This section describes the procedure of creating an Enrichment stream.
Note: It is recommended that you edit and update the default Enrichment streams based on your Enrichment requirements instead of creating a new Enrichment stream.
Procedure
- Click Add.
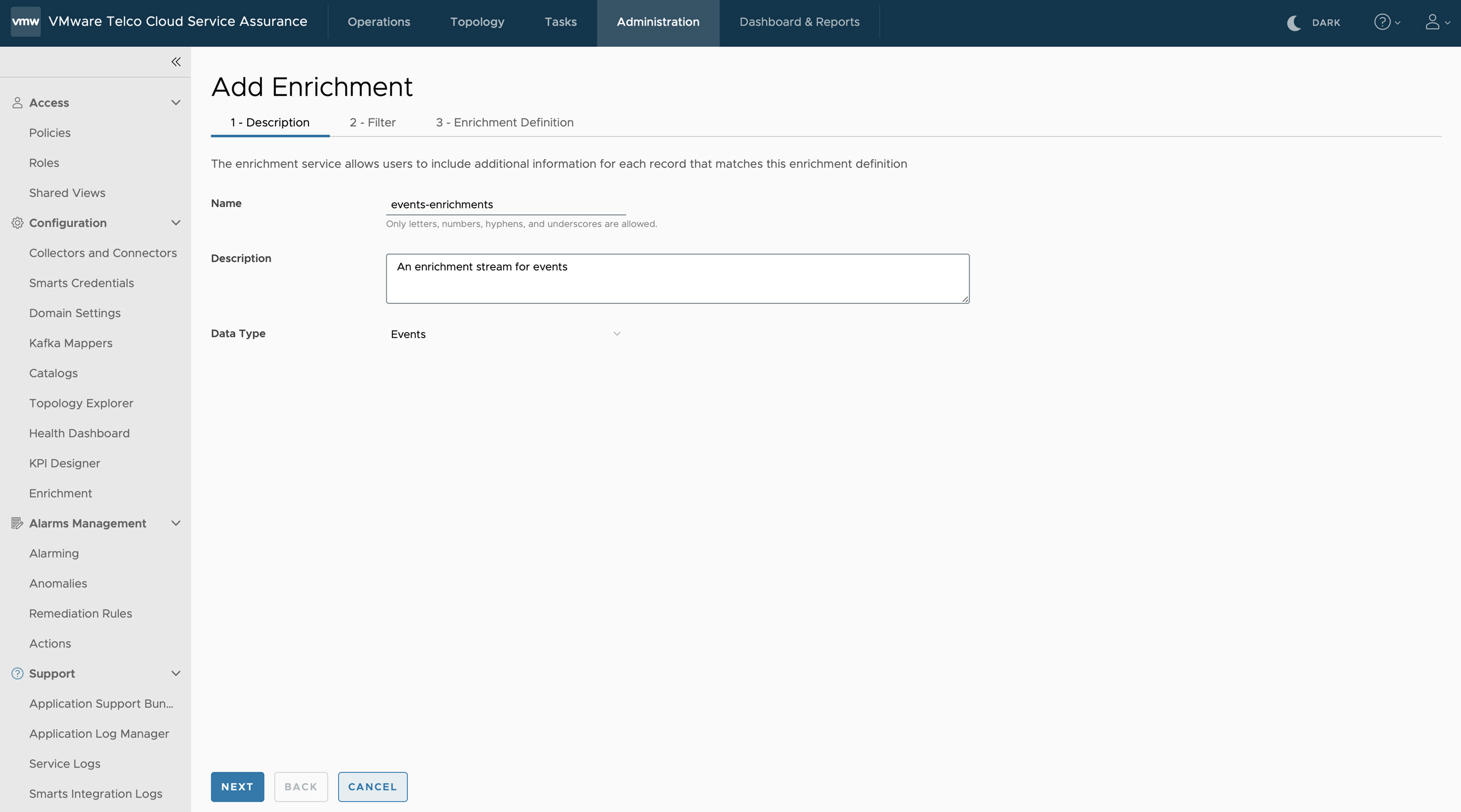
The browser navigates to the Add Enrichment page.Under the Description tab, enter the following parameters:
- Name: Required field. Configures the name of the Enrichment. Only letters, numbers, hyphens, and underscores are allowed.
- Description: Required field. Configures the description of the Enrichment. A double quote in the field will be escaped to a single quote.
- Data Type: Required field. Configures the data type of the VMware Telco Cloud Service Assurance record being enriched. Three types of records are supported. You can select only one record at a time.
- VMware Telco Cloud Service Assurance Event
- VMware Telco Cloud Service Assurance Metric
- VMware Telco Cloud Service Assurance Topology
- Under Filter, select the Property, Expression, and enter the Value for the Enrichment definition. The listed key properties are based on the selected data type such as Metrics, Events, or Topology.
- To add multiple filters within the same group, click Add Condition. The AND condition tag is used when you add filters within the same group.
- To add multiple filters, click Add Group. The OR condition tag is used when you add filters from different groups.
Note: While metrics and events Enrichment streams have filters, there is no filter available for the Topology stream. Under Description if you select the Data Type as Topology, the Filter tab disappears.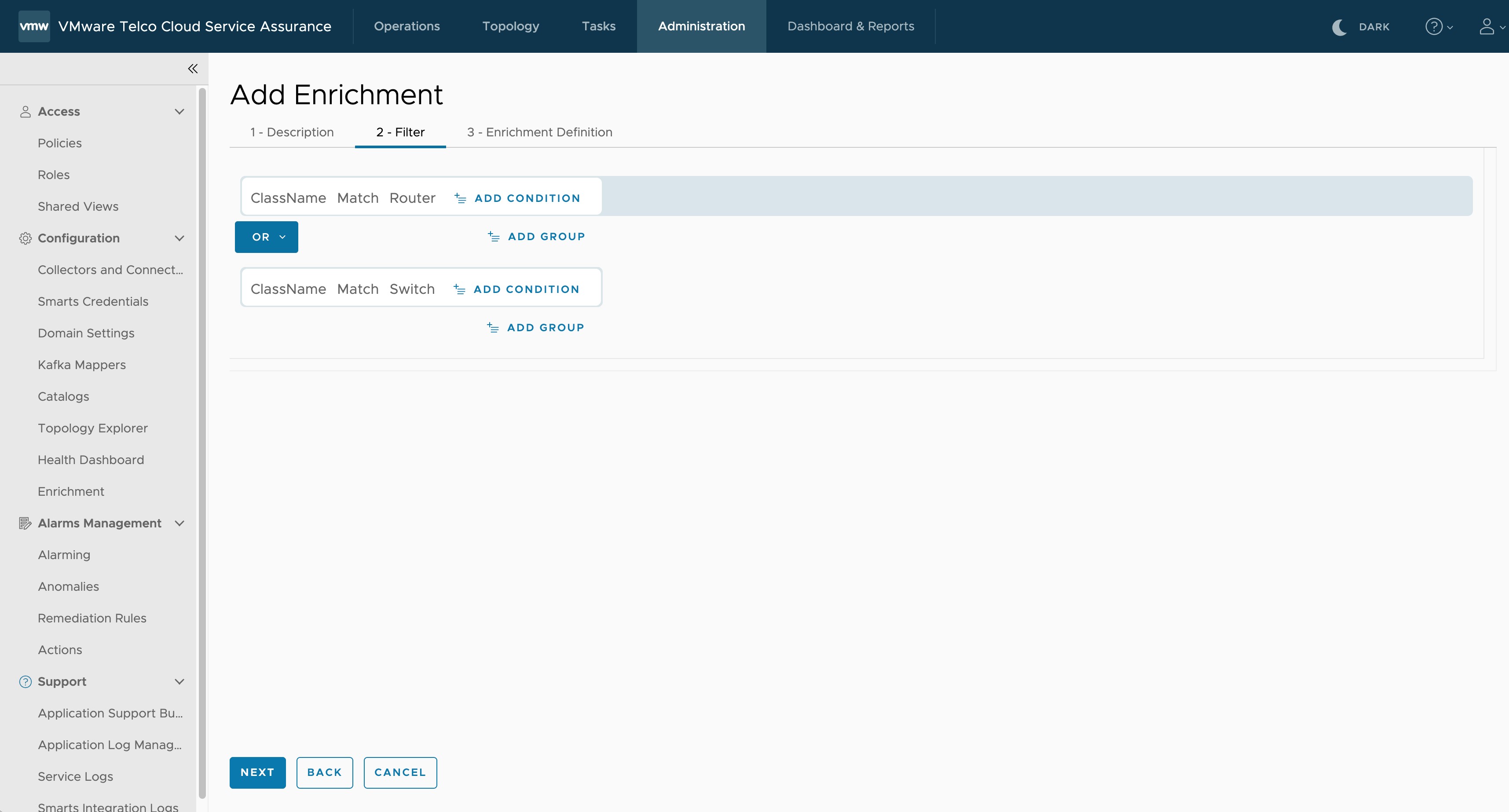
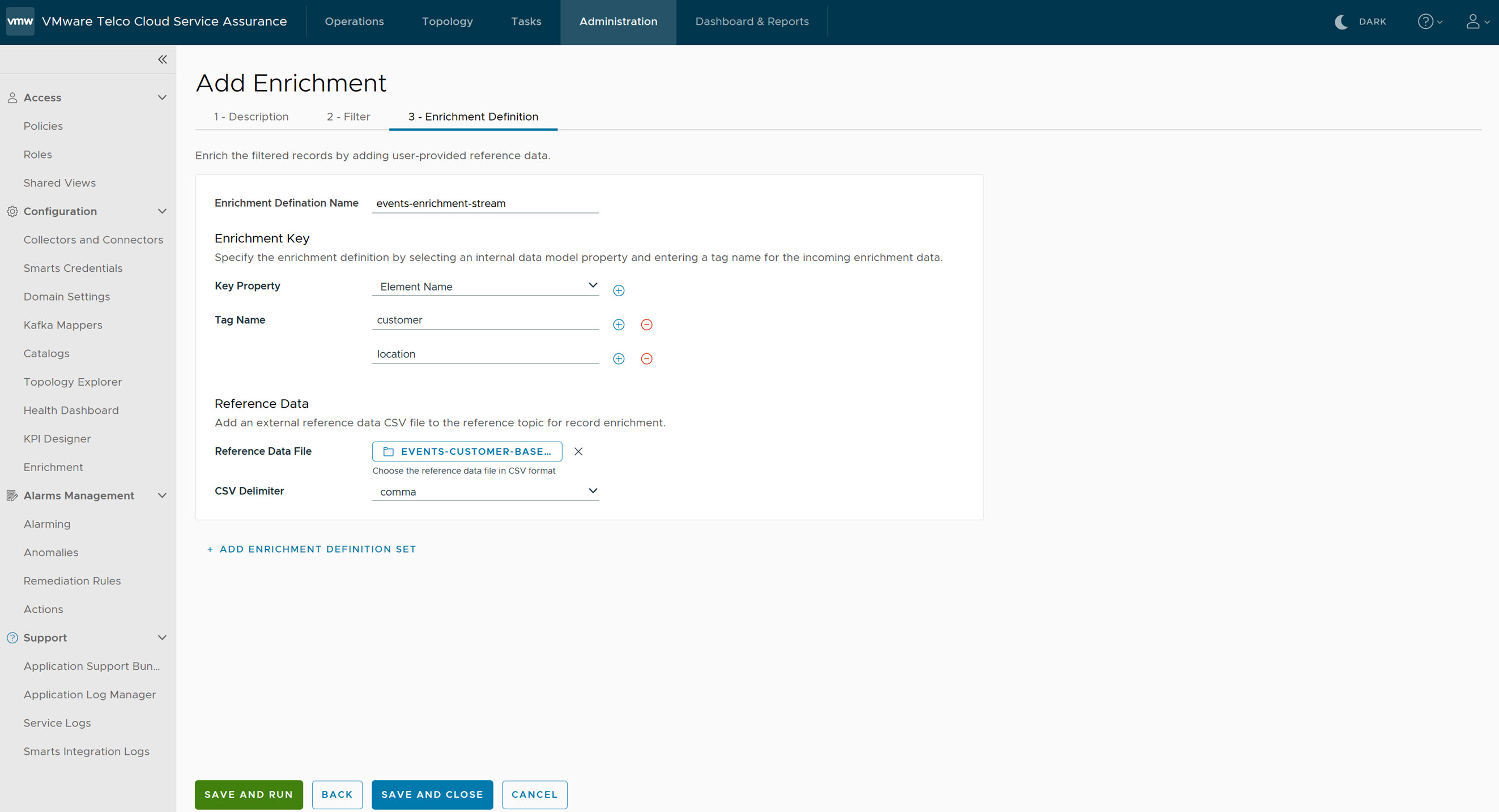
- Under Enrichment Definition tab, provide the following parameter details:
- Enrichment Definition Name: Required field. The name of the Enrichment definition. Atleast one Enrichment definition is required. To configure multiple Enrichments, click Add Enrichment Definition Set.
- In Enrichment Key, there are two fields to be configured:
- Key Property: Required field. Configures the key using the properties in the internal data model, which is used to match the corresponding external reference data key. The listed key properties are based on the selected data type such as Metrics, Events, or Topology. You can select multiple key properties.
- Tag Name: Required field. Provide a tag name for the Enrichment definition. You can add multiple tag names.
- In Reference Data, there are two fields to be configured:
- Reference Data File: Required field. Select the reference data file in CSV format. The file must have .csv as the file extension. The Enrichment uses the external reference data from the .csv file to enrich the VMware Telco Cloud Service Assurance records. Only letters, numbers, hyphens, underscores, and periods are allowed in the Reference Data File.
- CSV Delimiter: Required field. Select the delimiter type from the drop-down list. The default is comma.
Note:
- The reference data is not persisted. It is sent to the Kafka reference topic directly to be used by a running Enrichment stream. The reference data must be added again after the users stop and start the Enrichment.
- By default, the maximum file size is 10 MB, the admin can update the environment variable MAX_REFERENCE_DATA_SIZE and MAX_TOTAL_REFERENCE_DATA_SIZE of the Enrichment service to change the maximum file size.
The following table lists the supported Wild Card (regular expression) patterns for key properties in CSV reference data file.Patterns Description %text% Multiple character match: this is similar to checking any key that contains particular text. For example: %DIR%, any key that contains DIR is matched. text1_text2 Single character match: this is to check if any matching single character is present between text1 and text2. For example, Router-DI_, here matching key is Router-DIF or Router-DIZ or Router-DI2, any key which starts with Router-DI and ends with any single charcter after DI is matched. <NI-N2> Specify a range: this is to specify any number range. For example, 172.<16-31>.<0-255>.<0-255>. Here matching key is 172.18.220.176 and unmatching key is 172.14.255.224. Note: N1 must be less than N2.| (pipe) Pipe: this is to specify multiple matching fields within a key. For example: IP*-172.<16-31>.*|IP*-192.168.*|IP*-10.*|172.<16-31>.<0-255>.<0-255>|192.168.<0-255>.<0-255>|10.<0-255>.<0-255>.<0-255>,india
The example record has two fields, the first field is the datasource, and the second field is the location. In the following sample records, the key can be any of the following datasources.- IPv6-172.16.1.1
- IPv4-192.168.1.2
- IPv6-10.1.2.3
- 172.17.91.11
- 192.168.22.11
- 33.22.11.3
* (include all) For example: Router*DCP.