









Déployer un cluster de charge de travail sur du matériel spécialisé
Tanzu Kubernetes Grid prend en charge le déploiement de clusters de charge de travail sur des types spécifiques d'hôtes compatibles GPU sur vSphere 7.0 et versions ultérieures.
Déployer un cluster de charge de travail compatible GPU
Pour utiliser un nœud avec un GPU dans un cluster de charge de travail vSphere, vous devez activer le mode relais PCI. Cela permet au cluster d'accéder au GPU directement, en contournant l'hyperviseur ESXi, ce qui fournit un niveau de performance semblable à celui du GPU sur un système natif. Lorsque le mode relais PCI est utilisé, chaque périphérique GPU est dédié à une machine virtuelle (VM) dans le cluster de charge de travail vSphere.
RemarquePour ajouter des nœuds compatibles GPU aux clusters existants, utilisez la commande
tanzu cluster node-pool set.
Conditions requises
- Hôte ESXi avec une carte GPU NVIDIA V100 ou NVIDIA Tesla T4.
- vSphere 7.0 Update 3 et versions ultérieures. Les builds de la version 7.0u3, qui est la version minimale requise pour la prise en charge de cette fonctionnalité, sont répertoriées ci-dessous.
- Tanzu Kubernetes Grid v1.6+.
- Helm, le gestionnaire de modules Kubernetes. Pour l'installer, reportez-vous à la section Installation de Helm dans la documentation Helm.
Procédure
Pour créer un cluster de charge de travail avec des hôtes compatibles GPU, procédez de la manière suivante pour activer le relais PCI, créer une image de machine personnalisée, créer un fichier de configuration de cluster et une version de Tanzu Kubernetes, déployer le cluster de charge de travail et installer un opérateur GPU avec Helm.
-
Ajoutez les hôtes ESXi avec les cartes GPU à votre instance de vSphere Client.
-
Activez le relais PCI et enregistrez les ID de GPU comme suit :
- Dans votre instance de vSphere Client, sélectionnez l'hôte ESXi cible dans le cluster
GPU. - Sélectionnez Configurer > Matériel > Périphériques PCI (Configure > Hardware > PCI Devices).
- Sélectionnez l'onglet Tous les périphériques PCI.
- Sélectionnez le GPU cible dans la liste.
- Cliquez sur Basculer le relais.
- Sous Informations générales (General Information), enregistrez l'ID de périphérique et l'ID de fournisseur (mis en surbrillance en vert sur l'image ci-dessous). Les ID sont les mêmes pour les cartes GPU identiques. Vous aurez besoin de ces ID pour le fichier de configuration du cluster.
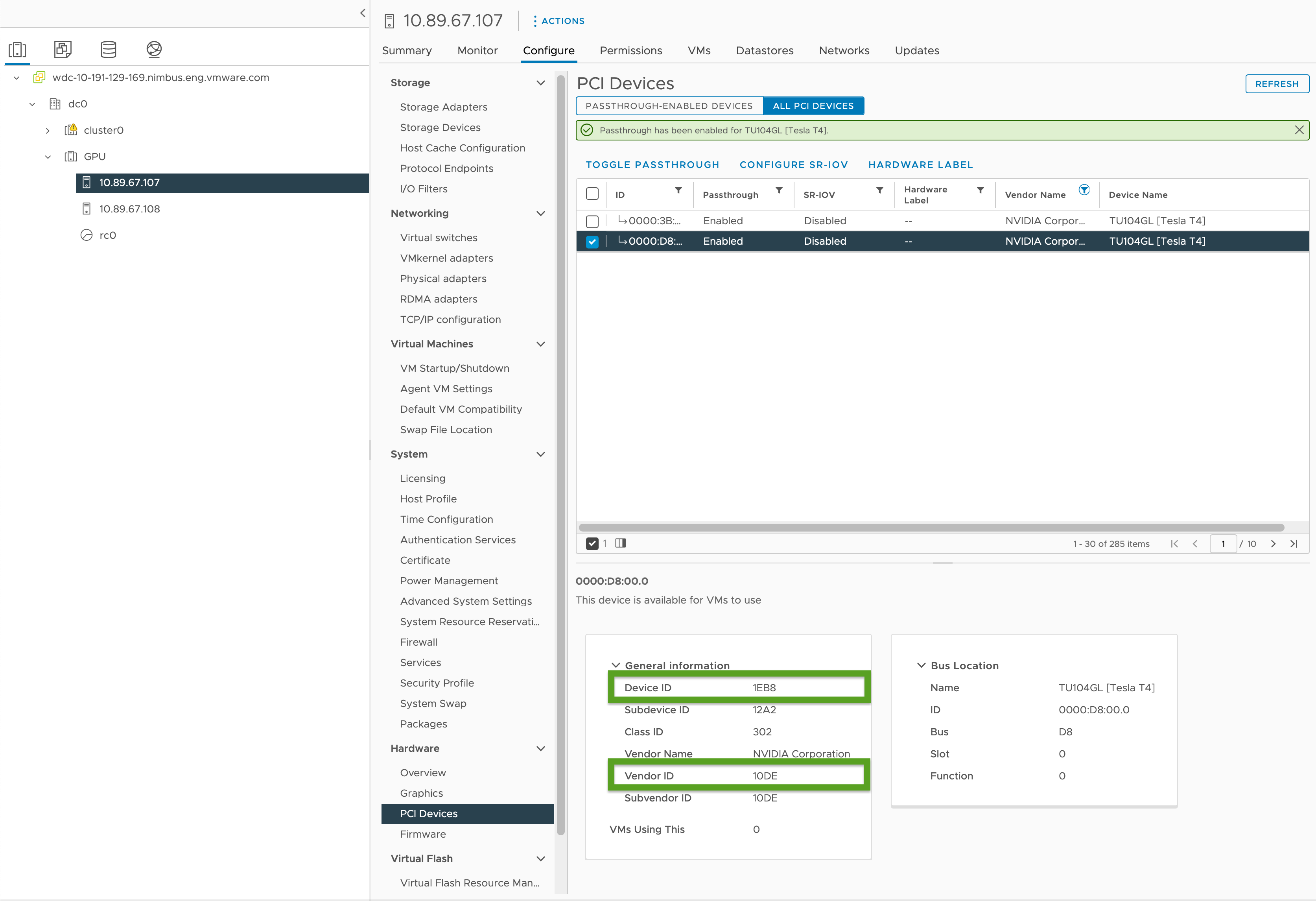
- Dans votre instance de vSphere Client, sélectionnez l'hôte ESXi cible dans le cluster
-
Créez un fichier de configuration de cluster de charge de travail à l'aide du modèle dans Modèle de cluster de charge de travail et incluez les variables suivantes :
... VSPHERE_WORKER_PCI_DEVICES: "0x<VENDOR-ID>:0x<DEVICE-ID>" VSPHERE_WORKER_CUSTOM_VMX_KEYS: 'pciPassthru.allowP2P=true,pciPassthru.RelaxACSforP2P=true,pciPassthru.use64bitMMIO=true,pciPassthru.64bitMMIOSizeGB=<GPU-SIZE>' VSPHERE_IGNORE_PCI_DEVICES_ALLOW_LIST: "<BOOLEAN>" VSPHERE_WORKER_HARDWARE_VERSION: vmx-17 WORKER_ROLLOUT_STRATEGY: "RollingUpdate"Où :
<VENDOR-ID>et<DEVICE-ID>correspond à l'ID de fournisseur et à l'ID de périphérique que vous avez enregistrés à une étape précédente. Par exemple, si l'ID de fournisseur est10DEet que l'ID de périphérique est1EB8, la valeur est"0x10DE:0x1EB8".<GPU-SIZE>correspond à la taille totale de mémoire tampon de trame (en Go) de tous les GPU du cluster arrondie à la puissance de deux suivante.- Par exemple, avec deux GPU de 40 Go, le total est de 80 Go, ce qui s'arrondit à 128 Go ; vous devez donc définir la valeur sur
pciPassthru.64bitMMIOSizeGB=128. - Pour déterminer la mémoire requise pour la carte GPU, consultez la documentation de votre carte NVIDIA GPU spécifique. Pour plus d'informations, reportez-vous au tableau Conditions requises pour l'utilisation de vGPU sur des GPU nécessitant au moins 64 Go d'espace MMIO avec des machines virtuelles à grande mémoire (en anglais) dans la documentation NVIDIA.
- Voir aussi :
- Article de la base de connaissances VMware Configuration de périphériques de relais VMDirectPath I/O sur un hôte VMware ESX ou VMware ESXi
- Article de la base de connaissances Dell PowerEdge : Relais PCI « Échec de la mise sous tension du module DevicePowerOn » lors de l'utilisation de GPU avec des machines virtuelles sur vSphere
- Par exemple, avec deux GPU de 40 Go, le total est de 80 Go, ce qui s'arrondit à 128 Go ; vous devez donc définir la valeur sur
<BOOLEAN>est défini surfalsesi vous utilisez le GPU NVIDIA Tesla T4 ettruesi vous utilisez le GPU NVIDIA V100.<VSPHERE_WORKER_HARDWARE_VERSION>est la version matérielle de la machine virtuelle vers laquelle nous voulons mettre à niveau la machine. La version minimale requise pour les nœuds GPU doit être 17.WORKER_ROLLOUT_STRATEGYest défini surRollingUpdatesi vous disposez de périphériques PCI supplémentaires pouvant être utilisés par les nœuds worker lors des mises à niveau. Sinon, utilisezOnDelete.
Remarque
Vous ne pouvez utiliser qu'un seul type de GPU par machine virtuelle. Par exemple, vous ne pouvez pas utiliser NVIDIA V100 et NVIDIA Tesla T4 sur une seule machine virtuelle, mais vous pouvez utiliser plusieurs instances de GPU avec les mêmes ID de fournisseur et ID de périphérique.
La CLI
tanzun'autorise pas la mise à jour de la spécificationWORKER_ROLLOUT_STRATEGYsur leMachineDeployment. Si la mise à niveau du cluster est bloquée en raison de périphériques PCI non disponibles, VMware suggère de modifier la stratégieMachineDeploymentà l'aide de la CLIkubectl. La stratégie de déploiement est définie dansspec.strategy.type.Pour obtenir la liste complète des variables que vous pouvez configurer pour les clusters compatibles GPU, reportez-vous à la section Clusters compatibles GPU dans Référence de variable de fichier de configuration.
-
Créez le cluster de charge de travail en exécutant :
tanzu cluster create -f CLUSTER-CONFIG-NAMEOù
CLUSTER-CONFIG-NAMEest le nom du fichier de configuration du cluster que vous avez créé dans les étapes précédentes. -
Ajoutez le référentiel NVIDIA Helm suivant :
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \ && helm repo update -
Installez l'opérateur NVIDIA GPU :
helm install --kubeconfig=./KUBECONFIG --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operatorOù
KUBECONFIGest le nom et l'emplacement du fichierkubeconfigde votre cluster de charge de travail. Pour plus d'informations, reportez-vous à la section Récupérer le cluster de charge de travailkubeconfig.Pour plus d'informations sur les paramètres de cette commande, reportez-vous à la section Installer l'opérateur GPU dans la documentation NVIDIA.
-
Assurez-vous que l'opérateur NVIDIA GPU est en cours d'exécution :
kubectl --kubeconfig=./KUBECONFIG get pods -ALe résultat est semblable à ce qui suit :
NAMESPACE NAME READY STATUS RESTARTS AGE gpu-operator gpu-feature-discovery-szzkr 1/1 Running 0 6m18s gpu-operator gpu-operator-1676396573-node-feature-discovery-master-7795vgdnd 1/1 Running 0 7m7s gpu-operator gpu-operator-1676396573-node-feature-discovery-worker-bq6ct 1/1 Running 0 7m7s gpu-operator gpu-operator-84dfbbfd8-jd98f 1/1 Running 0 7m7s gpu-operator nvidia-container-toolkit-daemonset-6zncv 1/1 Running 0 6m18s gpu-operator nvidia-cuda-validator-2rz4m 0/1 Completed 0 98s gpu-operator nvidia-dcgm-exporter-vgw7p 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-daemonset-mln6z 1/1 Running 0 6m18s gpu-operator nvidia-device-plugin-validator-sczdk 0/1 Completed 0 22s gpu-operator nvidia-driver-daemonset-b7flb 1/1 Running 0 6m38s gpu-operator nvidia-operator-validator-2v8zk 1/1 Running 0 6m18s
Test de votre cluster GPU
Pour tester votre cluster compatible GPU, créez un manifeste d'espace pour l'exemple cuda-vector-add dans la documentation Kubernetes et déployez-le. Le conteneur téléchargera, exécutera et effectuera un calcul CUDA avec le GPU.
-
Créez un fichier nommé
cuda-vector-add.yamlet ajoutez ce qui suit :apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add # https://github.com/kubernetes/kubernetes/blob/v1.7.11/test/images/nvidia-cuda/Dockerfile image: "registry.k8s.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 # requesting 1 GPU -
Appliquez le fichier :
kubectl apply -f cuda-vector-add.yaml -
Exécutez ce qui suit :
kubectl get po cuda-vector-addLe résultat est semblable à ce qui suit :
cuda-vector-add 0/1 Completed 0 91s -
Exécutez ce qui suit :
kubectl logs cuda-vector-addLe résultat est semblable à ce qui suit :
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
Déployer un cluster de charge de travail sur un site Edge
Tanzu Kubernetes Grid v1.6 et versions ultérieures prend en charge le déploiement de clusters de charge de travail sur les hôtes ESXi VMware du dispositif Edge. Vous pouvez utiliser cette approche pour exécuter de nombreux clusters Kubernetes dans différents emplacements tous gérés par un cluster de gestion central.
Topologie : Vous pouvez exécuter des clusters de charge de travail Edge en production avec un nœud de plan de contrôle unique et un ou deux hôtes seulement. Cependant, bien que cela utilise moins de CPU, de mémoire et de bande passante réseau, vous n'avez pas les mêmes caractéristiques de résilience et de récupération que les clusters Tanzu Kubernetes Grid de production standard. Pour plus d'informations, reportez-vous à la section Architecture de référence de la solution VMware Tanzu Edge 1.0.
Registre local : Pour réduire les délais de communication et maximiser la résilience, chaque cluster Edge doit disposer de son propre registre de conteneur Harbor local. Pour obtenir un aperçu de cette architecture, reportez-vous à la section Registre de conteneur dans Présentation de l'architecture. Pour installer un registre Harbor local, reportez-vous à la section Déployer un registre Harbor hors ligne sur vSphere.
Délais d'attente : En outre, lorsqu'un cluster de charge de travail Edge dispose de son cluster de gestion distant dans un centre de données principal, vous devrez peut-être ajuster certains délais d'attente pour laisser au cluster de gestion suffisamment de temps afin de se connecter aux machines du cluster de charge de travail. Pour ajuster ces délais d'attente, reportez-vous à la section Extension des délais d'attente pour les clusters Edge afin de gérer une latence plus élevée ci-dessous.
Spécification d'un modèle de VM local
Si vos clusters de charge de travail Edge utilisent leur propre stockage isolé plutôt que le stockage vCenter partagé, vous devez les configurer pour récupérer des images de modèles de VM de nœud, en tant que fichiers OVA, à partir d'un stockage local.
RemarqueVous ne pouvez pas utiliser
tanzu cluster upgradepour mettre à niveau la version de Kubernetes d'un cluster de charge de travail Edge qui utilise un modèle de VM local. Mettez plutôt à niveau le cluster en suivant la section Mettre à niveau un cluster Edge avec un modèle de VM local suivante de Mettre à niveau des clusters de charge de travail.
Pour spécifier un modèle de VM unique pour le cluster ou différents modèles propres aux déploiements de travailleurs et de machines de plan de contrôle :
-
Créez le fichier de configuration du cluster et générez le manifeste du cluster à l'étape 1 du processus en deux étapes décrit dans la section Créer un cluster basé sur une classe.
-
Assurez-vous que les modèles de VM pour le cluster :
- Disposent d'une version de Kubernetes valide pour TKG.
- Disposent d'une version OVA valide qui correspond à la propriété
spec.osImagesd'une TKr. - Sont chargés dans l'instance de vCenter locale et disposent d'un chemin d'inventaire valide, par exemple
/dc0/vm/ubuntu-2004-kube-v1.27.5+vmware.1-tkg.1.
-
Modifiez la spécification d'objet
Clusterdans le manifeste comme suit, selon que vous définissez un modèle de VM à l'échelle du cluster ou plusieurs modèles de VM :-
Modèle de VM à l'échelle du cluster :
- Sous
annotations, définissezrun.tanzu.vmware.com/resolve-vsphere-template-from-pathsur la chaîne vide. - Dans le bloc
vcentersousspec.topology.variables, définisseztemplatesur le chemin d'inventaire du modèle de VM. -
Par exemple :
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: topology: class: tkg-vsphere-default-v1.0.0 variables: - name: vcenter value: cloneMode: fullClone datacenter: /dc0 datastore: /dc0/datastore/sharedVmfs-0 folder: /dc0/vm/folder0 network: /dc0/network/VM Network resourcePool: /dc0/host/cluster0/Resources/rp0 ... template: VM-TEMPLATE ...VM-TEMPLATEcorrespond au chemin d'accès au modèle de VM pour le cluster.
- Sous
-
Plusieurs modèles de VM par
machineDeployment:- Sous
annotations, définissezrun.tanzu.vmware.com/resolve-vsphere-template-from-pathsur la chaîne vide. - Dans la valeur
variables.overridesde chaque blocmachineDeploymentssousspec.topology.workeretcontrolplane, ajoutez une ligne pourvcenterqui définittemplatesur le chemin d'accès de l'inventaire du modèle de VM. -
Par exemple :
annotations: run.tanzu.vmware.com/resolve-vsphere-template-from-path: "" ... spec: workers: machineDeployments: - class: tkg-worker metadata: annotations: run.tanzu.vmware.com/resolve-os-image: image-type=ova,os-name=ubuntu name: md-1 replicas: 2 variables: overrides: - name: vcenter value: ... datacenter: /dco template: VM-TEMPLATE ...VM-TEMPLATEcorrespond au chemin d'accès au modèle de VM pour lemachineDeployment.
- Sous
-
-
Utilisez le fichier de configuration modifié pour créer le cluster à l'étape 2 du processus décrit dans la section Créer un cluster basé sur une classe.
Extension des délais d'attente pour les clusters Edge afin de gérer une latence plus élevée
Si votre cluster de gestion gère à distance des clusters de charge de travail s'exécutant sur des sites Edge ou gère à distance plus de 20 clusters de charge de travail, vous pouvez ajuster des délais d'attente spécifiques afin que l'API de cluster ne bloque pas ou ne supprime pas les machines qui peuvent être temporairement hors ligne ou qui prennent plus de 12 minutes pour communiquer avec leur cluster de gestion à distance, en particulier si votre infrastructure est sous-provisionnée.
Voici trois paramètres que vous pouvez ajuster pour donner à vos clusters Edge un délai supplémentaire pour communiquer avec leur plan de contrôle :
-
MHC_FALSE_STATUS_TIMEOUT: Augmentez la valeur par défaut de12mpour, par exemple,40m, afin d'empêcher le contrôleurMachineHealthCheckde recréer la machine si sa conditionReadyresteFalsependant plus de 12 minutes. Pour plus d'informations sur les contrôles de santé de la machine, reportez-vous à la section Configurer les contrôles de santé de la machine pour les clusters Tanzu Kubernetes. -
NODE_STARTUP_TIMEOUT: Augmentez la valeur par défaut de20mpour, par exemple,60mempêcher le contrôleurMachineHealthCheckde bloquer l'accès au cluster pour de nouvelles machines lorsqu'elles ont mis plus de 20 minutes à démarrer, ce qu'il considère comme défectueux. -
etcd-dial-timeout-duration: Étendez la valeur par défaut de10mà40s(par exemple) dans le manifestecapi-kubeadm-control-plane-controller-managerpour empêcher l'échec prématuré des clientsetcdsur le cluster de gestion lors de l'analyse de la santé deetcdsur les clusters de charge de travail. Le cluster de gestion utilise sa capacité à se connecter àetcdcomme critère pour la santé de la machine. Par exemple :-
Dans un terminal, exécutez :
kubectl edit capi-kubeadm-control-plane-controller-manager -n capi-system -
Modifiez la valeur de
--etcd-dial-timeout-duration:- args: - --leader-elect - --metrics-bind-addr=localhost:8080 - --feature-gates=ClusterTopology=false - --etcd-dial-timeout-duration=40s command: - /manager image: projects.registry.vmware.com/tkg/cluster-api/kubeadm-control-plane-controller:v1.0.1_vmware.1
-
En outre, vous voudrez noter les éléments suivants :
-
capi-kubedm-control-plane-manager : S'il devient « séparé » des clusters de charge de travail d'une manière ou d'une autre, vous devrez peut-être le faire rebondir vers un nouveau nœud, afin qu'il puisse surveiller correctement
etcddans les clusters de charge de travail. -
Les configurations Pinniped dans TKG supposent toutes que vos clusters de charge de travail sont connectés à votre cluster de gestion. En cas de déconnexion, vous devez vous assurer que les espaces de charge de travail utilisent des comptes administratifs ou de service pour communiquer avec le serveur d'API sur vos sites Edge. Dans le cas contraire, la déconnexion du cluster de gestion interférera avec la capacité de vos sites Edge à s'authentifier via Pinniped sur leurs serveurs d'API de charge de travail locaux.
