









Référence de variable de fichier de configuration
Cette référence répertorie toutes les variables que vous pouvez spécifier pour fournir des options de configuration du cluster à la CLI Tanzu.
Pour définir ces variables dans un fichier de configuration YAML, laissez un espace entre les deux-points (:) et la valeur de variable. Par exemple :
CLUSTER_NAME: my-cluster
L'ordre des lignes dans le fichier de configuration n'a pas d'importance. Les options sont présentées ici par ordre alphabétique. Reportez-vous également à la section Priorité de la valeur de configuration ci-dessous.
Variables communes pour toutes les plates-formes cibles
Cette section répertorie les variables communes à toutes les plates-formes cibles. Ces variables peuvent s'appliquer aux clusters de gestion, aux clusters de charge de travail ou aux deux. Pour plus d'informations, reportez-vous à la section Configurer les informations de base de la création du cluster de gestion dans Créer un fichier de configuration de cluster de gestion.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
APISERVER_EVENT_RATE_LIMIT_CONF_BASE64 |
✔ | ✔ | Clusters basés sur une classe uniquement. Active et configure un contrôleur d'admission EventRateLimit pour modérer le trafic vers le serveur d'API Kubernetes. Définissez cette propriété en créant un fichier de configuration EventRateLimit config.yaml comme décrit dans la documentation de Kubernetes, puis en le convertissant en valeur de chaîne en exécutant base64 -w 0 config.yaml |
CAPBK_BOOTSTRAP_TOKEN_TTL |
✔ | ✖ | Facultatif ; la valeur par défaut est 15m, 15 minutes. Valeur TTL du jeton de démarrage utilisé par kubeadm lors des opérations d'initialisation du cluster. |
CLUSTER_API_SERVER_PORT |
✔ | ✔ | Facultatif ; la valeur par défaut est 6443. Cette variable est ignorée si vous activez NSX Advanced Load Balancer (vSphere). Pour remplacer le port du serveur d'API Kubernetes par défaut pour les déploiements avec NSX Advanced Load Balancer, définissez VSPHERE_CONTROL_PLANE_ENDPOINT_PORT. |
CLUSTER_CIDR |
✔ | ✔ | Facultatif ; la valeur par défaut est 100.96.0.0/11. Plage CIDR à utiliser pour les espaces. Modifiez la valeur par défaut uniquement si la plage recommandée n'est pas disponible. |
CLUSTER_NAME |
✔ | ✔ | Ce nom doit respecter les conditions requises en matière de nom d'hôte DNS, comme indiqué dans RFC 952 et modifié dans RFC 1123, et doit comporter 42 caractères ou moins. Pour les clusters de charge de travail, ce paramètre est remplacé par l'argument CLUSTER_NAME transmis à la commande tanzu cluster create.Pour les clusters de gestion, si vous ne spécifiez pas CLUSTER_NAME, un nom unique est généré. |
CLUSTER_PLAN |
✔ | ✔ | Requis. Définissez cette variable sur dev, prod ou un plan personnalisé, comme illustré dans Nouveau plan nginx.Le plan dev déploie un cluster avec un nœud de plan de contrôle unique. Le plan prod déploie un cluster hautement disponible avec trois nœuds de plan de contrôle. |
CNI |
✖ | ✔ | Facultatif ; la valeur par défaut est antrea. Interface réseau de conteneur. Ne remplacez pas la valeur par défaut pour les clusters de gestion. Pour les clusters de charge de travail, vous pouvez définir la variable CNI sur antrea, calico ou none. L'option calico n'est pas prise en charge sous Windows. Pour plus d'informations, reportez-vous à la section Déployer un cluster avec une CNI non définie par défaut. Pour personnaliser votre configuration Antrea, reportez-vous à la section Configuration de CNI Antrea ci-dessous. |
CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette option sur true si vous souhaitez que les certificats de machine virtuelle du nœud du plan de contrôle soient renouvelés automatiquement avant leur expiration. Pour plus d'informations, reportez-vous à la section Renouvellement automatique du certificat de nœud du plan de contrôle. |
CONTROLPLANE_CERTIFICATE_ROTATION_DAYS_BEFORE |
✔ | ✔ | Facultatif ; la valeur par défaut est 90. Si CONTROLPLANE_CERTIFICATE_ROTATION_ENABLED est true, définissez le nombre de jours avant la date d'expiration du certificat pour renouveler automatiquement les certificats de nœud de cluster. Pour plus d'informations, reportez-vous à la section Renouvellement automatique du certificat de nœud du plan de contrôle. |
ENABLE_AUDIT_LOGGING |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Journalisation d'audit pour le serveur d'API Kubernetes. Pour activer la journalisation d'audit, définissez la variable sur true. Tanzu Kubernetes Grid enregistre ces journaux dans /var/log/kubernetes/audit.log. Pour plus d'informations, reportez-vous à la section Journalisation d'audit.L'activation des audits Kubernetes peut entraîner des volumes de journaux très élevés. Pour gérer cette quantité, VMware recommande d'utiliser un redirecteur de journaux, tel que Fluent Bit. |
ENABLE_AUTOSCALER |
✖ | ✔ | Facultatif ; la valeur par défaut est false. Si cette variable est définie sur true, vous devez définir des variables supplémentaires dans le tableau Mise à l'échelle automatique du cluster ci-dessous. |
ENABLE_CEIP_PARTICIPATION |
✔ | ✖ | Facultatif ; la valeur par défaut est true. Définissez la variable sur false pour refuser de participer au programme d'amélioration du produit VMware. Vous pouvez également refuser ou accepter de participer au programme après le déploiement du cluster de gestion. Pour plus d'informations, reportez-vous aux sections Refuser ou accepter de participer au programme d'amélioration du produit (CEIP) de VMware dans Gérer la participation au CEIP et Programme d'amélioration du produit (« CEIP »). |
ENABLE_DEFAULT_STORAGE_CLASS |
✖ | ✔ | Facultatif ; la valeur par défaut est true. Pour plus d'informations sur les classes de stockage, reportez-vous à la section Stockage dynamique. |
ENABLE_MHC, etc. |
✔ | ✔ | Facultatif, reportez-vous à la section Contrôles de santé de la machine ci-dessous pour obtenir l'ensemble complet des variables MHC et leur fonctionnement.Pour les clusters de charge de travail créés par vSphere with Tanzu, définissez ENABLE_MHC sur false. |
IDENTITY_MANAGEMENT_TYPE |
✔ | ✖ | Facultatif ; la valeur par défaut est none.Pour les clusters de gestion : Définissez |
INFRASTRUCTURE_PROVIDER |
✔ | ✔ | Requis. Définissez cette variable sur vsphere, aws, azure ou tkg-service-vsphere. |
NAMESPACE |
✖ | ✔ | Facultatif ; défini par défaut sur default, pour déployer des clusters de charge de travail sur un espace de noms nommé default. |
SERVICE_CIDR |
✔ | ✔ | Facultatif ; la valeur par défaut est 100.64.0.0/13. Plage CIDR à utiliser pour les services Kubernetes. Modifiez cette valeur uniquement si la plage recommandée n'est pas disponible. |
Fournisseurs d'identité - OIDC
Si vous définissez IDENTITY_MANAGEMENT_TYPE: oidc, définissez les variables suivantes pour configurer un fournisseur d'identité OIDC. Pour plus d'informations, reportez-vous à la section Configurer la gestion des identités dans Créer un fichier de configuration de cluster de gestion.
Tanzu Kubernetes Grid s'intègre à OIDC à l'aide de Pinniped, comme décrit dans À propos de la gestion des identités et des accès.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
CERT_DURATION |
✔ | ✖ | Facultatif ; la valeur par défaut est 2160h. Définissez cette variable si vous configurez Pinniped pour utiliser des certificats auto-signés gérés par cert-manager. |
CERT_RENEW_BEFORE |
✔ | ✖ | Facultatif ; la valeur par défaut est 360h. Définissez cette variable si vous configurez Pinniped pour utiliser des certificats auto-signés gérés par cert-manager. |
OIDC_IDENTITY_PROVIDER_CLIENT_ID |
✔ | ✖ | Requis. valeur client_id que vous obtenez de votre fournisseur OIDC. Par exemple, si votre fournisseur est Okta, connectez-vous à Okta, créez une application Web et sélectionnez les options d'informations d'identification du client afin d'obtenir un client_id et un secret. Ce paramètre sera stocké dans un secret qui sera référencé par OIDCIdentityProvider.spec.client.secretName dans la ressource personnalisée OIDCIdentityProvider de Pinniped. |
OIDC_IDENTITY_PROVIDER_CLIENT_SECRET |
✔ | ✖ | Requis. valeur secret que vous obtenez de votre fournisseur OIDC. Ne codez pas cette valeur en Base64. |
OIDC_IDENTITY_PROVIDER_GROUPS_CLAIM |
✔ | ✖ | Facultatif. nom de la réclamation de vos groupes. Il permet de définir le groupe d'un utilisateur dans la réclamation JWT (JSON Web Token). La valeur par défaut est groups. Ce paramètre correspond à OIDCIdentityProvider.spec.claims.groups dans la ressource personnalisée OIDCIdentityProvider de Pinniped. |
OIDC_IDENTITY_PROVIDER_ISSUER_URL |
✔ | ✖ | Requis. Adresse IP ou DNS de votre serveur OIDC. Ce paramètre correspond à OIDCIdentityProvider.spec.issuer dans la valeur custom resource de Pinniped. |
OIDC_IDENTITY_PROVIDER_SCOPES |
✔ | ✖ | Requis. Liste séparée par des virgules de portées supplémentaires à demander dans la réponse du jeton. Par exemple, "email,offline_access". Ce paramètre correspond à OIDCIdentityProvider.spec.authorizationConfig.additionalScopes dans la ressource personnalisée OIDCIdentityProvider de Pinniped. |
OIDC_IDENTITY_PROVIDER_USERNAME_CLAIM |
✔ | ✖ | Requis. Nom de votre réclamation de nom d'utilisateur. Il permet de définir le nom d'utilisateur d'un utilisateur dans la réclamation JWT. En fonction de votre fournisseur, entrez des réclamations telles que user_name, email ou code. Ce paramètre correspond à OIDCIdentityProvider.spec.claims.username dans la ressource personnalisée OIDCIdentityProvider de Pinniped. |
OIDC_IDENTITY_PROVIDER_ADDITIONAL_AUTHORIZE_PARAMS |
✔ | ✖ | Facultatif. Ajoutez des paramètres personnalisés à envoyer au fournisseur d'identité OIDC. En fonction de votre fournisseur, ces réclamations peuvent être nécessaires pour recevoir un jeton d'actualisation de la part du fournisseur. Par exemple, prompt=consent. Séparez les valeurs multiples avec des virgules. Ce paramètre correspond à OIDCIdentityProvider.spec.authorizationConfig.additionalAuthorizeParameters dans la ressource personnalisée OIDCIdentityProvider de Pinniped. |
OIDC_IDENTITY_PROVIDER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Facultatif. Bundle d'autorité de certification codé en Base64 pour établir TLS avec des fournisseurs d'identité OIDC. Ce paramètre correspond à OIDCIdentityProvider.spec.tls.certificateAuthorityData dans la ressource personnalisée OIDCIdentityProvider de Pinniped. |
SUPERVISOR_ISSUER_URL |
✔ | ✖ | Ne pas modifier. Cette variable est automatiquement mise à jour dans le fichier de configuration lorsque vous exécutez la commande tanzu cluster create command. Ce paramètre correspond à JWTAuthenticator.spec.audience dans la ressource personnalisée JWTAuthenticator de Pinniped et FederationDomain.spec.issuer dans la ressource personnalisée FederationDomain de Pinniped. |
SUPERVISOR_ISSUER_CA_BUNDLE_DATA_B64 |
✔ | ✖ | Ne pas modifier. Cette variable est automatiquement mise à jour dans le fichier de configuration lorsque vous exécutez la commande tanzu cluster create command. Ce paramètre correspond à JWTAuthenticator.spec.tls.certificateAuthorityData dans la ressource personnalisée JWTAuthenticator de Pinniped. |
Fournisseurs d'identité - LDAP
Si vous définissez IDENTITY_MANAGEMENT_TYPE: ldap, définissez les variables suivantes pour configurer un fournisseur d'identité LDAP. Pour plus d'informations, reportez-vous à la section Configurer la gestion des identités dans Créer un fichier de configuration de cluster de gestion.
Tanzu Kubernetes Grid s'intègre à LDAP à l'aide de Pinniped, comme décrit dans À propos de la gestion des identités et des accès. Chacune des variables ci-dessous correspond à un paramètre de configuration dans la ressource personnalisée LDAPIdentityProvider de Pinniped. Pour obtenir une description complète de ces paramètres et des informations sur leur configuration, reportez-vous à la section LDAPIdentityProvider de la documentation de Pinniped.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
| Pour la connexion au serveur LDAP : | |||
LDAP_HOST |
✔ | ✖ | Requis. adresse IP ou DNS de votre serveur LDAP. Si le serveur LDAP écoute sur le port 636 par défaut, ce qui est la configuration sécurisée, vous n'avez pas besoin de spécifier le port. Si le serveur LDAP écoute sur un port différent, fournissez l'adresse et le port du serveur LDAP, sous la forme "host:port". Ce paramètre correspond à LDAPIdentityProvider.spec.host dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_ROOT_CA_DATA_B64 |
✔ | ✖ | Facultatif. Si vous utilisez un point de terminaison LDAPS, collez le contenu codé en Base64 du certificat de serveur LDAP. Ce paramètre correspond à LDAPIdentityProvider.spec.tls.certificateAuthorityData dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_BIND_DN |
✔ | ✖ | Requis. Nom unique d'un compte de service d'application existant. Par exemple, "cn=bind-user,ou=people,dc=example,dc=com". Le connecteur utilise ces informations d'identification pour rechercher des utilisateurs et des groupes. Ce compte de service doit posséder au moins des autorisations en lecture seule pour effectuer les requêtes configurées par les autres options de configuration LDAP_*. Il est inclus dans le secret pour spec.bind.secretName dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_BIND_PASSWORD |
✔ | ✖ | Requis. Mot de passe du compte de service d'application défini dans LDAP_BIND_DN. Il est inclus dans le secret pour spec.bind.secretName dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
| Pour la recherche d'utilisateurs : | |||
LDAP_USER_SEARCH_BASE_DN |
✔ | ✖ | Requis. point à partir duquel démarrer la recherche LDAP. Par exemple, OU=Users,OU=domain,DC=io. Ce paramètre correspond à LDAPIdentityProvider.spec.userSearch.base dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_USER_SEARCH_FILTER |
✔ | ✖ | Facultatif. filtre facultatif à utiliser par la recherche LDAP. Ce paramètre correspond à LDAPIdentityProvider.spec.userSearch.filter dans la ressource personnalisée LDAPIdentityProvider de Pinniped. À partir de TKG v2.3, lors de la création d'un cluster de gestion ou de la mise à jour du secret du module Pinniped pour un cluster de gestion existant, vous devez utiliser le format Pinniped pour cette valeur. Par exemple, &(objectClass=posixAccount)(uid={}). |
LDAP_USER_SEARCH_ID_ATTRIBUTE |
✔ | ✖ | Facultatif. Attribut LDAP qui contient l'ID d'utilisateur. Défini sur dn par défaut. Ce paramètre correspond à LDAPIdentityProvider.spec.userSearch.attributes.uid dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_USER_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Requis. Attribut LDAP qui contient le nom d'utilisateur. Par exemple, mail. Ce paramètre correspond à LDAPIdentityProvider.spec.userSearch.attributes.username dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
| Pour la recherche de groupes : | |||
LDAP_GROUP_SEARCH_BASE_DN |
✔ | ✖ | Facultatif. Point à partir duquel démarrer la recherche LDAP. Par exemple, OU=Groups,OU=domain,DC=io. Lorsque cette variable n'est pas définie, la recherche de groupes est ignorée. Ce paramètre correspond à LDAPIdentityProvider.spec.groupSearch.base dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_GROUP_SEARCH_FILTER |
✔ | ✖ | Facultatif. filtre facultatif à utiliser par la recherche LDAP. Ce paramètre correspond à LDAPIdentityProvider.spec.groupSearch.filer dans la ressource personnalisée LDAPIdentityProvider de Pinniped. À partir de TKG v2.3, lors de la création d'un cluster de gestion ou de la mise à jour du secret du module Pinniped pour un cluster de gestion existant, vous devez utiliser le format Pinniped pour cette valeur. Par exemple, &(objectClass=posixGroup)(memberUid={}). |
LDAP_GROUP_SEARCH_NAME_ATTRIBUTE |
✔ | ✖ | Facultatif. attribut LDAP qui contient le nom du groupe. Défini sur dn par défaut. Ce paramètre correspond à LDAPIdentityProvider.spec.groupSearch.attributes.groupName dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_GROUP_SEARCH_USER_ATTRIBUTE |
✔ | ✖ | Facultatif. Attribut de l'enregistrement d'utilisateur à utiliser comme valeur de l'attribut d'appartenance de l'enregistrement de groupe. Défini sur dn par défaut. Ce paramètre correspond à LDAPIdentityProvider.spec.groupSearch.userAttributeForFilter dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
LDAP_GROUP_SEARCH_SKIP_ON_REFRESH |
✔ | ✖ | Facultatif. Défini sur false par défaut. Lorsque ce paramètre est défini sur true, les appartenances à un groupe d'un utilisateur sont mises à jour uniquement au début de la session quotidienne de l'utilisateur. Il n'est pas recommandé de définir LDAP_GROUP_SEARCH_SKIP_ON_REFRESH sur true et vous ne devez le faire que lorsqu'il est par ailleurs impossible d'exécuter la requête de groupe suffisamment rapidement lors des actualisations de sessions. Ce paramètre correspond à LDAPIdentityProvider.spec.groupSearch.skipGroupRefresh dans la ressource personnalisée LDAPIdentityProvider de Pinniped. |
Configuration de nœuds
Configurez le plan de contrôle et les nœuds worker, ainsi que le système d'exploitation sur lequel les instances de nœud s'exécutent. Pour plus d'informations, reportez-vous à la section Configurer les paramètres de nœud dans Créer un fichier de configuration de cluster de gestion.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
CONTROL_PLANE_MACHINE_COUNT |
✔ | ✔ | Facultatif. Déployez un cluster de charge de travail avec plus de nœuds de plan de contrôle que les plans dev et prod définissent par défaut. Le nombre de nœuds de plan de contrôle que vous spécifiez doit être impair. |
CONTROL_PLANE_NODE_LABELS |
✔ | ✔ | Clusters basés sur une classe uniquement. Attribuez des étiquettes persistantes personnalisées aux nœuds de plan de contrôle, par exemple CONTROL_PLANE_NODE_LABELS: 'key1=value1,key2=value2'. Pour configurer cette option dans un cluster hérité basé sur un plan, utilisez une superposition ytt comme décrit dans Étiquettes de nœud personnalisées.Les étiquettes de nœuds worker sont définies dans leur pool de nœuds, comme décrit dans Gérer les pools de nœuds de types de VM différents. |
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | vSphere uniquement. Cette variable permet à l'utilisateur de spécifier une liste délimitée par des virgules de serveurs DNS à configurer sur des nœuds de plan de contrôle, par exemple, CONTROL_PLANE_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Prise en charge sur Ubuntu et Photon, mais pas sur Windows. Pour obtenir un exemple de cas d'utilisation, reportez-vous à la section IPAM de nœud ci-dessous. |
CONTROL_PLANE_NODE_SEARCH_DOMAINS |
✔ | ✔ | Clusters basés sur une classe uniquement. Configure les domaines de recherche .local pour les nœuds de cluster, par exemple CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. Pour configurer cela dans un cluster hérité basé sur un plan sur vSphere, utilisez une superposition ytt comme décrit dans Resolve.local Domain. |
CONTROLPLANE_SIZE |
✔ | ✔ | Facultatif. Taille des machines virtuelles du nœud de plan de contrôle. Remplace les paramètres SIZE et VSPHERE_CONTROL_PLANE_*. Reportez-vous à la section SIZE pour connaître les valeurs possibles. |
OS_ARCH |
✔ | ✔ | Facultatif. Architecture du système d'exploitation de la machine virtuelle de nœud. La valeur par défaut et la seule option actuelle est amd64. |
OS_NAME |
✔ | ✔ | Facultatif. Système d'exploitation de la machine virtuelle de nœud. La valeur par défaut est ubuntu pour Ubuntu LTS. Elle peut également être photon pour Photon OS sur vSphere ou amazon pour Amazon Linux sur AWS. |
OS_VERSION |
✔ | ✔ | Facultatif. Version du système d'exploitation OS_NAME, ci-dessus. La valeur par défaut est 20.04 pour Ubuntu. Elle peut être 3 pour Photon sur vSphere et 2 pour Amazon Linux sur AWS. |
SIZE |
✔ | ✔ | Facultatif. Taille des machines virtuelles des nœuds de plan de contrôle et worker. Remplace les paramètres VSPHERE_CONTROL_PLANE_\* et VSPHERE_WORKER_\*. Pour vSphere, définissez small, medium, large ou extra-large comme décrit dans la section Tailles de nœud prédéfinies. Pour AWS, définissez un type d'instance (par exemple, t3.small). Pour Azure, définissez un type d'instance (par exemple, Standard_D2s_v3). |
WORKER_MACHINE_COUNT |
✔ | ✔ | Facultatif. Déployez un cluster de charge de travail avec plus de nœuds worker que les plans dev et prod définissent par défaut. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | vSphere uniquement. Cette variable permet à l'utilisateur de spécifier une liste délimitée par des virgules de serveurs DNS à configurer sur des nœuds worker, par exemple, WORKER_NODE_NAMESERVERS: 10.132.7.1, 10.142.7.1. Prise en charge sur Ubuntu et Photon, mais pas sur Windows. Pour obtenir un exemple de cas d'utilisation, reportez-vous à la section IPAM de nœud ci-dessous. |
WORKER_NODE_SEARCH_DOMAINS |
✔ | ✔ | Clusters basés sur une classe uniquement. Configure les domaines de recherche .local pour les nœuds de cluster, par exemple CONTROL_PLANE_NODE_SEARCH_DOMAINS: corp.local. Pour configurer cela dans un cluster hérité basé sur un plan sur vSphere, utilisez une superposition ytt comme décrit dans Resolve.local Domain. |
WORKER_SIZE |
✔ | ✔ | Facultatif. Taille des machines virtuelles du nœud worker. Remplace les paramètres SIZE et VSPHERE_WORKER_*. Reportez-vous à la section SIZE pour connaître les valeurs possibles. |
CUSTOM_TDNF_REPOSITORY_CERTIFICATE |
✔ | ✔ | (Version d'évaluation technique) Facultatif. Définissez si vous utilisez un serveur de référentiel tdnf personnalisé avec un certificat auto-signé, plutôt que le serveur de référentiel tdnf par défaut de Photon. Entrez le contenu du certificat codé en base64 du serveur de référentiel tdnf. La variable supprime tous les référentiels sous |
Normes de sécurité des espaces pour le contrôleur d'admission de la sécurité des espaces
Configurez les normes de sécurité des espaces pour un contrôleur d'admission de sécurité des espaces (PSA, Pod Security Admission) à l'échelle du cluster, le plan de contrôle et les nœuds worker, ainsi que le système d'exploitation exécuté par les instances de nœud. Pour plus d'informations, reportez-vous à la section Contrôleur d'admission de la sécurité des espaces.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
POD_SECURITY_STANDARD_AUDIT |
✖ | ✔ | Facultatif, la valeur par défaut est restricted. Définit la stratégie de sécurité pour le mode audit du contrôleur PSA à l'échelle du cluster. Valeurs possibles : restricted, baseline et privileged. |
POD_SECURITY_STANDARD_DEACTIVATED |
✖ | ✔ | Facultatif, la valeur par défaut est false. Définissez cette variable sur true pour désactiver le PSA à l'échelle du cluster. |
POD_SECURITY_STANDARD_ENFORCE |
✖ | ✔ | Facultatif, n'a aucune valeur par défaut. Définit la stratégie de sécurité pour le mode enforce du contrôleur PSA à l'échelle du cluster. Valeurs possibles : restricted, baseline et privileged. |
POD_SECURITY_STANDARD_WARN |
✖ | ✔ | Facultatif, la valeur par défaut est restricted. Définit la stratégie de sécurité pour le mode warn du contrôleur PSA à l'échelle du cluster. Valeurs possibles : restricted, baseline et privileged. |
Réglage de Kubernetes (clusters basés sur une classe uniquement)
Les serveurs d'API Kubernetes, les kubelets et d'autres composants exposent divers indicateurs de configuration pour le réglage, par exemple l'indicateur --tls-cipher-suites pour configurer des suites de chiffrement permettant de renforcer la sécurité, l'indicateur --election-timeout pour augmenter le délai d'expiration etcd dans un cluster volumineux, etc.
ImportantCes variables de configuration Kubernetes sont destinées aux utilisateurs avancés. VMware ne garantit pas la fonctionnalité des clusters configurés avec des combinaisons arbitraires de ces paramètres.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
APISERVER_EXTRA_ARGS |
✔ | ✔ | Clusters basés sur une classe uniquement. Spécifiez les indicateurs kube-apiserver (kube-apiserver flags) au format « clé1=valeur1;clé2=valeur2 ». Par exemple, définissez des suites de chiffrement avec APISERVER_EXTRA_ARGS: "tls-min-version=VersionTLS12;tls-cipher-suites=TLS_RSA_WITH_AES_256_GCM_SHA384" |
CONTROLPLANE_KUBELET_EXTRA_ARGS |
✔ | ✔ | Clusters basés sur une classe uniquement. Spécifiez les indicateurs kubelet (kubelet flags) du plan de contrôle au format « clé1=valeur1;clé2=valeur2 ». Par exemple, limitez le nombre d'espaces de plan de contrôle avec CONTROLPLANE_KUBELET_EXTRA_ARGS: "max-pods=50" |
ETCD_EXTRA_ARGS |
✔ | ✔ | Clusters basés sur une classe uniquement. Spécifiez les indicateurs etcd (etcd flags) au format « clé1=valeur1;clé2=valeur2 ». Par exemple, si le cluster comprend plus de 500 nœuds ou si le stockage présente de mauvaises performances, vous pouvez augmenter heartbeat-interval et election-timeout avec ETCD_EXTRA_ARGS: "heartbeat-interval=300;election-timeout=2000" |
KUBE_CONTROLLER_MANAGER_EXTRA_ARGS |
✔ | ✔ | Clusters basés sur une classe uniquement. Spécifiez les indicateurs kube-controller-manager (kube-controller-manager flags) au format « clé1=valeur1;clé2=valeur2 ». Par exemple, désactivez le profilage de performances avec KUBE_CONTROLLER_MANAGER_EXTRA_ARGS: "profiling=false" |
KUBE_SCHEDULER_EXTRA_ARGS |
✔ | ✔ | Clusters basés sur une classe uniquement. Spécifiez les indicateurs kube-scheduler (kube-scheduler flags) au format « clé1=valeur1;clé2=valeur2 ». Par exemple, activez le mode d'accès à espace unique avec KUBE_SCHEDULER_EXTRA_ARGS: "feature-gates=ReadWriteOncePod=true" |
WORKER_KUBELET_EXTRA_ARGS |
✔ | ✔ | Clusters basés sur une classe uniquement. Spécifiez les indicateurs kubelet (kubelet flags) worker au format « clé1=valeur1;clé2=valeur2». Par exemple, limitez le nombre d'espaces worker avec WORKER_KUBELET_EXTRA_ARGS: "max-pods=50" |
Mise à l'échelle automatique du cluster
Les variables supplémentaires suivantes peuvent être configurées si ENABLE_AUTOSCALER est défini sur true. Pour plus d'informations sur la mise à l'échelle automatique du cluster, reportez-vous à la section Mettre à l'échelle des clusters de charge de travail.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
AUTOSCALER_MAX_NODES_TOTAL |
✖ | ✔ | Facultatif ; la valeur par défaut est 0. Nombre total maximal de nœuds dans le cluster, à la fois worker et de plan de contrôle. Définit la valeur du paramètre de mise à l'échelle automatique du cluster max-nodes-total. La mise à l'échelle automatique du cluster ne tente pas de mettre à l'échelle votre cluster au-delà de cette limite. Si cette option est définie sur 0, la mise à l'échelle automatique du cluster prend des décisions de mise à l'échelle en fonction des paramètres de SIZE minimal et maximal que vous configurez. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD |
✖ | ✔ | Facultatif ; la valeur par défaut est 10m. Définit la valeur du paramètre de mise à l'échelle automatique du cluster scale-down-delay-after-add. Durée pendant laquelle la mise à l'échelle automatique du cluster attend après une opération de montée en charge, puis reprend les analyses de réduction de charge. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE |
✖ | ✔ | Facultatif ; la valeur par défaut est 10s. Définit la valeur du paramètre de mise à l'échelle automatique du cluster scale-down-delay-after-delete. Durée pendant laquelle la mise à l'échelle automatique du cluster attend après la suppression d'un nœud, puis reprend les analyses de réduction de charge. |
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE |
✖ | ✔ | Facultatif ; la valeur par défaut est 3m. Définit la valeur du paramètre de mise à l'échelle automatique du cluster scale-down-delay-after-failure. Durée pendant laquelle la mise à l'échelle automatique du cluster attend après l'échec d'une réduction de charge, puis reprend les analyses de réduction de charge. |
AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME |
✖ | ✔ | Facultatif ; la valeur par défaut est 10m. Définit la valeur du paramètre de mise à l'échelle automatique du cluster scale-down-unneeded-time. Durée pendant laquelle la mise à l'échelle automatique du cluster doit attendre avant de réduire la charge d'un nœud éligible. |
AUTOSCALER_MAX_NODE_PROVISION_TIME |
✖ | ✔ | Facultatif ; la valeur par défaut est 15m. Définit la valeur du paramètre de mise à l'échelle automatique du cluster max-node-provision-time. Durée maximale pendant laquelle la mise à l'échelle automatique du cluster attend qu'un nœud soit provisionné. |
AUTOSCALER_MIN_SIZE_0 |
✖ | ✔ | Requis, toutes les instances IaaS. Nombre minimal de nœuds worker. La mise à l'échelle automatique du cluster ne tente pas de réduire le nombre de nœuds en dessous de cette limite. Pour les clusters prod sur AWS, AUTOSCALER_MIN_SIZE_0 définit le nombre minimal de nœuds worker dans la première zone de disponibilité. Si cette variable n'est pas définie, la valeur par défaut est WORKER_MACHINE_COUNT pour les clusters avec un seul nœud worker ou WORKER_MACHINE_COUNT_0 pour les clusters comportant plusieurs nœuds worker. |
AUTOSCALER_MAX_SIZE_0 |
✖ | ✔ | Requis, toutes les instances IaaS. Nombre maximal de nœuds worker. La mise à l'échelle automatique du cluster ne tente pas d'augmenter le nombre de nœuds au-delà de cette limite. Pour les clusters prod sur AWS, AUTOSCALER_MAX_SIZE_0 définit le nombre maximal de nœuds worker dans la première zone de disponibilité. Si cette variable n'est pas définie, la valeur par défaut est WORKER_MACHINE_COUNT pour les clusters avec un seul nœud worker ou WORKER_MACHINE_COUNT_0 pour les clusters comportant plusieurs nœuds worker. |
AUTOSCALER_MIN_SIZE_1 |
✖ | ✔ | Requis, utilisez cette variable uniquement pour les clusters prod sur AWS. Nombre minimal de nœuds worker dans la deuxième zone de disponibilité. La mise à l'échelle automatique du cluster ne tente pas de réduire le nombre de nœuds en dessous de cette limite. Si cette variable n'est pas définie, la valeur par défaut est WORKER_MACHINE_COUNT_1. |
AUTOSCALER_MAX_SIZE_1 |
✖ | ✔ | Requis, utilisez cette variable uniquement pour les clusters prod sur AWS. Nombre maximal de nœuds worker dans la deuxième zone de disponibilité. La mise à l'échelle automatique du cluster ne tente pas d'augmenter le nombre de nœuds au-delà de cette limite. Si cette variable n'est pas définie, la valeur par défaut est WORKER_MACHINE_COUNT_1. |
AUTOSCALER_MIN_SIZE_2 |
✖ | ✔ | Requis, utilisez cette variable uniquement pour les clusters prod sur AWS. Nombre minimal de nœuds worker dans la troisième zone de disponibilité. La mise à l'échelle automatique du cluster ne tente pas de réduire le nombre de nœuds en dessous de cette limite. Si cette variable n'est pas définie, la valeur par défaut est WORKER_MACHINE_COUNT_2. |
AUTOSCALER_MAX_SIZE_2 |
✖ | ✔ | Requis, utilisez cette variable uniquement pour les clusters prod sur AWS. Nombre maximal de nœuds worker dans la troisième zone de disponibilité. La mise à l'échelle automatique du cluster ne tente pas d'augmenter le nombre de nœuds au-delà de cette limite. Si cette variable n'est pas définie, la valeur par défaut est WORKER_MACHINE_COUNT_2. |
Configuration du proxy
Si votre environnement a un accès restreint à Internet ou inclut des proxys, vous pouvez éventuellement configurer Tanzu Kubernetes Grid pour envoyer le trafic HTTP et HTTPS sortant depuis kubelet, containerd et le plan de contrôle vers vos proxys.
Tanzu Kubernetes Grid vous permet d'activer les proxys de la manière suivante :
- Pour le cluster de gestion et un ou plusieurs clusters de charge de travail
- Pour le cluster de gestion uniquement
- Pour un ou plusieurs clusters de charge de travail
Pour plus d'informations, reportez-vous à Configurer des proxys dans Créer un fichier de configuration de cluster de gestion.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
TKG_HTTP_PROXY_ENABLED |
✔ | ✔ | Facultatif, pour envoyer le trafic HTTP(S) sortant du cluster de gestion vers un proxy, par exemple, dans un environnement à accès restreint à Internet, définissez cette variable sur |
TKG_HTTP_PROXY |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez configurer un proxy. Pour désactiver la configuration de votre proxy pour un cluster individuel, définissez cette variable sur
Par exemple, |
TKG_HTTPS_PROXY |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez configurer un proxy. Cela s'applique uniquement lorsque TKG_HTTP_PROXY_ENABLED = true. URL de votre proxy HTTPS. Vous pouvez définir cette variable sur la même valeur que TKG_HTTP_PROXY ou fournir une valeur différente. L'URL doit commencer par http://. Si vous définissez TKG_HTTPS_PROXY, vous devez également définir TKG_HTTP_PROXY. |
TKG_NO_PROXY |
✔ | ✔ | Facultatif. Cela s'applique uniquement lorsque Un ou plusieurs CIDR réseau ou noms d'hôte qui doivent contourner le proxy HTTP(S), séparés par des virgules et répertoriés sans espaces ou caractères génériques ( Par exemple, En interne, Tanzu Kubernetes Grid ajoute Si vous définissez TKG_NO_PROXY permet aux machines virtuelles de cluster de communiquer directement avec l'infrastructure qui exécute le même réseau, derrière le même proxy. Cela peut inclure, sans s'y limiter, votre infrastructure, votre serveur OIDC ou LDAP, Harbor, VMware NSX et NSX Advanced Load Balancer (vSphere). Définissez TKG_NO_PROXY pour inclure tous les points de terminaison auxquels les clusters doivent accéder, mais qui ne sont pas accessibles par vos proxys. |
TKG_PROXY_CA_CERT |
✔ | ✔ | Facultatif. Définissez cette variable si votre serveur proxy utilise un certificat auto-signé. Fournissez le certificat d'autorité de certification au format codé en base64, par exemple, TKG_PROXY_CA_CERT: "LS0t[...]tLS0tLQ=="". |
TKG_NODE_SYSTEM_WIDE_PROXY |
✔ | ✔ | (Version d'évaluation technique) Facultatif. Place les paramètres suivants dans export HTTP_PROXY=$TKG_HTTP_PROXY Lorsque les utilisateurs se connectent au nœud TKG via le protocole SSH et exécutent des commandes, celles-ci utilisent par défaut les variables définies. Les processus systemd ne sont pas affectés. |
Configuration de CNI Antrea
Variables facultatives supplémentaires à définir si la variable CNI est définie sur antrea. Pour plus d'informations, reportez-vous à la section Configurer la CNI Antrea dans Créer un fichier de configuration de cluster de gestion.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
ANTREA_DISABLE_UDP_TUNNEL_OFFLOAD |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour désactiver le déchargement de la somme de contrôle UDP d'Antrea. La définition de cette variable sur true évite les problèmes connus avec les pilotes réseau de sous-couche et de carte réseau physique. |
ANTREA_EGRESS |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Activez cette variable pour définir l'adresse IP SNAT utilisée pour le trafic d'espace sortant du cluster. Pour plus d'informations, reportez-vous à la section Sortie dans la documentation Antrea. |
ANTREA_EGRESS_EXCEPT_CIDRS |
✔ | ✔ | Facultatif. Les plages CIDR sortantes ne seront pas SNAT pour le trafic d'espace sortant. Incluez des guillemets (""). Par exemple, "10.0.0.0/6". |
ANTREA_ENABLE_USAGE_REPORTING |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Active ou désactive les rapports d'utilisation (télémétrie). |
ANTREA_FLOWEXPORTER |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour la visibilité du flux réseau. L'exportateur de flux interroge périodiquement les flux conntrack et les exporte sous forme d'enregistrements de flux IPFIX. Pour plus d'informations, reportez-vous à la section Visibilité du flux réseau dans Antrea dans la documentation Antrea. |
ANTREA_FLOWEXPORTER_ACTIVE_TIMEOUT |
✔ | ✔ | Facultatif ; la valeur par défaut est Remarque : les unités de temps valides sont |
ANTREA_FLOWEXPORTER_COLLECTOR_ADDRESS |
✔ | ✔ | Facultatif. Cette variable fournit l'adresse du collecteur IPFIX. Incluez des guillemets (""). La valeur par défaut est "flow-aggregator.flow-aggregator.svc:4739:tls". Pour plus d'informations, reportez-vous à la section Visibilité du flux réseau dans Antrea dans la documentation Antrea. |
ANTREA_FLOWEXPORTER_IDLE_TIMEOUT |
✔ | ✔ | Facultatif ; la valeur par défaut est Remarque : les unités de temps valides sont |
ANTREA_FLOWEXPORTER_POLL_INTERVAL |
✔ | ✔ | Facultatif ; la valeur par défaut est Remarque : les unités de temps valides sont |
ANTREA_IPAM |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour allouer des adresses IP à partir de pools d'adresses IP. L'ensemble souhaité de plages d'adresses IP, éventuellement avec des VLAN, est défini avec la CRD IPPool. Pour plus d'informations, reportez-vous à la section Capacités IPAM Antrea dans la documentation Antrea. |
ANTREA_KUBE_APISERVER_OVERRIDE |
✔ | ✔ | Facultatif. Spécifiez l'adresse du serveur d'API Kubernetes. Pour plus d'informations, reportez-vous à la section Suppression de kube-proxy dans la documentation Antrea. |
ANTREA_MULTICAST |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour activer le trafic multidiffusion dans le réseau du cluster (entre les espaces) et entre le réseau externe et le réseau du cluster. |
ANTREA_MULTICAST_INTERFACES |
✔ | ✔ | Facultatif. Noms de l'interface sur les nœuds utilisés pour transférer le trafic multidiffusion. Incluez des guillemets (""). Par exemple, "eth0". |
ANTREA_NETWORKPOLICY_STATS |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Activez cette variable pour collecter des statistiques NetworkPolicy. Les données statistiques incluent le nombre total de sessions, de paquets et d'octets autorisés ou refusés par une NetworkPolicy. |
ANTREA_NO_SNAT |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour désactiver SNAT (Source Network Address Translation). |
ANTREA_NODEPORTLOCAL |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Définissez cette variable sur false pour désactiver le mode NodePortLocal. Pour plus d'informations, reportez-vous à la section NodePortLocal (NPL) dans la documentation Antrea. |
ANTREA_NODEPORTLOCAL_ENABLED |
✔ | ✔ | Facultatif. Définissez cette variable sur true pour activer le mode NodePortLocal, comme décrit dans NodePortLocal (NPL) dans la documentation Antrea. |
ANTREA_NODEPORTLOCAL_PORTRANGE |
✔ | ✔ | Facultatif ; la valeur par défaut est 61000-62000. Pour plus d'informations, reportez-vous à la section NodePortLocal (NPL) dans la documentation Antrea. |
ANTREA_POLICY |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Active ou désactive l'API de stratégie native Antrea, qui sont des CRD de stratégie spécifiques à Antrea. En outre, la mise en œuvre des stratégies réseau Kubernetes reste active lorsque cette variable est activée. Pour plus d'informations sur l'utilisation des stratégies réseau, reportez-vous à la section CRD de stratégie réseau Antrea dans la documentation Antrea. |
ANTREA_PROXY |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Active ou désactive AntreaProxy, afin de remplacer kube-proxy pour le trafic du service entre espace et ClusterIP, pour de meilleures performances et une latence inférieure. Notez que kube-proxy est toujours utilisé pour d'autres types de trafic de service. Pour plus d'informations sur l'utilisation des proxys, reportez-vous à la section AntreaProxy dans la documentation Antrea. |
ANTREA_PROXY_ALL |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Active ou désactive AntreaProxy afin de gérer tout le trafic de service, y compris le trafic NodePort, LoadBalancer et ClusterIP. Pour remplacer kube-proxy par AntreaProxy, ANTREA_PROXY_ALL doit être activé. Pour plus d'informations sur l'utilisation des proxys, reportez-vous à la section AntreaProxy dans la documentation Antrea. |
ANTREA_PROXY_LOAD_BALANCER_IPS |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Définissez cette variable sur false pour diriger le trafic d'équilibrage de charge vers l'équilibrage de charge externe. |
ANTREA_PROXY_NODEPORT_ADDRS |
✔ | ✔ | Facultatif. Adresse IPv4 ou IPv6 pour NodePort. Incluez des guillemets (""). |
ANTREA_PROXY_SKIP_SERVICES |
✔ | ✔ | Facultatif. Tableau de valeurs de chaîne qui peut être utilisé pour indiquer une liste de services qu'AntreaProxy doit ignorer. Le trafic vers ces services ne fera pas l'objet d'un équilibrage de charge. Incluez des guillemets (""). Par exemple, un ClusterIP valide (tel que 10.11.1.2) ou un nom de service avec un espace de noms (tel que kube-system/kube-dns) sont des valeurs valides. Pour plus d'informations, reportez-vous à la section Cas d'utilisation spécifiques dans la documentation Antrea. |
ANTREA_SERVICE_EXTERNALIP |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour permettre à un contrôleur d'allouer des adresses IP externes à partir d'une ressource « ExternalIPPool » pour les services de type « LoadBalancer ». Pour plus d'informations sur la mise en œuvre des services de type « LoadBalancer », reportez-vous à la section Service de type LoadBalancer dans la documentation d'Antrea. |
ANTREA_TRACEFLOW |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Pour plus d'informations sur l'utilisation de Traceflow, reportez-vous au Guide de l'utilisateur de Traceflow dans la documentation Antrea. |
ANTREA_TRAFFIC_ENCAP_MODE |
✔ | ✔ | Facultatif ; la valeur par défaut est Remarque : les modes Le mode |
ANTREA_TRANSPORT_INTERFACE |
✔ | ✔ | Facultatif. Nom de l'interface sur le nœud utilisé pour le tunneling ou le routage du trafic. Incluez des guillemets (""). Par exemple, "eth0". |
ANTREA_TRANSPORT_INTERFACE_CIDRS |
✔ | ✔ | Facultatif. CIDR réseau de l'interface sur le nœud qui est utilisé pour le tunneling ou le routage du trafic. Incluez des guillemets (""). Par exemple, "10.0.0.2/24". |
Contrôles de santé de la machine
Définissez les variables suivantes si vous souhaitez configurer les contrôles de santé de la machine pour les clusters de gestion et de charge de travail. Pour plus d'informations, reportez-vous à la section Configurer les contrôles de santé de la machine dans Créer un fichier de configuration de cluster de gestion. Pour plus d'informations sur l'exécution d'opérations de contrôle de santé de la machine après le déploiement du cluster, reportez-vous à la section Configurer les contrôles de santé de la machine pour les clusters de charge de travail.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
ENABLE_MHC |
✔ | basé sur une classe : ✖ basé sur un plan : ✔ |
Facultatif, définissez cette variable sur true ou false pour activer ou désactiver le contrôleur MachineHealthCheck sur les nœuds de plan de contrôle et worker du cluster de gestion ou de charge de travail cible. Vous pouvez également laisser ce champ vide et définir ENABLE_MHC_CONTROL_PLANE et ENABLE_MHC_WORKER_NODE séparément pour les nœuds de plan de contrôle et worker. La valeur par défaut est vide.Le contrôleur assure la surveillance de la santé de la machine et la réparation automatique. Pour les clusters de charge de travail créés par vSphere with Tanzu, définissez la variable sur false. |
ENABLE_MHC_CONTROL_PLANE |
✔ | Facultatif ; la valeur par défaut est true. Pour plus d'informations, reportez-vous au tableau ci-dessous. |
|
ENABLE_MHC_WORKER_NODE |
✔ | Facultatif ; la valeur par défaut est true. Pour plus d'informations, reportez-vous au tableau ci-dessous. |
|
MHC_MAX_UNHEALTHY_CONTROL_PLANE |
✔ | ✖ | Facultatif ; clusters basés sur une classe uniquement. Défini sur 100% par défaut. Si le nombre de machines défectueuses dépasse la valeur que vous avez définie, le contrôleur MachineHealthCheck n'effectue pas de correction. |
MHC_MAX_UNHEALTHY_WORKER_NODE |
✔ | ✖ | Facultatif ; clusters basés sur une classe uniquement. Défini sur 100% par défaut. Si le nombre de machines défectueuses dépasse la valeur que vous avez définie, le contrôleur MachineHealthCheck n'effectue pas de correction. |
MHC_FALSE_STATUS_TIMEOUT |
✔ | basé sur une classe : ✖ basé sur un plan : ✔ |
Facultatif ; la valeur par défaut est 12m. Durée pendant laquelle le contrôleur MachineHealthCheck autorise la condition Ready d'un nœud à rester False avant de considérer la machine comme défectueuse et de la recréer. |
MHC_UNKNOWN_STATUS_TIMEOUT |
✔ | Facultatif ; la valeur par défaut est 5m. Durée pendant laquelle le contrôleur MachineHealthCheck autorise la condition Ready d'un nœud à rester Unknown avant de considérer la machine comme défectueuse et de la recréer. |
|
NODE_STARTUP_TIMEOUT |
✔ | Facultatif ; la valeur par défaut est 20m. Durée pendant laquelle le contrôleur MachineHealthCheck attend qu'un nœud rejoigne un cluster avant de considérer la machine comme défectueuse et de la recréer. |
|
Utilisez le tableau ci-dessous pour déterminer comment configurer les variables ENABLE_MHC, ENABLE_MHC_CONTROL_PLANE et ENABLE_MHC_WORKER_NODE.
Valeur de ENABLE_MHC |
Valeur de ENABLE_MHC_CONTROL_PLANE |
Valeur de ENABLE_MHC_WORKER_NODE |
Correction du plan de contrôle activée ? | Correction du nœud worker activée ? |
|---|---|---|---|---|
true / Emptytrue / Emptytrue / Vide |
true/false/vide |
true/false/vide |
Oui | Oui |
false |
true/vide |
true/vide |
Oui | Oui |
false |
true/vide |
false |
Oui | Non |
false |
false |
true/vide |
Non | Oui |
Configuration du registre d'images privé
Si vous déployez des clusters de gestion Tanzu Kubernetes Grid et des clusters Kubernetes dans des environnements qui ne sont pas connectés à Internet, vous devez configurer un référentiel d'images privé dans votre pare-feu et le remplir avec les images Tanzu Kubernetes Grid. Pour plus d'informations sur la configuration d'un référentiel d'images privé, reportez-vous à la section Préparer un environnement à accès restreint à Internet.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
ADDITIONAL_IMAGE_REGISTRY_1, ADDITIONAL_IMAGE_REGISTRY_2, ADDITIONAL_IMAGE_REGISTRY_3 |
✔ | ✔ | Charge de travail basée sur une classe et clusters de gestion autonomes uniquement. Adresses IP ou noms de domaine complets de trois registres privés approuvés au maximum, en plus du registre d'images principal défini par TKG_CUSTOM_IMAGE_REPOSITORY, pour que les nœuds de cluster de charge de travail y accèdent. Reportez-vous à la section Registres approuvés pour un cluster basé sur une classe. |
ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_2_CA_CERTIFICATE, ADDITIONAL_IMAGE_REGISTRY_3_CA_CERTIFICATE |
✔ | ✔ | Charge de travail basée sur une classe et clusters de gestion autonomes uniquement. Certificats d'autorité de certification au format codé en base64 de registres d'images privés configurés avec la valeur ADDITIONAL_IMAGE_REGISTRY-* ci-dessus. Par exemple, ADDITIONAL_IMAGE_REGISTRY_1_CA_CERTIFICATE: "LS0t[...]tLS0tLQ==". |
ADDITIONAL_IMAGE_REGISTRY_1_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_2_SKIP_TLS_VERIFY, ADDITIONAL_IMAGE_REGISTRY_3_SKIP_TLS_VERIFY |
✔ | ✔ | Charge de travail basée sur une classe et clusters de gestion autonomes uniquement. Définissez cette variable sur true pour tous les registres d'images privés configurés avec ADDITIONAL_IMAGE_REGISTRY-* ci-dessus qui utilisent un certificat auto-signé, mais pas ADDITIONAL_IMAGE_REGISTRY_*_CA_CERTIFICATE. Étant donné que le Webhook de connectivité Tanzu injecte le certificat d'autorité de certification Harbor dans les nœuds de cluster, ADDITIONAL_IMAGE_REGISTRY_*_SKIP_TLS_VERIFY doit toujours être défini sur false lors de l'utilisation de Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY |
✔ | ✔ | Requis si vous déployez Tanzu Kubernetes Grid dans un environnement à accès restreint à Internet. Fournissez l'adresse IP ou le nom de domaine complet du registre privé qui contient des images système TKG à partir desquelles les clusters démarrent, appelé registre d'images principal ci-dessous. Par exemple, custom-image-repository.io/yourproject. |
TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY |
✔ | ✔ | Facultatif. Définissez cette variable sur true si votre registre d'images principal privé utilise un certificat auto-signé et que vous n'utilisez pas TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE. Étant donné que le Webhook de connectivité Tanzu injecte le certificat d'autorité de certification Harbor dans les nœuds de cluster, TKG_CUSTOM_IMAGE_REPOSITORY_SKIP_TLS_VERIFY doit toujours être défini sur false lors de l'utilisation de Harbor. |
TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE |
✔ | ✔ | Facultatif. Définissez cette variable si votre registre d'images principal privé utilise un certificat auto-signé. Fournissez le certificat d'autorité de certification au format codé en base64, par exemple, TKG_CUSTOM_IMAGE_REPOSITORY_CA_CERTIFICATE: "LS0t[...]tLS0tLQ==". |
vSphere
Les options du tableau ci-dessous sont les options minimales que vous spécifiez dans le fichier de configuration de cluster lors du déploiement de clusters de charge de travail sur vSphere. La plupart de ces options sont les mêmes pour le cluster de charge de travail et le cluster de gestion que vous utilisez pour le déployer.
Pour plus d'informations sur les fichiers de configuration de vSphere, reportez-vous aux sections Configuration du cluster de gestion pour vSphere et Déployer des clusters de charge de travail pour vSphere.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
DEPLOY_TKG_ON_VSPHERE7 |
✔ | ✔ | Facultatif. Si vous effectuez un déploiement sur vSphere 7 ou 8, définissez cette variable sur true pour ignorer l'invite sur le déploiement sur vSphere 7 ou 8, ou sur false. Clusters de gestion sur vSphere with Tanzu. |
ENABLE_TKGS_ON_VSPHERE7 |
✔ | ✔ | Facultatif, si vous effectuez un déploiement vers vSphere 7 ou 8, définissez cette variable sur true pour être redirigé vers la page de l'interface utilisateur d'activation de vSphere with Tanzu, ou sur false. Clusters de gestion sur vSphere with Tanzu. |
NTP_SERVERS |
✔ | ✔ | Clusters basés sur une classe uniquement. Configure le serveur NTP du cluster si vous déployez des clusters dans un environnement vSphere qui ne dispose pas de l'option DHCP 42, par exemple NTP_SERVERS: time.google.com. Pour configurer cette option dans un cluster hérité basé sur un plan, utilisez une superposition ytt comme décrit dans la section Configuration de NTP sans option DHCP 42 (vSphere). |
TKG_IP_FAMILY |
✔ | ✔ | Facultatif. Pour déployer un cluster sur vSphere 7 ou 8 avec IPv6 pure, définissez cette variable sur ipv6. Pour la mise en réseau à double pile (expérimentale), reportez-vous à la section Clusters à double pile. |
VIP_NETWORK_INTERFACE |
✔ | ✔ | Facultatif. Définissez cette variable sur eth0, eth1, etc. Nom de l'interface réseau (par exemple, une interface Ethernet). Défini sur eth0 par défaut. |
VSPHERE_AZ_CONTROL_PLANE_MATCHING_LABELS |
✔ | ✔ | Pour les clusters déployés sur plusieurs zones de disponibilité, cette variable définit des étiquettes de sélecteur clé/valeur pour spécifier les zones de disponibilité dans lesquelles les nœuds de plan de contrôle du cluster peuvent se déployer. Cela permet de configurer les nœuds, par exemple, pour qu'ils s'exécutent dans toutes les zones de disponibilité d'une région et d'un environnement spécifiés sans répertorier les zones de disponibilité individuellement, par exemple : "region=us-west-1,environment=staging". Reportez-vous à la section Exécution de clusters sur plusieurs zones de disponibilité |
VSPHERE_AZ_0, VSPHERE_AZ_1, VSPHERE_AZ_2 |
✔ | ✔ | Facultatif Zones de déploiement sur lesquelles les déploiements de machines dans un cluster sont déployés. Reportez-vous à la section Exécution de clusters sur plusieurs zones de disponibilité |
VSPHERE_CONTROL_PLANE_DISK_GIB |
✔ | ✔ | Facultatif. Taille en gigaoctets du disque pour les machines virtuelles du nœud de plan de contrôle. Incluez des guillemets (""). Par exemple, "30". |
VSPHERE_CONTROL_PLANE_ENDPOINT |
✔ | ✔ | Requis pour Kube-Vip. Adresse IP virtuelle statique ou nom de domaine complet (FQDN) mappé à une adresse statique, pour les demandes d'API au cluster. Ce paramètre est requis si vous utilisez Kube-VIP pour votre point de terminaison de serveur d'API, tel que configuré en définissant AVI_CONTROL_PLANE_HA_PROVIDER sur falseSi vous utilisez NSX Advanced Load Balancer, AVI_CONTROL_PLANE_HA_PROVIDER: true, vous pouvez :
|
VSPHERE_CONTROL_PLANE_ENDPOINT_PORT |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez remplacer le port du serveur d'API Kubernetes pour les déploiements sur vSphere avec NSX Advanced Load Balancer. Le port par défaut est 6443. Pour remplacer le port du serveur d'API Kubernetes pour les déploiements sur vSphere sans NSX Advanced Load Balancer, définissez CLUSTER_API_SERVER_PORT. |
VSPHERE_CONTROL_PLANE_MEM_MIB |
✔ | ✔ | Facultatif. Quantité de mémoire en mégaoctets pour les machines virtuelles du nœud de plan de contrôle. Incluez des guillemets (""). Par exemple, "2048". |
VSPHERE_CONTROL_PLANE_NUM_CPUS |
✔ | ✔ | Facultatif. Nombre de CPU pour les machines virtuelles du nœud de plan de contrôle. Incluez des guillemets (""). La valeur doit être d'au moins 2. Par exemple, "2". |
VSPHERE_DATACENTER |
✔ | ✔ | Requis. Nom du centre de données dans lequel déployer le cluster, tel qu'il apparaît dans l'inventaire vSphere. Par exemple, /MY-DATACENTER. |
VSPHERE_DATASTORE |
✔ | ✔ | Requis. Nom de la banque de données vSphere que le cluster doit utiliser, tel qu'il apparaît dans l'inventaire vSphere. Par exemple, /MY-DATACENTER/datastore/MyDatastore. |
VSPHERE_FOLDER |
✔ | ✔ | Requis. Nom d'un dossier de machine virtuelle existant dans lequel placer les machines virtuelles Tanzu Kubernetes Grid, tel qu'il apparaît dans l'inventaire vSphere. Par exemple, si vous avez créé un dossier nommé TKG, le chemin d'accès est /MY-DATACENTER/vm/TKG. |
VSPHERE_INSECURE |
✔ | ✔ | Facultatif. Définissez cette variable sur true pour contourner la vérification de l'empreinte numérique. Si la valeur est false, définissez VSPHERE_TLS_THUMBPRINT. |
VSPHERE_MTU |
✔ | ✔ | Facultatif. Définissez la taille de l'unité de transmission maximale (MTU) pour les nœuds de cluster de gestion et de charge de travail sur un commutateur vSphere Standard. La valeur par défaut est de 1 500 si elle n'est pas définie. La valeur maximale est de 9 000. Reportez-vous à la section Configurer la MTU du nœud de cluster. |
VSPHERE_NETWORK |
✔ | ✔ | Requis. Nom d'un réseau vSphere existant à utiliser comme réseau de service Kubernetes, tel qu'il apparaît dans l'inventaire vSphere. Par exemple, VM Network. |
VSPHERE_PASSWORD |
✔ | ✔ | Requis. Mot de passe du compte d'utilisateur vSphere. Cette valeur est codée en base64 lorsque vous exécutez tanzu cluster create. |
VSPHERE_REGION |
✔ | ✔ | Facultatif. Balise pour la région dans vCenter, utilisée pour :
|
VSPHERE_RESOURCE_POOL |
✔ | ✔ | Requis. Nom d'un pool de ressources existant dans lequel placer cette instance de Tanzu Kubernetes Grid, tel qu'il apparaît dans l'inventaire vSphere. Pour utiliser le pool de ressources racine d'un cluster, entrez le chemin d'accès complet. Par exemple, pour un cluster nommé cluster0 dans le centre de données MY-DATACENTER, le chemin d'accès complet est /MY-DATACENTER/host/cluster0/Resources. |
VSPHERE_SERVER |
✔ | ✔ | Requis. Adresse IP ou nom de domaine complet de l'instance de vCenter Server sur laquelle vous souhaitez déployer le cluster de charge de travail. |
VSPHERE_SSH_AUTHORIZED_KEY |
✔ | ✔ | Requis. Collez le contenu de la clé publique SSH que vous avez créée dans Déployer un cluster de gestion pour vSphere. Par exemple, "ssh-rsa NzaC1yc2EA [...] hnng2OYYSl+8ZyNz3fmRGX8uPYqw== [email protected]". |
VSPHERE_STORAGE_POLICY_ID |
✔ | ✔ | Facultatif. Nom d'une stratégie de stockage de machine virtuelle pour le cluster de gestion, tel qu'il apparaît dans Stratégies et profils > Stratégies de stockage de machine virtuelle. Si la variable VSPHERE_DATASTORE est définie, la stratégie de stockage doit l'inclure. Sinon, le processus de création du cluster choisit une banque de données compatible avec la stratégie. |
VSPHERE_TEMPLATE |
✖ | ✔ | Facultatif. Spécifiez le chemin d'accès à un fichier OVA si vous utilisez plusieurs images OVA personnalisées pour la même version de Kubernetes, en utilisant le format /MY-DC/vm/MY-FOLDER-PATH/MY-IMAGE. Pour plus d'informations, reportez-vous à la section Déployer un cluster avec une image OVA personnalisée. |
VSPHERE_TLS_THUMBPRINT |
✔ | ✔ | Requis si VSPHERE_INSECURE est false. Empreinte numérique du certificat vCenter Server. Pour plus d'informations sur l'obtention de l'empreinte numérique du certificat vCenter Server, reportez-vous à la section Obtenir les empreintes numériques du certificat vSphere. Cette valeur peut être ignorée si l'utilisateur souhaite utiliser une connexion non sécurisée en définissant VSPHERE_INSECURE sur true. |
VSPHERE_USERNAME |
✔ | ✔ | Requis. Compte d'utilisateur vSphere, y compris le nom de domaine, avec les privilèges requis pour l'opération Tanzu Kubernetes Grid. Par exemple, [email protected]. |
VSPHERE_WORKER_DISK_GIB |
✔ | ✔ | Facultatif. Taille en gigaoctets du disque pour les machines virtuelles du nœud worker. Incluez des guillemets (""). Par exemple, "50". |
VSPHERE_WORKER_MEM_MIB |
✔ | ✔ | Facultatif. Quantité de mémoire en mégaoctets pour les machines virtuelles du nœud worker. Incluez des guillemets (""). Par exemple, "4096". |
VSPHERE_WORKER_NUM_CPUS |
✔ | ✔ | Facultatif. Nombre de CPU pour les machines virtuelles du nœud worker. Incluez des guillemets (""). La valeur doit être d'au moins 2. Par exemple, "2". |
VSPHERE_ZONE |
✔ | ✔ | Facultatif. Balise pour la zone dans vCenter, utilisée pour :
|
Équilibrage de charge Kube-VIP (version d'évaluation technique)
Pour plus d'informations sur la configuration de Kube-VIP en tant que service d'équilibrage de charge L4, reportez-vous à la section Équilibreur de charge Kube-VIP.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
KUBEVIP_LOADBALANCER_ENABLE |
✖ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true ou false. Active Kube-VIP en tant qu'équilibreur de charge pour les charges de travail. Si la variable est définie sur true, vous devez spécifier l'une des variables ci-dessous. |
KUBEVIP_LOADBALANCER_IP_RANGES |
✖ | ✔ | Liste de plages d'adresses IP sans chevauchement à allouer pour une adresse IP de service de type LoadBalancer. Par exemple : 10.0.0.1-10.0.0.23,10.0.2.1-10.0.2.24. |
KUBEVIP_LOADBALANCER_CIDRS |
✖ | ✔ | Liste de CIDR qui ne se chevauchent pas pour une adresse IP de service de type LoadBalancer. Par exemple : 10.0.0.0/24,10.0.2/24. Remplace le paramètre pour KUBEVIP_LOADBALANCER_IP_RANGES. |
NSX Advanced Load Balancer
Pour plus d'informations sur le déploiement de NSX Advanced Load Balancer, reportez-vous à la section Installer NSX Advanced Load Balancer.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
AVI_ENABLE |
✔ | ✖ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true ou false. Active NSX Advanced Load Balancer en tant qu'équilibrage de charge pour les charges de travail. Si la variable est true, vous devez définir les variables requises répertoriées dans la section NSX Advanced Load Balancer ci-dessous. |
AVI_ADMIN_CREDENTIAL_NAME |
✔ | ✖ | Facultatif ; la valeur par défaut est avi-controller-credentials. Nom du secret Kubernetes qui contient le nom d'utilisateur et le mot de passe de l'administrateur du contrôleur NSX Advanced Load Balancer. |
AVI_AKO_IMAGE_PULL_POLICY |
✔ | ✖ | Facultatif ; la valeur par défaut est IfNotPresent. |
AVI_CA_DATA_B64 |
✔ | ✖ | Requis. Contenu de l’autorité de certification du contrôleur utilisée pour signer le certificat du contrôleur. Il doit être codé en base64. Récupérez le contenu des certificats personnalisés non codés comme décrit dans la section Configuration du contrôleur Avi : certificat personnalisé. |
AVI_CA_NAME |
✔ | ✖ | Facultatif ; la valeur par défaut est avi-controller-ca. Nom du secret Kubernetes qui détient l'autorité de certification du contrôleur NSX Advanced Load Balancer. |
AVI_CLOUD_NAME |
✔ | ✖ | Requis. Le cloud que vous avez créé dans votre déploiement NSX Advanced Load Balancer. Par exemple, Default-Cloud. |
AVI_CONTROLLER |
✔ | ✖ | Requis. Adresse IP ou nom d’hôte du contrôleur NSX Advanced Load Balancer. |
AVI_CONTROL_PLANE_HA_PROVIDER |
✔ | ✔ | Requis. Définissez cette valeur sur true pour utiliser NSX Advanced Load Balancer comme point de terminaison du serveur d'API du plan de contrôle ou false pour utiliser Kube-Vip comme point de terminaison du plan de contrôle. |
AVI_CONTROL_PLANE_NETWORK |
✔ | ✖ | Facultatif. Définit le réseau VIP du plan de contrôle du cluster de charge de travail. Utilisez cette variable lorsque vous souhaitez configurer un réseau VIP distinct pour les clusters de charge de travail. Ce champ est facultatif et, s'il est laissé vide, le même réseau que AVI_DATA_NETWORK sera utilisé. |
AVI_CONTROL_PLANE_NETWORK_CIDR |
✔ | ✖ | Facultatif ; la valeur est définie par défaut sur le même réseau que AVI_DATA_NETWORK_CIDR. CIDR du sous-réseau à utiliser pour le plan de contrôle du cluster de charge de travail. Utilisez cette variable lorsque vous souhaitez configurer un réseau VIP distinct pour les clusters de charge de travail. Vous pouvez voir le CIDR de sous-réseau d'un réseau particulier dans la vue Infrastructure - Réseaux de l'interface NSX Advanced Load Balancer. |
AVI_DATA_NETWORK |
✔ | ✖ | Requis. Nom du réseau sur lequel le sous-réseau IP flottant ou le pool d'adresses IP est attribué à un équilibrage de charge pour le trafic vers les applications hébergées sur des clusters de charge de travail. Ce réseau doit être présent dans la même instance de vCenter Server que le réseau Kubernetes utilisé par Tanzu Kubernetes Grid, que vous spécifiez dans la variable SERVICE_CIDR. Cela permet à NSX Advanced Load Balancer de détecter le réseau Kubernetes dans vCenter Server et de déployer et de configurer des moteurs de service. |
AVI_DATA_NETWORK_CIDR |
✔ | ✖ | Requis. CIDR du sous-réseau à utiliser pour l'adresse IP virtuelle de l'équilibrage de charge. Cela provient de l'un des sous-réseaux configurés du réseau VIP. Vous pouvez voir le CIDR de sous-réseau d'un réseau particulier dans la vue Infrastructure - Réseaux de l'interface NSX Advanced Load Balancer. |
AVI_DISABLE_INGRESS_CLASS |
✔ | ✖ | Facultatif ; la valeur par défaut est false. Désactivez la classe d'entrée.Remarque : Cette variable ne fonctionne pas dans TKG v2.3. Pour obtenir une solution, reportez-vous à la section Problème connu Certaines variables de configuration ALB NSX ne fonctionnent pas dans les notes de mise à jour. |
AVI_DISABLE_STATIC_ROUTE_SYNC |
✔ | ✖ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true si les réseaux d'espace sont accessibles à partir du moteur de service NSX ALB.Remarque : Cette variable ne fonctionne pas dans TKG v2.3. Pour obtenir une solution, reportez-vous à la section Problème connu Certaines variables de configuration ALB NSX ne fonctionnent pas dans les notes de mise à jour. |
AVI_INGRESS_DEFAULT_INGRESS_CONTROLLER |
✔ | ✖ | Facultatif ; la valeur par défaut est false. Utilisez AKO comme contrôleur d'entrée par défaut.Remarque : Cette variable ne fonctionne pas dans TKG v2.3. Pour obtenir une solution, reportez-vous à la section Problème connu Certaines variables de configuration ALB NSX ne fonctionnent pas dans les notes de mise à jour. |
AVI_INGRESS_NODE_NETWORK_LIST |
✔ | ✖ | Spécifie le nom du réseau de groupe de ports dont font partie vos nœuds et le CIDR associé que la CNI alloue à chaque nœud pour que ce nœud l'attribue à ses espaces. Il est préférable de le mettre à jour dans le fichier AKODeploymentConfig (reportez-vous à la section Entrée L7 en mode ClusterIP), mais si vous utilisez le fichier de configuration du cluster, le format est semblable à : '[{"networkName": "vsphere-portgroup","cidrs": ["100.64.42.0/24"]}]' |
AVI_INGRESS_SERVICE_TYPE |
✔ | ✖ | Facultatif. Spécifie si l'AKO fonctionne en mode ClusterIP, NodePort ou NodePortLocal. Défini sur NodePort par défaut. |
AVI_INGRESS_SHARD_VS_SIZE |
✔ | ✖ | Facultatif. AKO utilise une logique de partitionnement pour les objets d'entrée de couche 7. Un service virtuel partitionné implique l'hébergement de plusieurs entrées non sécurisées ou sécurisées hébergées par une adresse IP virtuelle. Définissez cette variable sur LARGE, MEDIUM ou SMALL. La valeur par défaut est SMALL. Utilisez cette option pour contrôler le nombre de services virtuels de couche 7. Cela s'applique à la fois aux services virtuels sécurisés et non sécurisés, mais ne s'applique pas au relais. |
AVI_LABELS |
✔ | ✔ | Facultatif. Lorsque cette variable est définie, NSX Advanced Load Balancer est activé uniquement sur les clusters de charge de travail qui disposent de cette étiquette. Incluez des guillemets (""). Par exemple, AVI_LABELS: "{foo: 'bar'}". |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_CIDR |
✔ | ✖ | Facultatif. CIDR du sous-réseau à utiliser pour le plan de contrôle du cluster de gestion. Utilisez lorsque vous souhaitez configurer un réseau VIP distinct pour le plan de contrôle du cluster de gestion. Vous pouvez voir le CIDR de sous-réseau d'un réseau particulier dans la vue Infrastructure - Réseaux de l'interface NSX Advanced Load Balancer. Ce champ est facultatif et, s'il est laissé vide, le même réseau que AVI_DATA_NETWORK_CIDR sera utilisé. |
AVI_MANAGEMENT_CLUSTER_CONTROL_PLANE_VIP_NETWORK_NAME |
✔ | ✖ | Facultatif. Définit le réseau VIP du plan de contrôle du cluster de gestion. Utilisez lorsque vous souhaitez configurer un réseau VIP distinct pour le plan de contrôle du cluster de gestion. Ce champ est facultatif et, s'il est laissé vide, le même réseau que AVI_DATA_NETWORK sera utilisé. |
AVI_MANAGEMENT_CLUSTER_SERVICE_ENGINE_GROUP |
✔ | ✖ | Facultatif. Spécifie le nom du groupe de moteurs de service qui doit être utilisé par AKO dans le cluster de gestion. Ce champ est facultatif et, s'il est laissé vide, le même réseau que AVI_SERVICE_ENGINE_GROUP sera utilisé. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_NAME |
✔ | ✖ | Facultatif ; la valeur est définie par défaut sur le même réseau que AVI_DATA_NETWORK. Nom du réseau dans lequel vous attribuez un sous-réseau IP flottant ou un pool d'adresses IP à un équilibrage de charge pour le plan de contrôle du cluster de gestion et du cluster de charge de travail (si vous utilisez NSX ALB pour fournir la haute disponibilité du plan de contrôle). Ce réseau doit être présent dans la même instance de vCenter Server que le réseau Kubernetes utilisé par Tanzu Kubernetes Grid, que vous spécifiez dans la variable « SERVICE_CIDR » pour le cluster de gestion. Cela permet à NSX Advanced Load Balancer de détecter le réseau Kubernetes dans vCenter Server et de déployer et de configurer des moteurs de service. |
AVI_MANAGEMENT_CLUSTER_VIP_NETWORK_CIDR |
✔ | ✖ | Facultatif ; la valeur est définie par défaut sur le même réseau que AVI_DATA_NETWORK_CIDR. CIDR du sous-réseau à utiliser pour l'adresse IP virtuelle de l'équilibrage de charge du plan de contrôle du cluster de gestion et du cluster de charge de travail (si vous utilisez NSX ALB pour fournir la haute disponibilité du plan de contrôle). Cela provient de l'un des sous-réseaux configurés du réseau VIP. Vous pouvez voir le CIDR de sous-réseau d'un réseau particulier dans la vue Infrastructure - Réseaux de l'interface NSX Advanced Load Balancer. |
AVI_NAMESPACE |
✔ | ✖ | Facultatif ; la valeur par défaut est "tkg-system-networking". Espace de noms pour l'opérateur AKO. |
AVI_NSXT_T1LR |
✔ | ✖ | Facultatif. Chemin du routeur T1 NSX que vous avez configuré pour votre cluster de gestion dans l'interface utilisateur du contrôleur AVI, sous NSX Cloud. Cela est nécessaire lorsque vous utilisez NSX Cloud sur votre contrôleur NSX ALB. Pour utiliser un autre T1 pour vos clusters de charge de travail, modifiez l'objet AKODeploymentConfig install-ako-for-all une fois le cluster de gestion créé. |
AVI_PASSWORD |
✔ | ✖ | Requis. Mot de passe que vous avez défini pour l'administrateur du contrôleur lorsque vous l'avez déployé. |
AVI_SERVICE_ENGINE_GROUP |
✔ | ✖ | Requis. Nom du groupe de moteurs de service. Par exemple, Default-Group. |
AVI_USERNAME |
✔ | ✖ | Requis. Nom d'utilisateur de l'administrateur que vous avez défini pour l'hôte du contrôleur lorsque vous l'avez déployé. |
Routage d'espace NSX
Ces variables configurent les espaces de charge de travail avec des adresses IP routables, comme décrit dans Déployer un cluster avec des espaces d'adresses IP routables. Tous les paramètres de type chaîne doivent être entre guillemets doubles, par exemple "true".
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
NSXT_POD_ROUTING_ENABLED |
✖ | ✔ | Facultatif ; la valeur par défaut est "false". Définissez cette variable sur "true" pour activer les espaces routables NSX avec les variables ci-dessous. Reportez-vous à la section Déployer un cluster avec des espaces d'adresses IP routables. |
NSXT_MANAGER_HOST |
✖ | ✔ | Requis si NSXT_POD_ROUTING_ENABLED= "true".Adresse IP de NSX Manager. |
NSXT_ROUTER_PATH |
✖ | ✔ | Requis si NSXT_POD_ROUTING_ENABLED= "true". Chemin du routeur T1 affiché dans NSX Manager. |
| Pour l'authentification par nom d'utilisateur/mot de passe dans NSX : | |||
NSXT_USERNAME |
✖ | ✔ | Nom d'utilisateur pour la connexion à NSX Manager. |
NSXT_PASSWORD |
✖ | ✔ | Mot de passe pour la connexion à NSX Manager. |
Pour l'authentification à NSX à l'aide des informations d'identification et leur stockage dans un secret Kubernetes (définissez également NSXT_USERNAME et NSXT_PASSWORD ci-dessus) : |
|||
NSXT_SECRET_NAMESPACE |
✖ | ✔ | Facultatif ; la valeur par défaut est "kube-system". Espace de noms avec le secret contenant le nom d'utilisateur et le mot de passe NSX. |
NSXT_SECRET_NAME |
✖ | ✔ | Facultatif ; la valeur par défaut est "cloud-provider-vsphere-nsxt-credentials". Nom du secret contenant le nom d'utilisateur et le mot de passe NSX. |
| Pour l'authentification par certificat dans NSX : | |||
NSXT_ALLOW_UNVERIFIED_SSL |
✖ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur "true" si NSX utilise un certificat auto-signé. |
NSXT_ROOT_CA_DATA_B64 |
✖ | ✔ | Requis si NSXT_ALLOW_UNVERIFIED_SSL= "false".Chaîne de certificat racine d'autorité de certification codée en base64 que NSX utilise pour l'authentification LDAP. |
NSXT_CLIENT_CERT_KEY_DATA |
✖ | ✔ | Chaîne de fichier de clé de certificat codée en Base64 pour le certificat client local. |
NSXT_CLIENT_CERT_DATA |
✖ | ✔ | Chaîne de fichier de certificat codé en Base64 pour le certificat client local. |
| Pour que l'authentification à distance à NSX avec VMware Identity Manager, sur VMware Cloud (VMC) : | |||
NSXT_REMOTE_AUTH |
✖ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur "true" pour l'authentification à distance dans NSX avec VMware Identity Manager, sur VMware Cloud (VMC). |
NSXT_VMC_AUTH_HOST |
✖ | ✔ | Facultatif ; la valeur par défaut est vide. Hôte d’authentification VMC. |
NSXT_VMC_ACCESS_TOKEN |
✖ | ✔ | Facultatif ; la valeur par défaut est vide. Jeton d’accès d’authentification VMC. |
IPAM de nœud
Ces variables sont configurées dans la gestion des adresses IP (IPAM) dans le cluster, comme décrit dans la section IPAM de nœud. Tous les paramètres de type chaîne doivent être entre guillemets doubles, par exemple "true".
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
CONTROL_PLANE_NODE_NAMESERVERS |
✔ | ✔ | Liste délimitée par des virgules de serveurs de noms, par exemple, "10.10.10.10", pour les adresses de nœud de plan de contrôle gérées par l'IPAM de nœud. Prise en charge sur Ubuntu et Photon, mais pas sur Windows. |
NODE_IPAM_IP_POOL_APIVERSION |
✖ | ✔ | Version de l'API pour l'objet InClusterIPPool utilisé par le cluster de charge de travail. La valeur par défaut est "ipam.cluster.x-k8s.io/v1alpha2" ; les versions antérieures de TKG utilisaient v1alpha1. |
NODE_IPAM_IP_POOL_KIND |
✖ | ✔ | Type d'objet de pool d'adresses IP utilisé par le cluster de charge de travail. La valeur par défaut est "InClusterIPPool" ou peut être "GlobalInClusterIPPool" pour partager le même pool avec d'autres clusters. |
NODE_IPAM_IP_POOL_NAME |
✖ | ✔ | Nom de l'objet de pool d'adresses IP qui configure le pool d'adresses IP utilisé par un cluster de charge de travail. |
WORKER_NODE_NAMESERVERS |
✔ | ✔ | Liste délimitée par des virgules de serveurs de noms, par exemple, "10.10.10.10", pour les adresses de nœud worker gérées par l'IPAM de nœud. Prise en charge sur Ubuntu et Photon, mais pas sur Windows. |
MANAGEMENT_NODE_IPAM_IP_POOL_GATEWAY |
✔ | ✖ | Passerelle par défaut pour les adresses de pool IPAM dans un cluster de gestion, par exemple « 10.10.10.1 ». |
MANAGEMENT_NODE_IPAM_IP_POOL_ADDRESSES |
✔ | ✖ | Adresses disponibles pour l'allocation IPAM dans un cluster de gestion, dans une liste délimitée par des virgules qui peut inclure des adresses IP uniques, des plages (par exemple 10.0.0.2-10.0.0.100), ou des CIDR (par exemple 10.0.0.32/27).Incluez des adresses supplémentaires pour qu'elles restent inutilisées, si cela est nécessaire pour les mises à niveau du cluster. Le nombre requis d'adresses supplémentaires par défaut est de 1 et est défini par l'annotation topology.cluster.x-k8s.io/upgrade-concurrency dans les définitions topology.controlPlane et topology.workers de la spécification d'objet de cluster. |
MANAGEMENT_NODE_IPAM_IP_POOL_SUBNET_PREFIX |
✔ | ✖ | Préfixe réseau du sous-réseau pour les adresses de pool IPAM dans un cluster de gestion autonome, par exemple "24" |
Clusters compatibles GPU
Ces variables configurent des clusters de charge de travail compatibles GPU en mode relais PCI, comme décrit dans la section Déployer un cluster de charge de travail compatible GPU. Tous les paramètres de type chaîne doivent être entre guillemets doubles, par exemple "true".
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
VSPHERE_CONTROL_PLANE_CUSTOM_VMX_KEYS |
✔ | ✔ | Définit des clés VMX personnalisées sur toutes les machines du plan de contrôle. Utilisez le format Key1=Value1,Key2=Value2. Reportez-vous à la section Déployer un cluster de charge de travail compatible GPU. |
VSPHERE_CONTROL_PLANE_HARDWARE_VERSION |
✔ | ✔ | Version matérielle de la machine virtuelle du plan de contrôle avec le périphérique GPU en mode relais PCI. La version minimale requise est 17. Le format de la valeur est vmx-17, où les chiffres de fin correspondent à la version matérielle de la machine virtuelle. Pour connaître la prise en charge des fonctionnalités sur différentes versions matérielles, reportez-vous à la section Fonctions matérielles disponibles avec les paramètres de compatibilité de la machine virtuelle dans la documentation de vSphere. |
VSPHERE_CONTROL_PLANE_PCI_DEVICES |
✔ | ✔ | Configure le relais PCI sur toutes les machines du plan de contrôle. Utilisez le format <vendor_idgt;:<device_id>. Par exemple, VSPHERE_WORKER_PCI_DEVICES: "0x10DE:0x1EB8". Pour rechercher les ID de fournisseur et de périphérique, reportez-vous à la section Déployer un cluster de charge de travail compatible GPU. |
VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST |
✔ | ✔ | Définissez cette variable sur false si vous utilisez le GPU NVIDIA Tesla T4 et true si vous utilisez le GPU NVIDIA V100. |
VSPHERE_WORKER_CUSTOM_VMX_KEYS |
✔ | ✔ | Définit des clés VMX personnalisées sur toutes les machines worker. Utilisez le format Key1=Value1,Key2=Value2. Pour obtenir un exemple, reportez-vous à la section Déployer un cluster de charge de travail compatible GPU. |
VSPHERE_WORKER_HARDWARE_VERSION |
✔ | ✔ | Version matérielle de la machine virtuelle worker avec le périphérique GPU en mode relais PCI. La version minimale requise est 17. Le format de la valeur est vmx-17, où les chiffres de fin correspondent à la version matérielle de la machine virtuelle. Pour connaître la prise en charge des fonctionnalités sur différentes versions matérielles, reportez-vous à la section Fonctions matérielles disponibles avec les paramètres de compatibilité de la machine virtuelle dans la documentation de vSphere. |
VSPHERE_WORKER_PCI_DEVICES |
✔ | ✔ | Configure le relais PCI sur toutes les machines worker. Utilisez le format <vendor_idgt;:<device_id>. Par exemple, VSPHERE_WORKER_PCI_DEVICES: "0x10DE:0x1EB8". Pour rechercher les ID de fournisseur et de périphérique, reportez-vous à la section Déployer un cluster de charge de travail compatible GPU. |
WORKER_ROLLOUT_STRATEGY |
✔ | ✔ | Facultatif. Configure la stratégie de déploiement MachineDeployment. La valeur par défaut est RollingUpdate. Si cette variable est définie sur OnDelete, les machines worker existantes seront alors supprimées lors des mises à jour, avant la création des machines worker de remplacement. Il est impératif de définir cette variable sur OnDelete si tous les périphériques PCI disponibles sont utilisés par les nœuds worker. |
AWS
Les variables du tableau ci-dessous sont les options que vous spécifiez dans le fichier de configuration de cluster lors du déploiement de clusters de charge de travail sur AWS. Bon nombre de ces options sont les mêmes pour le cluster de charge de travail et le cluster de gestion que vous utilisez pour le déployer.
Pour plus d'informations sur les fichiers de configuration d'AWS, reportez-vous aux sections Configuration du cluster de gestion pour AWS et Fichiers de configuration du cluster AWS.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
AWS_ACCESS_KEY_ID |
✔ | ✔ | Facultatif. ID de clé d’accès pour votre compte AWS. Il s'agit d'une option pour l'authentification à AWS. Reportez-vous à la section Configurer les informations d'identification du compte AWS. Utilisez uniquement AWS_PROFILE ou une combinaison de AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY, mais pas les deux. |
AWS_CONTROL_PLANE_OS_DISK_SIZE_GIB |
✔ | ✔ | Facultatif. Taille de disque pour les nœuds du plan de contrôle. Remplace la taille de disque par défaut pour le type de machine virtuelle définie par CONTROL_PLANE_MACHINE_TYPE, SIZE ou CONTROLPLANE_SIZE. |
AWS_LOAD_BALANCER_SCHEME_INTERNAL |
✔ | ✔ | Facultatif. Pour les clusters de gestion, le schéma d'équilibrage de charge est défini sur interne, empêchant ainsi l'accès depuis Internet. Pour les clusters de charge de travail, le cluster de gestion accède à l'équilibrage de charge du cluster de charge de travail en interne lorsqu'il partage un VPC ou qu'il est homologué. Reportez-vous à la section Utiliser l'équilibrage de charge interne pour le serveur d'API Kubernetes. |
AWS_NODE_AZ |
✔ | ✔ | Requis. Nom de la zone de disponibilité AWS dans votre région choisie que vous souhaitez utiliser comme zone de disponibilité pour ce cluster de gestion. Les noms de zone de disponibilité sont identiques au nom de région AWS, avec un suffixe minuscule unique, tel que a, b ou c. Par exemple, us-west-2a. Pour déployer un cluster de gestion prod avec trois nœuds de plan de contrôle, vous devez également définir AWS_NODE_AZ_1 et AWS_NODE_AZ_2. Le suffixe de lettre dans chacune de ces zones de disponibilité doit être unique. Par exemple, us-west-2a, us-west-2b et us-west-2c. |
AWS_NODE_OS_DISK_SIZE_GIB |
✔ | ✔ | Facultatif. Taille de disque des nœuds worker. Remplace la taille de disque par défaut pour le type de machine virtuelle définie par NODE_MACHINE_TYPE, SIZE ou WORKER_SIZE. |
AWS_NODE_AZ_1 et AWS_NODE_AZ_2 |
✔ | ✔ | Facultatif. Définissez ces variables si vous souhaitez déployer un cluster de gestion prod avec trois nœuds de plan de contrôle. Les deux zones de disponibilité doivent se trouver dans la même région que AWS_NODE_AZ. Pour obtenir plus d'informations, reportez-vous à la section AWS_NODE_AZ. Par exemple, us-west-2a, ap-northeast-2b, etc. |
AWS_PRIVATE_NODE_CIDR_1 |
✔ | ✔ | Facultatif. Si la plage recommandée de 10.0.2.0/24 n'est pas disponible, entrez une plage d'adresses IP différente au format CIDR. Lorsque Tanzu Kubernetes Grid déploie votre cluster de gestion, il crée ce sous-réseau dans AWS_NODE_AZ_1. Pour obtenir plus d'informations, reportez-vous à la section AWS_PRIVATE_NODE_CIDR. |
AWS_PRIVATE_NODE_CIDR_2 |
✔ | ✔ | Facultatif. Si la plage recommandée de 10.0.4.0/24 n'est pas disponible, entrez une plage d'adresses IP différente au format CIDR. Lorsque Tanzu Kubernetes Grid déploie votre cluster de gestion, il crée ce sous-réseau dans AWS_NODE_AZ_2. Pour obtenir plus d'informations, reportez-vous à la section AWS_PRIVATE_NODE_CIDR. |
AWS_PROFILE |
✔ | ✔ | Facultatif. Profil d'informations d'identification AWS, géré par aws configure, que Tanzu Kubernetes Grid utilise pour accéder à son compte AWS. Il s'agit de l'option préférée pour l'authentification à AWS. Reportez-vous à la section Configurer les informations d'identification du compte AWS.Utilisez uniquement AWS_PROFILE ou une combinaison de AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY, mais pas les deux. |
AWS_PUBLIC_NODE_CIDR_1 |
✔ | ✔ | Facultatif. Si la plage recommandée de 10.0.3.0/24 n'est pas disponible, entrez une plage d'adresses IP différente au format CIDR. Lorsque Tanzu Kubernetes Grid déploie votre cluster de gestion, il crée ce sous-réseau dans AWS_NODE_AZ_1. Pour obtenir plus d'informations, reportez-vous à la section AWS_PUBLIC_NODE_CIDR. |
AWS_PUBLIC_NODE_CIDR_2 |
✔ | ✔ | Facultatif. Si la plage recommandée de 10.0.5.0/24 n'est pas disponible, entrez une plage d'adresses IP différente au format CIDR. Lorsque Tanzu Kubernetes Grid déploie votre cluster de gestion, il crée ce sous-réseau dans AWS_NODE_AZ_2. Pour obtenir plus d'informations, reportez-vous à la section AWS_PUBLIC_NODE_CIDR. |
AWS_PRIVATE_SUBNET_ID |
✔ | ✔ | Facultatif. Si vous définissez AWS_VPC_ID pour utiliser un VPC existant, entrez l'ID d'un sous-réseau privé qui existe déjà dans AWS_NODE_AZ. Ce paramètre est facultatif. Si vous ne le définissez pas, tanzu management-cluster create identifie automatiquement le sous-réseau privé. Pour déployer un cluster de gestion prod avec trois nœuds de plan de contrôle, vous devez également définir AWS_PRIVATE_SUBNET_ID_1 et AWS_PRIVATE_SUBNET_ID_2. |
AWS_PRIVATE_SUBNET_ID_1 |
✔ | ✔ | Facultatif. ID d'un sous-réseau privé existant dans AWS_NODE_AZ_1. Si vous ne définissez pas cette variable, tanzu management-cluster create identifie automatiquement le sous-réseau privé. Pour obtenir plus d'informations, reportez-vous à la section AWS_PRIVATE_SUBNET_ID. |
AWS_PRIVATE_SUBNET_ID_2 |
✔ | ✔ | Facultatif. ID d'un sous-réseau privé existant dans AWS_NODE_AZ_2. Si vous ne définissez pas cette variable, tanzu management-cluster create identifie automatiquement le sous-réseau privé. Pour obtenir plus d'informations, reportez-vous à la section AWS_PRIVATE_SUBNET_ID. |
AWS_PUBLIC_SUBNET_ID |
✔ | ✔ | Facultatif. Si vous définissez AWS_VPC_ID pour utiliser un VPC existant, entrez l'ID d'un sous-réseau public qui existe déjà dans AWS_NODE_AZ. Ce paramètre est facultatif. Si vous ne le définissez pas, tanzu management-cluster create identifie automatiquement le sous-réseau public. Pour déployer un cluster de gestion prod avec trois nœuds de plan de contrôle, vous devez également définir AWS_PUBLIC_SUBNET_ID_1 et AWS_PUBLIC_SUBNET_ID_2. |
AWS_PUBLIC_SUBNET_ID_1 |
✔ | ✔ | Facultatif. ID d'un sous-réseau public existant dans AWS_NODE_AZ_1. Si vous ne définissez pas cette variable, tanzu management-cluster create identifie automatiquement le sous-réseau public. Pour obtenir plus d'informations, reportez-vous à la section AWS_PUBLIC_SUBNET_ID. |
AWS_PUBLIC_SUBNET_ID_2 |
✔ | ✔ | Facultatif. ID d'un sous-réseau public existant dans AWS_NODE_AZ_2. Si vous ne définissez pas cette variable, tanzu management-cluster create identifie automatiquement le sous-réseau public. Pour obtenir plus d'informations, reportez-vous à la section AWS_PUBLIC_SUBNET_ID. |
AWS_REGION |
✔ | ✔ | Requis. Nom de la région AWS dans laquelle déployer le cluster. Par exemple, us-west-2. Vous pouvez également spécifier les régions us-gov-east et us-gov-west dans AWS GovCloud. Si vous avez déjà défini une région différente en tant que variable d'environnement (par exemple, dans Déployer des clusters de gestion sur AWS), vous devez annuler la définition de cette variable d'environnement. Par exemple, us-west-2, ap-northeast-2, etc. |
AWS_SECRET_ACCESS_KEY |
✔ | ✔ | Facultatif. Secret de clé d'accès pour votre compte AWS. Il s'agit d'une option pour l'authentification à AWS. Reportez-vous à la section Configurer les informations d'identification du compte AWS. Utilisez uniquement AWS_PROFILE ou une combinaison de AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY, mais pas les deux. |
AWS_SECURITY_GROUP_APISERVER_LB |
✔ | ✔ | Facultatif. Groupes de sécurité personnalisés avec des règles personnalisées à appliquer au cluster. Reportez-vous à la section Configurer des groupes de sécurité personnalisés. |
AWS_SECURITY_GROUP_BASTION |
|||
AWS_SECURITY_GROUP_CONTROLPLANE |
|||
AWS_SECURITY_GROUP_APISERVER_LB |
|||
AWS_SECURITY_GROUP_NODE |
|||
AWS_SESSION_TOKEN |
✔ | ✔ | Facultatif. Fournissez le jeton de session AWS accordé à votre compte si vous devez utiliser une clé d'accès temporaire. Pour plus d'informations sur l'utilisation de clés d'accès temporaires, reportez-vous à la section Présentation et obtention de vos informations d'identification AWS et fournissez le jeton de session pour votre compte AWS. Vous pouvez également spécifier des informations d'identification de compte en tant que variables d'environnement local ou dans votre chaîne de fournisseurs d'informations d'identification AWS par défaut. |
AWS_SSH_KEY_NAME |
✔ | ✔ | Requis. Nom de la clé privée SSH que vous avez enregistrée dans votre compte AWS. |
AWS_VPC_ID |
✔ | ✔ | Facultatif. Pour utiliser un VPC qui existe déjà dans votre région AWS sélectionnée, entrez l'ID du VPC, puis définissez AWS_PUBLIC_SUBNET_ID et AWS_PRIVATE_SUBNET_ID. |
BASTION_HOST_ENABLED |
✔ | ✔ | Facultatif. Par défaut, cette option est définie sur "true" dans la configuration Tanzu Kubernetes Grid globale. Spécifiez "true" pour déployer un hôte bastion AWS ou "false" pour réutiliser un hôte bastion existant. Si aucun hôte bastion n'existe dans vos zones de disponibilité et que vous définissez AWS_VPC_ID pour utiliser un VPC existant, définissez BASTION_HOST_ENABLED sur "true". |
CONTROL_PLANE_MACHINE_TYPE |
✔ | ✔ | Requis si une variable SIZE ou CONTROLPLANE_SIZE indépendante du cloud n'est pas définie. Type d'instance Amazon EC2 à utiliser pour les nœuds de plan de contrôle du cluster (par exemple, t3.small ou m5.large). |
NODE_MACHINE_TYPE |
✔ | ✔ | Requis si une variable SIZE ou WORKER_SIZE indépendante du cloud n'est pas définie. Type d'instance Amazon EC2 à utiliser pour les nœuds worker du cluster (par exemple, t3.small ou m5.large). |
Microsoft Azure
Les variables du tableau ci-dessous sont les options que vous spécifiez dans le fichier de configuration de cluster lors du déploiement de clusters de charge de travail sur Azure. Bon nombre de ces options sont les mêmes pour le cluster de charge de travail et le cluster de gestion que vous utilisez pour le déployer.
Pour plus d'informations sur les fichiers de configuration d'Azure, reportez-vous aux sections Configuration du cluster de gestion pour Azure et Fichiers de configuration du cluster Azure.
| Variable | Peut être défini dans… | Description | |
|---|---|---|---|
| YAML du cluster de gestion | YAML du cluster de charge de travail | ||
AZURE_CLIENT_ID |
✔ | ✔ | Requis. ID client de l'application pour l'instance de Tanzu Kubernetes Grid que vous avez enregistrée dans Azure. |
AZURE_CLIENT_SECRET |
✔ | ✔ | Requis. Clé secrète client Azure définie dans Enregistrer une application Tanzu Kubernetes Grid sur Azure. |
AZURE_CUSTOM_TAGS |
✔ | ✔ | Facultatif. Liste de balises séparées par des virgules à appliquer aux ressources Azure créées pour le cluster. Une balise est une paire clé-valeur (par exemple, "foo=bar, plan=prod"). Pour plus d'informations sur le balisage des ressources Azure, reportez-vous à la section Utiliser les balises pour organiser vos ressources Azure et la hiérarchie de gestion et Prise en charge des balises pour les ressources Azure dans la documentation Microsoft Azure. |
AZURE_ENVIRONMENT |
✔ | ✔ | Facultatif ; la valeur par défaut est AzurePublicCloud. Les clouds pris en charge sont AzurePublicCloud, AzureChinaCloud, AzureGermanCloud et AzureUSGovernmentCloud. |
AZURE_IDENTITY_NAME |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez utiliser des clusters sur différents comptes Azure. Nom à utiliser pour l'objet AzureClusterIdentity que vous créez afin d'utiliser des clusters sur différents comptes Azure. Pour plus d'informations, reportez-vous à la section Clusters sur différents comptes Azure dans Déployer des clusters de charge de travail sur Azure. |
AZURE_IDENTITY_NAMESPACE |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez utiliser des clusters sur différents comptes Azure. Espace de noms pour votre objet AzureClusterIdentity que vous créez afin d'utiliser des clusters sur différents comptes Azure. Pour plus d'informations, reportez-vous à la section Clusters sur différents comptes Azure dans Déployer des clusters de charge de travail sur Azure. |
AZURE_LOCATION |
✔ | ✔ | Requis. Nom de la région Azure dans laquelle déployer le cluster. Par exemple, eastus. |
AZURE_RESOURCE_GROUP |
✔ | ✔ | Facultatif ; la valeur est définie par défaut sur le paramètre CLUSTER_NAME. Nom du groupe de ressources Azure que vous souhaitez utiliser pour le cluster. Doit être unique à chaque cluster. AZURE_RESOURCE_GROUP et AZURE_VNET_RESOURCE_GROUP sont identiques par défaut. |
AZURE_SSH_PUBLIC_KEY_B64 |
✔ | ✔ | Requis. Votre clé publique SSH, créée dans Déployer un cluster de gestion dans Microsoft Azure, convertie en base64 avec les nouvelles lignes supprimées. Par exemple, c3NoLXJzYSBB [...] vdGFsLmlv. |
AZURE_SUBSCRIPTION_ID |
✔ | ✔ | Requis. ID d'abonnement de votre abonnement Azure. |
AZURE_TENANT_ID |
✔ | ✔ | Requis. ID de locataire de votre compte Azure. |
| Mise en réseau | |||
AZURE_CONTROL_PLANE_OUTBOUND_LB_FRONTEND_IP_COUNT |
✔ | ✔ | Facultatif ; la valeur par défaut est 1. Définissez cette variable pour ajouter plusieurs adresses IP frontales à l'équilibrage de charge du plan de contrôle dans des environnements avec un nombre élevé de connexions sortantes attendues. |
AZURE_ENABLE_ACCELERATED_NETWORKING |
✔ | ✔ | Facultatif ; la valeur par défaut est true. Définissez cette variable sur false pour désactiver la mise en réseau accélérée Azure sur les machines virtuelles disposant de plus de 4 CPU. |
AZURE_ENABLE_CONTROL_PLANE_OUTBOUND_LB |
✔ | ✔ | Facultatif. Définissez cette variable sur true si AZURE_ENABLE_PRIVATE_CLUSTER est définie sur true et que vous souhaitez activer une adresse IP publique sur l'équilibrage de charge sortant pour le plan de contrôle. |
AZURE_ENABLE_NODE_OUTBOUND_LB |
✔ | ✔ | Facultatif. Définissez cette variable sur true si AZURE_ENABLE_PRIVATE_CLUSTER est définie sur true et que vous souhaitez activer une adresse IP publique sur l'équilibrage de charge sortant pour les nœuds worker. |
AZURE_ENABLE_PRIVATE_CLUSTER |
✔ | ✔ | Facultatif. Définissez cette variable sur true pour configurer le cluster comme privé et utiliser un équilibrage de charge interne (ILB, Internal Load Balancer) Azure pour son trafic entrant. Pour plus d'informations, reportez-vous à la section Clusters privés Azure. |
AZURE_FRONTEND_PRIVATE_IP |
✔ | ✔ | Facultatif. Définissez cette variable si AZURE_ENABLE_PRIVATE_CLUSTER est définie sur true et que vous souhaitez remplacer l'adresse d'équilibrage de charge interne par défaut de 10.0.0.100. |
AZURE_NODE_OUTBOUND_LB_FRONTEND_IP_COUNT |
✔ | ✔ | Facultatif ; la valeur par défaut est 1. Définissez cette variable pour ajouter plusieurs adresses IP frontales à l'équilibrage de charge du nœud worker dans des environnements avec un nombre élevé de connexions sortantes attendues. |
AZURE_NODE_OUTBOUND_LB_IDLE_TIMEOUT_IN_MINUTES |
✔ | ✔ | Facultatif ; la valeur par défaut est 4. Définissez cette variable pour spécifier le nombre de minutes pendant lesquelles les connexions TCP sortantes restent ouvertes via l'équilibrage de charge sortant du nœud worker. |
AZURE_VNET_CIDR |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez déployer le cluster sur un nouveau réseau virtuel et des sous-réseaux, puis remplacer les valeurs par défaut. Par défaut, AZURE_VNET_CIDR est défini sur 10.0.0.0/16, AZURE_CONTROL_PLANE_SUBNET_CIDR sur 10.0.0.0/24 et AZURE_NODE_SUBNET_CIDR sur 10.0.1.0/24. |
AZURE_CONTROL_PLANE_SUBNET_CIDR |
|||
AZURE_NODE_SUBNET_CIDR |
|||
AZURE_VNET_NAME |
✔ | ✔ | Facultatif, définissez cette variable si vous souhaitez déployer le cluster sur un réseau virtuel existant et des sous-réseaux ou attribuer des noms à un nouveau réseau virtuel et à des sous-réseaux. |
AZURE_CONTROL_PLANE_SUBNET_NAME |
|||
AZURE_NODE_SUBNET_NAME |
|||
AZURE_VNET_RESOURCE_GROUP |
✔ | ✔ | Facultatif ; la valeur est définie par défaut sur celle de AZURE_RESOURCE_GROUP. |
| VM du plan de contrôle | |||
AZURE_CONTROL_PLANE_DATA_DISK_SIZE_GIB |
✔ | ✔ | Facultatif. Taille du disque de données et du disque du système d'exploitation, comme décrit dans la documentation Azure Rôles de disque pour les machines virtuelles du plan de contrôle en Go. Exemples : 128, 256. Les nœuds de plan de contrôle sont toujours provisionnés avec un disque de données. |
AZURE_CONTROL_PLANE_OS_DISK_SIZE_GIB |
|||
AZURE_CONTROL_PLANE_MACHINE_TYPE |
✔ | ✔ | Facultatif ; la valeur par défaut est Standard_D2s_v3. Taille de machine virtuelle Azure pour les machines virtuelles du nœud du plan de contrôle, choisie pour correspondre aux charges de travail attendues. La configuration minimale requise pour les types d'instance Azure est de 2 CPU et de 8 Go de mémoire. Pour connaître les valeurs possibles, reportez-vous à l'interface du programme d'installation de Tanzu Kubernetes Grid. |
AZURE_CONTROL_PLANE_OS_DISK_STORAGE_ACCOUNT_TYPE |
✔ | ✔ | Facultatif. Type de compte de stockage Azure pour les disques de machine virtuelle du plan de contrôle. Exemple : Premium_LRS. |
| Machines virtuelles du nœud worker | |||
AZURE_ENABLE_NODE_DATA_DISK |
✔ | ✔ | Facultatif ; la valeur par défaut est false. Définissez cette variable sur true pour provisionner un disque de données pour chaque machine virtuelle de nœud worker, comme décrit dans la documentation Azure Rôles de disque. |
AZURE_NODE_DATA_DISK_SIZE_GIB |
✔ | ✔ | Facultatif. Définissez cette variable si AZURE_ENABLE_NODE_DATA_DISK est définie sur true. Taille du disque de données, comme décrit dans la documentation Azure Rôles de disque pour les machines virtuelles worker en Go. Exemples : 128, 256. |
AZURE_NODE_OS_DISK_SIZE_GIB |
✔ | ✔ | Facultatif. Taille du disque de système d'exploitation, comme décrit dans la documentation Azure Rôles de disque pour les machines virtuelles worker en Go. Exemples : 128, 256. |
AZURE_NODE_MACHINE_TYPE |
✔ | ✔ | Facultatif. Taille de machine virtuelle Azure pour les machines virtuelles du nœud worker, choisie pour correspondre aux charges de travail attendues. La valeur par défaut est Standard_D2s_v3. Pour connaître les valeurs possibles, reportez-vous à l'interface du programme d'installation de Tanzu Kubernetes Grid. |
AZURE_NODE_OS_DISK_STORAGE_ACCOUNT_TYPE |
✔ | ✔ | Facultatif. Définissez cette variable si AZURE_ENABLE_NODE_DATA_DISK est définie sur true. Type de compte de stockage Azure pour les disques de machine virtuelle worker. Exemple : Premium_LRS. |
Priorité de la valeur de configuration
Lorsque la CLI Tanzu crée un cluster, elle lit les valeurs des variables répertoriées dans cette rubrique à partir de plusieurs sources. Si ces sources sont en conflit, elle résout les conflits dans l'ordre de priorité décroissant suivant :
| Traitement des couches, classé par priorité décroissante | Source | Exemples |
|---|---|---|
| 1. Variables de configuration du cluster de gestion définies dans l’interface du programme d’installation | Entrées dans l'interface du programme d'installation lancée par l'option --ui et écrites dans les fichiers de configuration du cluster. L'emplacement du fichier est défini par défaut sur ~/.config/tanzu/tkg/clusterconfigs/. |
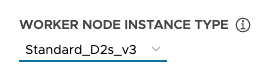 |
| 2. Variables de configuration de cluster définies dans votre environnement local | Définies dans le shell. | export AZURE_NODE_MACHINE_TYPE=Standard_D2s_v3 |
3. Variables de configuration de cluster définies dans la CLI Tanzu, avec tanzu config set env. |
Définies dans le shell ; enregistrées dans le fichier de configuration de la CLI Tanzu, ~/.config/tanzu/config.yaml. |
tanzu config set env.AZURE_NODE_MACHINE_TYPE Standard_D2s_v3 |
| 4. Variables de configuration de cluster définies dans le fichier de configuration du cluster | Définies dans le fichier transmis à l'option --file de tanzu management-cluster create ou tanzu cluster create. Le fichier est défini par défaut sur ~/.config/tanzu/tkg/cluster-config.yaml. |
AZURE_NODE_MACHINE_TYPE: Standard_D2s_v3 |
| 5. Valeurs de configuration par défaut d'usine | Définies dans providers/config_default.yaml. Ne modifiez pas ce fichier. |
AZURE_NODE_MACHINE_TYPE: "Standard_D2s_v3" |
