









This topic tells you how to monitor the health of the VMware Tanzu RabbitMQ for Tanzu Application Service service using the logs, metrics, and Key Performance Indicators (KPIs) generated by Tanzu RabbitMQ for Tanzu Application Service component VMs.
NoteAs of Tanzu RabbitMQ for Tanzu Application Service v2.0,
rabbitmq_prometheusplug-in now provides RabbitMQ Server metrics. Consequently, many metric names change after upgrading to Tanzu RabbitMQ for Tanzu Application Service v2.0. Both on-demand and pre-provisioned Tanzu RabbitMQ for Tanzu Application Service are affected. For a list of the changes made in v2.0 to metric names, refer to Migrating Metrics from Tanzu RabbitMQ for Tanzu Application Service v1.x to v2.0.
Metrics
Metrics are regularly-collected log entries that report measured component states. You can either consume metrics through the Loggregator subsystem, or by configuring a Prometheus server or the Healthwatch tile. The Loggregator subsystem collects metrics automatically based on the metrics polling interval. Prometheus servers and the Healthwatch tile directly scrape the VMs deployed by Tanzu RabbitMQ for Tanzu Application Service. The RabbitMQ servers expose the same information in each case.
For a full list of all metrics exposed in pre-provisioned and on-demand service instances of Tanzu RabbitMQ for Tanzu Application Service, see the Component Metrics Reference later in this topic.
NoteAs of Tanzu RabbitMQ for Tanzu Application Service v2.0, the format of the metrics has changed. For a list of the changes to metric names in Tanzu RabbitMQ for Tanzu Application Service v2.0, refer to Migrating Metrics from Tanzu RabbitMQ for Tanzu Application Service v1.x to v2.0.
Collecting Metrics with the Loggregator System
Loggregator-collected metrics are long, single lines of text that follow the format:
origin:"p-rabbitmq" eventType:ValueMetric timestamp:1616427704616569016 deployment:"cf-rabbitmq" job:"rabbitmq-broker" index:"0" ip:"10.0.4.101" tags:<key:"instance_id" value:"d4b4fd51-50de-4227-a96f-8ce636960f0b" > tags:<key:"source_id" value:"rabbitmq-broker" > valueMetric:<name:"_p_rabbitmq_service_broker_heartbeat" value:1 unit:"boolean" >
If the prometheus plug-in is enabled, Tanzu RabbitMQ for Tanzu Application Service automatically collects these metrics and forwards them to the Loggregator system. For general information about logging and metrics in VMware Tanzu Application Service for VMs and how to consume the metrics from the Loggregator system, see Overview of Logging and Metrics.
Configure the Metrics Polling Interval
The default metrics polling interval for Loggregator is 30 seconds. The metrics polling interval is a configuration option on the Tanzu RabbitMQ for Tanzu Application Service tile (Settings > RabbitMQ). Setting this interval to -1 deactivates metrics. The interval setting applies to all components deployed by the tile.
To configure the metrics polling interval:
- From the Ops Manager Installation Dashboard, click the Tanzu RabbitMQ for Tanzu Application Service tile.
- In the Tanzu RabbitMQ for Tanzu Application Service tile, click the Settings tab.
-
Click Metrics.
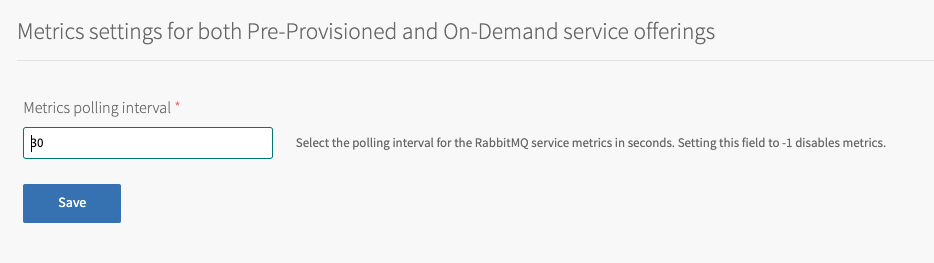
-
Configure the fields on the Metrics pane as follows:
Field Description Metrics polling interval The default setting is 30 seconds for all deployed components. VMware recommends that you do not change this interval. To avoid overwhelming components, do not set this below 10 seconds. Set this to -1 to deactivate metrics. Changing this setting affects all deployed instances. -
Click Save.
- Return to the Ops Manager Installation Dashboard.
- Click Review Pending Changes. For more information about this Ops Manager page, see Reviewing Pending Product Changes.
- Click Apply Changes to redeploy with the changes.
Gathering Additional Metrics
As of Tanzu RabbitMQ for Tanzu Application Service v2.0.11, in addition to the standard RabbitMQ server metrics gathered by Tanzu RabbitMQ for Tanzu Application Service, you can gather additional, detailed metrics for your system. For more information about the additional metrics, see rabbitmq-server in GitHub. To limit the performance impact of gathering more data, you can choose to gather additional metrics only for specific vhosts, or for only a subset of these metrics to be generated.
The process to configure additional metrics differs for the different service offerings:
-
For the on-demand offering: You configure additional metrics when creating or updating a service instance. For more information, see Collect Additional RabbitMQ Metrics in Loggregator (on-demand instances).
-
For the pre-provisioned offering: You configure additional metrics in Ops Manager. For more information, see Collect Additional RabbitMQ Metrics in Loggregator (pre-provisioned instances).
Collecting Metrics with Prometheus
Prometheus-style metrics are available at SERVICE-INSTANCE-ID:15692/metrics. To pull these metrics from the service instances, you must deploy and configure a Prometheus instance. For more information about the plug-in and monitoring RabbitMQ using Prometheus and Grafana, see the RabbitMQ documentation.
The following Prometheus scrape config dynamically discovers RabbitMQ instances:
job_name: rabbitmq
metrics_path: "/metrics"
scheme: http
dns_sd_configs:
- names:
- q-s4.rabbitmq-server.*.*.bosh.
type: A
port: 15692
NoteIf you are using TLS in the on-demand service offering, your port will be
15691.
The regular expression in the scrape config name ensures that Prometheus discovers all future service instances too.
If Prometheus is deployed with the Healthwatch v2 tile, then the above configuration is automatically applied.
NoteBy default, metrics are aggregated. This results in a lower performance overhead at the cost of lower data fidelity. For more information, refer to RabbitMQ documentation.
Scrape Per-object Metrics
To collect metrics on a per-object scope, such as per-queue, do one of the following:
-
Enable per-object metrics by setting
prometheus.return_per_object_metrics = true. For instructions, see Expert Mode: Overriding RabbitMQ Server Configuration -
Scrape the dedicated per-object metrics endpoint, for example:
job_name: rabbitmq metrics_path: "/metrics/per-object" scheme: http dns_sd_configs: - names: - q-s4.rabbitmq-server.*.*.bosh. type: A port: 15692Note
Collecting per-object metrics on a system with many objects, such as queues or connections, is very slow. Ensure you understand the impact on your system and its load before enabling this on a production cluster.
Filter the Per-object Metrics
As of Tanzu RabbitMQ for Tanzu Application Service v2.0.7, you can collect only the per-object metrics for certain scopes of metrics. This decreases the performance overhead, while retaining data fidelity for metrics that you are interested in. For more information, see Selective querying of per-object metrics.
For example, the following scrape config collects only the per-object metrics that allow you to see how many messages sit in every queue and how many consumers each of these queues have:
job_name: rabbitmq
metrics_path: "/metrics/detailed?family=queue_coarse_metrics&family=queue_consumer_count"
scheme: http
dns_sd_configs:
- names:
- q-s4.rabbitmq-server.*.*.bosh.
type: A
port: 15692
Grafana Dashboards
The RabbitMQ team has written dashboards that you can import into Grafana. These dashboards include documentation for each metric.
-
RabbitMQ-Overview: Dashboard for an overview of the RabbitMQ system
-
Erlang-Distribution: Dashboard for the underlying Erlang distribution
For more information about these dashboards, see the RabbitMQ documentation. If Grafana is deployed using the Healthwatch v2 tile, you can load these dashboards by selecting the Enable RabbitMQ dashboards checkbox in the Healthwatch tile.
Component Heartbeats
Some components periodically emit Boolean heartbeat metrics to the Loggregator system. 1 means the system is available, and 0 or the absence of a heartbeat metric means the service is not responding and you must investigate the issue.
Service Broker Heartbeat
_p_rabbitmq_service_broker_heartbeat |
|
|---|---|
| Description | RabbitMQ service broker is alive poll that indicates if the component is available and can respond to requests. Use: If the service broker does not emit heartbeats, this indicates that it is offline. The service broker is required to create, update, and delete service instances, which are critical for dependent tiles such as Spring Cloud Services and Spring Cloud Data Flow. Origin: Doppler/Firehose Type: Boolean Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 5 minutes |
| Recommended alert thresholds | Yellow warning: N/A Red critical: < 1 |
| Recommended response | Search the RabbitMQ service broker logs for errors. You can find this VM by targeting your Tanzu RabbitMQ for Tanzu Application Service deployment with BOSH, and running one of these commands:
|
HAProxy Heartbeat
NoteThe HAProxy is only used in the pre-provisioned service offering, so HAProxy heartbeats are only present if this service offering is enabled.
_p_rabbitmq_haproxy_heartbeat |
|
|---|---|
| Description | RabbitMQ HAProxy is alive poll, which indicates if the component is available can respond to requests. Use: If the HAProxy does not emit heartbeats, this indicates that it is offline. To be functional, pre-provisioned service instances require HAProxy. Origin: Doppler/Firehose Type: Boolean Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 5 minutes |
| Recommended alert thresholds | Yellow warning: N/A Red critical: < 1 |
| Recommended response | Search the RabbitMQ HAProxy logs for errors. You can find the VM by targeting your Tanzu RabbitMQ for Tanzu Application Service deployment with BOSH and running the following command, which lists HAProxy_GUID: bosh -d service-instance_GUID vms |
Key Performance Indicators
The following sections describe the metrics used as Key Performance Indicators (KPIs) and other useful metrics for monitoring the Tanzu RabbitMQ for Tanzu Application Service service.
KPIs for Tanzu RabbitMQ for Tanzu Application Service are metrics that operators find most useful for monitoring their Tanzu RabbitMQ for Tanzu Application Service service to ensure smooth operation. KPIs are high-signal-value metrics that can indicate emerging issues. KPIs can be raw component metrics or derived metrics generated by applying formulas to raw metrics.
VMware provides the following KPIs as general alerting and response guidance for typical Tanzu RabbitMQ for Tanzu Application Service installations. VMware recommends the following to operators:
- Continue to fine-tune the alert measures to your installation by observing historical trends.
- Expand beyond the guidance and create new, installation-specific monitoring metrics, thresholds, and alerts based on learning from your own installation.
For a list of all Tanzu RabbitMQ for Tanzu Application Service raw component metrics, see Component Metrics Reference later in this topic.
Component Heartbeats
If collecting metrics using Loggregator, several components in Tanzu RabbitMQ for Tanzu Application Service emit heartbeat metrics. For more information, see Component Heartbeats earlier in this topic.
RabbitMQ Server File Descriptors
rabbitmq_process_open_fds |
|
|---|---|
| Description | The number of file descriptors consumed. **Use**: If the number of file descriptors consumed becomes too large, the VM might lose the ability to perform disk I/O, which can cause data loss. >**Note** >nonpersistent messages are handled by retries or some other logic by the producers. **Origin**: Doppler/Firehose **Type**: Count **Frequency**: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 10 minutes |
| Recommended alert thresholds | **Yellow warning**: > 250000 **Red critical**: > 280000 |
| Recommended response | The default `ulimit` for Tanzu RabbitMQ for Tanzu Application Service is 300,000. If this metric meets or exceeds the recommended thresholds for extended periods of time, consider reducing the load on the server. |
Erlang Processes
erlang_vm_process_count |
|
|---|---|
| Description | The number of Erlang processes that RabbitMQ consumes. RabbitMQ runs on an Erlang VM. For more information, see the Erlang Documentation. Use: This is the key indicator of the processing capability of a node. Origin: Doppler/Firehose Type: Count Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 10 minutes |
| Recommended alert thresholds | Yellow warning: > 900000 Red critical: > 950000 |
| Recommended response | The default Erlang process limit in Tanzu RabbitMQ for Tanzu Application Service v1.6 and later is 1,048,816. If this metric meets or exceeds the recommended thresholds for extended periods of time, consider scaling the RabbitMQ nodes in the tile Resource Config pane. |
BOSH System Health Metrics
The BOSH layer that underlies Ops Manager generates healthmonitor metrics for all VMs in the deployment. As of Ops Manager v2.0, these metrics are in the Loggregator Firehose by default. For more information, see BOSH System Metrics Available in Loggregator Firehose in VMware Tanzu Application Service for VMs Release Notes.
All BOSH-deployed components generate the system health metrics listed in this section. These component metrics are from Tanzu RabbitMQ for Tanzu Application Service components, and serve as KPIs for the Tanzu RabbitMQ for Tanzu Application Service service.
RAM
system_mem_percent |
|
|---|---|
| Description | RAM being consumed by the p.rabbitmq VM. Use: RabbitMQ is considered to be in a good state when it has few or no messages. In other words, "an empty rabbit is a happy rabbit." Alerting on this metric can indicate that there are too few consumers or apps that read messages from the queue. Healthmonitor reports when RabbitMQ uses more than 40% of its RAM for the past ten minutes. Origin: BOSH HM Type: Percent Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 10 minutes |
| Recommended alert thresholds | Yellow warning: > 40 Red critical: > 50 |
| Recommended response | Add more consumers to drain the queue as fast as possible. |
CPU
system_cpu_user |
|
|---|---|
| Description | CPU being consumed by user processes on the p.rabbitmq VM.Use: A node that experiences context switching or high CPU usage becomes unresponsive. This also affects the ability of the node to report metrics. Healthmonitor reports when RabbitMQ uses more than 40% of its CPU for the past ten minutes. Origin: BOSH HM Type: Percent Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 10 minutes |
| Recommended alert thresholds | Yellow warning: > 60 Red critical: > 75 |
| Recommended response | Remember that "an empty rabbit is a happy rabbit". Add more consumers to drain the queue as fast as possible. |
Ephemeral Disk
system_disk_ephemeral_percent |
|
|---|---|
| Description | Ephemeral Disk being consumed by the p.rabbitmq VM. Use: If system disk fills up, there are too few consumers. Healthmonitor reports when RabbitMQ uses more than 50% of its Ephemeral Disk for the past ten minutes. Origin: BOSH HM Type: Percent Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 10 minutes |
| Recommended alert thresholds | Yellow warning: > 50 Red critical: > 75 |
| Recommended response | Remember that "an empty rabbit is a happy rabbit". Add more consumers to drain the queue as fast as possible. Insufficient disk space leads to node failures and might result in data loss due to all disk writes failing. |
Persistent Disk
system_disk_persistent_percent |
|
|---|---|
| Description | Persistent Disk being consumed by the p.rabbitmq VM.Use: If system disk fills up, there are too few consumers. Healthmonitor reports when RabbitMQ uses more than 50% of its Persistent Disk. Origin: BOSH HM Type: percent Frequency: 30 seconds (default), 10 seconds (configurable minimum) |
| Recommended measurement | Average over last 10 minutes |
| Recommended alert thresholds | Yellow warning: > 50 Red critical: > 75 |
| Recommended response | Remember that "an empty rabbit is a happy rabbit". Add more consumers to drain the queue as fast as possible. Insufficient disk space leads to node failures and might result in data loss due to all disk writes failing. |
Logging
You can configure Tanzu RabbitMQ for Tanzu Application Service to forward logs to an external syslog server, and customise the format of the logs output.
Configure Syslog Forwarding
Syslog forwarding is preconfigured and enabled by default. VMware recommends that you keep the default setting because it is good operational practice. However, you can opt out by selecting No for Do you want to configure syslog? in the Ops Manager Settings tab.
To enable monitoring for Tanzu RabbitMQ for Tanzu Application Service, operators designate an external syslog endpoint for Tanzu RabbitMQ for Tanzu Application Service component log entries. The endpoint serves as the input to a monitoring platform such as Datadog, Papertrail, or SumoLogic.
To specify the destination for Tanzu RabbitMQ for Tanzu Application Service log entries:
- From the Ops Manager Installation Dashboard, click the Tanzu RabbitMQ for Tanzu Application Service tile.
- In the Tanzu RabbitMQ for Tanzu Application Service tile, click the Settings tab.
-
Click Syslog.
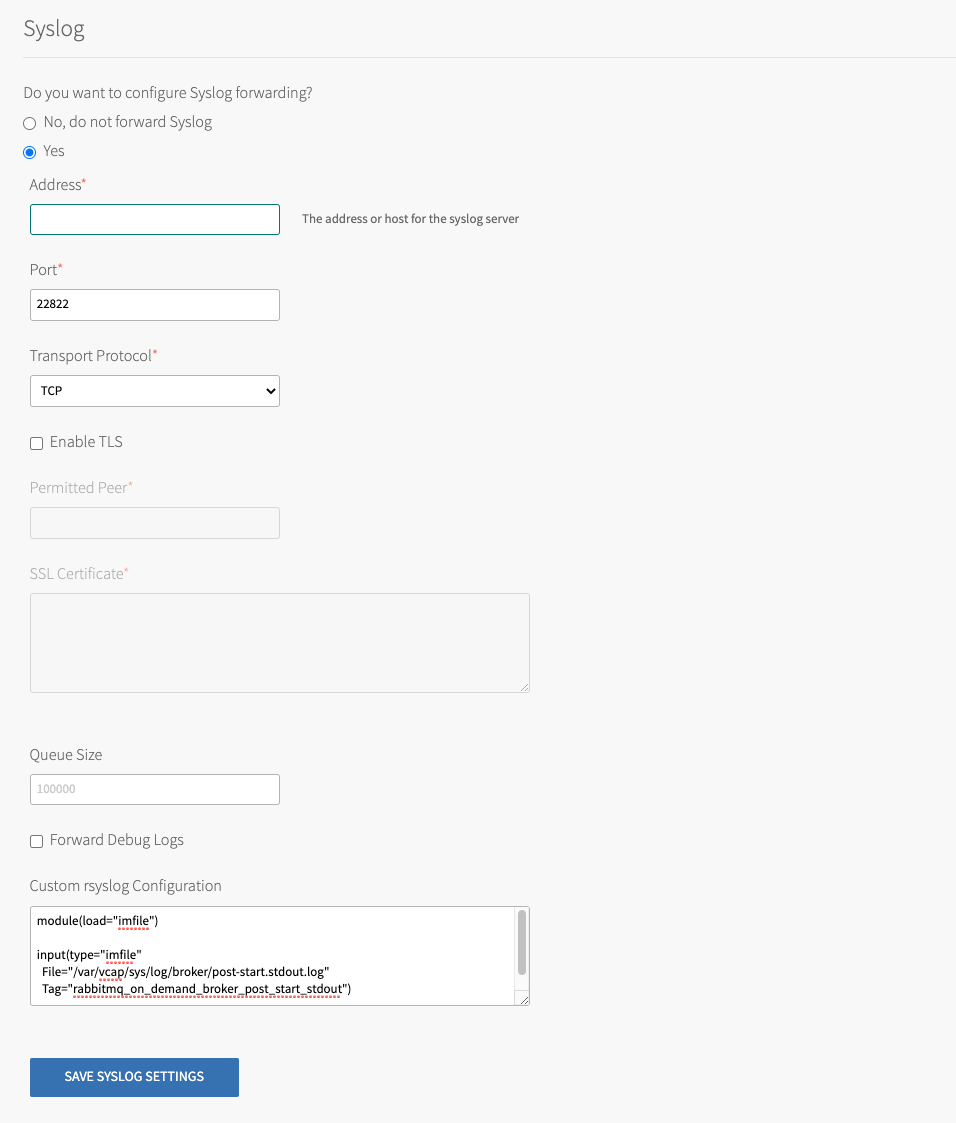
-
Configure the fields on the Syslog pane as follows:
Field Description Syslog Address Enter the IP or DNS address of the syslog server Syslog Port Enter the port of the syslog server Transport Protocol Select the transport protocol of the syslog server. The options are TLS, UDP, or RELP. Enable TLS Enable TLS to the syslog server. Permitted Peer If there are several peer servers that can respond to remote syslog connections, enter a wildcard in the domain, such as *.example.com.SSL Certificate If the server certificate is not signed by a known authority, such as an internal syslog server, enter the CA certificate of the log management service endpoint. Queue Size The number of log entries the buffer holds before dropping messages. A larger buffer size might overload the system. The default is 100000. Forward Debug Logs Some components produce very long debug logs. This option prevents them from being forwarded. These logs are still written to local disk. Custom Rules The custom rsyslog rules are written in RainerScript and are inserted before the rule that forwards logs. For the list of custom rules you can add in this field, see RabbitMQ Syslog Custom Rules later in this topic. For more information about the program names you can use in the custom rules, see RabbitMQ Program Names later in this topic. -
Click Save.
- Return to the Ops Manager Installation Dashboard.
- Click Review Pending Changes. For more information about this Ops Manager page, see Reviewing Pending Product Changes.
- Click Apply Changes to redeploy with the changes.
Logging Format
With Tanzu RabbitMQ for Tanzu Application Service logging configured, several types of components generate logs: the RabbitMQ message server nodes, the service brokers, and (if present) HAProxy.
-
The logs for RabbitMQ server nodes follow the format:
[job:"rabbitmq-server" ip:"192.0.2.0"] -
The logs for the pre-provisioned RabbitMQ service broker follow the format:
[job:"rabbitmq-broker" ip:"192.0.2.1"] -
The logs for the on-demand RabbitMQ service broker follow the format:
[job:"on-demand-broker" ip:"192.0.2.2"] -
The logs for HAProxy nodes follow the format:
[job:"rabbitmq-haproxy" ip:"192.0.2.3"]
RabbitMQ and HAProxy servers log at the info level and capture errors, warnings, and informational messages.
For users familiar with documentation for previous versions of the tile, the tag formerly called the app_name is now called the program_name.
The generic log format is as follows:
<PRI>TIMESTAMP IP_ADDRESS PROGRAM_NAME [job=NAME index=JOB_INDEX id=JOB_ID] MESSAGE
The raw logs look similar to the following:
<7>2017-06-28T16:06:10.733560+00:00 10.244.16.133 vcap.agent [job=rmq index=0 id=e37ecdca-5b10-4141-abd8-e1d777dfd8b5] 2017/06/28 16:06:10 CEF:0|CloudFoundry|BOSH|1|agent_api|ssh|1|duser=director.be5a66bb-a9b4-459f-a0d3-1fc5c9c3ed79.be148cc6-91ef-4eed-a788-237b0b8c63b7 src=10.254.50.4 spt=4222 shost=5ae233e0-ecc5-4868-9ae0-f9767571251b
<86>2017-06-28T16:06:16.704572+00:00 10.244.16.133 useradd [job=rmq index=0 id=e37ecdca-5b10-4141-abd8-e1d777dfd8b5] new group: name=bosh_ly0d2rbjr, GID=1003
<86>2017-06-28T16:06:16.704663+00:00 10.244.16.133 useradd [job=rmq index=0 id=e37ecdca-5b10-4141-abd8-e1d777dfd8b5] new user: name=bosh_ly0d2rbjr, UID=1001, GID=1003, home=/var/vcap/bosh_ssh/bosh_ly0d2rbjr, shell=/bin/bash
<86>2017-06-28T16:06:16.736932+00:00 10.244.16.133 usermod [job=rmq index=0 id=e37ecdca-5b10-4141-abd8-e1d777dfd8b5] add 'bosh_ly0d2rbjr' to group 'admin'
<86>2017-06-28T16:06:16.736964+00:00 10.244.16.133 usermod [job=rmq index=0 id=e37ecdca-5b10-4141-abd8-e1d777dfd8b5] add 'bosh_ly0d2rbjr' to group 'vcap'
Logs sent to external logging tools such as Papertrail might be presented in a different format.
The following table describes the logging tags used in this template:
| Tag | Description |
|---|---|
| PRI | This is a value which, in future, will be used to describe the severity of the log entry and which facility it came from. |
| TIMESTAMP | This is the timestamp of when the log is forwarded, for example, 2016-08-24T05:14:15.000003Z. The timestamp value is typically slightly after when the log entry was generated. |
| IP_ADDRESS | The internal IP address of server on which the log entry originated |
| PROGRAM_NAME | Process name of the program the generated the message. Same as app_name before v1.9.0. For more information about program name, see RabbitMQ Program Names below. |
| NAME | The BOSH instance group name (for example, rabbitmq_server) |
| JOB_INDEX | BOSH job index. Used to distinguish between multiple instances of the same job. |
| JOB_ID | BOSH VM GUID. This is distinct from the CID displayed in the Ops Manager Status tab, which corresponds to the VM ID assigned by the infrastructure provider. |
| MESSAGE | The log entry that appears |
RabbitMQ Program Names
For new service instances created using Tanzu RabbitMQ for Tanzu Application Service v1.20 and later, the default program name is rabbitmq-server. Existing service instances, including instances upgraded from Tanzu RabbitMQ for Tanzu Application Service v1.19 and earlier, have the program names listed in the table below.
If you want new service instances to keep the program names that are in Tanzu RabbitMQ for Tanzu Application Service v1.19 and earlier, you must manually add custom rules. For the custom rules to add, see Add RabbitMQ Syslog custom rules.
The following table lists the program names you can make available for use in the logs:
| Program Name | Description |
|---|---|
| rabbitmq_server_cluster_check | Checks that the RabbitMQ cluster is healthy. Runs after every deploy |
| rabbitmq_server_node_check | Checks that the RabbitMQ node is healthy. Runs after every deploy |
| rabbitmq_route_registrar_stderr | Registers the route for the management API with the Gorouter in your VMware Tanzu Application Service for VMs deployment |
| rabbitmq_route_registrar_stdout | Registers the route for the management API with the Gorouter in your VMware Tanzu Application Service for VMs deployment |
| rabbitmq_server | The Erlang VM and RabbitMQ apps. Logs can span multiple lines. |
| rabbitmq_server_drain | Shuts down the Erlang VM and RabbitMQ apps. Runs as part of the BOSH lifecycle |
| rabbitmq_server_http_api_access | Access to the RabbitMQ Management UI |
| rabbitmq_server_init | Starts the Erlang VM and RabbitMQ |
| rabbitmq_server_post_deploy_stderr | Runs the node check and cluster check. Runs after every deploy |
| rabbitmq_server_post_deploy_stdout | Runs the node check and cluster check. Runs after every deploy |
| rabbitmq_server_pre_start | Runs before the rabbitmq-server job is started |
| rabbitmq_server_sasl | Supervisor, progress, and crash reporting for the Erlang VM and RabbitMQ apps |
| rabbitmq_server_shutdown_stderr | Stops the RabbitMQ app and Erlang VM. |
| rabbitmq_server_shutdown_stdout | Stops the RabbitMQ app and Erlang VM |
| rabbitmq_server_startup_stderr | Starts the RabbitMQ app and Erlang VM, then configures users and permissions |
| rabbitmq_server_startup_stdout | Starts the RabbitMQ app and Erlang VM, then configures users and permissions |
| rabbitmq_server_upgrade | Shuts down Erlang VM and RabbitMQ app if required during an upgrade |
Add RabbitMQ syslog Custom Rules
Tanzu RabbitMQ for Tanzu Application Service syslog configuration is now managed by Ops Manager. For new services instances, to continue to filter logs in the same way as Tanzu RabbitMQ for Tanzu Application Service v1.19 and earlier, you must manually add custom rules. This retains the program names.
The custom rsyslog rules are written in RainerScript. You can add a subset of the following rules depending on how you want to filter the logs. For more information, see the RainerScript documentation.
To add custom rules that keep the same program names as in Tanzu RabbitMQ for Tanzu Application Service v1.19 and earlier:
-
Add the following rules to the Custom Syslog Configuration field in the Syslog pane:
module(load="imfile") input(type="imfile" File="/var/vcap/sys/log/broker/post-start.stdout.log" Tag="rabbitmq_on_demand_broker_post_start_stdout") input(type="imfile" File="/var/vcap/sys/log/broker/post-start.stderr.log" Tag="rabbitmq_on_demand_broker_post_start_stderr") input(type="imfile" File="/var/vcap/sys/log/broker/broker.log" Tag="rabbitmq_on_demand_broker") input(type="imfile" File="/var/vcap/sys/log/broker/broker-ctl.log" Tag="rabbitmq_on_demand_broker_ctl") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-service-broker/broker_stdout.log" Tag="rabbitmq_broker_startup_stdout") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-service-broker/broker_stderr.log" Tag="rabbitmq_broker_startup_stderr") input(type="imfile" File="/var/vcap/sys/log/route_registrar/route_registrar.log" Tag="rabbitmq_broker_route_registrar_stdout") input(type="imfile" File="/var/vcap/sys/log/route_registrar/route_registrar.err.log" Tag="rabbitmq_broker_route_registrar_stderr") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-haproxy/haproxy.log" Tag="rabbitmq_haproxy") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-haproxy/pre-start.stderr.log" Tag="rabbitmq_haproxy_pre_start_stderr") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-haproxy/pre-start.stdout.log" Tag="rabbitmq_haproxy_pre_start_stdout") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-haproxy/startup_stderr.log" Tag="rabbitmq_haproxy_pre_startup_stderr") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-haproxy/startup_stdout.log" Tag="rabbitmq_haproxy_pre_startup_stdout") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/rabbit@*-sasl.log" Tag="rabbitmq_server_sasl") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/rabbit@*.log" Tag="rabbitmq_server") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/startup_stderr.log" Tag="rabbitmq_server_startup_stderr") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/startup_stdout.log" Tag="rabbitmq_server_startup_stdout") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/shutdown_stdout.log" Tag="rabbitmq_server_shutdown_stdout") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/shutdown_stderr.log" Tag="rabbitmq_server_shutdown_stderr") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/management-ui/access.log*" Tag="rabbitmq_server_http_api_access") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/upgrade.log" Tag="rabbitmq_server_upgrade") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/init.log" Tag="rabbitmq_server_init") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/node-check.log" Tag="rabbitmq_server_node_check") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/cluster-check.log" Tag="rabbitmq_server_cluster_check") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/post-deploy.stderr.log" Tag="rabbitmq_server_post_deploy_stderr") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/post-deploy.stdout.log" Tag="rabbitmq_server_post_deploy_stdout") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/drain.log" Tag="rabbitmq_server_drain") input(type="imfile" File="/var/vcap/sys/log/rabbitmq-server/pre-start.log" Tag="rabbitmq_server_pre_start") input(type="imfile" File="/var/vcap/sys/log/route_registrar/route_registrar.log" Tag="rabbitmq_route_registrar_stdout") input(type="imfile" File="/var/vcap/sys/log/route_registrar/route_registrar.err.log" Tag="rabbitmq_route_registrar_stderr")
Component Metrics Reference
Tanzu RabbitMQ for Tanzu Application Service component VMs emit the following raw metrics.
NoteAs of Tanzu RabbitMQ for Tanzu Application Service v2.0, the format of the metrics has changed. For a list of the changes to metric names in Tanzu RabbitMQ for Tanzu Application Service v2.0, refer to Migrating Metrics from Tanzu RabbitMQ for Tanzu Application Service v1.x to v2.0.
RabbitMQ Server Metrics
RabbitMQ server metrics are emitted by the rabbitmq_prometheus plug-in. The list of metrics provided is extensive, and allows full observability of your messages, VM health, and more.
For the full list of metrics emitted, see the rabbitmq-server repository in GitHub.
HAProxy Metrics (Pre-provisioned Only)
Tanzu RabbitMQ for Tanzu Application Service HAProxy components emit the following metrics.
| Name Space | Unit | Description |
|---|---|---|
_p_rabbitmq_haproxy_heartbeat |
Boolean | Indicates whether the RabbitMQ HAProxy component is available and can respond to requests |
_p_rabbitmq_haproxy_health_connections |
Count | The total number of concurrent front-end connections to the server |
_p_rabbitmq_haproxy_backend_qsize_amqp |
Size | The total size of the AMQP queue on the server |
_p_rabbitmq_haproxy_backend_retries_amqp |
Count | The number of AMQP retries to the server |
_p_rabbitmq_haproxy_backend_ctime_amqp |
Time | The total time to establish the TCP AMQP connection to the server |
On-Demand Broker Metrics
The Tanzu RabbitMQ for Tanzu Application Service on-demand broker emits the following metrics.
| Name Space | Unit | Description |
|---|---|---|
_on_demand_broker_p_rabbitmq_quota_remaining |
Count | The total quota for on-demand service instances set for this broker |
_on_demand_broker_p_rabbitmq_total_instances |
Count | The total count of on-demand service instances created by this broker |
_on_demand_broker_p_rabbitmq_{PLAN_NAME}_quota_remaining |
Count | The total quota for on-demand service instances set for this broker for a specific plan |
_on_demand_broker_p_rabbitmq_{PLAN_NAME}_total_instances |
Count | The total count of on-demand service instances created by this broker for a specific plan |
