


| vCenter Server 8.0 Update 3a | 18 JUL 2024 | ISO Build 24091160 Check for additions and updates to these release notes. |







What's New
This release delivers critical bug fixes. For more information, see the Resolved Issues section.
Earlier Releases of vCenter Server 8.0
Features, resolved and known issues of vCenter Server are described in the release notes for each release. Release notes for earlier releases of vCenter Server 8.0 are:
For internationalization, compatibility, installation, upgrade, open source components and product support notices, see the VMware vSphere 8.0 Release Notes.
For more information on vCenter Server supported upgrade and migration paths, please refer to VMware knowledge base article 67077.
Patches Contained in This Release
Patch for VMware vCenter Server 8.0 Update 3a
Product Patch for vCenter Server containing VMware software fixes.
This patch is applicable to vCenter Server.
| Download Filename |
VMware-vCenter-Server-Appliance-8.0.3.00100-24091160-patch-FP.iso |
| Build |
24091160 |
| Download Size |
8507.3 MB |
| sha256checksum |
2b65ce11d3d56a1acba21e52d89202ed51b33f6a5bc24381c425f92e8445a85f |
Download and Installation
Log in to the Broadcom Support Portal to download this patch.
For download instructions, see Download Broadcom products and software.
-
Attach the
VMware-vCenter-Server-Appliance-8.0.3.00100-24091160-patch-FP.isofile to the vCenter Server CD or DVD drive. -
Log in to the appliance shell as a user with super administrative privileges (for example, root) and run the following commands:
-
To stage the ISO:
software-packages stage --iso -
To see the staged content:
software-packages list --staged -
To install the staged rpms:
software-packages install --staged
-
For more information on using the vCenter Server shells, see VMware knowledge base article 2100508.
For more information on patching vCenter Server, see Patching and Updating vCenter Server 8.0 Deployments.
For more information on staging patches, see Upgrading the vCenter Server Appliance.
Resolved Issues
Installation, Upgrade, and Migration Issues
-
PR 3406386: Updates to vCenter 8.0 Update 3 might fail due to unnecessary certificates in the VMware Endpoint Certificate Store (VECS)
Due to a rare issue with VECS certificates that are no longer necessary, updates to vCenter 8.0 Update 3 might fail with an error such as
Pre-install failed for vmidentity:Expandin the vSphere Client. In the/var/log/vmware/applmgmt/Patchrunner.log, you see messages such as:2024-07-08T11:06:39.692Z vmidentity:Expand ERROR vmidentity Something went wrong while reading certs from TRUSTED_ROOTS or deleting ssoserver cert:This issue is resolved in this release.
-
PR 3408378: If you do not open port 9087 in your firewall between ESXi hosts and vCenter, compliance checks and vSphere HA might fail after vCenter update to 8.0 Update 3
Starting from 8.0 Update 3, the vSphere Lifecycle Manager downloads updates for ESXi hosts by a HTTPS connection to the vCenter instance on port 9087. If you do not open port 9087 in your firewall between ESXi hosts and vCenter, you might see compliance check errors. For example, in the
lifecycle.logyou see messages such as:<Timestamp> In(14) lifecycle[2112988]: Downloader:373 Opening https://<VC-FQDN>:9087/vum/repository/hostupdate/__micro-depot__vendor-DEL__DEL-ESXi-8.0-Addon-cumulative_metadata__index__.xml for download<Timestamp> Wa(12) lifecycle[2112988]: Downloader:210 Download failed: <urlopen error timed out>, 9 retry left...In addition, after updating vCenter to 8.0 Update 3, vSphere HA might fail to start on all ESXi hosts with messages such as:
An error occurred when vCenter Server attempted to initialize the vSphere HA Agent running on the host.HA Agent Unreachable - The vSphere HA Agent on the host cannot be reached.Cannot complete the configuration of the vSphere HA agent on the host. Applying HA VIBs on the cluster encountered failure.A general system error occurred: Installing HA components failed on the cluster: domain-<ID>.Cannot find vSphere HA master agent.This issue is resolved in this release. The fix restores functionality on port 9084.
Known Issues
Installation, Upgrade, and Migration Issues
-
Update to vCenter 8.0 Update 3 might fail at 95% with the error "Exception occured in postInstallHook for wcp:Patch"
If the roles
CNS-DatastoreorCNS-SEARCH-AND-SPBMalready exist in your vCenter system, during the PostInstallHook phase of an update to vCenter 8.0 Update 3, the process might try to recreate the roles, which causes a conflict and stops the update.In the
Patchrunner.log, you see an error such as:Failed to apply patch roles_groups_users! Error: Role CNS-Datastore (id: 1090) not found in VCandException occured in postInstallHook for wcp:Patch.Workaround: See KB 371524.
-
Upgrades from ESXi 7.0.x and 8.0.x might fail because the upgrade prechecks report that a vFAT partition was not unmounted
Starting with vSphere 8.0 Update 3, the upgrade precheck includes a vFAT partition validation step, dosfsck, because corrupted vFAT partitions might lead to unexpected behavior. This issue is specific to ESXi hosts, where another OS than ESXi has mounted the vFAT partitions and adds a bit that ESXi does not use. As a result of the check, in the vSphere Client you see an error such as
A problem with one or more vFAT bootbank partitions was detected. Please refer to KB 91136 and run dosfsck on bootbank partitions.Workaround: To remove the unnecessary bit, follow the steps in KB 345227.
-
If the vCenter certificate mode is set to thumbprint, vSphere HA clusters might fail to configure after update to vCenter 8.0 Update 3
If for some reason the advanced setting
vpxd.certmgmt.modein a vCenter instance is set tothumbprint, which is recommended only as a fallback option, the primary vSphere HA host might remain active but other vSphere HA clusters fail to configure after update to vCenter 8.0 Update 3.In the
fdm.log, you see messages such as:Failed to SSL handshake; SSL(<io_obj p:0x0000002e86fda5f0, h:30, <TCP '10.10.10.10 : 8111'>, <TCP '10.10.10.11 : 11911'>>), e: 167773208(tlsv1 alert unknown ca (SSL routines)), duration: 5msec or Er(163) Fdm[1151234]:--> The remote host certificate has these problems: Er(163) Fdm[1151234]: --> Er(163) Fdm[1151234]: --> * unable to get local issuer certificate)Workaround: Change the vpxd certificate mode to
vmcaorcustom, depending on your environment. For more information, see Change the ESXi Certificate Mode and KB 372329.
Known Issues from Previous Releases
- Installation, Upgrade, and Migration Issues
- Miscellaneous Issues
- Networking Issues
- Storage Issues
- vCenter Server and vSphere Client Issues
- Virtual Machine Management Issues
- vSphere Lifecycle Manager Issues
- VMware Host Client Issues
- Security Features Issues
- vSphere Cluster Service Issues
Installation, Upgrade, and Migration Issues
-
You see a security warning for the ESX Agent Manager configuration during the pre-check phase of a vCenter upgrade
During the pre-check phase of a vCenter update or upgrade, in the vSphere Client and logs, you might see an error such as:
Source ESX Agent Manager Configuration contains URLs that are not trusted by the System! Please refer to https://kb.vmware.com/s/article/93526 to trust the URLs: <LIST_OF_URLs>Or
Source vSphere ESX Agent Manager (EAM) upgrade failed to obtain EAM URLs to check against trusted certificates by the System! Verify that the ESX Agent Manager extension is running properly on the source vCenter Server instance and https://VC_IP/eam/mob presents correct data. If log in to the MOB is not successful, try resolving the issue with https://kb.vmware.com/s/article/94934. -
In a mixed vSphere 7.x and 8.x environment with vSphere DRS, an incompatible virtual machine might prevent an ESXi host to enter maintenance mode
In a mixed vSphere 7.x and 8.x environment with DRS, a VM of 7.x version that is not compatible with ESXi 8.0 Update 1 and later might prevent an ESXi 8.0 Update 1 host to enter maintenance mode. The issue is specific for virtual machines with VMDK on a vSphere Virtual Volumes datastore. In the vSphere Client, you see an error such as Waiting for all VMs to be powered off or suspended or migrated. In a DRS cluster check the Faults page on the DRS tab for troubleshooting.
Workaround: Power-off the incompatible virtual machine.
-
vSphere Lifecycle Manager baseline check compliance fails on ESXi hosts of version 7.0 GA in a vCenter 8.0 Update 3 system
Due to a limitation of the
esxupdatememory resource pool on 7.0 GA ESXi hosts, a vSphere Lifecycle Manager baseline check compliance scan might fail on 7.0 GA ESXi host in a vCenter 8.0 Update 3 system with error such asThe host returns esxupdate error codes: -1.The host
esxupdate.logcontains an error such as:<Timestamp> esxupdate: <PID>: esxupdate: ERROR: vmware.runcommand.RunCommandError:Error running command '['/sbin/smbiosDump']': [Errno 12] Cannot allocate memoryThe
vmkernel.logcontains error such as:<Timestamp> cpu0:<PID>)Admission failure in path: host/vim/vmvisor/esxupdate/python.<PID>:python.<PID>:uw.<PID>This issue is specific for 7.0 GA ESXi hosts, as
esxupdatememory allocation is increased in 7.0 Update 1 and later.Workaround: Use an ISO upgrade baseline to upgrade the 7.0 GA ESXi hosts to a 8.x version or revert the vCenter system back to version 7.0 and upgrade the hosts to a version of 7.0 Update 1 and later.
-
You see an error Failed to get ceip status in the Virtual Appliance Management Interface (VAMI) during update to vCenter Server 8.0 Update 1
During an update, vCenter stops and restarts the VMDir service and within this interval, if you try to log in to the VAMI, you might see an error such as Failed to get ceip status. This is expected and does not indicate an actual issue with the vCenter system.
Workaround: Wait for the VMDir service to restart and refresh the Virtual Appliance Management Interface.
-
If you click NEXT before the progress bar reaches 100% in a vCenter Server Lifecycle Manager plug-in upgrade, the Server Lifecycle Manager service fails
In the Upgrade Plug-in step of the vCenter Server Lifecycle Manager plug-in upgrade wizard, if you click NEXT before the progress bar reaches 100%, the Server Lifecycle Manager service fails.
Workaround: Wait for the progress bar to reach 100% before you click NEXT.
-
vCenter upgrade or update to 8.0 Update 2a or later fails during precheck with the error "VMCA root certificate validation failed"
If your vCenter system has a legacy VMCA root certificate dating back to version 5.x which does not have the Subject Key Identifier (SKID) extension, upgrades and updates to vCenter 8.0 Update 2 and later fail because the OpenSSL version 3.0 in 8.0 Update 2 is not compatible with legacy root certificates. vCenter Server 8.0 Update 2a adds a precheck to detect this issue and shows the error message VMCA root certificate validation failed if the source vCenter has VMCA root certificate without SKID.
Workaround: Regenerate a VMCA root certificate by following the steps in VMware knowledge base article 94840.
-
You see a "vc.health.error.dbjob3" warning after a vCenter upgrade
In the vSphere Client or the in Virtual Appliance Management Interface, you might see the warning
vc.health.error.dbjob3after a vCenter upgrade although the vCenter overall health status is green. This issue does not affect vCenter operations, it can only affect historical statistics when some data does not roll up for more than 72 hours.Workaround: See Delete old tasks, events and statistics data in vCenter Server 5.x, 6.x, 7.x and 8.x how to clear stats data, if not relevant anymore.
-
A reduced downtime upgrade (RDU) on a vCenter system might fail when you use Update Planner
During RDU, if you use Update Planner, in the vSphere Client you might see an error such as:
Update 8.0.2.00000 for component vlcm is not found. -
Update to vCenter 8.0 Update 3 might fail with an error "Destination path '/storage/analytics/stage/...' already exists"
Starting with vCenter 8.0 Update 3, the analytics service stores telemetry log files in a new directory.
In rare cases, if previous update attempts had failed and reverted, when patching to vCenter 8.0 Update 3, the attempt to copy the telemetry log files to the new location might fail because these files already exist from a prior patching attempt. In the
patchrunner.logfile, you see an error such asDestination path '/storage/analytics/stage/XXXXXX_processed_logs' already exists.Workaround: Delete all files under
/storage/log/vmware/analytics/stage,/storage/log/vmware/analytics/prod,/storage/analytics/stage, and/storage/analytics/prod, and retry the update. -
Failed parallel remediation by using vSphere Lifecycle Manager on one ESXi host might cause other hosts to remain in a pending reboot state
An accidental loss of network connectivity during a parallel remediation by using vSphere Lifecycle Manager might cause the operation to fail on one of the ESXi hosts. Remediation on other hosts continues, but the hosts cannot reboot to complete the task.
Workaround: If an ESXi host consistently fails remediation attempts, manually trigger a reboot. For more information, see VMware knowledge base article 91260.
-
You see a security warning for the ESX Agent Manager configuration during the pre-check phase of a vCenter upgrade
During the pre-check phase of a vCenter update or upgrade, in the vSphere Client and logs, you might see an error such as:
Source ESX Agent Manager Configuration contains URLs that are not trusted by the System! Verify following URLs and their respective statuses and follow KB 93526.Workaround: For more information, see VMware knowledge base article 93526.
-
Firmware compliance details are missing from a vSphere Lifecycle Manager image compliance report for an ESXi standalone host
Firmware compliance details might be missing from a vSphere Lifecycle Manager image compliance report for an ESXi standalone host in two cases:
-
You run a compliance report against a standalone host managed with a vSphere Lifecycle Manager image from vSphere Client and then navigate away before the compliance report gets generated.
-
You trigger a page refresh after the image compliance reports are generated.
In such cases, even when you have the firmware package available in the Desired State, the firmware compliance section remains empty when you revisit or refresh the vSphere Client browsing session. If you use GET image compliance API, then firmware compliance details are missing from the response.
Workaround: Invoke the image compliance scan for a standalone host managed with a vSphere Lifecycle Manager image by using the vSphere Client and do not navigate away or refresh the browser. For API, use the Check image compliance API for fetching the firmware details as apposed to GET image compliance.
-
-
You see vCenter update status as failed although it completes successfully
A rare race condition might cause vCenter to report a successful update as failed. The issue occurs if during vCenter reboot
/storage/coreunmounts before the system acknowledges the Installation complete status. As a result, the update fails with an error such asNo such file or directory: '/storage/core/software-update/install_operation'. In thesoftware-packages.logs, you see errors such as:2023-08-17T10:57:59.229 [15033]DEBUG:vmware.appliance.update.update_state:In State._get using state file /etc/applmgmt/appliance/software_update_state.conf2023-08-17T10:57:59.229 [15033]INFO:vmware.appliance.update.update_state:Found operation in progress /storage/core/software-update/install_operation2023-08-17T10:57:59.229 [15033]ERROR:vmware.appliance.update.update_functions:Can't read JSON file /storage/core/software-update/install_operation [Errno 2] No such file or directory: '/storage/core/software-update/install_operation'2023-08-17T10:57:59.229 [15033]DEBUG:vmware.appliance.update.update_state:Operation in progress is orphaned2023-08-17T10:57:59.229 [15033]DEBUG:vmware.appliance.update.update_state:Operation in progress is finished2023-08-17T10:57:59.229 [15033]DEBUG:vmware.appliance.update.update_state:Writing to state file from State._get2023-08-17T10:57:59.229 [15033]DEBUG:vmware.appliance.update.update_state:In State._writeInfo writing to state file /etc/applmgmt/appliance/software_update_state.conf2023-08-17T10:57:59.229 [15033]INFO:vmware.vherd.base.software_update:Installation failed. Please collect the VC support bundle.Workaround: Check if vCenter restarts successfully and the vCenter health status is green, and ignore the failure report.
-
Patching to vCenter 8.0 Update 2 fails in IPv6 environments with no DNS server and hostname
When you update your vCenter system to 8.0 Update 2 from an earlier version of 8.x, if your system uses an IPv6 network without a hostname, such as PNID, and a DNS server, in the VMware Appliance Management Interface you might see an error such as
Data conversion/Post install hook failed.Workaround: Manually update the
/etc/hostsfile with the missing IPv6 loopback entry:::1 localhost ipv6-localhost ipv6-loopbackand reboot the system.See this example:
root@localhost []# cat /etc/hosts# Begin /etc/hosts(network card version)127.0.0.1 localhost.localdomain127.0.0.1 localhost::1 localhost ipv6-localhost ipv6-loopback -
If you apply a host profile using a software FCoE configuration to an ESXi 8.0 host, the operation fails with a validation error
Starting from vSphere 7.0, software FCoE is deprecated, and in vSphere 8.0 software FCoE profiles are not supported. If you try to apply a host profile from an earlier version to an ESXi 8.0 host, for example to edit the host customization, the operation fails. In the vSphere Client, you see an error such as
Host Customizations validation error.Workaround: Disable the Software FCoE Configuration subprofile in the host profile.
-
During a reduced downtime upgrade (RDU), when configuring Target VM network settings, you see no network portgroups
In very rare cases, during a reduced downtime upgrade of a single self-managed vCenter instance that uses a migration-based method, when a source vCenter VM has thin disk provisioning and the target vCenter cluster does not have enough storage to accommodate the required space for the default thick disk mode selected by the validation process, you might see no network portgroups in the Target VM deployment wizard. In the vSphere Client, if you select Same Configuration in the Deployment type step of the Target VM deployment wizard, you see an empty error message in the Network Settings screen and no portgroups available.
Workaround: In the Deployment type step of the Target VM deployment wizard, select Detailed Configuration.
-
You cannot use ESXi hosts of version 8.0 as a reference host for existing host profiles of earlier ESXi versions
Validation of existing host profiles for ESXi versions 7.x, 6.7.x and 6.5.x fails when only an 8.0 reference host is available in the inventory.
Workaround: Make sure you have a reference host of the respective version in the inventory. For example, use an ESXi 7.0 Update 2 reference host to update or edit an ESXi 7.0 Update 2 host profile.
-
URL-based patching or file-based backup of vCenter 8.0 Update 2 might fail due to OpenSSL noncompliance to Federal Information Processing Standards (FIPS)
With vCenter 8.0 Update 2, OpenSSL works only with Diffie-Hellman parameters compliant to NIST SP 800-56A and FIPS 140-2. For URL-based patching or file-based backup of vCenter 8.0 Update 2 systems, FTPS servers in your environment must support the following ciphers:
OpenSSL Cipher Suite
Name AT-TLS Cipher Suite Name
Hexadecimal Value
DHE-RSA-AES256-SHA
TLS_DHE_RSA_WITH_AES_256_CBC_SHA
39
DHE-DSS-AES256-SHA
TLS_DHE_DSS_WITH_AES_256_CBC_SHA
38
AES256-SHA
TLS_RSA_WITH_AES_256_CBC_SHA
35
EDH-RSA-DES-CBC3-SHA
TLS_DHE_RSA_WITH_3DES_EDE_CBC_SHA
16
EDH-DSS-DES-CBC3-SHA
TLS_DHE_DSS_WITH_3DES_EDE_CBC_SHA
13
DES-CBC3-SHA
TLS_RSA_WITH_3DES_EDE_CBC_SHA
0A
DHE-RSA-AES128-SHA
TLS_DHE_RSA_WITH_AES_128_CBC_SHA
33
DHE-DSS-AES128-SHA
TLS_DHE_DSS_WITH_AES_128_CBC_SHA
32
AES128-SHA
TLS_RSA_WITH_AES_128_CBC_SHA
2F
Workaround: Make sure your file servers are FIPS compliant.
-
VMNICs might be down after an upgrade to ESXi 8.0
If the peer physical switch of a VMNIC does not support Media Auto Detect, or Media Auto Detect is disabled, and the VMNIC link is set down and then up, the link remains down after upgrade to or installation of ESXi 8.0.
Workaround: Use either of these 2 options:
-
Enable the option
media-auto-detectin the BIOS settings by navigating to System Setup Main Menu, usually by pressing F2 or opening a virtual console, and then Device Settings > <specific broadcom NIC> > Device Configuration Menu > Media Auto Detect. Reboot the host. -
Alternatively, use an ESXCLI command similar to:
esxcli network nic set -S <your speed> -D full -n <your nic>. With this option, you also set a fixed speed to the link, and it does not require a reboot.
-
-
After upgrade to ESXi 8.0, you might lose some nmlx5_core driver module settings due to obsolete parameters
Some module parameters for the
nmlx5_coredriver, such asdevice_rss,drssandrss, are deprecated in ESXi 8.0 and any custom values, different from the default values, are not kept after an upgrade to ESXi 8.0.Workaround: Replace the values of the
device_rss,drssandrssparameters as follows:-
device_rss: Use theDRSSparameter. -
drss: Use theDRSSparameter. -
rss: Use theRSSparameter.
-
-
Second stage of vCenter Server restore procedure freezes at 90%
When you use the vCenter Server GUI installer or the vCenter Server Appliance Management Interface (VAMI) to restore a vCenter from a file-based backup, the restore workflow might freeze at 90% with an error
401 Unable to authenticate user, even though the task completes successfully in the backend. The issue occurs if the deployed machine has a different time than the NTP server, which requires a time sync. As a result of the time sync, clock skew might fail the running session of the GUI or VAMI.Workaround: If you use the GUI installer, you can get the restore status by using the
restore.job.getcommand from theapplianceshshell. If you use VAMI, refresh your browser.
Miscellaneous Issues
-
In Hybrid Linked Mode, the cloud vCenter is not able to discover plug-ins deployed on an on-prem vCenter
Hybrid Linked Mode allows you to link your cloud vCenter Server instance with an on-premises vCenter Single Sign-On domain, but the cloud vCenter might not be able to discover plug-ins deployed on the on-prem instance because it does not have the necessary permissions.
Workaround: Install the vCenter Cloud Gateway in your on-premises environment and either browse the plug-ins deployed on the on-prem instance from the VMware Cloud Console or directly from the vSphere Client on the on-prem vCenter.
-
In a vCenter Server system with DPUs, if IPv6 is disabled, you cannot manage DPUs
Although the vSphere Client allows the operation, if you disable IPv6 on an ESXi host with DPUs, you cannot use the DPUs, because the internal communication between the host and the devices depends on IPv6. The issue affects only ESXi hosts with DPUs.
Workaround: Make sure IPv6 is enabled on ESXi hosts with DPUs.
-
You cannot customize firewall rule configuration with the option 'Only allow connections from the following networks' on ESXi hosts
Starting with vSphere 8.0 Update 2, you cannot customize firewall rule configuration with the option Only allow connections from the following networks on ESXi hosts. For example, in the VMware Host Client, when you navigate to Networking > Firewall rules, select DHCP client, provide an IP and check Only allow connections from the following networks, the operation fails with an error such as
Operation failed, diagnostics report: Invalid operation requested: Can not change allowed ip list this ruleset, it is owned by system service.. This is expected behavior.Workaround: None
-
You might see 10 min delay in rebooting an ESXi host on HPE server with pre-installed Pensando DPU
In rare cases, HPE servers with pre-installed Pensando DPU might take more than 10 minutes to reboot in case of a failure of the DPU. As a result, ESXi hosts might fail with a purple diagnostic screen and the default wait time is 10 minutes.
Workaround: None.
-
If you have an USB interface enabled in a remote management application that you use to install ESXi 8.0, you see an additional standard switch vSwitchBMC with uplink vusb0
Starting with vSphere 8.0, in both Integrated Dell Remote Access Controller (iDRAC) and HP Integrated Lights Out (ILO), when you have an USB interface enabled, vUSB or vNIC respectively, an additional standard switch
vSwitchBMCwith uplinkvusb0gets created on the ESXi host. This is expected, in view of the introduction of data processing units (DPUs) on some servers but might cause the VMware Cloud Foundation Bring-Up process to fail.Workaround: Before vSphere 8.0 installation, disable the USB interface in the remote management application that you use by following vendor documentation.
After vSphere 8.0 installation, use the ESXCLI command
esxcfg-advcfg -s 0 /Net/BMCNetworkEnableto prevent the creation of a virtual switchvSwitchBMCand associated portgroups on the next reboot of host.See this script as an example:
~# esxcfg-advcfg -s 0 /Net/BMCNetworkEnableThe value of BMCNetworkEnable is 0 and the service is disabled.
~# rebootOn host reboot, no virtual switch, PortGroup and VMKNIC are created in the host related to remote management application network.
-
If an NVIDIA BlueField DPU is in hardware offload mode disabled, virtual machines with configured SR-IOV virtual function cannot power on
NVIDIA BlueField DPUs must be in hardware offload mode enabled to allow virtual machines with configured SR-IOV virtual function to power on and operate.
Workaround: Always use the default hardware offload mode enabled for NVIDIA BlueField DPUs when you have VMs with configured SR-IOV virtual function connected to a virtual switch.
-
In the Virtual Appliance Management Interface (VAMI), you see a warning message during the pre-upgrade stage
Moving vSphere plug-ins to a remote plug-in architecture, vSphere 8.0 deprecates support for local plug-ins. If your 8.0 vSphere environment has local plug-ins, some breaking changes for such plug-ins might cause the pre-upgrade check by using VAMI to fail.
In the Pre-Update Check Results screen, you see an error such as:
Warning message: The compatibility of plug-in package(s) %s with the new vCenter Server version cannot be validated. They may not function properly after vCenter Server upgrade.Resolution: Please contact the plug-in vendor and make sure the package is compatible with the new vCenter Server version.Workaround: Refer to the VMware Compatibility Guide and VMware Product Interoperability Matrix or contact the plug-in vendors for recommendations to make sure local plug-ins in your environment are compatible with vCenter Server 8.0 before you continue with the upgrade. For more information, see the blog Deprecating the Local Plugins :- The Next Step in vSphere Client Extensibility Evolution and VMware knowledge base article 87880.
Networking Issues
-
Overlapping hot-add and hot-remove operations for DirectPath I/O devices might fail
With vSphere 8.0 Update 1, by using vSphere API you can add or remove a DirectPath I/O device without powering off VMs. However, if you run several operations at the same time, some of the overlapping tasks might fail.
Workaround: Plan for 20 seconds processing time between each hot-add or hot-remove operation for DirectPath I/O devices.
-
Hot adding and removing of DirectPath I/O devices is not automatically enabled on virtual machines
With vSphere 8.0 Update 1, by using vSphere API you can add or remove a DirectPath I/O device without powering off VMs. When you enable the hotplug functionality that allows you to hot add and remove DirectPath I/O devices to a VM, if you use such a VM to create an OVF and deploy a new VM, the new VM might not have the hotplug functionality automatically enabled.
Workaround: Enable the hotplug functionality as described in Hot-add and Hot-remove support for VMDirectPath I/O Devices.
-
You cannot set the Maximum Transmission Unit (MTU) on a VMware vSphere Distributed Switch to a value larger than 9174 on a Pensando DPU
If you have the vSphere Distributed Services Engine feature with a Pensando DPU enabled on your ESXi 8.0 system, you cannot set the Maximum Transmission Unit (MTU) on a vSphere Distributed Switch to a value larger than 9174.
Workaround: None.
-
You see link flapping on NICs that use the ntg3 driver of version 4.1.3 and later
When two NICs that use the
ntg3driver of versions 4.1.3 and later are connected directly, not to a physical switch port, link flapping might occur. The issue does not occur onntg3drivers of versions earlier than 4.1.3 or thetg3driver. This issue is not related to the occasional Energy Efficient Ethernet (EEE) link flapping on such NICs. The fix for the EEE issue is to use antg3driver of version 4.1.7 or later, or disable EEE on physical switch ports.Workaround: Upgrade the
ntg3driver to version 4.1.8 and set the new module parameternoPhyStateSetto1. ThenoPhyStateSetparameter defaults to0and is not required in most environments, except they face the issue. -
You cannot use Mellanox ConnectX-5, ConnectX-6 cards Model 1 Level 2 and Model 2 for Enhanced Network Stack (ENS) mode in vSphere 8.0
Due to hardware limitations, Model 1 Level 2, and Model 2 for Enhanced Network Stack (ENS) mode in vSphere 8.0 is not supported in ConnectX-5 and ConnectX-6 adapter cards.
Workaround: Use Mellanox ConnectX-6 Lx and ConnectX-6 Dx or later cards that support ENS Model 1 Level 2, and Model 2A.
-
Pensando DPUs do not support Link Layer Discovery Protocol (LLDP) on physical switch ports of ESXi hosts
When you enable LLDP on an ESXi host with a DPU, the host cannot receive LLDP packets.
Workaround: None.
Storage Issues
-
VASA API version does not automatically refresh after upgrade to vCenter Server 8.0
vCenter Server 8.0 supports VASA API version 4.0. However, after you upgrade your vCenter Server system to version 8.0, the VASA API version might not automatically change to 4.0. You see the issue in 2 cases:
-
If a VASA provider that supports VASA API version 4.0 is registered with a previous version of VMware vCenter, the VASA API version remains unchanged after you upgrade to VMware vCenter 8.0. For example, if you upgrade a VMware vCenter system of version 7.x with a registered VASA provider that supports both VASA API versions 3.5 and 4.0, the VASA API version does not automatically change to 4.0, even though the VASA provider supports VASA API version 4.0. After the upgrade, when you navigate to vCenter Server > Configure > Storage Providers and expand the General tab of the registered VASA provider, you still see VASA API version 3.5.
-
If you register a VASA provider that supports VASA API version 3.5 with a VMware vCenter 8.0 system and upgrade the VASA API version to 4.0, even after the upgrade, you still see VASA API version 3.5.
Workaround: Unregister and re-register the VASA provider on the VMware vCenter 8.0 system.
-
-
Migration of a First Class Disk (FCD) might fail and the FCD remains in a tentative state
In certain scenarios, when you migrate a FCD to another datastore by invoking the
RelocateVStorageObjectAPI, the operation might intermittently fail and the FCD remains in a tentative state. As a result, you cannot complete any other operation on the FCD. For example, if you try another migration, in the backlog you see the errorcom.vmware.vim.fcd.error.fcdAlreadyInTentativeState.Workaround: Reconcile the source datastore of the FCD by following the steps described in VMware knowledge base article 2147750.
-
vSphere Storage vMotion operations might fail in a vSAN environment due to an unauthenticated session of the Network File Copy (NFC) manager
Migrations to a vSAN datastore by using vSphere Storage vMotion of virtual machines that have at least one snapshot and more than one virtual disk with different storage policy might fail. The issue occurs due to an unauthenticated session of the NFC manager because the Simple Object Access Protocol (SOAP) body exceeds the allowed size.
Workaround: First migrate the VM home namespace and just one of the virtual disks. After the operation completes, perform a disk only migration of the remaining 2 disks.
vCenter Server and vSphere Client Issues
-
You see overlapped labels for parameters in the Edit VM Startup/Shutdown Configuration dialog box
In the vSphere Client, when you select an ESXi host and click Configure > Virtual Machines > VM Startup/Shutdown > Edit, you see overlapped labels for some parameters in the Edit VM Startup/Shutdown Configuration dialog box that opens. The overlapped labels are as follows:
-
System influence: labels the checkbox Automatically start and stop the virtual machines with the system.
-
Startup delay: numeric value that specifies the delay time that a host waits before powering on the next virtual machine in automatic startup configuration.
-
Shutdown delay: numeric value that defines the maximum time the ESXi host waits for a shutdown command to complete, and the option Continue if VMware Tools is started.
-
Shutdown action: such as Guest Shutdown, Power Off, Suspend, and None.
Workaround: None. See the screenshot to figure out the sequence of labels:
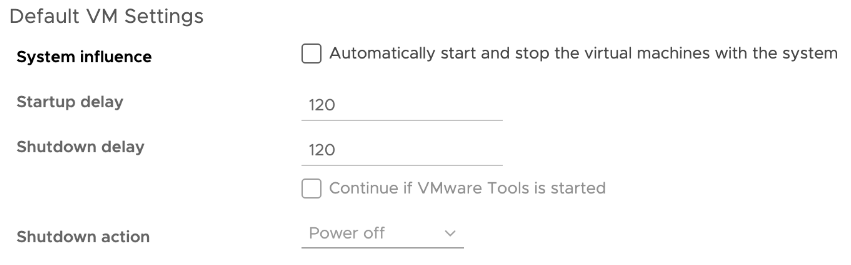
-
-
When you move a standalone ESXi host back to a cluster that you manage with vSphere Lifecycle Manager images, you might see an error in the vSphere Client
If you move out an ESXi host from a cluster that you manage with vSphere Lifecycle Manager images, it becomes a standalone host that is connected to a vCenter Server instance but is not part of any cluster. If you move such a host back to a cluster, in the Updates tab of the vSphere Client you might see an error such as
The host [IP] is not a vLCM managed standalone host. This message does not indicate a functional issue.Workaround: Refresh the vSphere Client session or change the tab and return to the Updates tab.
-
VMware vCenter Lifecycle Manager might fail to load latest certificates and cannot complete a range of tasks
VMware vCenter Lifecycle Manager might fail to load the latest certificates when you opt for a non-disruptive certificate renewal in vCenter 8.0 Update 2. As a result, any functionality relying on vCenter Lifecycle Manager, which provides the underlying VMware vCenter Orchestration platform, such as the Update Planner, vSphere+ vCenter Lifecycle Management Service, and reduced downtime upgrade for vCenter, might fail.
Workaround: Restart the vCenter Lifecycle Manager to get the latest certificates. For more information, see VMware knowledge base article 2109887.
-
You see the same license product name displayed multiple times in the vSphere Client
Starting with vSphere 8.0 Update 2b, you can apply a single Solution License to the components of VMware vSphere Foundation and VMware Cloud Foundation. In different screens in the vSphere Client, you might see the license product name multiplied by the number of components for which you use the license. For example, if you use a vSphere 8 Enterprise Plus for VMware Cloud Foundation license for 3 components, such as ESXi, vCenter, and vSphere with Tanzu, you see the name listed 3 times.
Workaround: None
-
ESXi hosts might become unresponsive, and you see a vpxa dump file due to a rare condition of insufficient file descriptors for the request queue on vpxa
In rare cases, when requests to the vpxa service take long, for example waiting for access to a slow datastore, the request queue on vpxa might exceed the limit of file descriptors. As a result, ESXi hosts might briefly become unresponsive, and you see a
vpxa-zdump.00*file in the/var/coredirectory. The vpxa logs contain the lineToo many open files.Workaround: None. The vpxa service automatically restarts and corrects the issue.
-
An external gateway firewall might block vSphere Pod traffic to clusterIPs
When you deploy Supervisor Services on vSphere Pods with Supervisors configured with the VDS stack, traffic from the vSphere Pod to ClusterIPs goes through the external gateway and a custom firewall can block it.
Workaround: For more information, see vSphere Pod Traffic to ClusterIP Time-outs.
-
You do not see the option to push root certificates to vCenter hosts
In the Add Trusted Root Certificate screen under the Certificate Management tab in the vSphere Client, you do not see the option Start Root certificate push to vCenter Hosts.
Workaround: This change in the Add Trusted Root Certificate screen is related to the non-disruptive certificate management capability introduced with vCenter 8.0 Update 2 and is expected. For more information, see Non-disruptive Certificate Management.
-
If you use custom update repository with untrusted certificates, vCenter Server upgrade or update by using vCenter Lifecycle Manager workflows to vSphere 8.0 might fail
If you use a custom update repository with self-signed certificates that the VMware Certificate Authority (VMCA) does not trust, vCenter Lifecycle Manager fails to download files from such a repository. As a result, vCenter Server upgrade or update operations by using vCenter Lifecycle Manager workflows fail with the error
Failed to load the repository manifest data for the configured upgrade.Workaround: Use CLI, the GUI installer, or the Virtual Appliance Management Interface (VAMI) to perform the upgrade. For more information, see VMware knowledge base article 89493.
-
A scheduled task fails and doesn't schedule further runs
With vSphere 8.0 Update 2, if a vCenter user is unauthorized or unauthenticated, all scheduled tasks they own fail and cannot be scheduled until the user privileges are restored or a different vSphere user takes over the scheduled tasks. In the vSphere Client, you see messages for failed tasks and reasons for the failure.
Workaround: Any vSphere user with sufficient privileges to edit scheduled tasks, including the current task owner with restored privileges, can click Edit and submit the scheduled task, without actually changing the scheduled task. For more information, see Scheduling vSphere Tasks.
Virtual Machine Management Issues
-
In a mixed vCenter environment, when you clone a VM with First Class Disk (FCD) attached and delete it, the attached FCD in the cloned VM is also deleted
In a mixed vCenter environment, where vCenter is on version 8.0 Update 2 or later and ESXi is on version 7.0 Update 3 or earlier, when you clone a VM with FCD, the parameter
KeepAfterDeleteVMis set toFALSEby default. As a result, if the cloned VM is deleted, the attached cloned FCD is also deleted.Workaround: In a mixed vCenter environment, where vCenter is of version 8.0 Update 2 or later and ESXi is on version 7.0 Update 3 or earlier, set the
KeepAfterDeleteVMparameter toTRUEby using the FCD API :setVStorageObjectControlFlags. You can invoke the FCD API athttps://<VC_IP>/mob/?moid=VStorageObjectManager&method=setVStorageObjectControlFlagsand pass the control flag :KeepAfterDeleteVM.
vSphere Lifecycle Manager Issues
-
You do not see a warning or error when entering non-numeric values for a desired cluster configuration setting in the vSphere Client that requires numbers
When you edit the host settings of the draft configuration for a cluster that uses vSphere Configuration Profiles, you can enter non-numeric values in a field that expects only numbers and you see no error or warning. For example, if you set non-numeric characters in the setting for syslog rotations,
esx/syslog/global_settings/rotations, which expects a number, the Edit dialog box closes without an error and seems to save the value, but the setting actually keeps the previous valid value.Workaround: Use numeric values in fields that expect numbers. Use numbers in text inputs that expect numbers.
-
In the vSphere Client, you see a different count of components in a vSphere Lifecycle Manager image
When you prepare a vSphere Lifecycle Manager image for a cluster or standalone ESXi host, and manually add or remove components, you might see a different count of the components in Updates > Hosts > Image > Components and in the list of components when you click Show details. The discrepancy occurs when the vSphere Lifecycle Manager considers not to use some of the additional components, for example if a driver is being deprecated, or if you remove a component, such as VMware Tools or Host Client.
Workaround: None. You can safely ignore the difference in the count, because it does not impact the actual list of components that vSphere Lifecycle Manager uses for the image installation.
-
You cannot edit the VMware vSphere Lifecycle Manager Update Download scheduled task
In the vSphere Client, when you navigate to a vCenter Server instance and select Scheduled Tasks under the Configure tab, if you select the VMware vSphere Lifecycle Manager Update Download task and click Edit, you cannot modify the existing settings.
Workaround: You can edit the VMware vSphere Lifecycle Manager Update Download task by following the steps in the topic Configure the vSphere Lifecycle Manager Automatic Download Task.
-
Manually applied security advanced options on a vCenter system might not persist across vSphere Lifecycle Manager operations
Some of all manually applied security advanced options on a vCenter system might not persist across vSphere Lifecycle Manager operations, such as upgrade, update, backup, or restore.
Workaround: Re-apply the manual settings after the vSphere Lifecycle Manager task completes.
-
If a parallel remediation task fails, you do not see the correct number of ESXi hosts that passed or skipped the operation
With vSphere 8.0, you can enable vSphere Lifecycle Manager to remediate all hosts that are in maintenance mode in parallel instead of in sequence. However, if a parallel remediation task fails, in the vSphere Client you might not see the correct number of hosts that passed, failed, or skipped the operation, or even not see such counts at all. The issue does not affect the vSphere Lifecycle Manager functionality, but only the reporting in the vSphere Client.
Workaround: None.
-
You see an authentication error on the vSphere Lifecycle Manager home view in one of several linked vCenter instances
After an update of a linked vCenter system, access to the vSphere Lifecycle Manager home page in the vSphere Client from one of the linked vCenter instances might fail. When you select Menu > Lifecycle Manager, you see the error
Authentication failed, Lifecycle Manager server could not be contacted. The issue also affects vSphere Lifecycle Manager baseline pages and workflows. Workflows with vSphere Lifecycle Manager images are not affected.Workaround: Log in to the vSphere Client from another vCenter instance in the linked environment or restart the vsphere-ui service to resolve the issue.
-
You see error messages when try to stage vSphere Lifecycle Manager Images on ESXi hosts of version earlier than 8.0
ESXi 8.0 introduces the option to explicitly stage desired state images, which is the process of downloading depot components from the vSphere Lifecycle Manager depot to the ESXi hosts without applying the software and firmware updates immediately. However, staging of images is only supported on an ESXi 8.0 or later hosts. Attempting to stage a vSphere Lifecycle Manager image on ESXi hosts of version earlier than 8.0 results in messages that the staging of such hosts fails, and the hosts are skipped. This is expected behavior and does not indicate any failed functionality as all ESXi 8.0 or later hosts are staged with the specified desired image.
Workaround: None. After you confirm that the affected ESXi hosts are of version earlier than 8.0, ignore the errors.
-
A remediation task by using vSphere Lifecycle Manager might intermittently fail on ESXi hosts with DPUs
When you start a vSphere Lifecycle Manager remediation on an ESXi hosts with DPUs, the host upgrades and reboots as expected, but after the reboot, before completing the remediation task, you might see an error such as:
A general system error occurred: After host … remediation completed, compliance check reported host as 'non-compliant'. The image on the host does not match the image set for the cluster. Retry the cluster remediation operation.This is a rare issue, caused by an intermittent timeout of the post-remediation scan on the DPU.
Workaround: Reboot the ESXi host and re-run the vSphere Lifecycle Manager compliance check operation, which includes the post-remediation scan.
VMware Host Client Issues
-
VMware Host Client might display incorrect descriptions for severity event states
When you look in the VMware Host Client to see the descriptions of the severity event states of an ESXi host, they might differ from the descriptions you see by using Intelligent Platform Management Interface (IPMI) or Lenovo XClarity Controller (XCC). For example, in the VMware Host Client, the description of the severity event state for the PSU Sensors might be
Transition to Non-critical from OK, while in the XCC and IPMI, the description isTransition to OK.Workaround: Verify the descriptions for severity event states by using the ESXCLI command
esxcli hardware ipmi sdr listand Lenovo XCC.
Security Features Issues
-
If you use an RSA key size smaller than 2048 bits, RSA signature generation fails
Starting from vSphere 8.0, ESXi uses the OpenSSL 3.0 FIPS provider. As part of the FIPS 186-4 requirement, the RSA key size must be at least 2048 bits for any signature generation, and signature generation with SHA1 is not supported.
Workaround: Use RSA key size larger than 2048.
-
You cannot encrypt virtual machines when connected to a vCenter version earlier than 8.0 Update 1
When you use the vSphere Client to connect to a vCenter system of version 7.x or earlier than 8.0 Update 1, and try to encrypt a VM either in the New Virtual Machine wizard or in the Edit Settings dialog of an existing VM, you see errors such as
Operation failed! RuntimeFault.Summary and A general runtime error occurred. Key /default KMS cluster not found. The task completes successfully when you use the vSphere Client to log in to a vCenter system of version 8.0 Update 1 or later.Workaround: Use the vSphere Client from the vCenter instance of version earlier than 8.0 Update 1 to encrypt the VM. Alternatively, you can enable VM encryption on another vCenter instance of version 8.0 Update 1 and later, and migrate the already encrypted VM to the vCenter instance of earlier version.
vSphere Cluster Service Issues
-
In the vSphere Client, you see the vSphere HA status of Embedded vSphere Cluster Service VMs as Unprotected
vSphere 8.0 Update 3 introduces a redesign of vCLS to Embedded vCLS, which utilizes vSphere Pod technology. Deployment and lifecycle of such VMs are now managed within ESXi and are no longer managed by the vSphere ESX Agent Manager (EAM). On the Summary tab in the vSphere Client, you see the vSphere HA status of Embedded vSphere Cluster Service VMs as Unprotected, but this is expected, because vSphere HA does not manage Embedded vSphere Cluster Service VMs.
Workaround: Ignore the information in the vSphere HA card on the Summary tab in the vSphere Client. For more information, see vSphere Cluster Services.
