









VMware Aria Automation prend en charge les éléments du catalogue en libre-service que les ingénieurs DevOps et les scientifiques des données peuvent utiliser pour provisionner des charges de travail d'IA dans VMware Private AI Foundation with NVIDIA de manière conviviale et personnalisable.
Conditions préalables
En tant qu'administrateur de cloud, vérifiez que l'environnement VMware Private AI Foundation with NVIDIA est configuré. Reportez-vous à la section Préparation de VMware Cloud Foundation pour le déploiement de charges de travail Private AI.
Connecter VMware Aria Automation à un domaine de charge de travail pour VMware Private AI Foundation with NVIDIA
Avant d'ajouter les éléments du catalogue pour le provisionnement d'applications d'IA à l'aide de VMware Aria Automation, connectez VMware Aria Automation à VMware Cloud Foundation.
Procédure
Créer des éléments de catalogue d'IA dans VMware Aria Automation à l'aide de l'assistant de configuration du catalogue
En tant qu'administrateur de cloud, vous pouvez utiliser l'assistant de configuration du catalogue dans VMware Aria Automation pour configurer et fournir des machines virtuelles à apprentissage profond avec GPU activé et des clusters VMware Tanzu Kubernetes Grid (TKG) en tant qu'éléments de catalogue que les scientifiques des données et les équipes DevOps de votre organisation peuvent demander dans le catalogue de Automation Service Broker en libre-service.
Fonctionnement de l'assistant de configuration du catalogue
- Ajouter un compte de cloud. Les comptes de cloud sont les informations d'identification utilisées pour collecter des données et déployer des ressources sur votre instance de vCenter.
- Ajouter une licence NVIDIA.
- Configurer une intégration VMware Data Services Manager.
- Sélectionner le contenu à ajouter au catalogue d'Automation Service Broker.
- Créer un projet. Le projet lie vos utilisateurs aux régions de compte de cloud, afin qu'ils puissent déployer des modèles de cloud avec des réseaux et des ressources de stockage sur votre instance de vCenter.
- Station de travail d'IA : machine virtuelle avec GPU activé qui peut être configurée avec un vCPU, vGPU et une mémoire souhaités, et l'option permettant de préinstaller les infrastructures AI/ML telles que des exemples PyTorch, des exemples CUDA et TensorFlow.
- Station de travail RAG d'IA : machine virtuelle avec GPU activé dotée de la solution de référence RAG (génération augmentée de récupération).
- Serveur d'inférence Triton : machine virtuelle avec GPU activé dotée du serveur d'inférence Triton.
- Cluster Kubernetes d'IA : cluster VMware Tanzu Kubernetes Grid avec des nœuds worker compatibles avec le GPU pour exécuter des charges de travail cloud natives AI/ML.
- Cluster RAG Kubernetes d'IA : cluster VMware Tanzu Kubernetes Grid avec des nœuds worker compatibles avec le GPU pour exécuter une solution RAG de référence.
- Base de données DSM : base de données pgvector gérée par VMware Data Services Manager.
- Station de travail RAG d'IA avec DSM : machine virtuelle avec GPU activé dotée d'une base de données pgvector gérée par VMware Data Services Manager.
- Cluster RAG Kubernetes d'IA avec DSM : cluster VMware Tanzu Kubernetes Grid avec une base de données pgvector gérée par VMware Data Services Manager.
- Activation du provisionnement de charges de travail d'IA sur un autre superviseur.
- Intégration d'une modification de votre licence NVIDIA AI Enterprise, y compris le fichier .tok de la configuration client et le dispositif License Server ou l'URL de téléchargement des pilotes invités vGPU pour un environnement déconnecté.
- Intégration d'une modification d'image de VM à apprentissage profond.
- Utilisation d'autres classes de VM vGPU ou sans GPU, d'une stratégie de stockage ou d'un registre de conteneur.
- Création d'éléments de catalogue dans un nouveau projet.
Vous pouvez modifier les modèles des éléments du catalogue que l'assistant a créés pour répondre aux besoins spécifiques de votre organisation.
Avant de commencer
- Vérifiez que VMware Private AI Foundation with NVIDIA est configuré jusqu'à cette étape du workflow de déploiement. Reportez-vous à la section Préparation de VMware Cloud Foundation pour le déploiement de charges de travail Private AI.
Procédure
- Une fois connecté à VMware Aria Automation, cliquez sur Lancer le démarrage rapide.
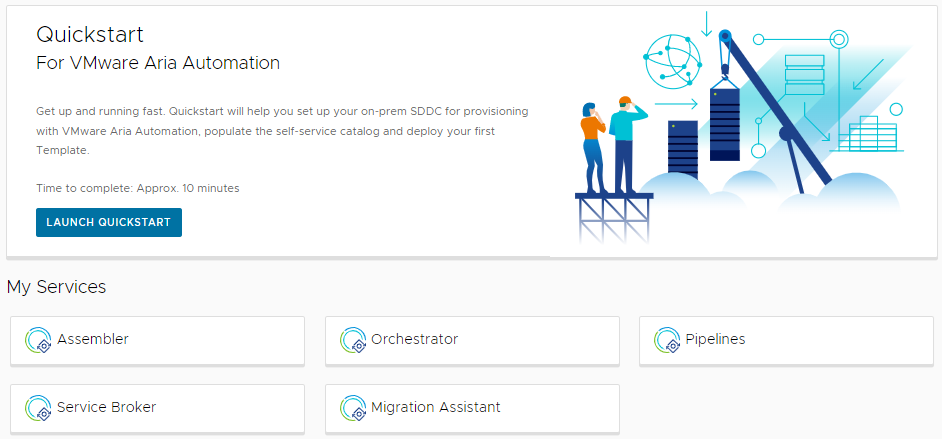
- Sur la carte Services Private AI Automation, cliquez sur Démarrer.
- Sélectionnez le compte de cloud auquel provisionner l'accès.
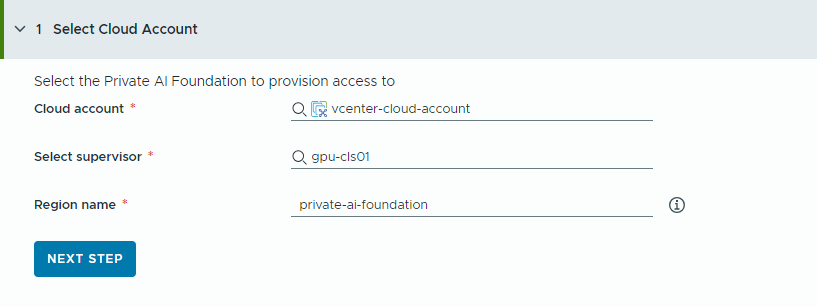
Notez que toutes les valeurs ici sont des exemples de cas d'utilisation. Les valeurs de votre compte dépendent de votre environnement.
- Sélectionnez un compte de cloud vCenter.
- Sélectionnez un superviseur avec GPU activé.
- Entrez un nom de région.
Une région est automatiquement sélectionnée si le superviseur est déjà configuré avec une région.
Si le superviseur n'est pas associé à une région, ajoutez-en un à cette étape. Pensez à utiliser un nom descriptif pour votre région qui aide vos utilisateurs à distinguer les régions avec GPU activé des autres régions disponibles.
- Cliquez sur Étape suivante.
- Fournissez des informations sur votre dispositif NVIDIA License Server.
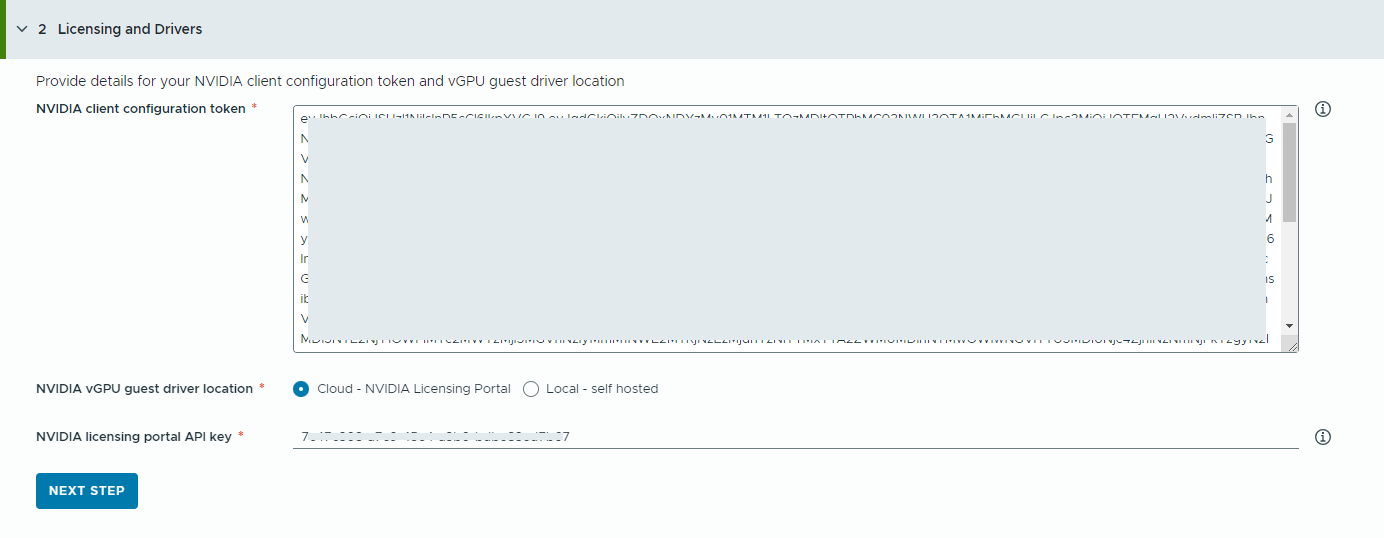
- Copiez et collez le contenu du jeton de configuration client NVIDIA.
Le jeton de configuration client permet d'attribuer une licence au pilote vGPU invité dans la machine virtuelle à apprentissage profond et aux opérateurs GPU sur les clusters TKG.
- Sélectionnez l'emplacement des pilotes NVIDIA vGPU.
- Cloud : le pilote vGPU NVIDIA est hébergé sur le portail de licences NVIDIA.
Vous devez fournir la clé API du portail de licences NVIDIA, qui permet d'évaluer si un utilisateur a le droit de télécharger les pilotes NVIDIA vGPU. La clé API doit être un UUID.
- Local : le pilote NVIDIA vGPU est hébergé sur site et accessible à partir d'un réseau privé.
Vous devez fournir l'emplacement des pilotes invités vGPU pour les VM.
Pour les environnements isolés, le pilote vGPU doit être disponible sur votre réseau privé ou votre centre de données.
- Cloud : le pilote vGPU NVIDIA est hébergé sur le portail de licences NVIDIA.
- Cliquez sur Étape suivante.
- Copiez et collez le contenu du jeton de configuration client NVIDIA.
- Configurez une base de données VMware Data Services Manager (DSM) pour les applications RAG afin de générer des éléments de catalogue de base de données distincts.
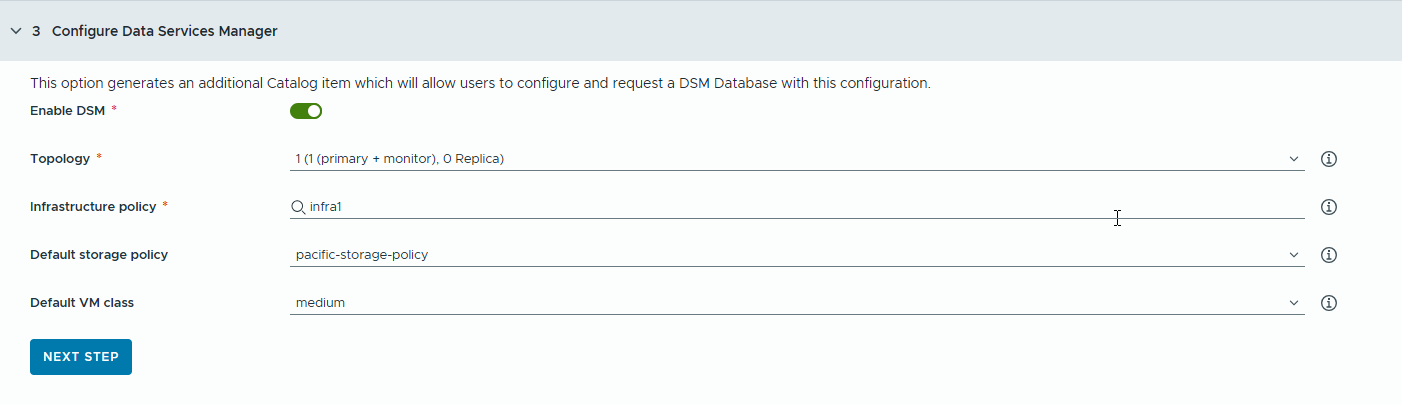
Utilisez VMware Data Services Manager pour créer des bases de données vectorielles, telles qu'une base de données PostgreSQL avec l'extension pgvector.
Les bases de données sont provisionnées dans un domaine de charge de travail différent de celui des VM à apprentissage profond, vous devez donc utiliser des classes de VM et des profils de stockage différents pour chacune d'elles. Pour les bases de données VMware Data Services Manager, sélectionnez une stratégie de stockage et une classe de VM adaptées aux cas d'utilisation RAG.
- Activez l'option.
Pour que vos développeurs et utilisateurs de catalogue partagent une base de données DSM unique, utilisez cette option.Note : Lorsque l'option est activée, un nouvel élément de catalogue de bases de données DSM est créé.
Si aucune une intégration DSM n'est requise pour votre projet, vous pouvez désactiver l'option et passer à l'étape suivante. Dans ce cas, aucun élément de catalogue DSM n'est généré, mais vos utilisateurs disposent toujours d'une base de données DSM intégrée sur d'autres éléments du catalogue RAG.
- Sélectionnez un mode de réplica et une topologie.
La configuration des nœuds de base de données dépend du mode de réplica.
- Serveur unique : un seul nœud principal sans réplica.
- Cluster vSphere unique : trois nœuds (1 principal, 1 moniteur, 1 réplica) sur un cluster vSphere unique fournissant des mises à niveau sans interruption.
- Sélectionnez une stratégie d'infrastructure.
La stratégie d'infrastructure définit la qualité et la quantité de ressources que la base de données peut consommer à partir des clusters vSphere.
Une fois que vous avez sélectionné une stratégie d'infrastructure, vous pouvez choisir parmi les stratégies de stockage et les classes de VM associées à la stratégie d'infrastructure.
- Sélectionnez une stratégie de stockage par défaut.
La stratégie de stockage définit le placement et les ressources de stockage de la base de données.
- Sélectionnez une classe de VM par défaut.
Aucune classe de VM n'est disponible pour provisionner la base de données récemment demandée.
Notez que les classes de VM de DSM sont différentes de celles du superviseur.
- Activez l'option.
- Configurez les éléments du catalogue.
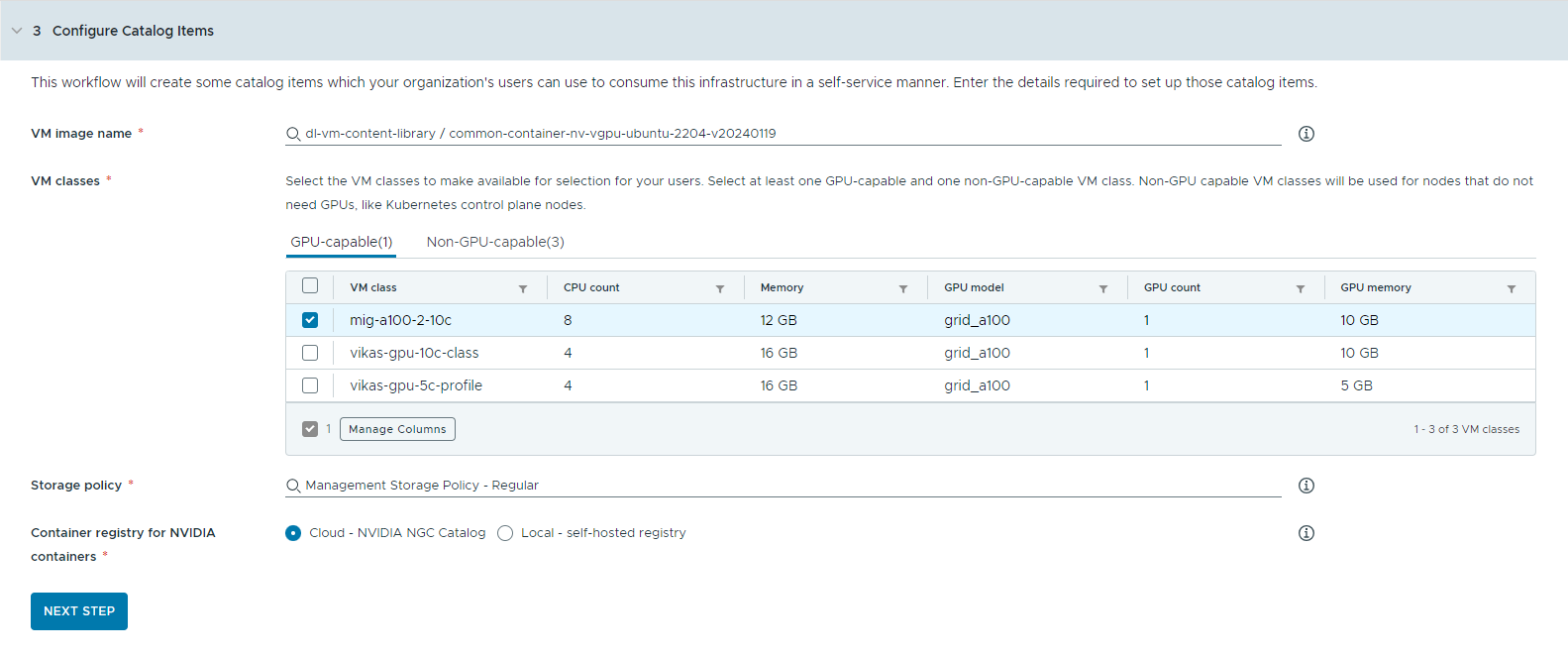
- Sélectionnez la bibliothèque de contenu qui contient l'image de la VM à apprentissage profond.
Vous ne pouvez accéder qu'à une seule bibliothèque de contenu à la fois. Si la bibliothèque de contenu contient des images Kubernetes, ces dernières sont filtrées pour en faciliter la navigation.
- Sélectionnez l'image de VM à utiliser pour créer la VM de la station de travail.
- Sélectionnez une version de Tanzu Kubernetes que vous souhaitez utiliser pour les déploiements de clusters Kubernetes d'IA.
La version de Tanzu Kubernetes (TKr) est la version d'exécution de Kubernetes qui est déployée lorsqu'un utilisateur demande un cluster Kubernetes. Vous pouvez choisir entre les trois versions de Tanzu Kubernetes les plus récentes prises en charge pour VMware Private AI Foundation.
- Sélectionnez les classes de VM que vous souhaitez mettre à la disposition des utilisateurs de votre catalogue.
Vous devez ajouter au moins une classe compatible avec le GPU et une classe non compatible avec le GPU.
- Les classes de VM avec GPU activé sont utilisées pour la machine virtuelle à apprentissage profond et pour les nœuds worker du cluster TKG. Lorsque l'élément de catalogue est déployé, le cluster TKG est créé avec les classes de VM sélectionnées.
- Des nœuds non compatibles avec le GPU sont requis pour exécuter les plans de contrôle Kubernetes.
- Les classes de VM avec la mémoire virtuelle unifiée (UVM) activée sont requises pour exécuter des stations de travail d'IA avec le serveur d'inférence Triton.
- Sélectionnez une stratégie de stockage.
La stratégie de stockage définit le placement et les ressources de stockage pour les machines virtuelles.
La stratégie de stockage que vous définissez pour la VM n'est pas la même que la stratégie de stockage de VMware Data Services Manager.
- Spécifiez le registre de conteneur dans lequel vous souhaitez extraire les ressources de cloud de GPU NVIDIA.
- Cloud : les images de conteneur sont extraites du catalogue NVIDIA NGC.
- Local : pour les environnements isolés, les conteneurs sont extraits d'un registre privé.
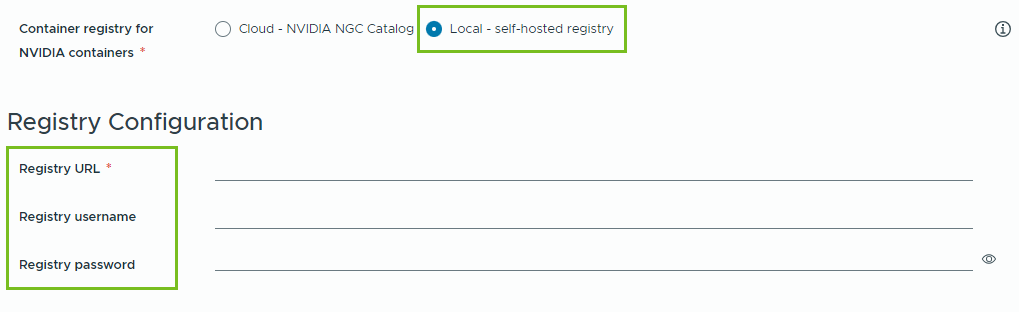
Vous devez fournir l'emplacement du registre autohébergé. Si le registre nécessite une authentification, vous devez également fournir des informations d'identification de connexion.
Vous pouvez utiliser Harbor comme registre local pour les images de conteneur à partir du catalogue NVIDIA NGC. Reportez-vous à la section Configuration d'un registre Harbor privé dans VMware Private AI Foundation with NVIDIA.
- (Facultatif) Configurez un serveur proxy.
Dans les environnements sans accès direct à Internet, le serveur proxy est utilisé pour télécharger le pilote vGPU et extraire les conteneurs de la station de travail d'IA sans RAG.
Note : La prise en charge des environnements isolés est disponible pour les éléments de catalogue Station de travail d'IA et Serveur d'inférence Triton. Les éléments Station de travail d'IA et Cluster Kubernetes d'IA ne prennent pas en charge les environnements isolés et nécessitent une connectivité Internet. - Cliquez sur Étape suivante.
- Sélectionnez la bibliothèque de contenu qui contient l'image de la VM à apprentissage profond.
- Configurez l'accès aux éléments du catalogue en créant un projet et en attribuant des utilisateurs.
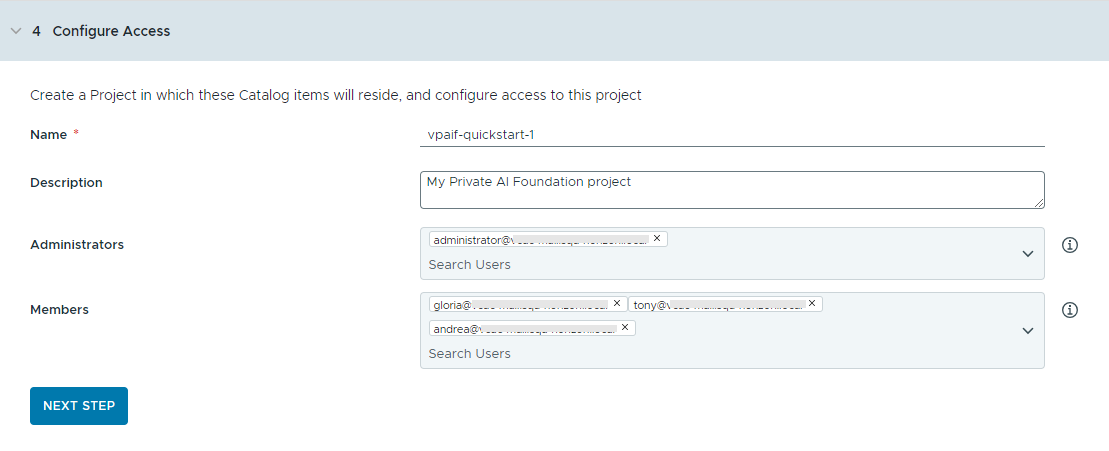
Les projets sont utilisés pour gérer les personnes, les ressources attribuées, les modèles de cloud et les déploiements.
- Entrez un nom et une description pour le projet.
Le nom du projet ne doit contenir que des caractères alphanumériques minuscules ou des traits d'union (-).
- Pour rendre les éléments du catalogue disponibles pour d'autres utilisateurs, ajoutez un administrateur et des membres.
Les administrateurs disposent de plus d'autorisations que les membres. Pour plus d'informations, consultez Présentation des rôles d'utilisateur de VMware Aria Automation.
- Cliquez sur Étape suivante.
- Entrez un nom et une description pour le projet.
- Vérifiez votre configuration sur la page Résumé.
Pensez à enregistrer les détails de votre configuration avant d'exécuter l'assistant.
- Cliquez sur Exécuter le démarrage rapide.
Résultats
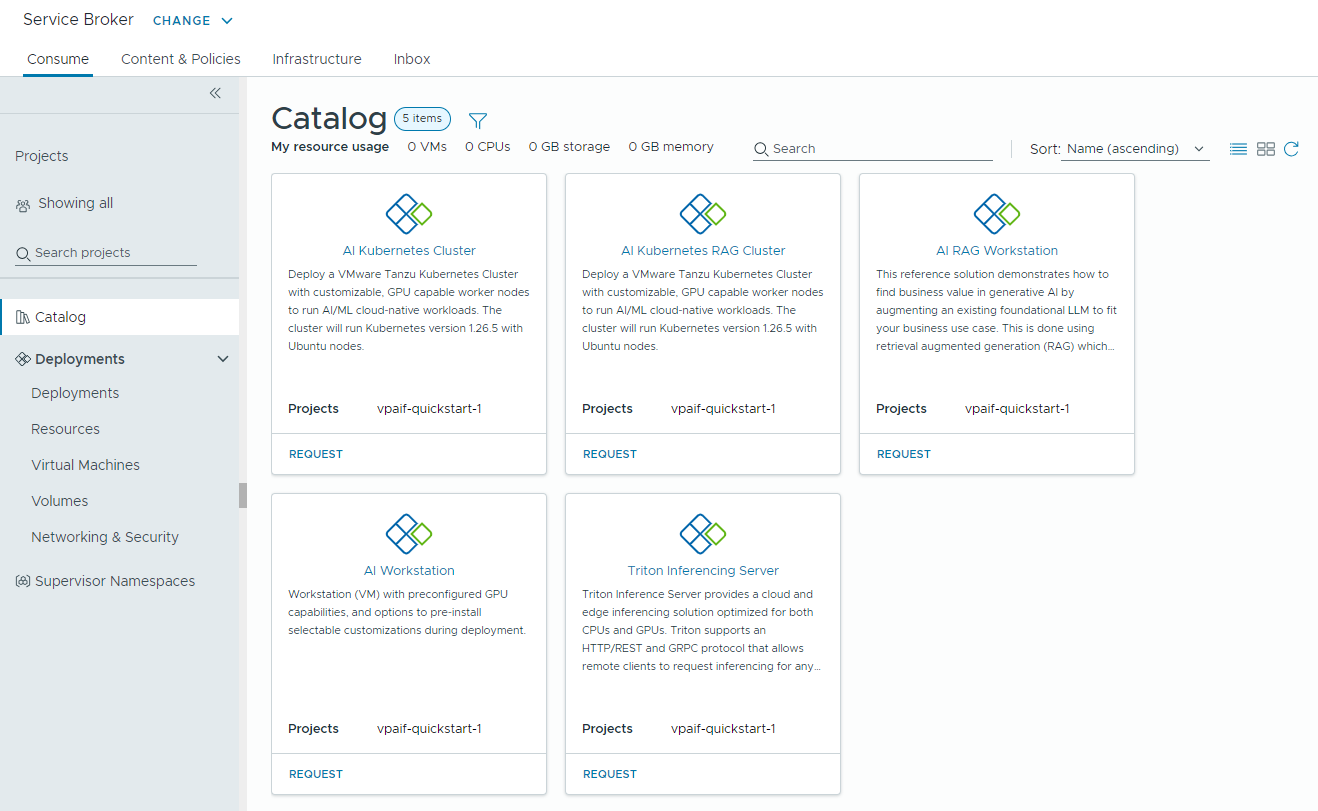
Les éléments de catalogue suivants : Station de travail d'IA, Station de travail RAG d'IA, Station de travail RAG d'IA avec DSM, Base de données DSM, Automation Service BrokerServeur d'inférence Triton, Cluster Kubernetes d'IA, Cluster RAG Kubernetes d'IA et Cluster RAG Kubernetes d'IA avec DSM sont créés dans le catalogue de et les utilisateurs de votre organisation peuvent désormais les déployer.
Dépannage
- Si l'assistant de configuration du catalogue échoue, réexécutez-le pour un autre projet.
