









Implementar un clúster de carga de trabajo en hardware especializado
Tanzu Kubernetes Grid admite la implementación de clústeres de carga de trabajo en tipos específicos de hosts habilitados para GPU en vSphere 7.0 y versiones posteriores.
Implementar un clúster de carga de trabajo habilitado para GPU
Para utilizar un nodo con una GPU en un clúster de carga de trabajo de vSphere, debe habilitar el modo de acceso directo PCI. Esto permite que el clúster acceda a la GPU directamente, sin pasar por el hipervisor ESXi, lo que proporciona un nivel de rendimiento similar al rendimiento de la GPU en un sistema nativo. Cuando se utiliza el modo de acceso directo PCI, cada dispositivo GPU está dedicado a la máquina virtual (VM) del clúster de carga de trabajo de vSphere.
NotaPara agregar nodos habilitados para GPU a los clústeres existentes, utilice el comando
tanzu cluster node-pool set.
Requisitos previos
- Host ESXi con tarjeta GPU NVIDIA V100 o NVIDIA Tesla T4.
- vSphere 7.0 Update 3 y versiones posteriores. A continuación, se enumeran las compilaciones para 7.0u3, que es el mínimo necesario para admitir esto.
- Tanzu Kubernetes Grid v1.6+.
- Helm, el administrador de paquetes de Kubernetes. Para instalar, consulte Instalar Helm en la documentación de Helm.
Procedimiento
Para crear un clúster de carga de trabajo de hosts habilitados para GPU, siga estos pasos para habilitar el acceso directo a PCI, crear una imagen de máquina personalizada, crear un archivo de configuración del clúster y versión Tanzu Kubernetes, implementar el clúster de carga de trabajo e instalar un operador de GPU mediante Helm.
-
Agregue los hosts ESXi con las tarjetas GPU al vSphere Client.
-
Habilite el acceso directo PCI y registre los identificadores de GPU de la siguiente manera:
- En el vSphere Client, seleccione el host ESXi de destino en el clúster
GPU. - Seleccione Configurar (Configure) > Hardware > Dispositivos PCI (PCI Devices).
- Seleccione la pestaña Todos los dispositivos PCI.
- Seleccione la GPU de destino de la lista.
- Haga clic en Alternar acceso directo.
- En Información general (General Information), registre el ID de dispositivo y el ID de proveedor (resaltados en verde en la imagen a continuación). Los identificadores son los mismos para las tarjetas GPU idénticas. Los necesitará para el archivo de configuración del clúster.
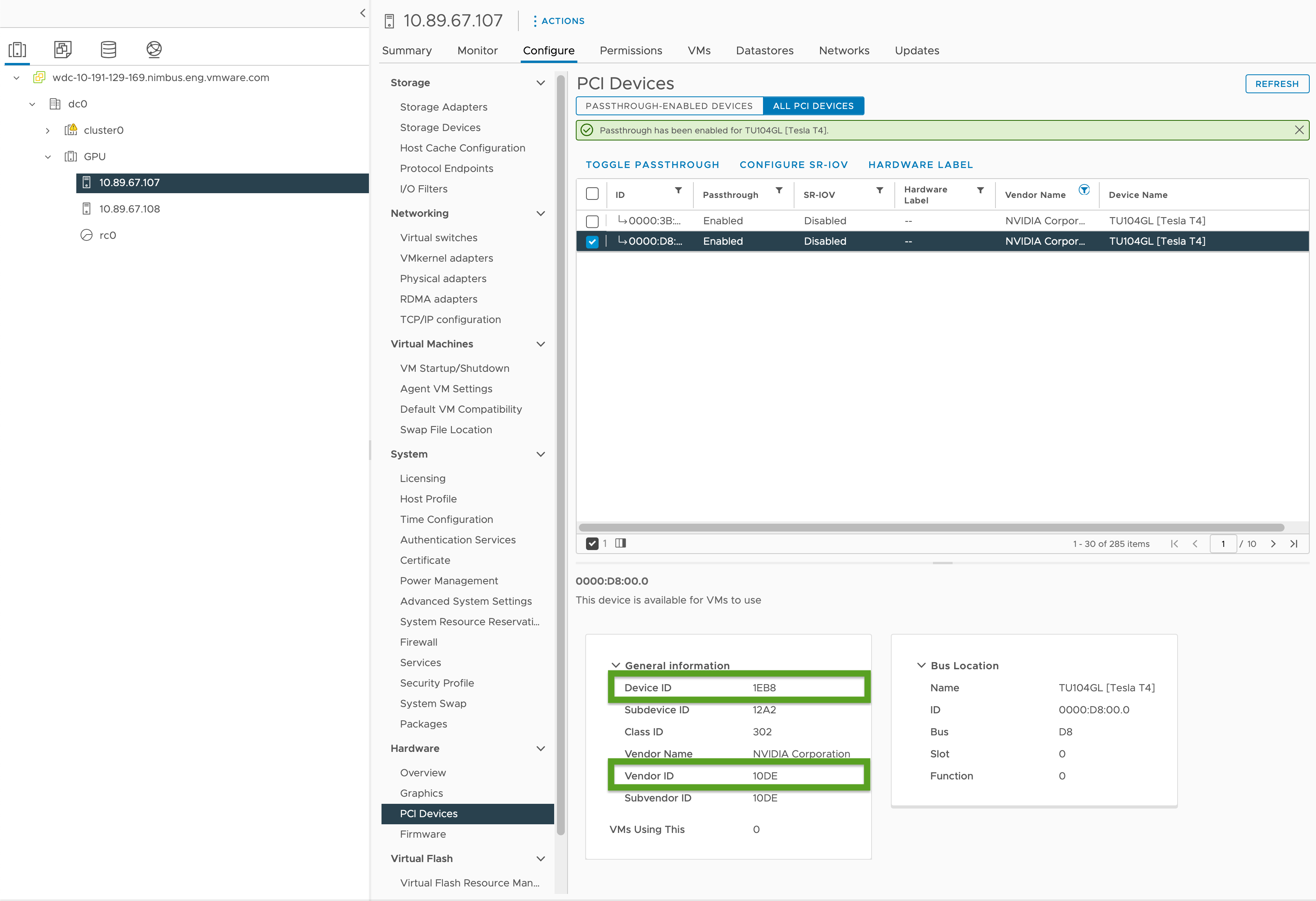
- En el vSphere Client, seleccione el host ESXi de destino en el clúster
-
Cree un archivo de configuración del clúster de carga de trabajo mediante la plantilla en Plantilla de clúster de carga de trabajo e incluya las siguientes variables:
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"Donde:
<VENDOR-ID>y<DEVICE-ID>es el identificador del proveedor y del dispositivo que registró en un paso anterior. Por ejemplo, si el identificador del proveedor es10DEy el identificador del dispositivo es1EB8, el valor es"0x10DE:0x1EB8".<GPU-SIZE>es el total de GB de memoria de framebuffer de todas las GPU del clúster redondeadas a la siguiente potencia más alta de dos.- Por ejemplo, con dos GPU de 40 GB, el total es de 80 GB, lo que redondea a 128 GB; por lo que establecería el valor en
pciPassthru.64bitMMIOSizeGB=128. - Para encontrar la memoria necesaria para la tarjeta de GPU, consulte la documentación de su tarjeta GPU de NVIDIA específica. Consulte la tabla Requisitos para usar vGPU en GPU que requieren 64 GB o más de espacio MMIO con máquinas virtuales de gran memoria en la documentación de NVIDIA.
- Consulte también:
- Artículo de la base de conocimientos de VMware Configurar dispositivos de acceso directo de VMDirectPath I/O en un host VMware ESX o VMware ESXi
- Artículo de la base de conocimientos de Dell PowerEdge: "Error en el encendido del módulo 'DevicePowerOn’" de acceso directo PCI al utilizar GPU con máquinas virtuales en vSphere
- Por ejemplo, con dos GPU de 40 GB, el total es de 80 GB, lo que redondea a 128 GB; por lo que establecería el valor en
<BOOLEAN>esfalsesi utiliza la GPU NVIDIA Tesla T4 ytruesi utiliza la GPU NVIDIA V100.<VSPHERE_WORKER_HARDWARE_VERSION>es la versión de hardware de la máquina virtual a la que desea que se actualice la máquina virtual. La versión mínima requerida para los nodos de GPU debe ser 17.WORKER_ROLLOUT_STRATEGYesRollingUpdatesi tiene dispositivos PCI adicionales que los nodos de trabajo pueden utilizar durante las actualizaciones; de lo contrario, utiliceOnDelete.
Nota
Solo puede utilizar un tipo de GPU por máquina virtual. Por ejemplo, no puede utilizar NVIDIA V100 y NVIDIA Tesla T4 en una sola máquina virtual, pero puede usar varias instancias de GPU con el mismo identificador de proveedor y el mismo identificador de dispositivo.
La CLI de
tanzuno permite actualizar la especificaciónWORKER_ROLLOUT_STRATEGYenMachineDeployment. Si la actualización del clúster se bloquea debido a que los dispositivos PCI no están disponibles, VMware sugiere editar la estrategiaMachineDeploymentmediante la CLI dekubectl. La estrategia de lanzamiento se define enspec.strategy.type.Para obtener una lista completa de variables que puede configurar para clústeres habilitados para GPU, consulte Clústeres habilitados para GPU en Referencia de variables del archivo de configuración.
-
Cree el clúster de carga de trabajo ejecutando:
tanzu cluster create -f CLUSTER-CONFIG-NAMEDonde
CLUSTER-CONFIG-NAMEes el nombre del archivo de configuración del clúster que creó en los pasos anteriores. -
Agregue el repositorio de Helm NVIDIA:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
Instale el operador de GPU NVIDIA:
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operatorDonde
KUBECONFIGes el nombre y la ubicación dekubeconfigpara el clúster de carga de trabajo. Para obtener más información, consulte Recuperar clúster de carga de trabajokubeconfig.Para obtener información sobre los parámetros de este comando, consulte Instalar el operador de GPU en la documentación de NVIDIA.
-
Asegúrese de que el operador de GPU NVIDIA se esté ejecutando:
kubectl --kubeconfig=./KUBECONFIG get pods -ALos resultados son similares a:
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
Probar el clúster de GPU
Para probar el clúster habilitado para GPU, cree un manifiesto del pod para el ejemplo cuda-vector-add de la documentación de Kubernetes e impleméntelo. El contenedor descargará, ejecutará y realizará un cálculo CUDA con la GPU.
-
Cree un archivo con el nombre
cuda-vector-add.yamly agregue lo siguiente:apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
Aplique el archivo:
kubectl apply -f cuda-vector-add.yaml -
Ejecute:
kubectl get po cuda-vector-addLos resultados son similares a:
cuda-vector-add 0/1 Completed 0 91s -
Ejecute:
kubectl logs cuda-vector-addLos resultados son similares a:
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
Implementar un clúster de carga de trabajo en un sitio de Edge
Tanzu Kubernetes Grid v1.6+ es compatible con la implementación de clústeres de carga de trabajo en hosts VMware ESXi de Edge. Puede utilizar este enfoque si desea ejecutar muchos clústeres de Kubernetes en diferentes ubicaciones administradas por un clúster de administración central.
Topología: Puede ejecutar clústeres de carga de trabajo de edge en producción con un solo nodo del plano de control y solo uno o dos hosts. Sin embargo, si bien esto utiliza menos CPU, memoria y ancho de banda de red, no tiene las mismas características de resistencia y recuperación de los clústeres Tanzu Kubernetes Grid de producción estándar. Para obtener más información, consulte Arquitectura de referencia de la solución edge de VMware Tanzu 1.0.
Registro local: Para minimizar los retrasos de comunicación y maximizar la resistencia, cada clúster de edge debe tener su propio registro de contenedor de Harbor local. Para obtener una descripción general de esta arquitectura, consulte Registro de contenedores en Descripción general de la arquitectura. Para instalar un registro de Harbor local, consulte Implementar un registro de Harbor sin conexión en vSphere.
Tiempos de espera: Además, cuando un clúster de carga de trabajo de edge tiene su clúster de administración remoto en un centro de datos principal, es posible que deba ajustar ciertos tiempos de espera para permitir que el clúster de administración tenga tiempo suficiente para conectarse con las máquinas del clúster de carga de trabajo. Para ajustar estos tiempos de espera, consulte Ampliar tiempos de espera de clústeres Edge para gestionar una mayor latencia a continuación.
Especificar una plantilla de máquina virtual local
Si los clústeres de carga de trabajo de Edge utilizan su propio almacenamiento aislado en lugar de almacenamiento vCenter compartido, debe configurarlos para recuperar imágenes de plantilla de máquina virtual de nodo, como archivos OVA, del almacenamiento local.
NotaNo se puede utilizar
tanzu cluster upgradepara actualizar la versión de Kubernetes de un clúster de carga de trabajo de Edge que utiliza una plantilla de máquina virtual local. En su lugar, actualice el clúster siguiendo Actualizar un clúster de Edge con una plantilla de máquina virtual local en el tema Actualizar clústeres de carga de trabajo.
Para especificar una sola plantilla de máquina virtual para el clúster, o diferentes plantillas específicas de las implementaciones de máquinas de plano de control y trabajo:
-
Cree el archivo de configuración del clúster y genere el manifiesto del clúster como el paso 1 del proceso de dos pasos descrito en Crear un clúster basado en clases.
-
Asegúrese de que las plantillas de máquina virtual para el clúster:
- Tienen una versión de Kubernetes válida para TKG.
- Tienen una versión de OVA válida que coincida con la propiedad
spec.osImagesde un TKr. - Se cargan en vCenter locales y tienen una ruta de acceso de inventario válida, por ejemplo,
/dc0/vm/ubuntu-2004-kube-v1.26.8+vmware.1-tkg.1.
-
Edite la especificación del objeto
Clusteren el manifiesto de la siguiente manera, en función de si va a definir una plantilla de máquina virtual de todo el clúster o varias plantillas de máquina virtual:-
Plantilla de máquina virtual de todo el clúster:
- En
annotations, establezcarun.tanzu.vmware.com/resolve-vsphere-template-from-pathen la cadena vacía. - En el bloque
vcenterenspec.topology.variables, establezcatemplateen la ruta de acceso de inventario de la plantilla de máquina virtual. -
Por ejemplo:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...Donde
VM-TEMPLATEes la ruta de acceso a la plantilla de máquina virtual del clúster.
- En
-
Plantillas de varias máquinas virtuales por
machineDeployment:- En
annotations, establezcarun.tanzu.vmware.com/resolve-vsphere-template-from-pathen la cadena vacía. - En
variables.overridespara cada bloquemachineDeploymentsenspec.topology.workerycontrolplane, agregue una línea paravcenterque establezcatemplateen la ruta de acceso de inventario de la plantilla de máquina virtual. -
Por ejemplo:
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...Donde
VM-TEMPLATEes la ruta de acceso a la plantilla de máquina virtual paramachineDeployment.
- En
-
-
Utilice el archivo de configuración modificado para crear el clúster como el paso 2 del proceso descrito en Crear un clúster basado en clases.
Ampliar tiempos de espera de clústeres Edge para gestionar una mayor latencia
Si el clúster de administración administra de forma remota clústeres de carga de trabajo que se ejecutan en sitios Edge o administra más de 20 clústeres de carga de trabajo, puede ajustar los tiempos de espera específicos para que la API del clúster no bloquee ni elimine máquinas que puedan estar desconectadas temporalmente o que tarden más de 12 minutos en comunicarse con su clúster de administración remoto, especialmente si la infraestructura no está aprovisionada.
Existen tres ajustes que puede ajustar para dar a los clústeres edge más tiempo para comunicarse con su plano de control:
-
MHC_FALSE_STATUS_TIMEOUT: Amplíe el valor predeterminado12ma, por ejemplo,40mpara evitar que el controladorMachineHealthCheckrecree la máquina si su estado enReadypermanece enFalsedurante más de 12 minutos. Para obtener más información sobre las comprobaciones de estado de las máquinas, consulte Configurar comprobaciones de estado de la máquina para clústeres de Tanzu Kubernetes. -
NODE_STARTUP_TIMEOUT: Amplíe el valor predeterminado de20ma, por ejemplo,60mpara evitar que el controladorMachineHealthCheckbloquee que las nuevas máquinas se unan al clúster porque tardaron más de 20 minutos en iniciarse, considerando que están en mal estado. -
etcd-dial-timeout-duration: Amplíe el valor predeterminado de10ma, por ejemplo,40sen el manifiestocapi-kubeadm-control-plane-controller-managerpara evitar que los clientesetcddel clúster de administración presenten errores antes de tiempo al examinar el estado deetcden los clústeres de carga de trabajo. El clúster de administración utiliza su capacidad para conectarse conetcdcomo una barra de medir para el estado de la máquina. Por ejemplo:-
En un terminal, ejecute:
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
Cambie el valor de
--etcd-dial-timeout-duration:- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
Además, debe tener en cuenta lo siguiente:
-
capi-kubedm-control-plane-manager : Si de alguna manera se "separa" de los clústeres de carga de trabajo, es posible que deba devolverlo en un nuevo nodo para que pueda supervisar
etcden los clústeres de carga de trabajo correctamente. -
Todas las configuraciones Pinniped en TKG asumen que los clústeres de carga de trabajo están conectados al clúster de administración. En casos de desconexión, debe asegurarse de que los pods de carga de trabajo utilicen cuentas administrativas o de servicio para comunicarse con el servidor de API en los sitios de edge. De lo contrario, la desconexión del clúster de administración interferirá con los sitios de edge que puedan autenticarse a través de Pinniped en los servidores de API de carga de trabajo locales.
