









È possibile creare una distribuzione dell'appliance di VMware Cloud Director con un cluster HA del database che fornisce funzionalità di failover al database di VMware Cloud Director.
L'appliance VMware Cloud Director include un database PostgreSQL incorporato. Il database PostgreSQL incorporato include la suite di strumenti di Replication Manager (repmgr), che fornisce una funzionalità a disponibilità elevata (HA) a un cluster di server PostgreSQL.
È possibile distribuire l'appliance di VMware Cloud Director come cella primaria, cella di standby o cella dell'applicazione VMware Cloud Director. Vedere Distribuzione dell'appliance di VMware Cloud Director tramite vSphere Client, Distribuzione dell'appliance di VMware Cloud Director tramite VMware OVF Tool o #GUID-D35B3629-FCA2-40A6-8009-1A6CF8120F30.
Per configurare la disponibilità elevata per il database di VMware Cloud Director, quando si crea il gruppo di server, è possibile configurare un cluster HA del database distribuendo un'istanza primaria e due istanze di standby dell'appliance VMware Cloud Director. È possibile scalare in orizzontale il gruppo di server distribuendo inoltre le celle delle applicazioni. Vedere la figura Cluster HA di un database dell'appliance di VMware Cloud Director.
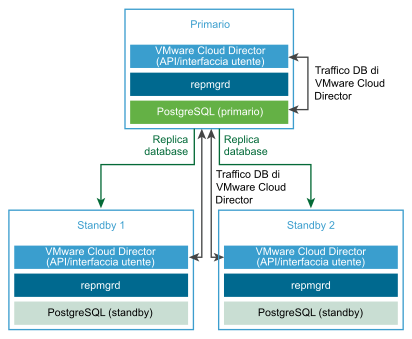
Creazione di una distribuzione dell'appliance VMware Cloud Director con database HA
- Distribuire l'appliance VMware Cloud Director come cella primaria.
La cella primaria è il primo membro del gruppo di server di VMware Cloud Director. Il database incorporato è configurato come database di VMware Cloud Director. Il nome del database è
vcloude l'utente del database èvcloud. - Verificare che la cella primaria sia in esecuzione.
- Per verificare l'integrità del servizio VMware Cloud Director, accedere con le credenziali dell'amministratore di sistema al VMware Cloud Director Service Provider Admin Portal all'indirizzo https://primary_eth0_ip_address/provider.
- Per verificare l'integrità del database PostgreSQL, accedere come root all'interfaccia utente di gestione dell'appliance all'indirizzo https://primary_eth1_ip_address:5480.
Il nodo primario deve essere in stato di esecuzione.
- Distribuire due istanze dell'appliance VMware Cloud Director come celle di standby.
I database incorporati vengono configurati in modalità di replica con il database primario.
Nota: Dopo la distribuzione iniziale dell'appliance di standby, Replication Manager inizia a sincronizzare il proprio database con il database dell'appliance primaria. Durante questo periodo, il database di VMware Cloud Director e quindi l'interfaccia utente di VMware Cloud Director non sono disponibili. - Verificare che tutte le celle nel cluster HA siano in esecuzione.
- (Facoltativo) Distribuire una o più istanze dell'appliance VMware Cloud Director come celle dell'applicazione VMware Cloud Director.
I database incorporati non vengono utilizzati. La cella dell'applicazione VMware Cloud Director si connette al database primario.
Automatic. Vedere l'
API dell'appliance VMware Cloud Director. La modalità di failover predefinita per le nuove celle è
Manual. Se la modalità di failover non è coerente tra i nodi del cluster, la modalità di failover del cluster è
Indeterminate. La modalità di
Indeterminate può causare stati di cluster incoerenti tra i nodi e i nodi che seguono una cella primaria precedente. Per visualizzare la modalità di failover del cluster, vedere
Visualizzazione della modalità di failover e dell'integrità del cluster dell'appliance di VMware Cloud Director.
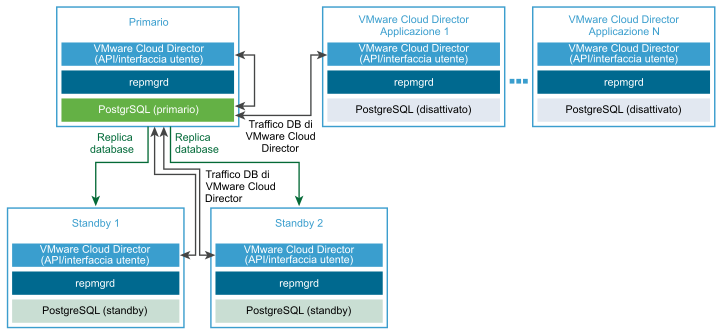
Creazione di una distribuzione dell'appliance VMware Cloud Director senza database HA
- Distribuire l'appliance VMware Cloud Director come cella primaria.
La cella primaria è il primo membro del gruppo di server di VMware Cloud Director. Il database incorporato è configurato come database di VMware Cloud Director. Il nome del database è
vcloude l'utente del database èvcloud. - Verificare che la cella primaria sia in esecuzione.
- Per verificare l'integrità del servizio VMware Cloud Director, accedere con le credenziali dell'amministratore di sistema al VMware Cloud Director Service Provider Admin Portal all'indirizzo https://primary_eth0_ip_address/provider.
- Per verificare l'integrità del database PostgreSQL, accedere come root all'interfaccia utente di gestione dell'appliance all'indirizzo https://primary_eth1_ip_address:5480.
Il nodo primario deve essere in stato di esecuzione.
- (Facoltativo) Distribuire una o più istanze dell'appliance VMware Cloud Director come celle dell'applicazione VMware Cloud Director.
Il database incorporato non viene utilizzato. La cella dell'applicazione VMware Cloud Director si connette al database primario.
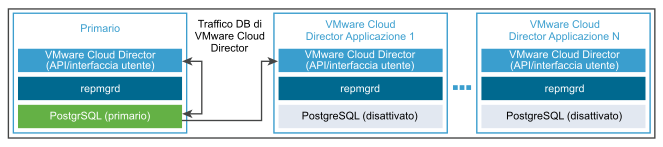
Failover automatico dell'appliance di VMware Cloud Director
Se il servizio del database primario non riesce, è possibile attivare VMware Cloud Director per eseguire un failover automatico in un nuovo database primario.
Grazie al failover automatico, l'amministratore non deve avviare l'azione di failover se il servizio di database primario non funziona per qualsiasi motivo. Per impostazione predefinita, la modalità di failover è impostata su manuale. È possibile impostare la modalità di failover su automatica o manuale utilizzando l'API dell'appliance di VMware Cloud Director. Vedere Riferimento dello schema dell'API dell'appliance di VMware Cloud Director.
Automatic. Vedere l'
API dell'appliance VMware Cloud Director. La modalità di failover predefinita per le nuove celle è
Manual. Se la modalità di failover non è coerente tra i nodi del cluster, la modalità di failover del cluster è
Indeterminate. La modalità di
Indeterminate può causare stati di cluster incoerenti tra i nodi e i nodi che seguono una cella primaria precedente. Per visualizzare la modalità di failover del cluster, vedere
Visualizzazione della modalità di failover e dell'integrità del cluster dell'appliance di VMware Cloud Director.
Se l'ambiente dispone di almeno due celle di standby attive, in caso errore del database primario, viene avviato automaticamente un failover del database. Dopo il failover, deve essere presente almeno una cella di standby attiva affinché il nuovo database primario possa essere aggiornato. In circostanze normali, la distribuzione dell'appliance di VMware Cloud Director deve disporre sempre di almeno due celle di standby attive. Se è presente una sola cella di standby attiva per un breve periodo, ad esempio a causa di un errore della cella primaria e della promozione di una delle celle di standby, la cella primaria non riuscita deve essere sostituita con una nuova cella di standby non appena possibile.
Quando sono presenti una cella primaria attiva e almeno due celle di standby attive, lo stato del cluster viene considerato Healthy. Se sono presenti una cella primaria attiva e una sola cella di standby attiva, lo stato del cluster è Degraded. Se si verifica un altro errore del database mentre il cluster ha stato Degraded, la cella primaria non può essere aggiornata finché non è online un'altra cella di standby. Quando il database primario non può essere aggiornato, VMware Cloud Director non è disponibile perché le celle di VMware Cloud Director non sono in grado di aggiornare il database finché non è presente almeno una cella di standby attiva per elaborare una replica di streaming dal database primario. Il concetto di un cluster Healthy e Degraded è lo stesso indipendentemente dal fatto che si attivi il failover manuale o automatico.
Dopo un errore del database primario, lo stato della cella primaria è No_Active_Primary. Per un failover manuale dell'appliance VMware Cloud Director, l'amministratore deve promuovere manualmente un'istanza di standby come primaria e ridistribuire la cella primaria non riuscita come cella di standby. Per il failover automatico dell'appliance, VMware Cloud Director promuove automaticamente una cella da standby a primaria e l'amministratore ridistribuisce manualmente la cella primaria non riuscita come standby.
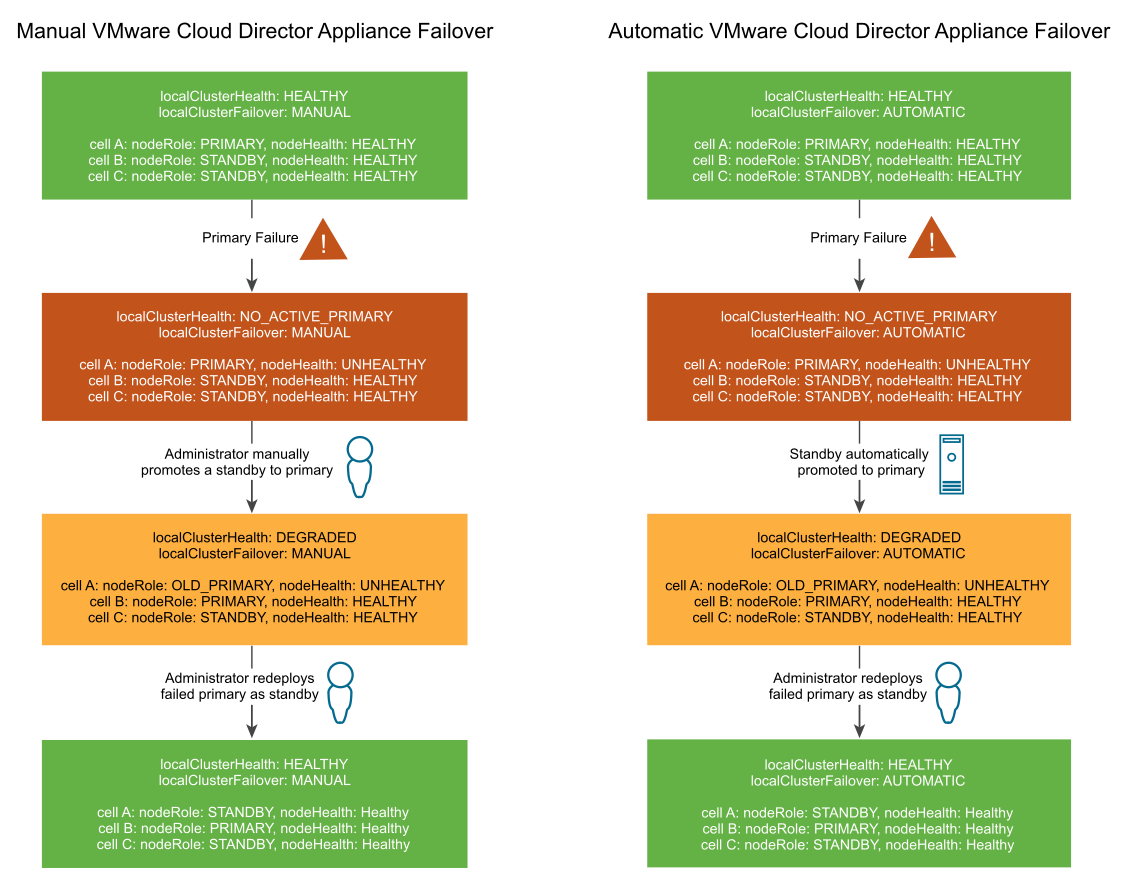
Annullamento automatico della priorità di una cella primaria di VMware Cloud Director non riuscita
Se una nuova cella primaria viene promossa dopo un errore della cella primaria, VMware Cloud Director annulla automaticamente la priorità della cella primaria precedente per impedirne il riavvio.
In caso di failover, se un database primario non riuscito viene riavviato dopo la promozione di una nuova cella primaria, VMware Cloud Director annulla automaticamente la priorità della cella primaria precedente. Questa automazione previene la sindrome split brain in cui due database attivi possono divergere l'uno dall'altro. L'automazione di annullamento della priorità arresta e disattiva il servizio vpostgres nel nodo primario precedente. Successivamente, è possibile ridistribuire la cella primaria non riuscita come cella di standby per reimpostare l'integrità del cluster su Healthy.
Per ulteriori informazioni sulla visualizzazione dello stato di integrità del cluster e sulla modalità di failover, vedere Visualizzazione della modalità di failover e dell'integrità del cluster dell'appliance di VMware Cloud Director.
