









What if you don't know the minimum or maximum service instances that your application should be running between? You can use Tanzu Service Mesh Service Autoscaler to test an application’s operating range. You can use Tanzu Service Mesh Service Autoscaler as a tool to determine the behavior of new services that have been deployed.
By implementing the autoscaler in a test environment while the load on the services is varied, the autoscaler in performance mode can recommend how many instances of a service are needed to meet the highest levels of demand.
In efficiency mode, the autoscaler can observe the minimum instances of services for times of lower demand. In addition, efficiency mode can help save resources in a testing environment by having apps that are not being tested scaled to their minimum number of instances.
You can select various metrics for scaling to observe their importance in making scaling decisions and to assess how well services respond to quickly changing demand levels. With Tanzu Service Mesh Service Autoscaler as a testing tool, you can prepare for production readiness.
Use Case 2 Examples
The following two screenshots show how you can use the Tanzu Service Mesh Service Autoscaler to learn more about a new application.
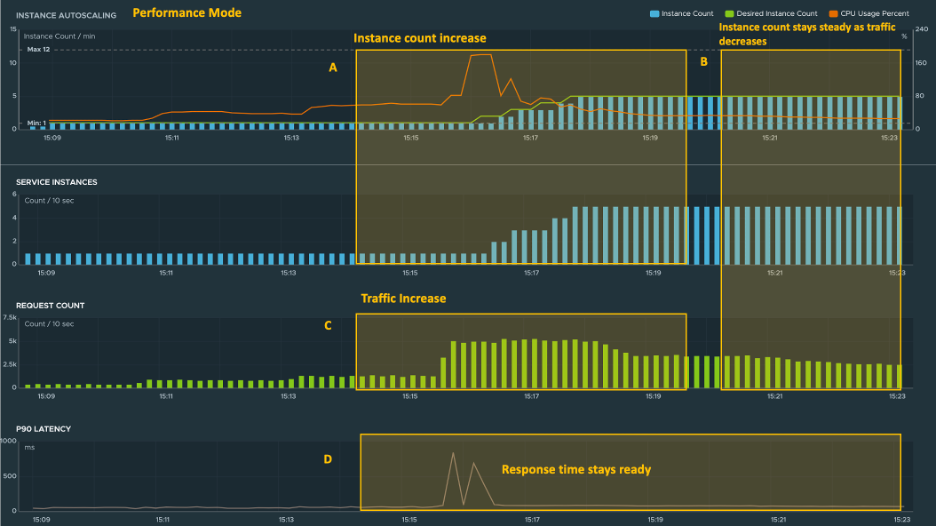
This screenshot is an example of the autoscaler in performance mode. The autoscaler sets the number of service instances to a level that is necessary (A) to handle the increasing level of traffic (C). Despite changing traffic levels, the p90 latencies remain steady (D). Because the autoscaler is in performance mode, the number of service instances does not return to the lower count (B) even as traffic decreases (B). You can use performance mode to gauge what resources are required during times of the highest demand.
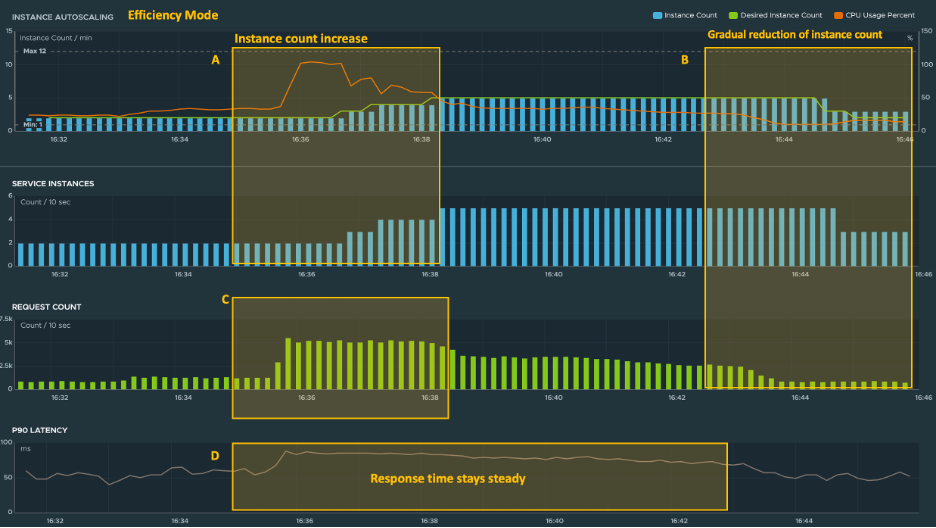
This screenshot is an example of the autoscaler in efficiency mode. Here the autoscaler sets the number of service instances to a level that is necessary to handle the current traffic to the application and avoid overprovisioning of resources. The service instance count increases (A) when the number of requests increase (C). Service instances gradually decrease as traffic to the app decreases (B). Because the autoscaler adjusts the service instances to a level that can handle the traffic, p90 latency can remain steady (D). You can use efficiency mode to gauge the range of resources required to handle the various levels of demand expected of the application.
