









Es posible crear una implementación de dispositivo de VMware Cloud Director con un clúster de HA de base de datos que proporcione capacidades de conmutación por error a la base de datos de VMware Cloud Director.
El dispositivo de VMware Cloud Director incluye una base de datos de PostgreSQL integrada. La base de datos de PostgreSQL integrada incluye el conjunto de herramientas de Replication Manager (repmgr), que proporciona una función de alta disponibilidad (High Availability, HA) a un clúster de servidores de PostgreSQL.
Puede implementar el dispositivo de VMware Cloud Director como celda principal, celda en espera o celda de aplicación de VMware Cloud Director. Consulte Implementar el dispositivo de VMware Cloud Director mediante vSphere Client, Implementar el dispositivo de VMware Cloud Director mediante VMware OVF Tool o #GUID-D35B3629-FCA2-40A6-8009-1A6CF8120F30.
Para configurar HA para la base de datos de VMware Cloud Director, al crear el grupo de servidores, puede implementar una instancia principal y dos instancias en espera del dispositivo de VMware Cloud Director para configurar un clúster de HA de base de datos. Puede escalar horizontalmente el grupo de servidores mediante la implementación adicional de celdas de aplicación. Consulte la figura Clúster de HA de base de datos del dispositivo de VMware Cloud Director.
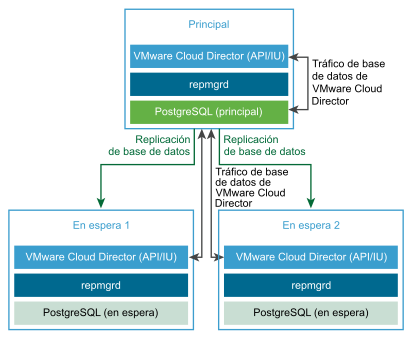
Crear una implementación de dispositivo de VMware Cloud Director con HA de base de datos
- Implemente el dispositivo de VMware Cloud Director como celda principal.
La celda principal es el primer miembro del grupo de servidores de VMware Cloud Director. La base de datos integrada se configura como la base de datos de VMware Cloud Director. El nombre de la base de datos es
vcloudy el usuario de la base de datos esvcloud. - Compruebe que la celda principal esté lista y en ejecución.
- Para comprobar el estado del servicio de VMware Cloud Director, inicie sesión con las credenciales de administrador del sistema en VMware Cloud Director Service Provider Admin Portal en https://primary_eth0_ip_address/provider.
- Para comprobar el estado de la base de datos PostgreSQL, inicie sesión como usuario raíz en la interfaz de usuario de administración de dispositivos en https://primary_eth1_ip_address:5480.
El nodo principal debe estar en estado de ejecución.
- Implemente dos instancias del dispositivo de VMware Cloud Director como celdas en espera.
Las bases de datos integradas se configuran en modo de replicación con la base de datos principal.
Nota: Después de la implementación inicial del dispositivo en espera, Replication Manager comienza a sincronizar su base de datos con la base de datos del dispositivo principal. Durante este período, la base de datos de VMware Cloud Director y, por tanto, la interfaz de usuario de VMware Cloud Director no están disponibles. - Compruebe que todas las celdas del clúster de HA estén en ejecución.
Consulte la Ver el estado del clúster y el modo de conmutación por error del dispositivo de VMware Cloud Director.
- (Opcional) Implemente una o varias instancias del dispositivo de VMware Cloud Director como celdas de aplicación de VMware Cloud Director.
Las bases de datos integradas no se utilizan. La celda de aplicación de VMware Cloud Director se conecta a la base de datos principal.
Automatic. Consulte
API del dispositivo de VMware Cloud Director. El modo de conmutación por error predeterminado para las celdas nuevas es
Manual. Si el modo de conmutación por error es incoherente en los nodos de un clúster, se establece en
Indeterminate en dicho clúster. El modo
Indeterminate puede producir estados de clúster incoherentes entre los nodos y los nodos que siguen una celda principal anterior. Para ver el modo de conmutación por error del clúster, consulte
Ver el estado del clúster y el modo de conmutación por error del dispositivo de VMware Cloud Director.
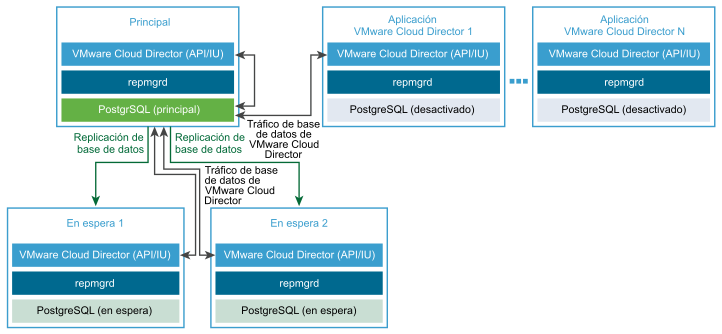
Crear una implementación de dispositivo de VMware Cloud Director sin HA de base de datos
- Implemente el dispositivo de VMware Cloud Director como celda principal.
La celda principal es el primer miembro del grupo de servidores de VMware Cloud Director. La base de datos integrada se configura como la base de datos de VMware Cloud Director. El nombre de la base de datos es
vcloudy el usuario de la base de datos esvcloud. - Compruebe que la celda principal esté lista y en ejecución.
- Para comprobar el estado del servicio de VMware Cloud Director, inicie sesión con las credenciales de administrador del sistema en VMware Cloud Director Service Provider Admin Portal en https://dirección_ip_eth0_principal/proveedor.
- Para comprobar el estado de la base de datos PostgreSQL, inicie sesión como usuario raíz en la interfaz de usuario de administración de dispositivos en https://primary_eth1_ip_address:5480.
El nodo principal debe estar en estado de ejecución.
- (Opcional) Implemente una o varias instancias del dispositivo de VMware Cloud Director como celdas de aplicación de VMware Cloud Director.
La base de datos integrada no se utiliza. La celda de aplicación de VMware Cloud Director se conecta a la base de datos principal.
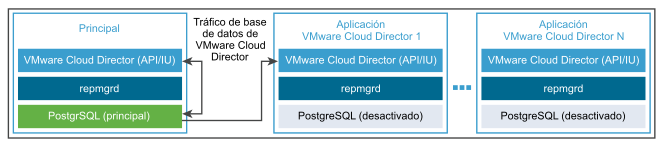
Conmutación por error automática del dispositivo de VMware Cloud Director
Si se produce un error en el servicio de base de datos principal, puede activar VMware Cloud Director para que realice una conmutación por error automática a una nueva base de datos principal.
Con la conmutación por error automática, ya no es necesario que un administrador inicie la acción de conmutación por error cuando el servicio de base de datos principal no puede realizar sus funciones por algún motivo. De forma predeterminada, el modo de conmutación por error se establece como manual. Puede establecerlo como automático o como manual mediante la API del dispositivo de VMware Cloud Director. Consulte la Referencia del esquema de la API del dispositivo de VMware Cloud Director.
Automatic. Consulte
API del dispositivo de VMware Cloud Director. El modo de conmutación por error predeterminado para las celdas nuevas es
Manual. Si el modo de conmutación por error es incoherente en los nodos de un clúster, se establece en
Indeterminate en dicho clúster. El modo
Indeterminate puede producir estados de clúster incoherentes entre los nodos y los nodos que siguen una celda principal anterior. Para ver el modo de conmutación por error del clúster, consulte
Ver el estado del clúster y el modo de conmutación por error del dispositivo de VMware Cloud Director.
Si el entorno tiene al menos dos celdas en espera activas, una conmutación por error de la base de datos se inicia automáticamente en caso de que se produzca un error de base de datos principal. Tras la conmutación por error, debe haber al menos una celda en espera activa para que se pueda actualizar la nueva base de datos principal. En circunstancias normales, la implementación del dispositivo de VMware Cloud Director precisa de al menos dos celdas en espera activas en todo momento. Si solo hay una celda en espera activa durante un breve período de tiempo (por ejemplo, si se produce un error en la base de datos principal y se promociona una de las celdas en espera), debe reemplazarse la base de datos principal anterior en la que se produjo el error por otra celda en espera nueva lo antes posible.
Cuando hay una base de datos principal activa y al menos dos celdas en espera activas, se considera que el clúster tiene el estado Healthy. Cuando hay una base de datos principal activa y solo una celda en espera activa, el clúster cambia al estado Degraded. Si se produce otro error de base de datos mientras el clúster está en el estado Degraded, la base de datos principal no se puede actualizar hasta que se conecte otra celda en espera. Cuando esto ocurre, VMware Cloud Director no está disponible porque no se puede actualizar la base de datos con las celdas de VMware Cloud Director hasta que hay al menos una celda en espera activa para procesar una replicación por secuencias desde la base de datos principal. Que el clúster esté en estado Healthy o Degraded es independiente de si se activa la conmutación por error manual o automática.
Después de un error en la base de datos principal, el estado de la principal es No_Active_Primary. Para una conmutación por error manual del dispositivo de VMware Cloud Director, el administrador debe promocionar manualmente una instancia en espera a principal y volver a implementar la instancia principal con errores como en espera. Para la conmutación por error automática del dispositivo, VMware Cloud Director promociona automáticamente una instancia en espera a principal, y el administrador vuelve a implementar manualmente la instancia principal con errores como en espera.
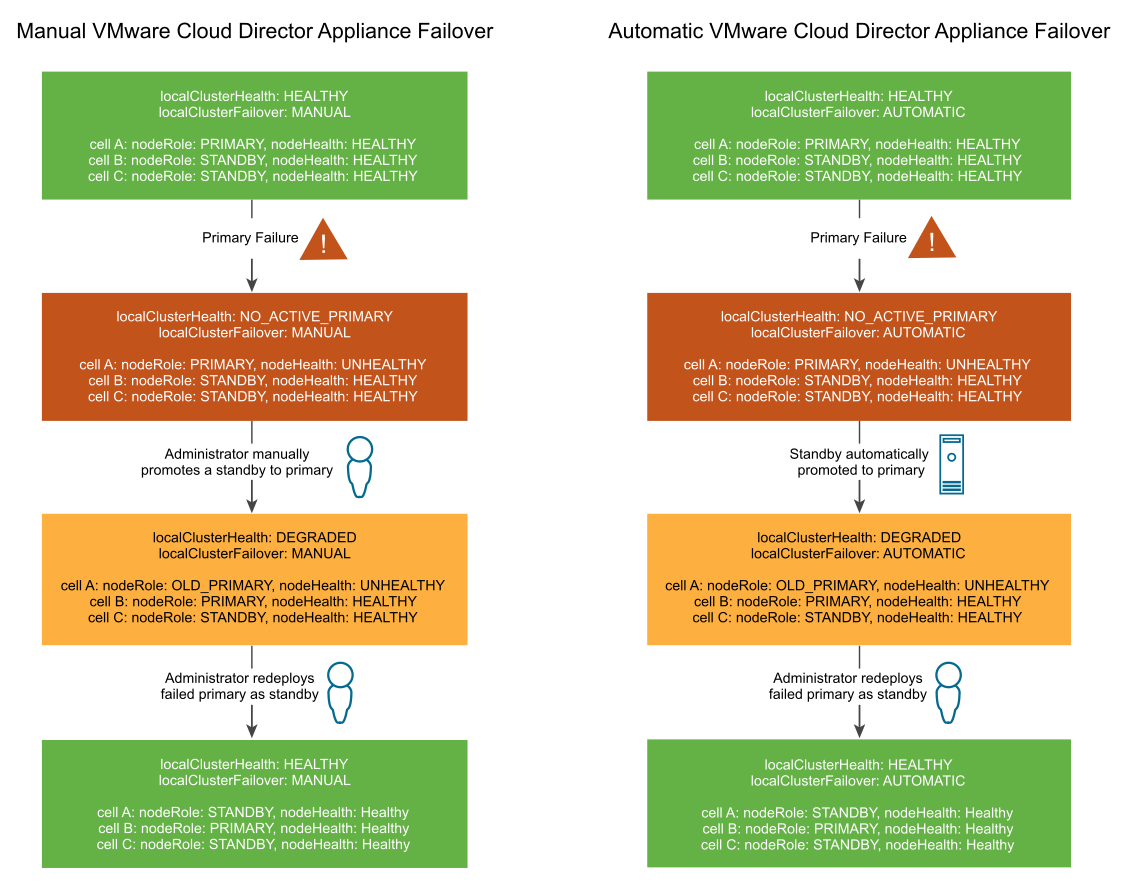
Creación automática de barreras de una celda principal de VMware Cloud Director con errores
Si se promueve una nueva celda principal después de un error en una celda principal, VMware Cloud Director crea una barrera de forma automática alrededor de la celda principal anterior para evitar que se reinicie.
En caso de una conmutación por error, si una base de datos principal con errores se reinicia después de promover una nueva celda principal, VMware Cloud Director crea una barrera de forma automática alrededor de la celda principal anterior. Esta automatización evita el síndrome de cerebro dividido, el cual causa que dos bases de datos activas diverjan la una de la otra. La automatización de la creación de barreras detiene y activa el servicio vpostgres en el nodo principal anterior. A continuación, puede volver a implementar la celda principal con errores como una celda en espera para restaurar el estado del clúster a Healthy.
Para obtener más información sobre cómo ver el estado de mantenimiento del clúster y el modo de conmutación por error, consulte Ver el estado del clúster y el modo de conmutación por error del dispositivo de VMware Cloud Director.
