









The Tanzu Kubernetes clusters are deployed in the compute workload domains.
Telco Cloud Platform RAN consumes resources from the compute workload domain. Resource pools provide guaranteed resource availability to workloads. Resource pools are elastic; more resources can be added as its capacity grows. Each Kubernetes cluster can be mapped to a resource pool. A resource pool can be dedicated to a Kubernetes cluster or shared across multiple clusters.
In a RAN deployment design with a Regional Data Center and Cell Sites, Kubernetes control plane node can be placed on a vSphere cluster at Regional Data Center and Worker nodes can be placed on a ESXi host at Cell Site to support CNF workloads. Both vSphere clusters and ESXi hosts can be managed by a vCenter Server in the compute workload domain.
Recommended Resource Workload Domain Design
Design Recommendation |
Design Justification |
Design Implication |
|---|---|---|
Map the Tanzu Kubernetes clusters to the vSphere Resource Pool in the compute workload domain. |
Enables Resource Guarantee and Resource Isolation. |
During resource contention, workloads can be starved for resources and can experience performance degradation. Note: You must proactively perform monitoring and capacity management and add the capacity before the contention occurs. |
|
|
|
Place the Kubernetes cluster management network on a virtual network, which is routable to the management network for vSphere, Harbor, and repository mirror. |
|
|
Enable 1:1 Kubernetes Cluster to Resource Pool mapping for data plane intensive workloads.
Reduced resource contention can lead to better performance.
Better resource isolation and resource guarantees and reporting.
Enable N:1 Kubernetes Cluster to Resource Pool mapping for control plane workloads where resources are shared.
Efficient use of the server resources
High workload density
Use vRealize Operation Manager to provide recommendations on the required resource by analyzing performance statistics.
Consider the total number of ESXi hosts and Kubernetes cluster limits.
Management and Workload Kubernetes Clusters
A Kubernetes cluster in Telco Cloud Platform RAN consists of etcd and the Kubernetes control and data planes.
Etcd: Etcd must run in the cluster mode with an odd number of cluster members to establish a quorum. A 3-node cluster tolerates the loss of a single member, while a 5-node cluster tolerates the loss of two members. In a stacked mode deployment, etcd availability determines the number of Kubernetes Control nodes.
Control Plane node: The Kubernetes control plane must run in redundant mode to avoid a single point of failure. To improve API availability, Kube-Vip is placed in front of the Control Plane nodes.
Component |
Availability |
|---|---|
API Server |
Active/Active |
Kube-controller-manager |
Active/Passive |
Kube-scheduler |
Active/Passive |
Do not place CNF workloads on the control plane nodes.
Worker Node
5G RAN workloads are classified based on their performances. Generic workloads such as web services, lightweight databases, monitoring dashboards, and so on, are supported adequately using standard configurations on Kubernetes nodes. In addition to the recommendations outlined in the Tuning Telco Cloud Platform 5G Edition for Data Plane Intensive Workloads white paper, the data plane workload performance can benefit from further tuning in the following areas:
NUMA Topology
CPU Core Affinity
Huge Pages
NUMA Topology: When deploying Kubernetes worker nodes that host high data bandwidth applications, ensure that the processor, memory, and vNIC are vertically aligned and remain within a single NUMA boundary.
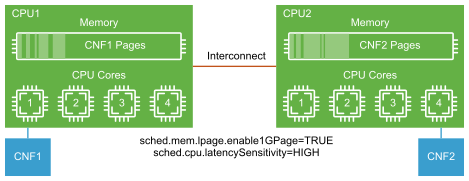
The topology manager is a new component in the Kubelet and provides NUMA awareness to Kubernetes at the pod admission time. The topology manager figures out the best locality of resources by pulling topology hints from the Device Manager and the CPU manager. Pods are then placed based on the topology information to ensure optimal performance.
Topology Manager is optional, if the NUMA placement best practices are followed during the Kubernetes cluster creation.
CPU Core Affinity: CPU pinning can be achieved in different ways. Kubernetes built-in CPU manager is the most common. The CPU manager implementation is based on cpuset. When a VM host initializes, host CPU resources are assigned to a shared CPU pool. All non-exclusive CPU containers run on the CPUs in the shared pool. When the Kubelet creates a container requesting a guaranteed CPU, CPUs for that container are removed from the shared pool and assigned exclusively for the life cycle of the container. When a container with exclusive CPUs is terminated, its CPUs are added back to the shared CPU pool.
The CPU manager includes the following two policies:
None: Default policy. The kubelet uses the CFS quota to enforce pod CPU limits. The workload can move between different CPU cores depending on the load on the Pod and the available capacity on the worker node.
Static: With the static policy enabled, the CPU request results in the container getting allocated the whole CPU and no other container can schedule on that CPU.
For data plane intensive workloads, the CPU manager policy must be set to static to guarantee an exclusive CPU core on the worker node.
CPU Manager for Kubernetes (CMK) is another tool used by selective CNF vendors to assign the core and NUMA affinity for data plane workloads. Unlike the built-in CPU manager, CMK is not bundled with Kubernetes binaries and it requires separate download and installation. CMK must be used over the built-in CPU manager if required by the CNF vendor.
Huge Pages: For Telco workloads, the default huge page size can be 2 MB or 1 GB. To report its huge page capacity, the worker node determines the supported huge page sizes by parsing the /sys/kernel/mm/hugepages/hugepages-{size}kB directory on the host. Huge pages must be set to pre-allocated for maximum performance. Pre-allocated huge pages reduce the amount of available memory on a worker node. A node can only pre-allocate huge pages for the default size. The Transport Huge Pages must be deactivated.
Container workloads requiring huge pages use hugepages-<hugepagesize> in the Pod specification. As of Kubernetes 1.18, multiple huge page sizes are supported per Pod. Huge Pages allocation occurs at the pod level.
Recommended tuning details:
Design Recommendation |
Design Justification |
Design Implication |
|---|---|---|
Three Control nodes per Kubernetes cluster to ensure full redundancy |
3-node cluster tolerates the loss of a single member |
|
Install and activate the PTP clock synchronization service |
Kubernetes and its components rely on the system clock to track events, logs, state, and so on. |
None |
Deactivate Swap on all Kubernetes Cluster Nodes. |
Swap causes a decrease in the overall performance of the cluster. |
None |
Vertically align Processor, memory, and vNIC and keep them within a single NUMA boundary for data plane intensive workloads. |
|
Requires an extra configuration step on the vCenter Server to ensure NUMA alignment. Note: This is not required for generic workloads such as web services, lightweight databases, monitoring dashboards, and so on. |
The CPU manager policy set to static for data plane intensive workloads. |
When the CPU manager is used for CPU affinity, the static mode is required to guarantee exclusive CPU cores on the worker node for data-intensive workloads. |
Requires an extra configuration step for CPU Manager through NodeConfig Operator. Note: This is not required for generic workloads such as web services, lightweight databases, monitoring dashboards, and so on. |
When enabling static CPU manager policy, set aside sufficient CPU resources for the kubelet operation. |
|
Note: This is not required for generic workloads such as web services, lightweight databases, monitoring dashboards, and so on. |
Enable huge page allocation at boot time. |
|
Note: This is not required for generic workloads such as web services, lightweight databases, monitoring dashboards, and so on. |
Set the default huge page size to 1 GB. Set the overcommit size to 0. |
|
For 1 GB pages, the huge page memory cannot be reserved after the system boot. Note: This is not required for generic workloads such as web services, lightweight databases, monitoring dashboards, and so on. |
Mount the file system type hugetlbfs on the root file system. |
|
Perform an extra configuration step in the worker node VM configuration. Note: This is not required for generic workloads such as web services, lightweight databases, monitoring dashboards, and so on. |
Storage Considerations for RAN
In Kubernetes, a Volume is a directory on a disk that is accessible to the containers inside a pod. Kubernetes supports many types of volumes. However, for the Telco Cloud Platform RAN deployment with a Regional Data Center and Cell Site location, follow these recommendations when configuring your storage.
Location |
Storage Type |
Justification |
Regional Data Center |
vSAN |
The vSphere cluster at Regional Data Center can have three or more ESXi hosts to support vSAN storage. |
Cell Site |
Local Storage |
The Cell Site vSphere Cluster may have a single host configuration, so the local disk is the primary choice. You can also use any NFS storage available locally. |
If vSAN storage is used in Regional Data Center (RDC), you must follow the vSAN storage policies.
vSAN storage policies define storage requirements for your StorageClass. Cloud Native Persistent Storage or Volume (PV) inherits performance and availability characteristics made available by the vSAN storage policy. These policies determine how the storage objects are provisioned and allocated within the datastore to guarantee the required level of service. Kubernetes StorageClass is a way for Kubernetes admins to describe the “classes” of storage available for a Tanzu Kubernetes cluster by the Cloud Admin. Different StorageClasses map to different vSAN storage policies.
For more information about Cloud Native Storage Design for 5G Core, see the Telco Cloud Platform 5G Edition Reference Architecture Guide 2.2.
