









This section lists the default CAAS, CNF, and Third-Party workflows available in Workflow Hub. CAAS and CNF related workflows have been developed for TCA 2.3 feature parity. The same feature set has been tested on TCA 3.0 as well.
In VMware Telco Clould Automation 3.1, prebuilt workflows support sending status updates to VMware Telco Clould Service Assurance (TCSA). For more information, see Workflow Hub - Default Workflows and Payload Samples.
"notificationDetails": {
"locusId": "",
"market": "",
"model": "",
"region": "",
"system_type": "",
"tcsa": {
"url": ""
},
"vendor": ""
}
- locusId: Site identifier of the customer in TCSA context (Optional).
- market: Market name of the customer in TCSA context (Optional).
- model: Vendor model name in TCSA context (Optional).
- region: Region of the customer in TCSA context (Optional).
- system_type: System type for the customer in TCSA context (Optional).
- tcsa.url: TCSA Kafka URL with port number in TCSA context (Optional).
- vendor: Vendor name in TCSA context (Optional).
Create or Edit Management Cluster
Description
| Name | Id |
|---|---|
| Create or Edit a Management Cluster | create-edit-management-cluster |
Payload Details
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| managementCluster.action | action can be "create" or "edit". | |
| managementCluster.managementClusterCreate | Contains the payload that is used by TCA API user to create management cluster | *clusterTemplateName should be given instead of id in key "managementCluster.managementClusterCreate.clusterTemplateId" |
| managementCluster.managementClusterCreate.retryRequired | In case management cluster deployment failed and user want to retry cluster creation, this value can be set to "True" [Default is "False", in that case there will be no retry and management cluster will be deleted and recreated] | |
| managementCluster.managementClusterEdit | If action is edit, the configuration that are required to be edited and their payload should be given under this key | |
| managementCluster.managementClusterEdit.name | Name of management cluster to be edited | |
| managementCluster.managementClusterEdit.edit | It contains the configurations that are required to be edited, configurations that required to be edited should be set to "True" [See sample Edit Management Cluster Payload for more details]. Supported editable configurations are masterNodes, workerNodes, clusterConfig, password. The payload of the configurations that are required to be edited should be given under key with name same as configuration name [See sample Edit Management Cluster Payload for more details].The payload under these keys correspond to the payload that is used by TCA API user to edit the cluster. |
|
| mgmt_cluster_max_create_time | Timeout for management cluster creation workflow in seconds, default 3000 seconds [50 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then mgmt_cluster_max_create_time should be 2400 |
| mgmt_cluster_max_edit_time | Timeout for management cluster edit workflow in seconds, default 3000 seconds [50 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then mgmt_cluster_max_edit_time should be 2400 |
| Create Management Cluster |
|---|
{
"password":"<password of TCA Manager>",
"tca":"<ip address of TCA Manager>",
"username":"<username of TCA Manager>",
"managementCluster":{
"action":"create",
"managementClusterCreate":{
"retryRequired":"True",
"name":"<management cluster name>",
"clusterType":"MANAGEMENT",
"clusterTemplateId":"<management cluster template name>",
"hcxCloudUrl":"https://<TCA-CP URL>",
"vmTemplate":"/<Datacenter>/vm/<Folder>/<Template Name>",
"endpointIP":"<endpoint ip>",
"placementParams":[
{
"type":"Folder",
"name":"<folder name/path>"
},
{
"type":"Datastore",
"name":"<datastore name/path>"
},
{
"type":"ResourcePool",
"name":"<resourcepool name/path>"
},
{
"type":"ClusterComputeResource",
"name":"<vsphere cluster name/path>"
}
],
"clusterPassword":"<base64 encoded password>",
"masterNodes":[
{
"name":"master",
"networks":[
{
"label":"MANAGEMENT",
"networkName":"<network path>",
"mtu":"",
"isManagement":true
}
]
}
],
"workerNodes":[
{
"name":"<nodepool name>",
"networks":[
{
"label":"MANAGEMENT",
"networkName":"<network path>",
"mtu":"",
"isManagement":true
}
]
}
]
}
}
} |
Edit Management Cluster Payload : Sample Payload
The version in the following payload are wrt to TCA 2.3. The values will be different for different releases of TCA.
| Edit Management Cluster |
|---|
{
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"managementCluster": {
"action": "edit",
"managementClusterEdit": {
"name": "<management cluster name>",
"edit": {
"masterNodes": "True",
"workerNodes": "True",
"clusterConfig": "True",
"password": "True"
},
"masterNodes": [
{
"name": "master",
"replica": 1
}
],
"workerNodes": {
"replica": 1
},
"clusterConfig": {
"tools": [
{
"name": "nodeconfig-operator",
"version": "2.3.0-21450070"
},
{
"name": "tca-kubecluster-operator",
"version": "2.3.0-21465265"
},
{
"name": "test-controller",
"version": "2.3.0-21492058"
},
{
"name": "tca-diagnosis-operator",
"version": "2.3.0-21482158"
},
{
"name": "istio",
"version": "1.17.0"
},
{
"name": "vmconfig-operator",
"version": "2.3.0-21415178",
"properties": {
"tcaResiliencyEnabled": true,
"extraConfig": ""
}
}
]
},
"password": {
"existingClusterPassword": "<base64 encoded password>",
"clusterPassword": "<base64 encoded password>"
}
}
}
} |
Create Management Cluster Payload [Airgap] : Sample Payload
| Create Management Cluster (Airgap) |
|---|
{
"password":"<password of TCA Manager>",
"tca":"<ip address of TCA Manager>",
"username":"<username of TCA Manager>",
"managementCluster":{
"action":"create",
"managementClusterCreate":{
"airgapConfig":{
"type":"extension",
"extensionId":"<extension id>"
},
"retryRequired":"True",
"name":"<management cluster name>",
"clusterType":"MANAGEMENT",
"clusterTemplateId":"<management cluster template name>",
"hcxCloudUrl":"https://<TCA-CP URL>",
"vmTemplate":"/<Datacenter>/vm/<Folder>/<Template Name>",
"endpointIP":"<endpoint ip>",
"placementParams":[
{
"type":"Folder",
"name":"<folder name/path>"
},
{
"type":"Datastore",
"name":"<datastore name/path>"
},
{
"type":"ResourcePool",
"name":"<resourcepool name/path>"
},
{
"type":"ClusterComputeResource",
"name":"<vsphere cluster name/path>"
}
],
"clusterPassword":"<base64 encoded password>",
"masterNodes":[
{
"name":"master",
"networks":[
{
"label":"MANAGEMENT",
"networkName":"<network path>",
"mtu":"",
"isManagement":true
}
]
}
],
"workerNodes":[
{
"name":"<nodepool name>",
"networks":[
{
"label":"MANAGEMENT",
"networkName":"<network path>",
"mtu":"",
"isManagement":true
}
]
}
]
}
}
} |
- Management cluster template should be pre created before using this workflow
- In the key clusterTemplateId, cluster template name should be given i.e. managementCluster.managementClusterCreate.clusterTemplateId: <cluster template name>
Create Workload Cluster
| Name | Id |
|---|---|
| Create Workload Cluster | idempotent-create-workload-cluster |
Payload Details
| Parameters | Description | |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| workloadCluster | Contains the payload that is used by TCA API user to create workload cluster | In workload cluster payload, value for key spec.nfOrchestrationTcaCPId, spec.clusterConfigSpec.cloudProviders.primeRef.vimId, spec.clusterConfigSpec.cloudProvider.subRefs[0].vimId, spec.controlPlaneSpec.cloudProvider.vimId should be vimName instead of id |
| wkld_cluster_max_run_time | Timeout for workload cluster creation workflow in seconds, default 2700 seconds [45 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then wkld_cluster_max_run_time should be 2400 |
| Create Workload Cluster |
|---|
{
"password": "<password of TCA Manager>",
"username": "<username of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"workloadCluster": {
"metadata": {
"name": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>"
},
"spec": {
"nfOrchestrationTcaCPId": "<vim name>",
"clusterConfigSpec": {
"clusterNetwork": {
"pods": {
"cidrBlocks": [
"100.96.0.0/11"
]
},
"services": {
"cidrBlocks": [
"100.64.0.0/13"
]
}
},
"ipFamilies": "IPv4",
"controlPlaneEndpoint": {
"host": "<endpoint ip>"
},
"cniType": "antrea",
"tcaBomReleaseRef": {
"name": "<tbr name>"
},
"cloudProviders": {
"primeRef": {
"vimId": "<vim name>",
"datacenter": "<datacenter name>"
}
},
"security": {
"auditConfig": {
"enable": true
},
"podSecurityDefaultPolicy": {
"enable": true,
"podSecurityStandardAudit": "baseline",
"podSecurityStandardWarn": "baseline",
"podSecurityStandardEnforce": "privileged"
}
}
},
"controlPlaneSpec": {
"clusterName": "<workload cluster name>",
"controlPlaneName": "<workload cluster name>",
"tcaBomReleaseRef": {
"name": "<tbr name>"
},
"cloudProvider": {
"vimId": "<vim name>"
},
"cloudMachineTemplate": {
"type": "VSphereMachine",
"vSphereMachine": {
"cloneMode": "fullClone",
"datacenter": "<datacenter name>",
"datastore": "<datastore name/path>",
"folder": "<folder name/path>",
"resourcePool": "<resourcepool name/path>",
"template": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
},
"numCPUs": 8,
"diskGiB": 50,
"memoryMiB": 16384,
"replicas": 1,
"rolloutBefore": {
"certificatesExpiryDays": 90
},
"network": {
"devices": [
{
"networkName": "<network path>",
"nameservers": [
"10.1.1.1",
"10.1.1.2"
],
"dhcp4": true
}
]
}
}
}
}
} |
| Create Workload Cluster (Airgap) |
|---|
{
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"workloadCluster": {
"metadata": {
"name": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>"
},
"spec": {
"nfOrchestrationTcaCPId": "<vim name>",
"clusterConfigSpec": {
"airgapSpec": {
"type": "extension",
"extensionId": "<extension id>"
},
"clusterNetwork": {
"pods": {
"cidrBlocks": [
"100.96.0.0/11"
]
},
"services": {
"cidrBlocks": [
"100.64.0.0/13"
]
}
},
"ipFamilies": "IPv4",
"controlPlaneEndpoint": {
"host": "<endpoint ip>"
},
"cniType": "antrea",
"tcaBomReleaseRef": {
"name": "<tbr name>"
},
"cloudProviders": {
"primeRef": {
"vimId": "<vim name>",
"datacenter": "<datacenter name>"
}
},
"security": {
"auditConfig": {
"enable": true
},
"podSecurityDefaultPolicy": {
"enable": true,
"podSecurityStandardAudit": "baseline",
"podSecurityStandardWarn": "baseline",
"podSecurityStandardEnforce": "privileged"
}
}
},
"controlPlaneSpec": {
"clusterName": "<workload cluster name>",
"controlPlaneName": "<workload cluster name>>",
"tcaBomReleaseRef": {
"name": "<tbr name>"
},
"cloudProvider": {
"vimId": "<vim name>"
},
"cloudMachineTemplate": {
"type": "VSphereMachine",
"vSphereMachine": {
"cloneMode": "fullClone",
"datacenter": "<datacenter name>",
"datastore": "<datastore name/path>",
"folder": "<folder name/path>",
"resourcePool": "<resourcepool name/path>",
"template": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
},
"numCPUs": 8,
"diskGiB": 50,
"memoryMiB": 16384,
"replicas": 1,
"rolloutBefore": {
"certificatesExpiryDays": 90
},
"network": {
"devices": [
{
"networkName": "<network path>",
"nameservers": [
"10.1.1.1",
"10.1.1.2"
],
"dhcp4": true
}
]
}
}
}
}
} |
- At every place in payload, vimName, should be given in place of vimId, tcaCpId i.e for key spec.nfOrchestrationTcaCPId, spec.clusterConfigSpec.cloudProviders.primeRef.vimId, spec.clusterConfigSpec.cloudProvider.subRefs[0].vimId, spec.controlPlaneSpec.cloudProvider.vimId vimName should be given instead of id.
Create Nodepool
| Name | Id |
|---|---|
| Create Node Pool | idempotent-create-nodepool |
| Parameters | Description | Comments |
|---|---|---|
| mgmtClusterName | Name of management cluster | |
| nodepool | Contains the payload that is used by TCA API user to create nodepool. | In nodepool payload, value for key spec.cloudProvider.vimId should be vimName |
| np_max_run_time | Timeout for nodepool creation workflow in seconds, default 2700 seconds [45 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then np_max_run_time should be 2400 |
| password | TCA-M password | |
| tca | TCA-M IP | |
| username | TCA-M username |
| Create Nodepool |
|---|
{
"mgmtClusterName": "<management cluster name>",
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"nodepool": {
"metadata": {
"name": "<nodepool name>",
"resourceVersion": 1
},
"spec": {
"cloneMode": "fullClone",
"cloudMachineTemplate": {
"vSphereMachine": {
"datacenter": "<datacenter name>",
"datastore": "<datastore name/path>",
"folder": "<folder name/path>",
"resourcePool": "<resourcepool name/path>",
"template": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
},
"cloudProvider": {
"vimId": "<vim name>"
},
"clusterName": "<workload cluster name>",
"diskGiB": 50,
"kubeadmConfigTemplate": {
"joinConfiguration": {
"nodeRegistration": {
"kubeletExtraArgs": {
"cpu-manager-policy": "static",
"system-reserved": "cpu=1,memory=1Gi"
}
}
}
},
"labels": {
"key1": "value1",
"key2": "value2"
},
"memoryMiB": 65536,
"network": {
"devices": [
{
"dhcp4": true,
"nameservers": [
"10.1.1.1",
"10.1.1.2"
],
"networkName": "<network path>"
}
]
},
"numCPUs": 8,
"replicas": 1,
"tcaBomReleaseRef": {
"name": "<tbr name>"
}
}
}
} |
- Value for key spec.cloudProvider.vimId should be vimName
AddOns Creation
| Name | Id |
|---|---|
| Create Workload Cluster AddOn | create-workload-cluster-addon |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| clusterName | Workload cluster name | |
| mgmtClusterName | Management Cluster Name | |
| addons | Array with each object corresponding to the payload that is used by TCA API user to create addOns | |
| addons[*].addonName | AddOn name | |
| timeouts.addon_max_run_time | Timeout for addons creation workflow in seconds, default 600 seconds [10 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.addon_max_run_time should be 2400 |
| Create AddOns |
|---|
{
"password":"<password of TCA Manager>",
"username":"<username of TCA Manager>",
"tca":"<ip address of TCA Manager>",
"clusterName":"<workload cluster name>",
"mgmtClusterName":"<management cluster name>",
"addons":[
{
"addonName":"systemsettings",
"metadata":{
"name":"systemsettings",
"clusterName":"<workload cluster name>"
},
"spec":{
"name":"systemSettings",
"clusterRef":{
"name":"<workload cluster name>",
"namespace":"<workload cluster name>"
},
"config":{
"stringData":{
"values.yaml":"clusterPassword: <base64 encoded password>\n"
}
}
}
},
{
"addonName":"harbor",
"metadata":{
"name":"harbor",
"clusterName":"<workload cluster name>"
},
"spec":{
"name":"harbor",
"clusterRef":{
"name":"<workload cluster name>",
"namespace":"<workload cluster name>"
},
"config":{
"stringData":{
"values.yaml":"harbors:\n - protocol: http\n externalHarborIp: <external harbor ip>\n port: <port number>\n externalHarborUser: admin\n externalHarborPwd: <base64 encoded password>\n insecure: true\n"
}
}
}
}
]
} |
Create and Instantiate CNF
| Name | Id |
|---|---|
| Create and Instantiate CNF | create-and-instantiate-cnf |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| clusterName | Workload cluster name | |
| cnf | Contains the payload to create and instantiate CNF | |
| cnf.cnfdName | Name of the CNF catalog | |
| cnf.cnfInstanceName | Name of CNF instance | |
| cnf.nodePoolName | Name of the nodepool that should be customized while instantiating CNF | |
| cnf.payload.additionalParams | Corresponds to additionalParams in TCA CNF instantiate API payload | |
| timeouts.cnf_instantiate_max_run_time | Timeout for create and instantiate cnf workflow in seconds, default 2700 seconds [45 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.cnf_instantiate_max_run_time should be 2400 |
| Create and Instantiate CNF |
|---|
{
"password": "<password of TCA Manager>",
"username": "<username of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"clusterName": "<workload cluster name>",
"cnf": {
"cnfdName": "<cnf catalog name>",
"cnfInstanceName": "<cnf instance name>",
"nodePoolName": "<nodepool name>",
"payload": {
"additionalParams": {
"vduParams": [
{
"repoUrl": "<repo URL>",
"username": "<repo username>",
"password": "<repo password>",
"metadata": [
{
"key1": "value1",
"key2": "value2"
}
],
"vduName": "<vdu Name>"
}
],
"disableGrant": false,
"ignoreGrantFailure": false,
"disableAutoRollback": false,
"timeoutInSecs": 1200
}
}
}
} |
- CNF Catalog should be uploaded before executing this workflow
- In above payload key1, key2 will depend on the CNF to be instantiated
Upgrade Set of Management Clusters
| Name | Id |
|---|---|
| Upgrade a Set of Management Clusters | upgrade-set-of-management-clusters |
| Parameters | Description | Comments |
|---|---|---|
| timeouts.mgmt_cluster_max_upgrade_time | Timeout for management cluster upgrade workflow in seconds, default 12000 seconds [200 minutes] | In case user want to upgrade multiple management clusters on same TCA using this workflow, then they must set this value to high number to avoid workflow timeout since TCA supports only 1 management cluster upgrade at a time, the rest will be queued at TCA side. If user wants timeout to be 400 minutes i.e 24000 seconds, then timeouts.mgmt_cluster_max_upgrade_time should be 24000 |
| managementClustersUpgrade | This key contains payload to upgrade a set of a management clusters | |
| managementClustersUpgrade[*].tca | TCA-M IP | |
| managementClustersUpgrade[*].username | TCA-M username | |
| managementClustersUpgrade[*].password | TCA-M password | |
| managementClustersUpgrade[*].managementClusterUpgrade | This key contains the payload to upgrade management cluster | |
| managementClustersUpgrade[*].managementClusterUpgrade.name | Name of management cluster to be upgraded | |
| managementClustersUpgrade[*].managementClusterUpgrade.skipValidation | true or false depending on whether validations before upgrade are to be skipped | |
| managementClustersUpgrade[*].managementClusterUpgrade.kubernetesVersion | Kubernetes version to which cluster is to be upgraded | |
| managementClustersUpgrade[*].managementClusterUpgrade.vmTemplate | vm template corresponding to the Kubernetes version |
| Upgrade Set of Management Cluster |
|---|
{
"timeouts": {
"mgmt_cluster_max_upgrade_time": 24000
},
"managementClustersUpgrade": [
{
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"managementClusterUpgrade": {
"name": "<management cluster name>",
"skipValidation": false,
"kubernetesVersion": "v1.24.10+vmware.1",
"vmTemplate": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
},
{
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"managementClusterUpgrade": {
"name": "<management cluster name>",
"skipValidation": false,
"kubernetesVersion": "v1.24.10+vmware.1",
"vmTemplate": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
}
]
} |
- In case user want to use this workflow to upgrade multiple management clusters managed by same TCA, then user has two options:
- OPTION 1: Increase the timeout value for workflow by setting timeouts.mgmt_cluster_max_upgrade_time to higher number
- OPTION 2: Clone the workflow and modify it to support sequential upgrade instead parallel by setting mode as sequential in foreach state
Upgrade Set of Workload Clusters
| Name | Id |
|---|---|
| Upgrade Set of Workload Clusters Control Plane | upgrade-set-of-workload-clusters-control-plane |
| Parameters | Description | Comments |
|---|---|---|
| timeouts.upgradeWorkloadClusterControlPlane | Timeout for workload cluster control plane upgrade workflow in seconds, default 7200 seconds [120 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.upgradeWorkloadClusterControlPlane should be 2400 |
| workloadClustersUpgrade | This key contains payload to upgrade a set of a workload clusters control plane | |
| workloadClustersUpgrade[*].tca | TCA-M IP | |
| workloadClustersUpgrade[*].username | TCA-M username | |
| workloadClustersUpgrade[*].password | TCA-M password | |
| workloadClustersUpgrade[*].workloadClusterUpgrade | This key contains the payload to upgrade workload cluster control plane | |
| workloadClustersUpgrade[*].workloadClusterUpgrade.clusterName | Name of workload cluster | |
| workloadClustersUpgrade[*].workloadClusterUpgrade.mgmtClusterName | Name of management cluster | |
| workloadClustersUpgrade[*].workloadClusterUpgrade.tbrName | tbr to which workload cluster will be upgraded | |
| workloadClustersUpgrade[*].workloadClusterUpgrade.template | template corresponding to the kubernetes version |
| Upgrade Set of Workload Cluster |
|---|
{
"workloadClustersUpgrade": [
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"workloadClusterUpgrade": {
"clusterName": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>",
"tbrName": "<tbr name>",
"template": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
},
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"workloadClusterUpgrade": {
"clusterName": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>",
"tbrName": "<tbr name>",
"template": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
}
]
} |
Upgrade Set of Nodepools
| Name | Id |
|---|---|
| Upgrade a set of Node Pools | upgrade-set-of-nodepools |
| Parameters | Description | Comments |
|---|---|---|
| timeouts.nodepoolUpgradeRun | Timeout for workload cluster nodepool upgrade workflow in seconds, default 2400 seconds [40 minutes] | If user wants timeout to be 45 minutes i.e 2700 seconds, then timeouts.nodepoolUpgradeRun should be 2700 |
| nodepoolsUpgrade | This key contains payload to upgrade a set of a nodepools | |
| nodepoolsUpgrade[*].tca | TCA-M IP | |
| nodepoolsUpgrade[*].username | TCA-M username | |
| nodepoolsUpgrade[*].password | TCA-M password | |
| nodepoolsUpgrade[*].nodepoolSpec | This key contains the payload to upgrade nodepool | |
| nodepoolsUpgrade[*].nodepoolSpec.mgmtClusterName | Name of management cluster | |
| nodepoolsUpgrade[*].nodepoolSpec.clusterName | Name of workload cluster | |
| nodepoolsUpgrade[*].nodepoolSpec.nodepoolName | Name of nodepool to be upgraded | |
| nodepoolsUpgrade[*].nodepoolSpec.template | vm template corresponding to upgraded Kubernetes version [Optional, Default value: workload cluster control plane vm template] |
| Upgrade Set of Nodepools |
|---|
{
"nodepoolsUpgrade": [
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"nodepoolSpec": {
"mgmtClusterName": "<management cluster name>",
"clusterName": "<workload cluster name>",
"nodepoolName": "<nodepool name>",
"template": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
},
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"nodepoolSpec": {
"mgmtClusterName": "<management cluster name>",
"clusterName": "<workload cluster name>",
"nodepoolName": "<nodepool name>"
}
},
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"nodepoolSpec": {
"mgmtClusterName": "<management cluster name>",
"clusterName": "<workload cluster name>",
"nodepoolName": "<nodepool name>"
}
},
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"nodepoolSpec": {
"mgmtClusterName": "<management cluster name>",
"clusterName": "<workload cluster name>",
"nodepoolName": "<nodepool name>"
}
}
]
} |
Management Cluster Pre Upgrade Validations
| Name | Id |
|---|---|
| Pre-Upgrade Validations for Management Cluster | management-cluster-pre-upgrade-validations |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| mgmtClusterPreUpgradeValidate | This key contains payload to validate management cluster | |
| mgmtClusterPreUpgradeValidate.mgmtClusterName | Name of management cluster on which validations are to be performed |
| Management Cluster Pre Upgrade Validations |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"mgmtClusterPreUpgradeValidate": {
"mgmtClusterName": "<management cluster name>"
}
} |
- Validations performed by this workflow are same as the validations performed by TCA Diagnosis API on management cluster using caseSelectors as pre-upgrade.
- The set of validations performed and validation report can be found on the Cluster on which validations are run.
- Login to TCA
- Go to CAAS Infrastructure
- Click on the cluster on which validation is performed → Go to Diagnosis tab
Management Cluster Post Upgrade Validations
| Name | Id |
|---|---|
| Post-Upgrade Validations for Management Cluster | management-cluster-post-upgrade-validations |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| mgmtClusterPostUpgradeValidate | This key contains payload to validate management cluster | |
| mgmtClusterPostUpgradeValidate.mgmtClusterName | Name of management cluster on which validations are to be performed |
| Management Cluster Post Upgrade Validations |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"mgmtClusterPostUpgradeValidate": {
"mgmtClusterName": "<management cluster name>"
}
} |
- Validations performed by this workflow are same as the validations performed by TCA Diagnosis API on management cluster using caseSelectors as post-upgrade.
- The set of validations performed and validation report can be found on the Cluster on which validations are run.
- Login to TCA
- Go to CAAS Infrastructure
- Click on the cluster on which validation is performed → Go to Diagnosis tab
Workload Cluster Pre Upgrade Validations
| Name | Id |
|---|---|
| Pre-Upgrade Validations for Workload Cluster | workload-cluster-pre-upgrade-validations |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| wkldClusterPreUpgradeValidate | This key contains payload to validate workload cluster | |
| wkldClusterPreUpgradeValidate.mgmtClusterName | Name of management cluster managing the workload cluster | |
| wkldClusterPreUpgradeValidate.clusters | Array with each object corresponding to cluster on which validations is to be performed | |
| wkldClusterPreUpgradeValidate.clusters[*].clusterName | Name of workload cluster on which validations are to be performed |
| Workload Cluster Pre Upgrade Validations |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"wkldClusterPreUpgradeValidate": {
"mgmtClusterName": "<management cluster name>",
"clusters": [
{
"clusterName": "<workload cluster name>"
}
]
}
} |
- Validations performed by this workflow are same as the validations performed by TCA Diagnosis API on workload cluster using caseSelectors as pre-upgrade.
- The set of validations performed and validation report can be found on the Cluster on which validations are run.
- Login to TCA
- Go to CAAS Infrastructure
- Click on the cluster on which validation is performed → Go to Diagnosis tab
Workload Cluster Post Upgrade Validations
| Name | Id |
|---|---|
| Post-Upgrade validations for Workload cluster | workload-cluster-post-upgrade-validations |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| wkldClusterPostUpgradeValidate | This key contains payload to validate workload cluster | |
| wkldClusterPostUpgradeValidate.mgmtClusterName | Name of management cluster managing the workload cluster | |
| wkldClusterPostUpgradeValidate.clusters | Array with each object corresponding to cluster on which validations is to be performed | |
| wkldClusterPostUpgradeValidate.clusters[*].clusterName | Name of workload cluster on which validations are to be performed |
| Workload Cluster Post Upgrade Validations |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"wkldClusterPostUpgradeValidate": {
"mgmtClusterName": "<management cluster name>",
"clusters": [
{
"clusterName": "<workload cluster name>"
}
]
}
} |
- Validations performed by this workflow are same as the validations performed by TCA Diagnosis API on workload cluster using caseSelectors as post-upgrade.
- The set of validations performed and validation report can be found on the Cluster on which validations are run.
- Login to TCA
- Go to CAAS Infrastructure
- Click on the cluster on which validation is performed → Go to Diagnosis tab
Delete CNF Instance
| Name | Id |
|---|---|
| Delete a CNF Instance | delete-cnf-instance |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| cnfInstanceName | Name of CNF Instance to be terminated and deleted | |
| timeouts.cnf_terminate_wait | Timeout for delete cnf workflow in seconds, default 300 seconds [5 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.cnf_terminate_wait should be 2400 |
| Delete CNF Instance |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"cnfInstanceName": "<cnf instance name>"
} |
Delete Nodepool
| Name | Id |
|---|---|
| Delete Node Pool | delete-nodepool |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| mgmtClusterName | Name of management cluster managing workload cluster | |
| clusterName | Name of workload cluster | |
| nodepoolName | Name of nodepool to be deleted | |
| np_max_delete_time | Timeout for delete nodepool workflow in seconds, default 2700 seconds [45 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then np_max_delete_time should be 2400 |
| Delete Nodepool |
|---|
{
"clusterName": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>",
"nodepoolName": "<nodepool name>",
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>"
} |
Delete Workload Cluster
| Name | Id |
|---|---|
| Delete Workload Cluster | delete-v2-workload-cluster |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| mgmtClusterName | Name of management cluster managing workload cluster | |
| clusterName | Name of workload cluster to be deleted | |
| timeouts.delete_cluster | Timeout for delete workload cluster workflow in seconds, default 2700 seconds | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.delete_cluster should be 2400 |
| timeouts.delete_vim | Timeout for delete vim in seconds, default 100 seconds | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.delete_vim should be 2400 |
| Delete Workload Cluster |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"clusterName": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>"
} |
Delete Management Cluster
| Name | Id |
|---|---|
| Delete a Management Cluster | delete-management-cluster |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| mgmtClusterName | Name of management cluster to be deleted | |
| mgmt_cluster_delete_max_run_time | Timeout for delete management cluster workflow in seconds, default 3600 seconds | If user wants timeout to be 40 minutes i.e 2400 seconds, then mgmt_cluster_delete_max_run_time should be 2400 |
| Delete Management Cluster |
|---|
{
"password": "<password of TCA Manager>",
"username": "<username of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"mgmtClusterName": "<management cluster name>"
} |
Upgrade CNF
| Name | Id |
|---|---|
| Upgrade CNF Instance | upgrade-cnf-instance |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| cnfUpgrade | This key contains payload to upgrade CNF instance | |
| cnfUpgrade.cnfdName | CNF catalog name for existing CNF instance | |
| cnfUpgrade.newCnfdName | CNF catalog name using which the instance will be upgraded | |
| cnfUpgrade.payload.componentMapping | Corresponds to componentMapping in TCA CNF upgrade API payload | |
| cnfUpgrade.payload.additionalParams | Corresponds to additionalParams in TCA CNF upgrade API payload | |
| upgrade_max_run_time | Timeout for upgrade cnf workflow in seconds, default 1200 seconds | If user wants timeout to be 40 minutes i.e 2400 seconds, then upgrade_max_run_time should be 2400 |
| CNF Upgrade |
|---|
{
"password": "<password of TCA Manager>",
"username": "<username of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"cnfUpgrade": {
"cnfdName": "<cnf catalog name>",
"newCnfdName": "<new cnf catalog name>",
"cnfInstanceName": "<cnf instance name>",
"payload": {
"componentMapping": [
{
"oldVduId": "helm1",
"newVduId": "helm1"
}
],
"additionalParams": {
"helm1": {
"metadata": {
"fileInput": ""
},
"namespace": "default",
"repoUrl": "<repo URL>",
"username": "<repo username>",
"password": "<repo password>"
},
"namespace": "default",
"repoUrl": "<repo URL>",
"username": "<repo username>",
"password": "<repo password>"
}
}
},
"clusterName": "<workload cluster name>"
} |
Run Kubernetes Job
Description
| Name | Id |
|---|---|
| Create Kubernetes Job | k8s-job |
| Parameters | Description | Comments |
|---|---|---|
| runK8sJob | The payload to create config-map and job is given under this key | |
| runK8sJob.fetchPodLogs | true or false depending on whether user wants to fetch the pod logs or not, this will be useful for debugging incase the job fails. Default is false | |
| runK8sJob.kubeconfig | Kubeconfig of cluster where user wants to run the job | The cluster must have the access to the image with which user wants to run the Kubernetes job |
| runK8sJob.configMapSpec | This key contains the payload to create Kubernetes config-map | The namespace under which config map is to be created must pre-exist in the cluster |
| runK8sJob.jobSpec | This key contains payload to create Kubernetes job | The namespace under which job is to be created must pre-exist in the cluster |
| runK8sJob.cleanupJob | true or false depending on whether user wants to clean up job after completion or not, default is true | |
| timeouts.monitorJobTimeout | Timeout for Run Kubernetes Job workflow in seconds, default 300 seconds | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.monitorJobTimeout should be 2400 |
| Run Kubernetes Job |
|---|
{
"runK8sJob": {
"fetchPodLogs": true,
"kubeconfig": "<base64 encoded Kubeconfig of cluster>",
"configMapSpec": {
"apiVersion": "v1",
"kind": "ConfigMap",
"metadata": {
"name": "<configmap name>",
"namespace": "default"
},
"data": {
"key1": "value1",
"key2": "value2"
}
},
"jobSpec": {
"apiVersion": "batch/v1",
"kind": "Job",
"metadata": {
"name": "<job name>",
"namespace": "default"
},
"spec": {
"template": {
"spec": {
"containers": [
{
"name": "<container name>",
"image": "<image>",
"command": [
"<command 1>",
"<command 2>"
]
}
],
"restartPolicy": "OnFailure"
}
},
"backoffLimit": 4
}
}
}
} |
- The cluster whose Kubeconfig is given as input must be accessible from the Workflow Hub.
- The image using which the Kubernetes job is to created must be accessible from the cluster where user wants to run the job.
- The namespace under which config-map and job is to be created must pre-exist in the cluster.
Ansible Executer
Description
This workflow is used to execute anisble playbooks.
| Name | Id |
|---|---|
| Execute an Ansible Playbook | execute-ansible-playbook |
| Parameters | Description | Comments |
|---|---|---|
| ansibleExecuter | The payload to execute ansible playbooks is given under this key | |
| ansibleExecuter.kubeconfig | Kubeconfig of cluster where user wants to execute playbooks | |
| ansibleExecuter.playbookInput | The input json that user wants to give to ansible playbook will come under this key [Optional in case the playbook does not require any input] | This input will be json and not string |
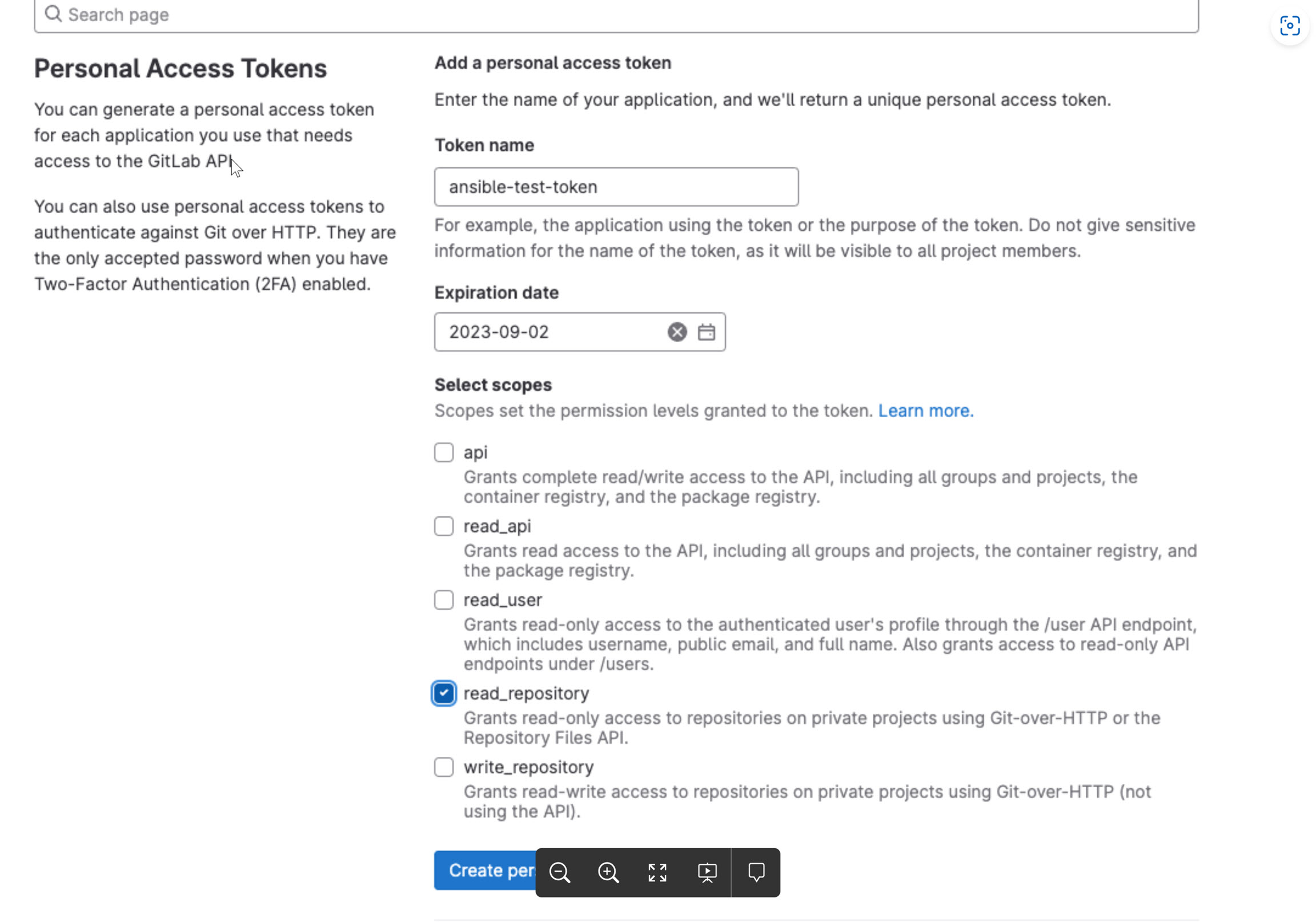
| ansibleExecuter.token | gitlab accees token | Since the playbook that user want to execute will be hosted in some repository, if the repository is not accessible from cluster (private repo), in that case user needs to give the access token to access the repo. Steps to get access token from gitlab:
|
| ansibleExecuter.gitRepoUrl | URL of the repo where playbooks are saved | |
| ansible_executer.gitRepoBranch | Git Repo Branch [Optional] | |
| ansible_executer.resources.limits.cpu | container cpu limit [Optional, default: 500m] | These resources request and limit corresponds to standard Kubernetes resources request and limit |
| ansible_executer.resources.limits.memory | container memory limit [Optional, default 500 Mi] | |
| ansible_executer.resources.requests.cpu | container cpu requests [Optional, default 50m] | |
| ansible_executer.resources.requests.memory | container memory requests [Optional, default 50 Mi] | |
| ansibleExecuter.playbookPath | Relative path of the playbook that needs to be executed | |
| ansibleExecuter.playbookInputParameterName | Name under which the playbookInputParameters will be loaded [Required only when ansibleExecuter.playbookInput is given] | |
| ansibleExecuter.inventory | The inventory file that user want to give for executing playbooks [Optional] | |
| ansibleExecuter.fetchPodLogs | true or false depending on whether user wants to fetch logs or not after execution, default is false | |
| ansibleExecuter.namespace | namespace [optional, default value: default ] | |
| ansibleExecuter.image | image using which container will be built to execute ansible playbooks [Default: vmwaresaas.jfrog.io/tcaworkflowhub-prod-docker-local/ansible-executor:3.0.0] | Incase this workflow is to be run on airgap setup, the image has to be passed |
| timeouts.ansibleExecutionTimeOut | Timeout for Ansible Executer workflow in seconds, default 600 seconds | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.ansibleExecutionTimeOut should be 2400 |
Ansible Executer : Sample Payload
| Ansible Executer ESX Hardening |
|---|
{
"ansible_executer": {
"kubeconfig": "<base64 encoded Kubeconfig of cluster>",
"playbookInput": <playbook input>,
"token": "<TOKEN>",
"gitRepoUrl": "<git repo URL>",
"playbookPath": "<relative playbook path>",
"playbookInputParameterName": "<playbook input parameter name>",
"fetchPodLogs": true,
"image": "<airgap_server_fqdn>/registry/ansible-executor:3.0.0-ob-<build number>" # This parameter should be required only in case of airgap setup otherwise this parameter can be removed
}
} |
Example 2: The following example does ls and print package manager on host.
| Ansible Executer Test SSH |
|---|
{
"ansible_executer":{
"kubeconfig":"<base64 encoded Kubeconfig of cluster>",
"inventory":{
"test-hosts":{
"hosts":{
"<Host 1 IP>":{
"ansible_ssh_pass":"<host ssh password>",
"ansible_ssh_user":"<host ssh username>"
},
"<Host 2 IP>":{
"ansible_ssh_pass":"<host ssh password>",
"ansible_ssh_user":"<host ssh username>"
}
}
}
},
"token":"<TOKEN>",
"gitRepoUrl":"<git repo URL>",
"playbookPath":"ansible_scripts/test_ssh.yml",
"fetchPodLogs":true,
"image": "<airgap_server_fqdn>/registry/ansible-executor:3.0.0-ob-<build number>" # This parameter should be required only in case of airgap setup otherwise this parameter can be removed
}
} |
The sample playbook, test_ssh.yml, located at git repo at relative path ansible_scripts/test_ssh.yml is shown below:
| test ssh playbook |
|---|
---
- hosts: test-hosts
tasks:
- name: "This is a test task"
command: ls
register: ls_output
- name: Print ls ls_output
debug:
var: ls_output.stdout_lines
- name: Print Package Manager
debug:
var: ansible_pkg_mgr |
- We have provided a built in image that contains ansible and python script to execute the playbook. The cluster whose Kubeconfig is given as input to the workflow must be accessible from the Workflow Hub and the image must be accessible from the cluster where user wants to execute the playbooks.
- Incase this workflow is to be run on airgap setup, the image has to be passed as an input in key ansible_executer.image
-
The workflow is written assuming following:
- Playbook is located at a git repo
- The playbook scripts hosted on gitlab should be accessible to the Workflow Hub and the Cluster on which ansible executer container is targeted to run.
- If playbook to be executed requires an input, that input must be loaded in some variable in playbook and that variable name is give under key playbookInputParameterName.
- If the playbook is to be executed using the inventory file, then the inventory details must be given as input.
- The pre built image for ansible executions is built considering above assumptions, in case user wants some additional use cases that are not supported by the image, they can create their image and write a new workflow accordingly to execute ansible playbook.
Create Management Cluster
| Name | Id |
|---|---|
| Create Management Cluster | create-management-cluster |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| managementCluster.managementClusterCreate | Contains the payload that is used by TCA API user to create management cluster | *clusterTemplateName should be given instead of id in key "managementCluster.managementClusterCreate.clusterTemplateId" |
| managementCluster.managementClusterCreate.retryRequired | In case management cluster deployment failed and user want to retry cluster creation, this value can be set to "True" [Default is "False", in that case there will be no retry and management cluster will be deleted and recreated] | |
| mgmt_cluster_max_create_time | Timeout for management cluster creation workflow in seconds, default 3000 seconds [50 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then mgmt_cluster_max_create_time should be 2400 |
| Create Management Cluster |
|---|
{
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"managementCluster": {
"managementClusterCreate": {
"clusterPassword": "<base64 encoded password>",
"clusterTemplateId": "<management cluster template name>",
"clusterType": "MANAGEMENT",
"endpointIP": "<endpoint ip>",
"hcxCloudUrl": "https://<TCA-CP URL>",
"masterNodes": [
{
"name": "master",
"networks": [
{
"isManagement": true,
"label": "MANAGEMENT",
"mtu": "",
"networkName": "<network path>"
}
]
}
],
"name": "<management cluster name>",
"placementParams": [
{
"name": "<folder name/path>",
"type": "Folder"
},
{
"name": "<datastore name/path>",
"type": "Datastore"
},
{
"name": "<resourcepool name/path>",
"type": "ResourcePool"
},
{
"name": "<vsphere cluster name/path>",
"type": "ClusterComputeResource"
}
],
"retryRequired": "True",
"vmTemplate": "/<Datacenter>/vm/<Folder>/<Template Name>",
"workerNodes": [
{
"name": "<nodepool name>",
"networks": [
{
"isManagement": true,
"label": "MANAGEMENT",
"mtu": "",
"networkName": "<network path>"
}
]
}
]
}
}
} |
- Management cluster template should be pre created before using this workflow
- In the key clusterTemplateId, cluster template name should be given i.e. managementCluster.managementClusterCreate.clusterTemplateId: <cluster template name>
Edit Management Cluster
| Name | Id |
|---|---|
| Edit a Management Cluster | edit-management-cluster |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| managementCluster.managementClusterEdit | The configuration that are required to be edited and their payload should be given under this key | |
| managementCluster.managementClusterEdit.name | Name of management cluster to be edited | |
| managementCluster.managementClusterEdit.edit | It contains the configurations that are required to be edited, configurations that required to be edited should be set to "True" [See sample Edit Management Cluster Payload for more details]. Supported editable configurations are masterNodes, workerNodes, clusterConfig, password. The configurations that are required to be edited, their payload [same payload as used by TCA API user] should be given under key with name same as configuration name [See sample Edit Management Cluster Payload for more details] | |
| mgmt_cluster_max_edit_time | Timeout for management cluster edit workflow in seconds, default 3000 seconds [50 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then mgmt_cluster_max_edit_time should be 2400 |
| Edit Management Cluster |
|---|
{
"managementCluster": {
"managementClusterEdit": {
"edit": {
"clusterConfig": "True",
"masterNodes": "True",
"password": "True",
"workerNodes": "True"
},
"clusterConfig": {
"tools": [
{
"name": "nodeconfig-operator",
"version": "2.3.0-21450070"
},
{
"name": "tca-kubecluster-operator",
"version": "2.3.0-21465265"
},
{
"name": "test-controller",
"version": "2.3.0-21492058"
},
{
"name": "tca-diagnosis-operator",
"version": "2.3.0-21482158"
},
{
"name": "istio",
"version": "1.17.0"
},
{
"name": "vmconfig-operator",
"properties": {
"extraConfig": "",
"tcaResiliencyEnabled": true
},
"version": "2.3.0-21415178"
}
]
},
"masterNodes": [
{
"name": "master",
"replica": 1
}
],
"name": "<management cluster name>",
"password": {
"clusterPassword": "<base64 encoded password>",
"existingClusterPassword": "<base64 encoded password>"
},
"workerNodes": {
"replica": 1
}
}
},
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>"
} |
- Version in above payloads are wrt to TCA 2.3. The values will be different for different releases of TCA.
Cluster Upgrade Validations
| Name | Id |
|---|---|
| CAAS Clusters Upgrade Validations | caas-cluster-upgrade-validations |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| clusterUpgradeValidations | This key contains payload to validate cluster | |
| clusterUpgradeValidations.mgmtClusterName | Name of management cluster | |
| clusterUpgradeValidations.clusterType | management or workload | |
| clusterUpgradeValidations.clusters | Array with each object corresponding to cluster on which validations is to be performed [Required only when cluster type is workload] | |
| clusterUpgradeValidations.clusters[*].clusterName | Name of workload cluster on which validations are to be performed [Required only when cluster type is workload cluster] | |
| clusterUpgradeValidations.caseSelectors | Array of strings that supports all such selectors supported by TCA diagnosis API [See Sample Cluster Upgrade Validations Payload for more details] | |
| timeouts.upgrade_validations_run | Timeout for Cluster Upgrade Validations workflow in seconds, default 1800 seconds [30 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.upgrade_validations_run should be 2400 |
| Cluster Upgrade Validations |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"clusterUpgradeValidations": {
"mgmtClusterName": "<management cluster name>",
"clusterType": "workload",
"clusters": [
{
"clusterName": "<workload cluster name>"
}
],
"caseSelectors": [
"pre-upgrade"
]
}
} |
Management Cluster Upgrade
| Name | Id |
|---|---|
| Upgrade a Management Cluster | management-cluster-upgrade |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| managementClusterUpgrade | This key contains payload to upgrade management cluster | |
| managementClusterUpgrade.name | Name of management cluster to be upgraded | |
| managementClusterUpgrade.skipValidation | true or false depending on whether validations before upgrade are to be skipped | |
| managementClusterUpgrade.kubernetesVersion | Kubernetes version to which cluster is to be upgraded | |
| managementClusterUpgrade.vmTemplate | vm template corresponding to the Kubernetes version | |
| timeouts.mgmt_cluster_max_upgrade_time | Timeout for management cluster upgrade workflow in seconds, default 12000 seconds [200 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then mgmt_cluster_max_upgrade_time should be 2400 |
| Management Cluster Upgrade |
|---|
{
"password": "<password of TCA Manager>",
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"managementClusterUpgrade": {
"name": "<management cluster name>",
"skipValidation": false,
"kubernetesVersion": "v1.24.10+vmware.1",
"vmTemplate": "/<Datacenter>/vm/<Folder>/<Template Name>"
}
} |
Workload Cluster Control Plane Upgrade
| Name | Id |
|---|---|
| Upgrade a Workload Cluster Control Plane | workload-cluster-control-plane-upgrade |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| wkldClusterUpgrade | This key contains payload to upgrade workload cluster | |
| wkldClusterUpgrade.clusterName | Name of workload cluster | |
| wkldClusterUpgrade.mgmtClusterName | Name of management cluster | |
| wkldClusterUpgrade.tbrName | tbr to which workload cluster will be upgraded | |
| wkldClusterUpgrade.template | template corresponding to the Kubernetes version | |
| timeouts.upgradeWorkloadClusterControlPlane | Timeout for workload cluster control plane upgrade workflow in seconds, default 7200 seconds [120 minutes] | If user wants timeout to be 40 minutes i.e 2400 seconds, then timeouts.upgradeWorkloadClusterControlPlane should be 2400 |
| Workload Cluster Control Plane Upgrade |
|---|
{
"tca": "<ip address of TCA Manager>",
"username": "<username of TCA Manager>",
"password": "<password of TCA Manager>",
"workloadClusterUpgrade": {
"clusterName": "<workload cluster name>",
"mgmtClusterName": "<management cluster name>",
"tbrName": "<tbr name>",
"template": "/<Datacenter>/vm/<Folder>/<TemplateName>"
}
} |
Workload Cluster Nodepool Upgrade
| Name | Id |
|---|---|
| Upgrade Workload Cluster Node Pool | upgrade-nodepool |
| Parameters | Description | Comments |
|---|---|---|
| tca | TCA-M IP | |
| username | TCA-M username | |
| password | TCA-M password | |
| timeouts.nodepoolUpgradeRun | Timeout for nodepool upgrade workflow in seconds, default 2400 seconds [40 minutes] | If user wants timeout to be 45 minutes i.e 2700 seconds, then timeouts.nodepoolUpgradeRun should be 2700 |
| nodepoolSpec | This key contains payload to upgrade nodepool | |
| nodepoolSpec.clusterName | name of workload cluster | |
| nodepoolSpec.mgmt-clusterName | name of management cluster | |
| nodepoolSpec.nodepoolName | name of nodepool to be upgraded |
| Workload Cluster Nodepool Upgrade |
|---|
{
"tca": "<ip address of TCA Manager>",
"username":"<username of TCA Manager>",
"password":"<password of TCA Manager>",
"timeouts":{
"nodepoolUpgradeRun": 4800
},
"nodepoolSpec":{
"clusterName":"<workload cluster name>",
"mgmtClusterName":"<management cluster name>",
"nodepoolName":"<nodepool name>"
}
} |
