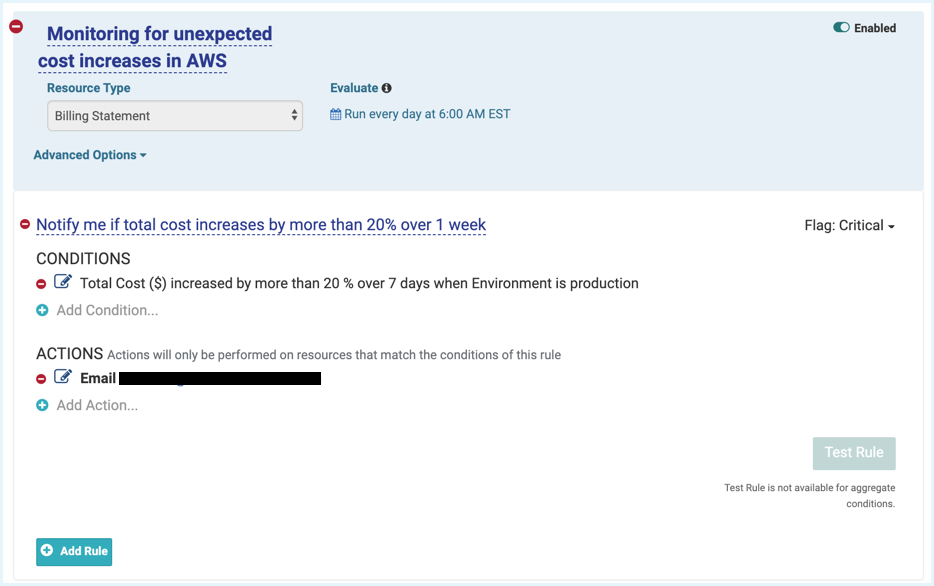
Variants:
- Limit this policy to certain AWS Service Types, for example, CloudFront Costs.
- Leverage Perspectives. For example, send an alert when the Transfer Costs for the Production environment increase by 20% over 1 month and send an alert when the Total Cost of any of your Departments increases by 20%.
- If your CloudFormation cost increases by 10% or more in one month, identify this increase before the trend continues upward.
Identify Offending Groups
When your cloud costs are rising, it is critical to proactively identify cost variances by the offending functional business group.
Examples
- The monthly cost for any environment is projected to increase by more than 10% compared to the previous month.
- The actual monthly cost for any environment has increased more than 10% compared to the previous month.
- The projected monthly cost for any department will exceed the budget by more than 5%.
- The actual monthly cost for any department has exceeded the budget by more than 5%.
Sample Group Cost Increase Policy: This policy alerts stakeholders when the development environment costs exceeds a specific ($) amount. Use this policy to control or monitor month-over-month costs for a single service or across all services.
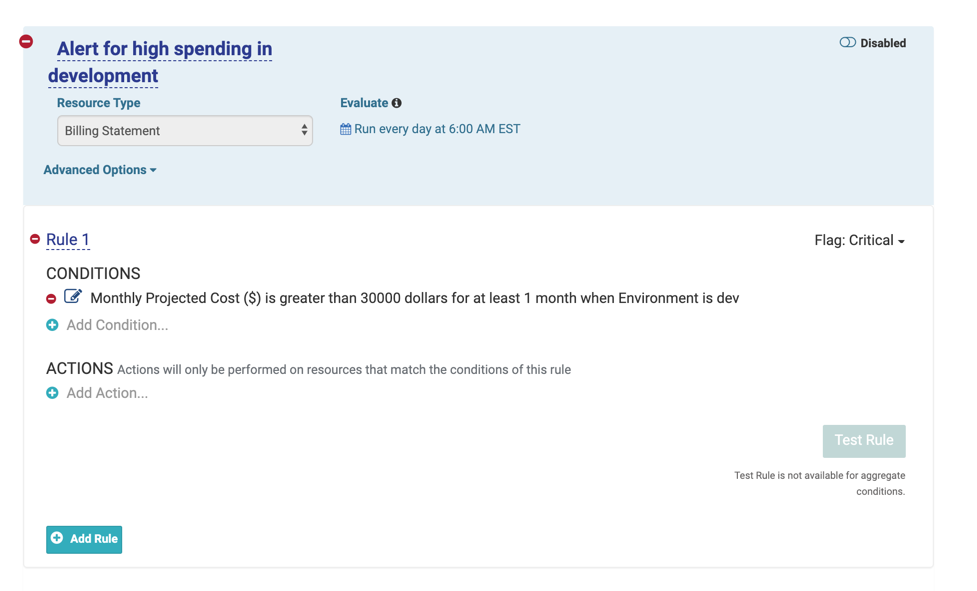
Budget and Cost Trend Monitoring
Set a budget and compare how your monthly spend is tracking with reference to that budget. Tanzu CloudHealth customers can configure the policy to evaluate when MTD Actual Cost is within their budget, or when MTD Projected Cost is expected to exceed the budget.
Example: If MTD Cost > 100% of budget, then send email notification
Sample Over Budget Policy: This policy alerts stakeholders when the projected cost for the month is expected to be above the originally specified budget by a certain threshold. Use it to track your actual spend in comparison to your allocated budget.
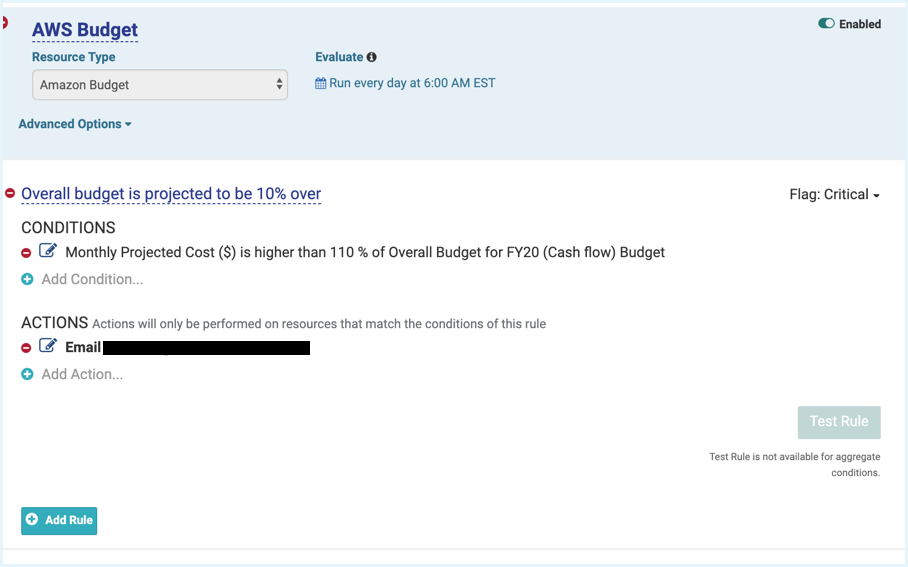
Variants
- Use Perspectives. If projected MTD for Production spend is > 100% of budget, send email notification to budget owner.
- Compare the MTD Actual Cost with the budget.
Other Sample Policies for Cost Trends
- If total cost increased by more than 40% in one week, send notification.
- If total S3 costs increase by more than 10% in 1 day, send notification.
- If the total projected cost of your AWS assets will exceed the cost in the previous billing period.
- The total cost of your AWS assets has exceeded the cost in the previous billing period.
Unexpected Cost Increase
When overall costs in your cloud environment increase suddenly, it could be an indicator of a larger problem. Anomaly Detection helps you identify an increase or sudden decrease in cost and usage and make informed decisions. You can set a policy to alert you when the cost impact of anomalies exceeds the specified threshold. To create an alert, select AWS anomaly as the resource type when building the policy. For more details, see Cost Anomaly Detection.
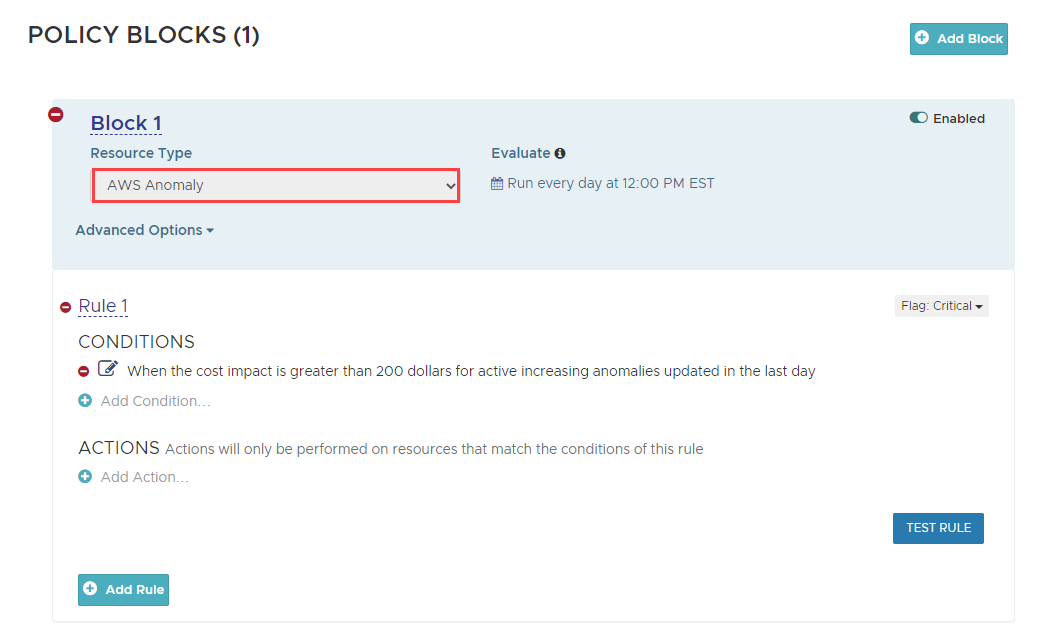
Cost Optimization
Identity Reserved Instance Purchase
Purchasing reserved instances (RIs) is a great way to receive a significant discount on the hourly prices for instances and maximize your pricing alternative. Based on your EC2 compute usage history, instances that are running On-Demand more than 50% of the time should be identified and you should consider purchasing reserved capacity for them. Of course, rightsizing your instances must always be done before making any RI purchase.
Example: Instance MTD On-Demand Hours > 500 hours
Sample Identified RI Purchase policy: Policy monitors your month-to-date on-demand usage to see if there is an opportunity to reduce your AWS cost by purchasing Reserved Instances for one or more EC2 instances.
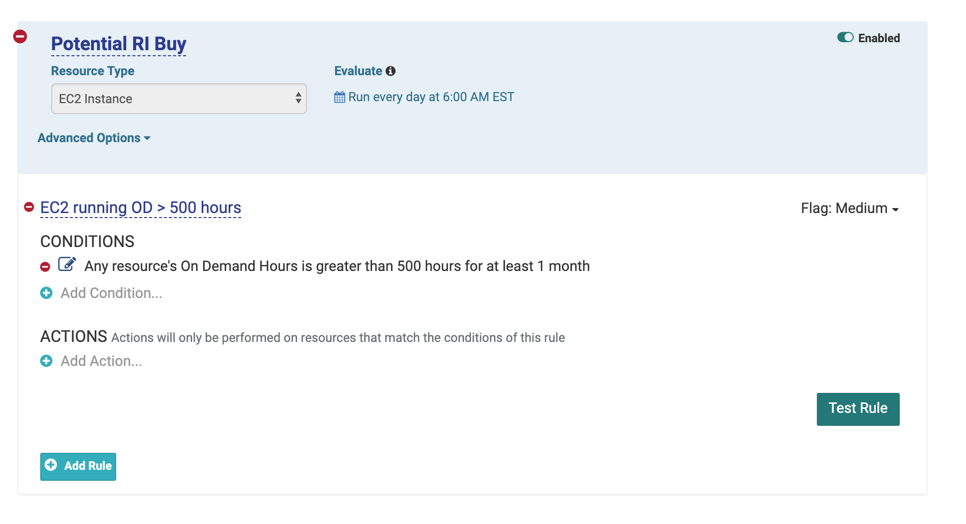
Variant
- Notify when any instance usage of %Reserved is less than 50% for at least 1 month
Modify Reserved Instances
These policies can be used to track and optimize the benefits of your reserved instances. They can help correlate those benefits to meet your changing business needs as your cloud footprint grows and changes.
Sample Modify RI Policy: This policy can execute any possible EC2 RI modification when the savings resulting from the modification exceeds a certain ($) amount. This policy will also alert specific users when the RI modification has been executed.
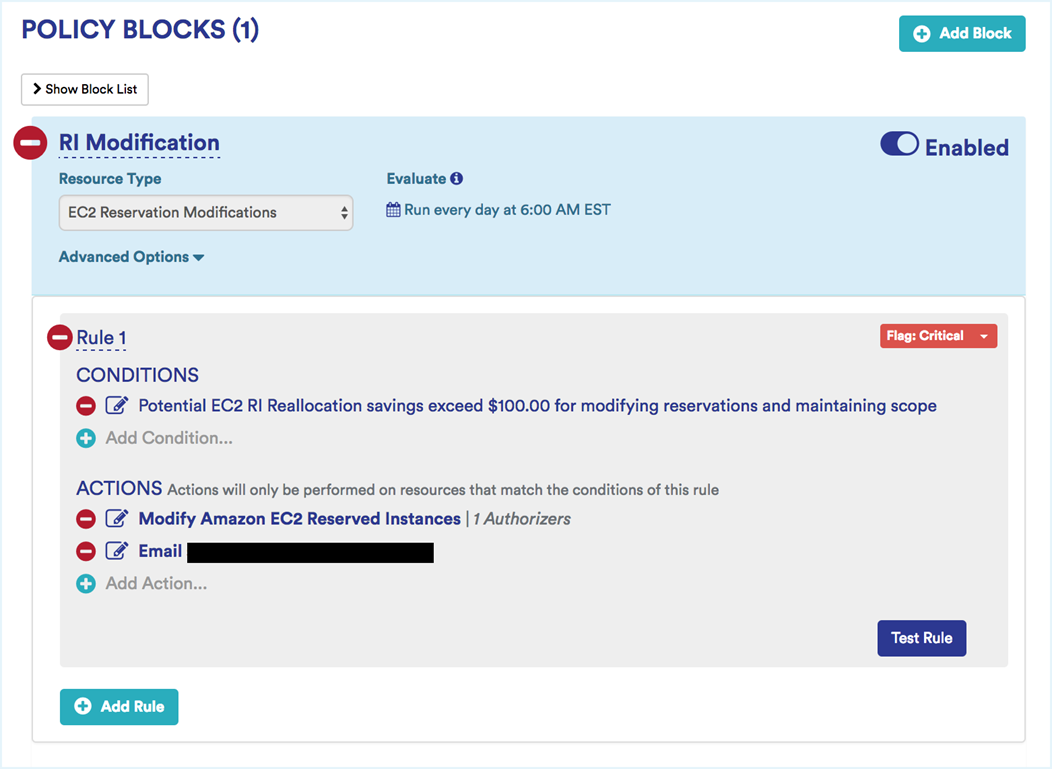
Variant
- Notify when any instance usage of %Reserved is less than 50% for at least 1 month
Identify Underutlized Reserved Instances
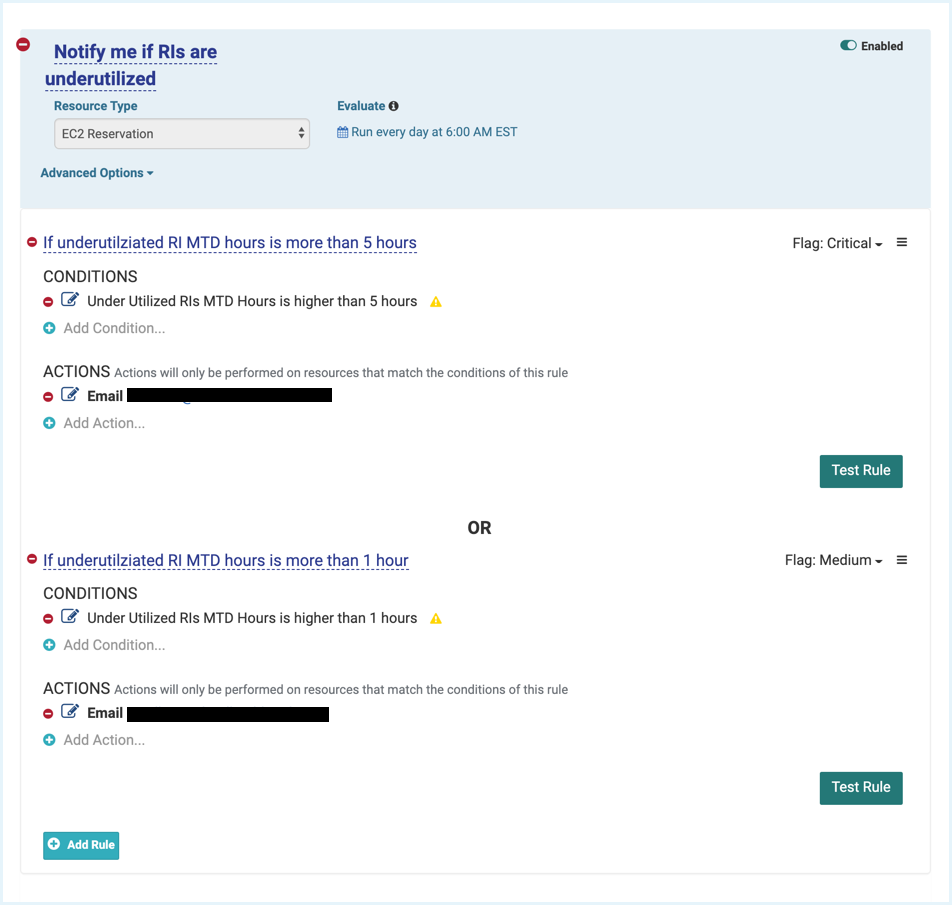
Sample Underutilized RI Policy: This policy notifies when RIs are underutilized during hourly usage. The first notification is flagged as a warning (i.e., underutilized RI hours MTD > 1 hr) while the second one is flagged as critical (i.e., underutilized RI hours MTD > 5 hr).
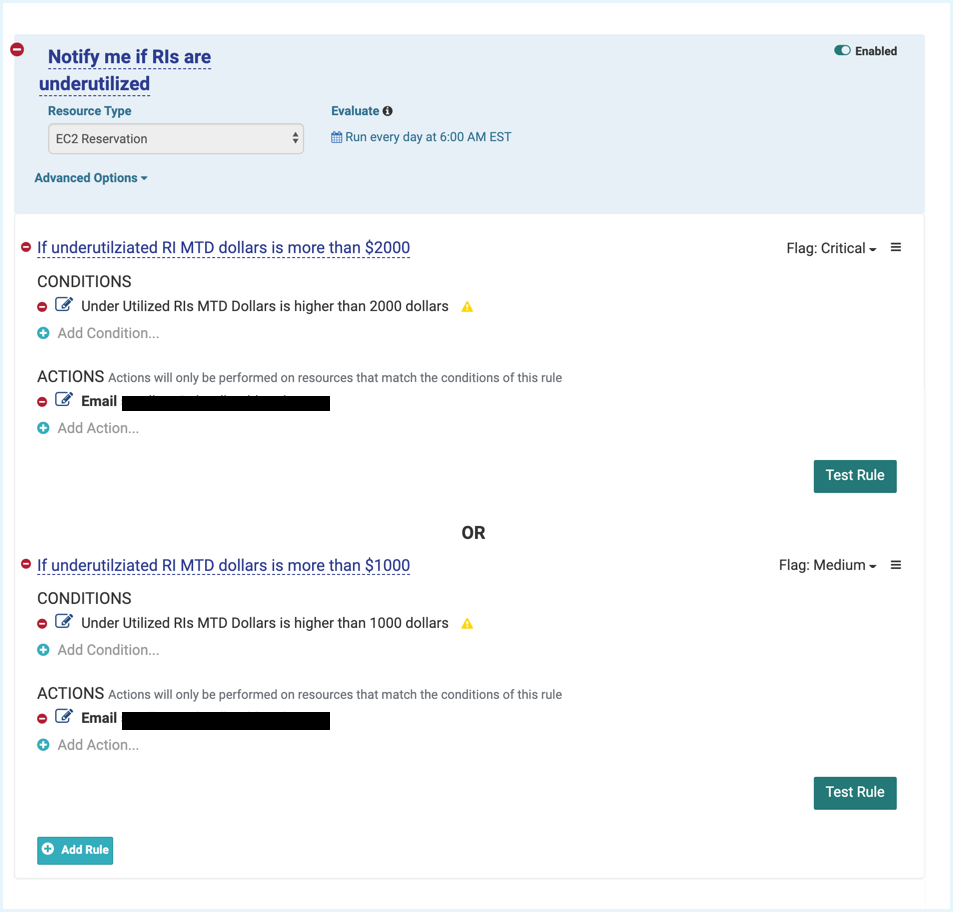
Sample RI Hour Utilization Policy: This policy notifies when RIs are underutilized based on wasted monthly cost. You can create increasing flag levels for the notifications before taking action.
Operational Governance
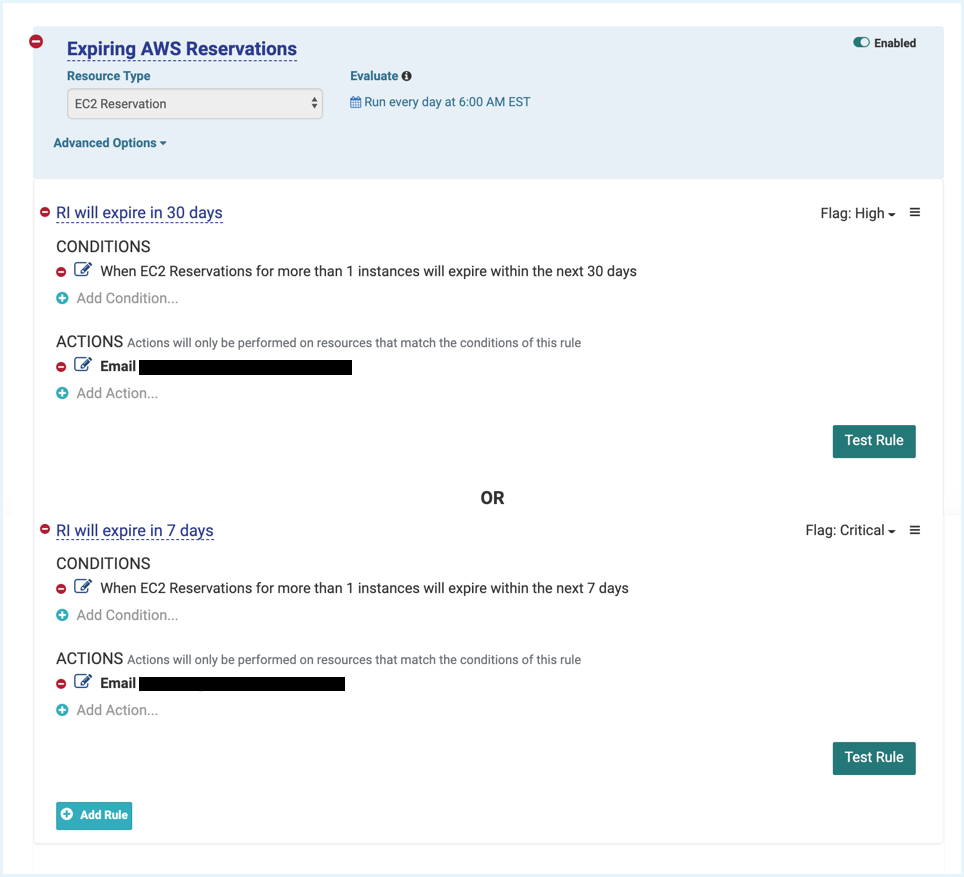
Identify Expiring Reserved Instances
Get notified about RIs that are expiring in the next 60-90 days so that you have enough time to do a rightsizing analysis and determine which new ones should be purchased.
Sample Expiring RI Policy: Expiring Reservations in 60 days, high alert. Expiring Reservations in 30 days, critical alert.
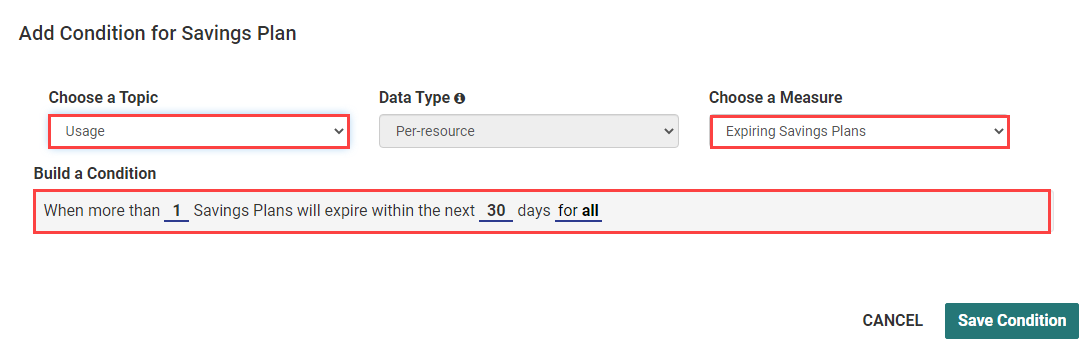
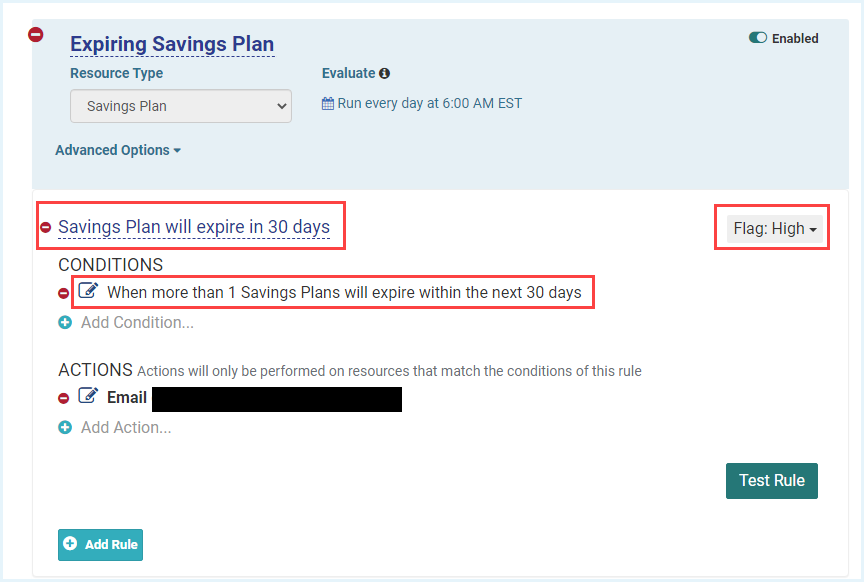
Identify Expiring Savings Plans
AWS Savings Plans are a discount mechanism where users commit to a certain amount of AWS spend for every hour, for 1 year or 3 years. Using the Tanzu CloudHealth platform, you can create an alert to track the Savings Plans that are expiring shortly. For example, you can set an alert 60-90 days in advance of your Savings Plans expiration date, so that you will have enough time to make informed business decisions like if and how you plan to replace that Savings Plan.
Sample Expiring Savings Plan Policy: Expiring Savings Plans in 30 days, high alert.
Identify and Terminate Zombie Instances
These are running instances that are idle, most likely forgotten, and costing you money. Identify instances that are running with a daily average CPU rate lower than 10% for 2 weeks in a row and Network I/O less than 5 MB for 4 or more days. If you want to be more specific, isolate instances based on their instance type.
Example: C-type instances (compute intensive) that have a Maximum CPU less than 10% for the last 14 days are most likely to be running idle and are good candidates to be terminated.
Sample Zombie Instance Identifying Policy: This policy identifies potential zombie EC2 instances. It looks at specific instance types that are either compute optimized (e.g., C family) or storage and I/O optimized. Two rules make up this policy:
- Rule 1: Identify C-class instance types that have a low average CPU %, stop them, and notify the IAM user (i.e., owner) of these instances.
- Rule 2: Identify HS-class instances that have low average read and write operations, stop them, and notify the IAM user of these instances.
These two rules would evaluate separately. In addition, by leveraging Tanzu CloudHealth Perspectives, you can run these rules against specific non-production environments.
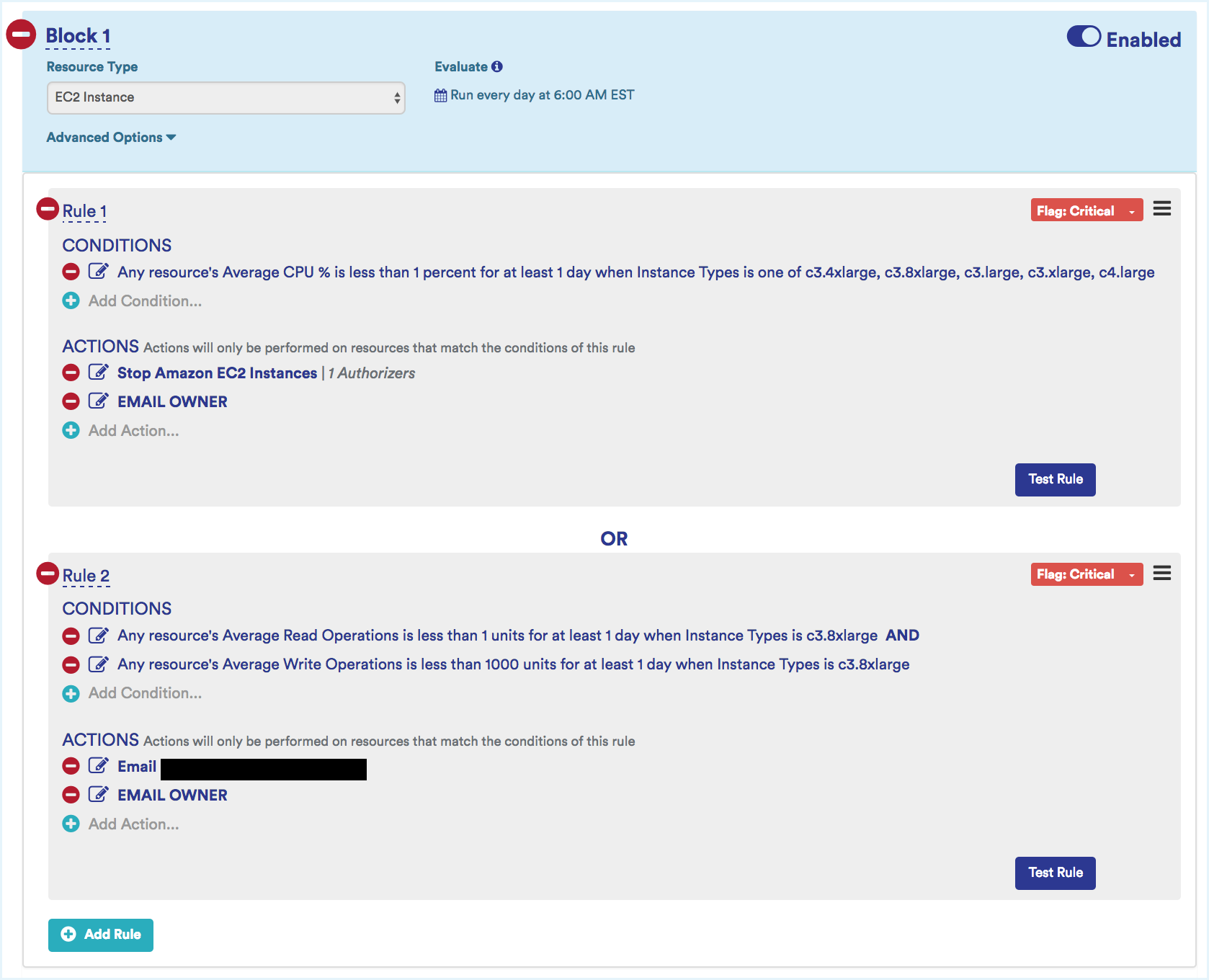
Variant: Add different rules that capture other performance metrics such as network traffic.
Identify and Terminate Zombie Volumes
These are EBS volumes that were launched with an instance but left unattached after the instance was terminated, costing you money.
Example: Identify volumes that have been unattached for more than 2 weeks and terminate them after confirming that they do not contain critical data.
Sample Zombie Volume Identifying Policy: This policy identifies attached but potentially unused EBS volumes and terminates them.
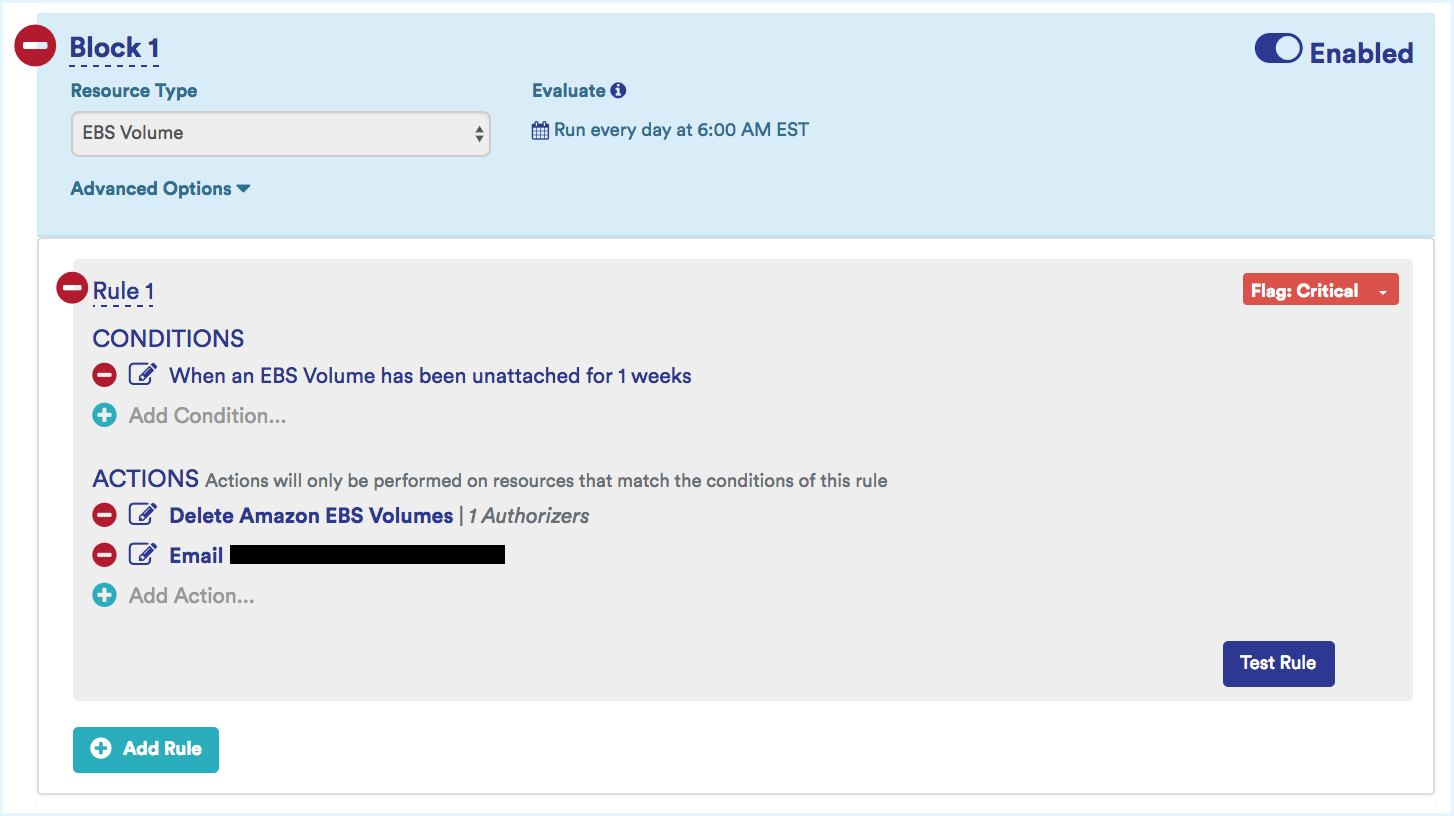
Identify and Delete Old Snapshots
These are old snapshots that have crossed a certain age threshold. Old snapshots can become a legal liability.
Example: Identify snapshots that are older than 6 months and terminate them after confirming that they do not contain critical data.
Sample old Snapshot Identifying Policy: This policy sends a notification when it identifies potential zombie EC2 snapshots that older than 6 months.
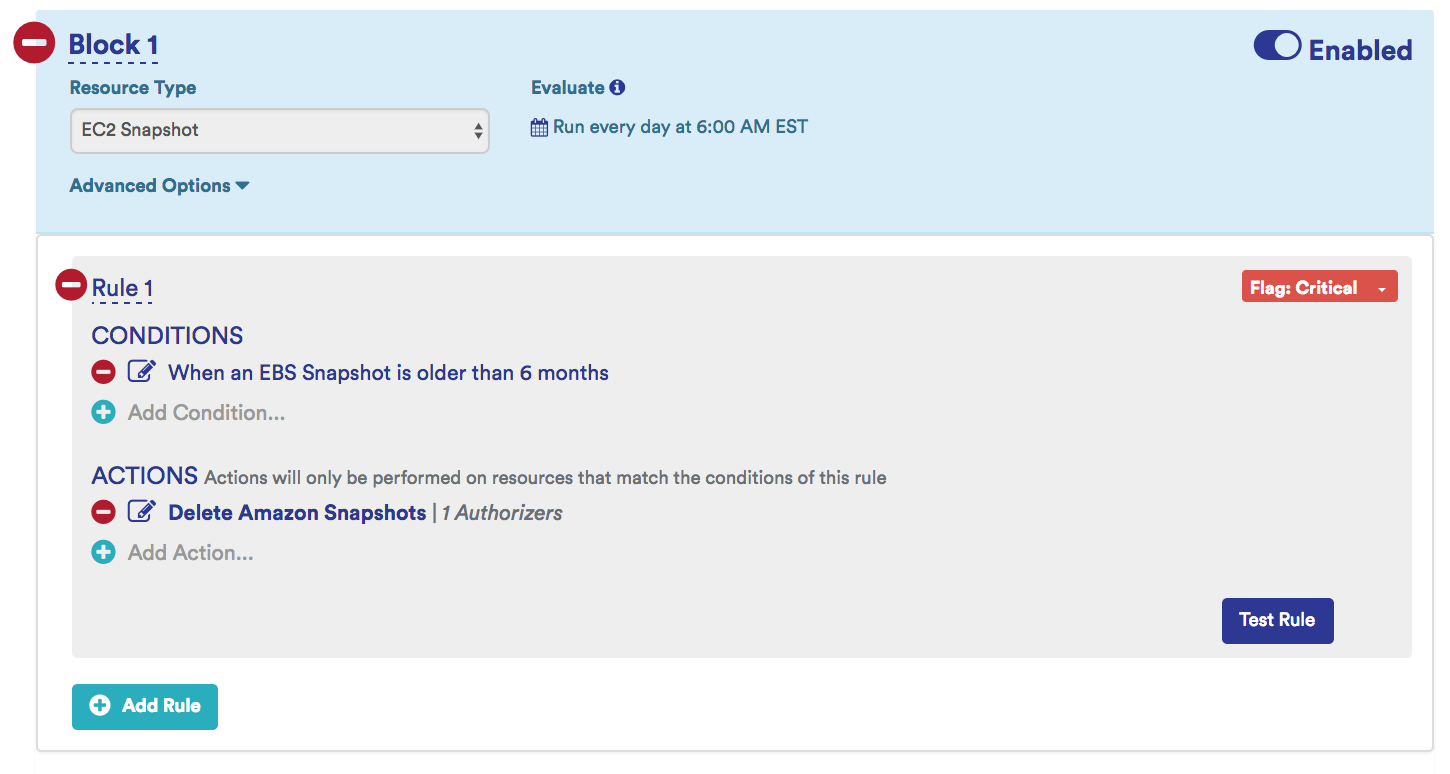
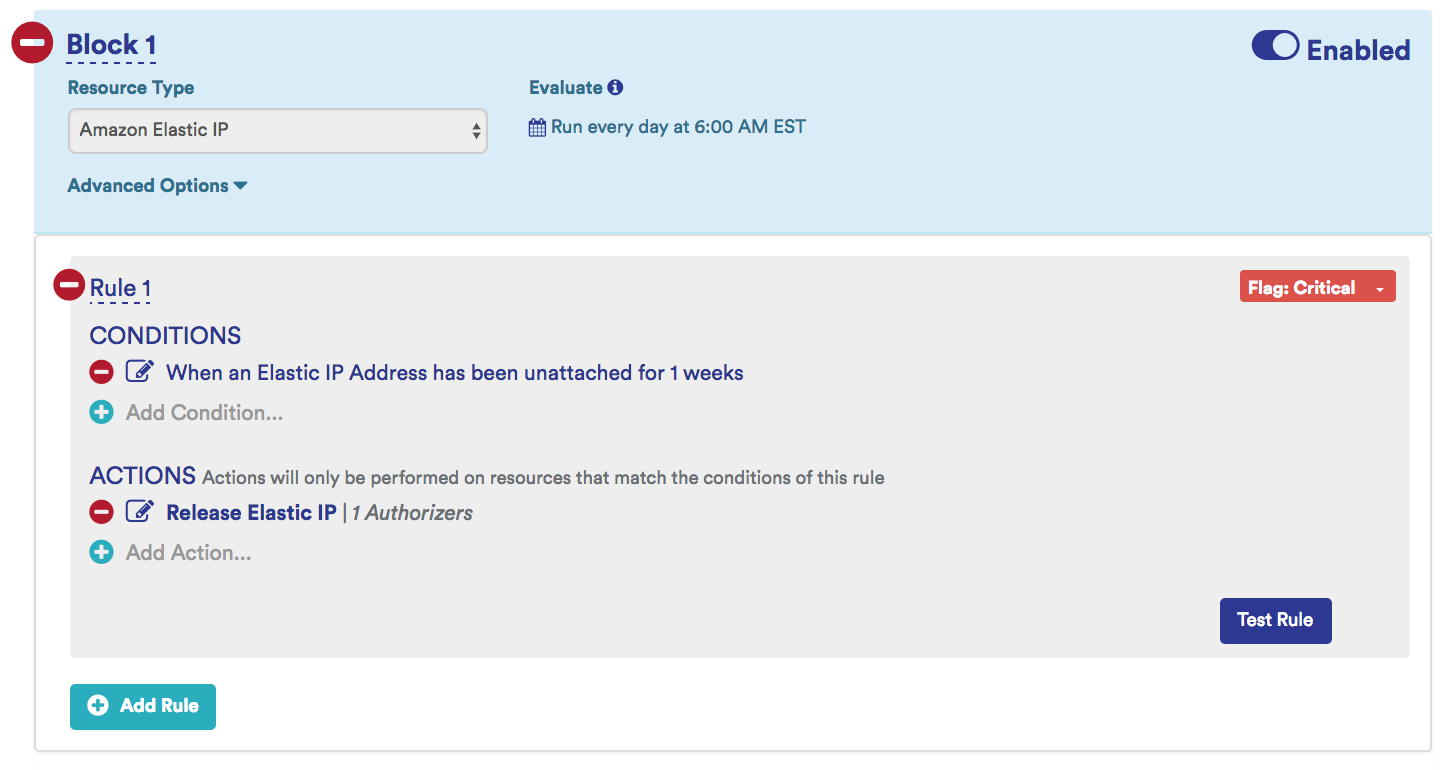
Release Disassociated Elastic IPs
Amazon charges for Elastic IPs only when they are not associated with an instance. Sometimes when instances are terminated, the Elastic IP is not released, which will result in a charge.
When setting up a policy to automatically delete Elastic IP addresses in order to avoid incurring costs, the EIP is only terminated if it is not attached to both an instance and an Elastic Network Interface, a sort of virtual adapter applied to an instance for networking purposes. A single instance can have multiple ENIs (the exact number depending on instance type and size) each with its own IPv4 EIP and private IPv4 address. These ENIs can be freely removed from instances and attached to others.
For more information, see Elastic Network Interfaces in the AWS documentation.
If an ENI is removed from one instance and not reassigned to another, it will retain its EIP. When reporting on EIPs, this “floating” EIP will appear as unattached. If an EIP is attached to an orphaned ENI, it will not incur costs like it would if it were unattached from an instance normally. However, for reporting purposes it is best to ensure that you do not have any floating ENIs or EIPs.
Example: Identify and release EIPs that are no longer associated with a running instance for more than 1 week.
Sample Release Disassociated Elastic IP Identifying Policy: This policy identifies disassociated EIPs that exist for more than 1 week and send a notification and releases them.
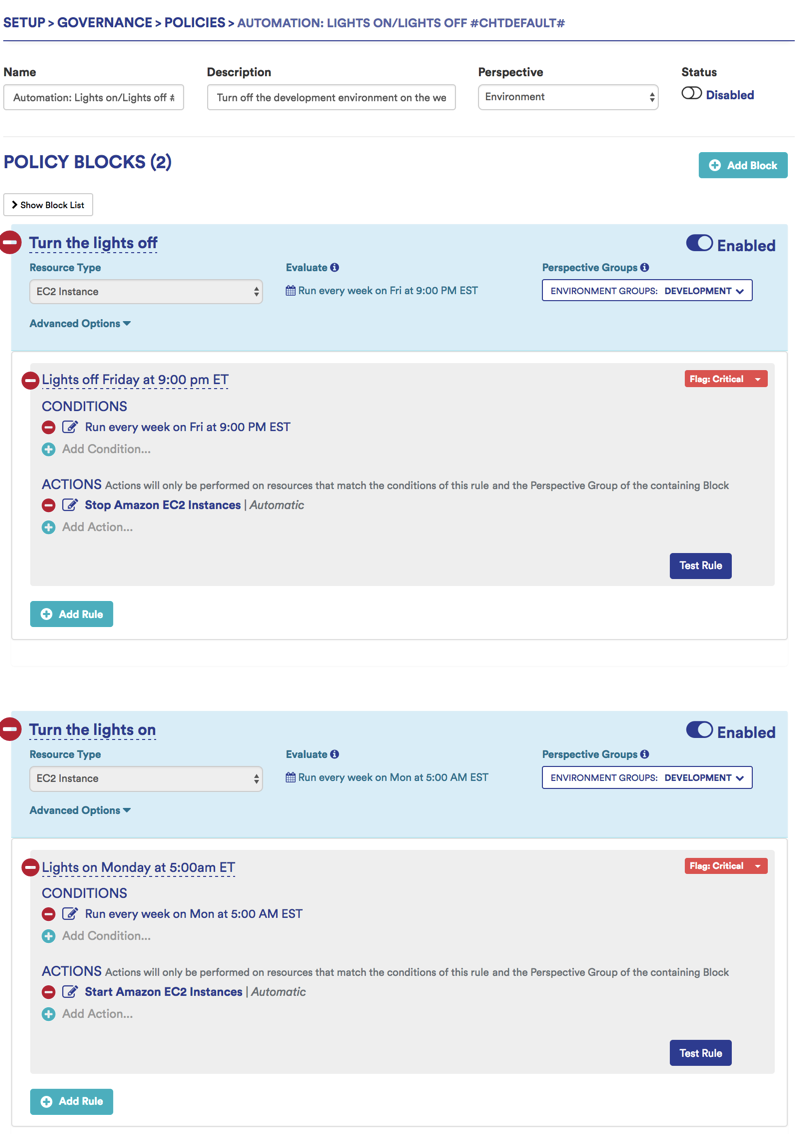
Instance Scheduling (Lights On/Lights Off)
Not all instances are in use 24x7x365, especially those outside of production. These instances can be periodically shut down to reduce cost.
Example: Stop EC2 instances in development environment at 7pm on Friday, Start deployment of EC2 instances at 6am on Monday
Sample Lights on/Lights off Policy: Turns off development environment over the weekend.
Identify Older Generation Instances
Upgrade older generation instances to the latest generation for reduced costs and improved performance.
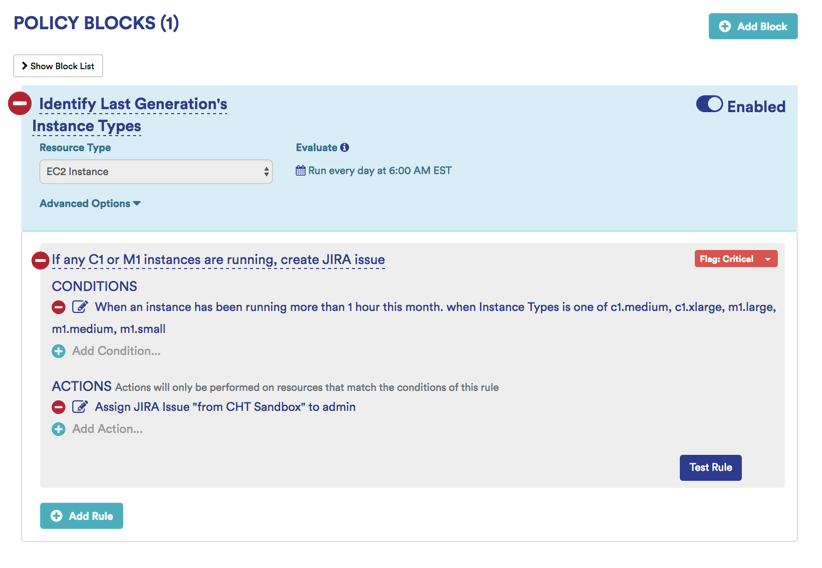
Example: Identify legacy AWS Instances (T1, M1, C1, CC2, M2, CR1, CG1, HI1, HS1) and notify owner so they can upgrade.
Identify Older Generation Instance Policy: Looks for M1 and C1 instance types with more than 1 hour of runtime in a given month, sends JIRA notification.
Performance Management
Volume Rightsizing
Examples:
- Get notified if your PIOPS storage cost changes by more than 15% over a week across your entire cloud infrastructure.
- Send a critical notification if your PIOPS storage cost changes by more than 15% over a week for your development or production group.
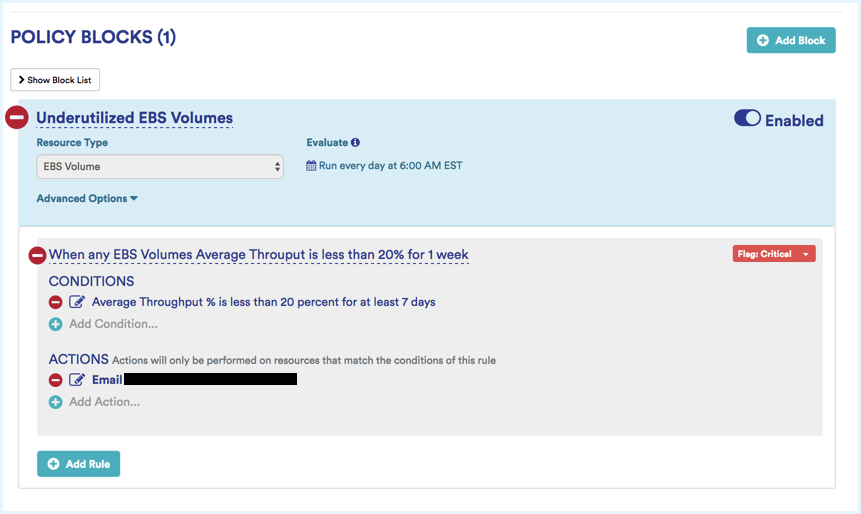
- If any volume type average weekly disk throughput is < 20%, send email notification
Sample Volume Rightsizing Policy: Notify me if the average is less than 20% across all my EBS volumes for 1 week.
EC2 Instance Rightsizing
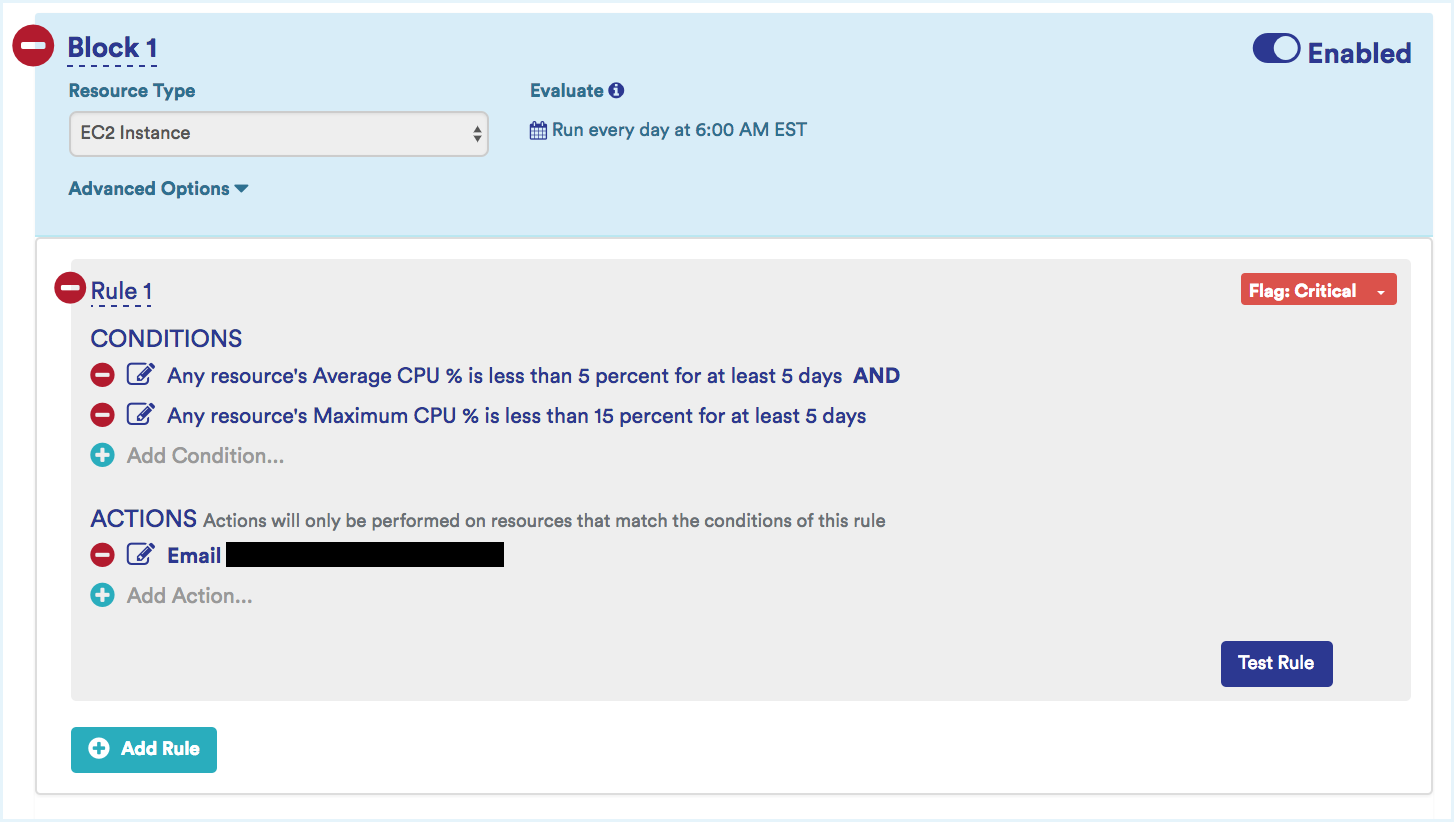
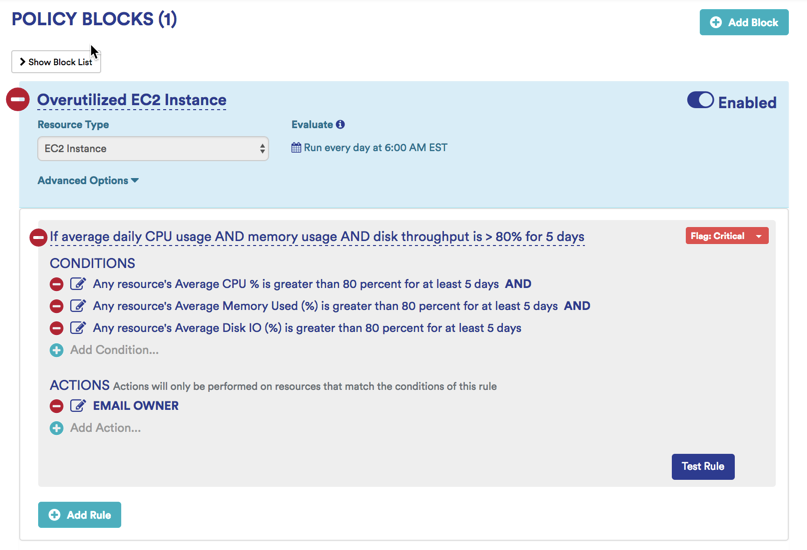
Specify performance thresholds for your instances so that you can monitor for underutilized and overutilized instances. Underutilized instances should be downgraded for cost efficiency, while overutilized instances should be upgraded to avoid performance problems.
- Underutilization Example: If average CPU is less than 20% average disk IO is less than 35%, and max CPU is less than 35% for more than 5 days, notify the instance owner.
- Overutilization Example: If daily average CPU usage AND memory usage AND disk throughput is > 80% for 5 days, then send email notification
Asset and Configuration Governance
Tag Compliance
Tagging is an essential way to accurately group assets in their appropriate business groups. Set notifications to identify assets that do not conform with the internal tagging standards defined by your organization.
Examples:
- If any asset is missing the tag Environment, send notification and execute a lambda function to tag the asset.
- If any asset is untagged, alert its owner and stop the instance
Sample Best Practice Policy: This Policy sends an email alert reporting any new AWS assets that are provisioned without being tagged.
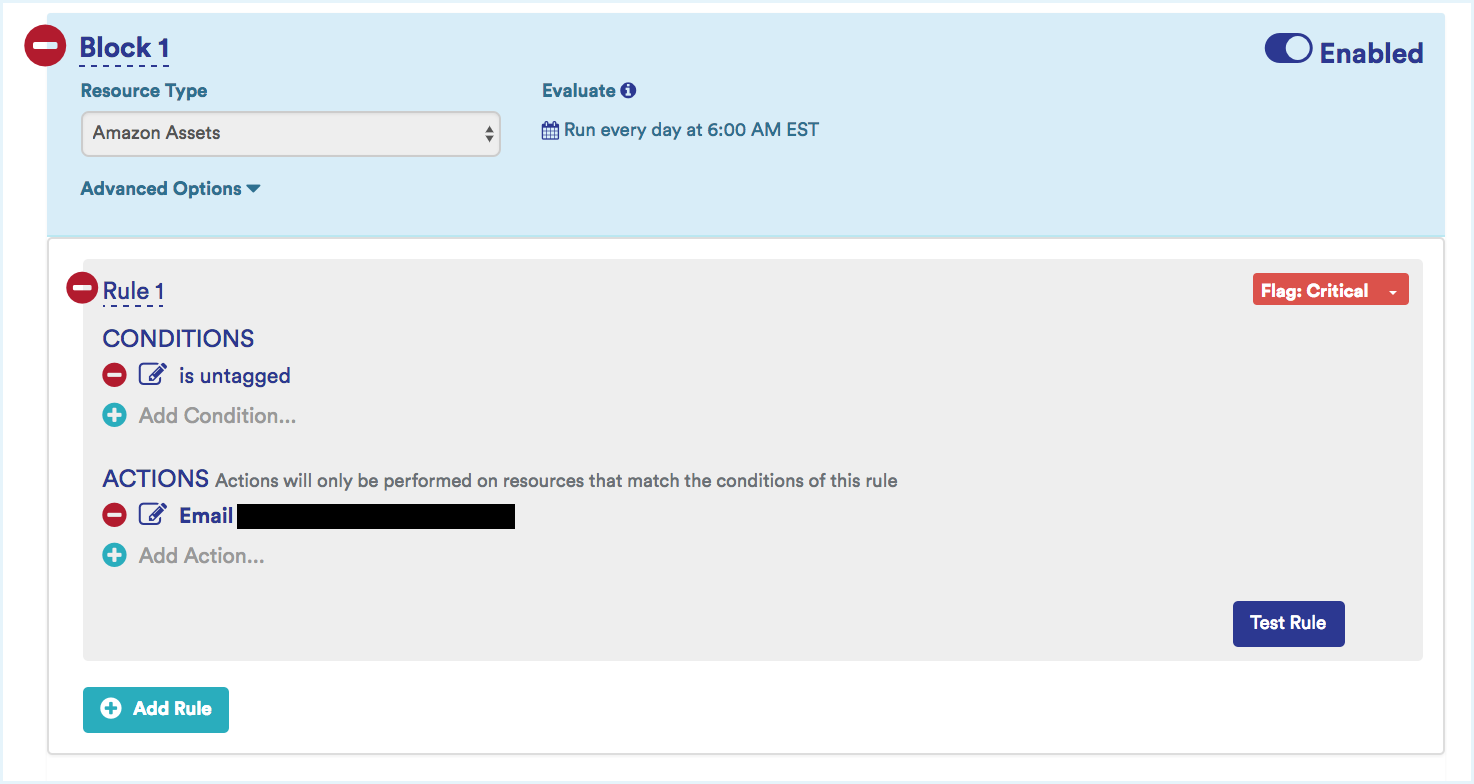
Nonconforming Assets
In any organization, there are asset types and configurations that are not-preferred, or are outright not allowed. Whether is it certain instance types, regions, AMI types, OS, or network type, it’s critical that you can quickly identify these and take action to correct them.
Examples:
- When any resource is out of compliance with a specific AWS Config Rule
- When an instance has been running more than 1 hour this month. when VPC Enabled is VPC disabled
- When an instance has been running more than 1 hour this month. when Operating System is Red Hat Enterprise Linux
Sample Best Practice Policy: This policy identifies any running EC2 instances that do not comply with AWS Config Rules.
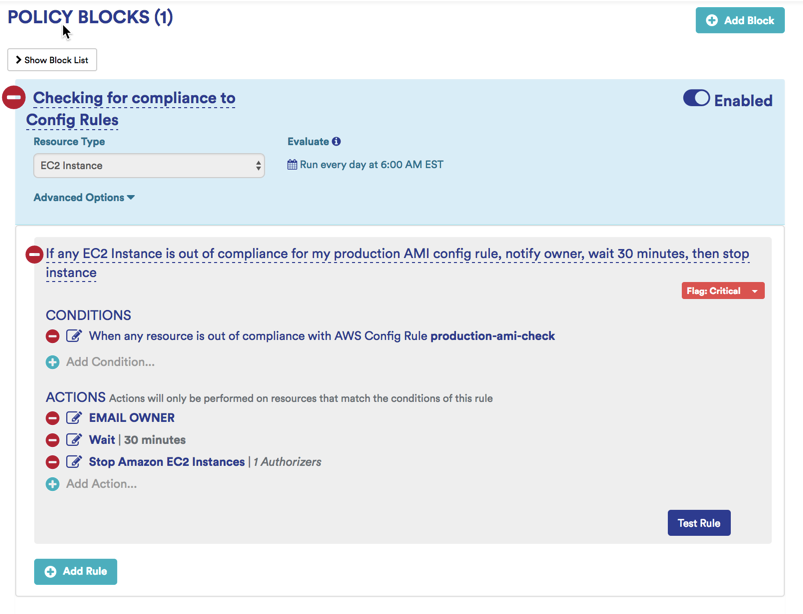
Security Management
Default Security Policy
Tanzu CloudHealth best practices for security management policies include access control policies, network security policies, application and data security policies, and audit trail policies.
Default policies for AWS Security Best Practices and the Center for Internet Security Best Practices are available in the Tanzu CloudHealth platform.
