









VMware Aria Automation は、DevOps エンジニアとデータ サイエンティストが VMware Private AI Foundation with NVIDIA で AI ワークロードをユーザー フレンドリでカスタマイズ可能な方法でプロビジョニングするために使用できるセルフサービス カタログ アイテムのサポートを提供します。
前提条件
クラウド管理者である場合は、VMware Private AI Foundation with NVIDIA 環境が構成されていることを確認します。プライベート AI ワークロード展開のための VMware Cloud Foundation の準備を参照してください。
VMware Private AI Foundation with NVIDIA のワークロード ドメインへの VMware Aria Automation の接続
VMware Aria Automation を使用して AI アプリケーションをプロビジョニングするためのカタログ アイテムを追加するには、VMware Aria Automation を VMware Cloud Foundation に接続します。
手順
カタログ セットアップ ウィザードを使用した VMware Aria Automation での AI カタログ アイテムの作成
クラウド管理者である場合は、VMware Aria Automation のカタログ セットアップ ウィザードを使用して、組織内のデータ サイエンティストや DevOps チームがセルフサービス Automation Service Broker カタログで要求できるカタログ アイテムとして、GPU 対応のディープ ラーニング仮想マシンおよび VMware Tanzu Kubernetes Grid (TKG) クラスタを設定および提供することになります。
カタログ セットアップ ウィザードの仕組み
- クラウド アカウントを追加します。クラウド アカウントは、vCenter インスタンスからデータを収集し、そのインスタンスにリソースを展開するために使用される認証情報です。
- NVIDIA ライセンスを追加します。
- VMware Data Services Manager 統合を構成します。
- Automation Service Broker カタログに追加するコンテンツを選択します。
- プロジェクトを作成します。プロジェクトはユーザーをクラウド アカウント リージョンにリンクして、ネットワークとストレージ リソースを含むクラウド テンプレートを vCenter インスタンスに展開できるようにします。
- [AI Workstation] – GPU 対応の仮想マシンで、目的の vCPU、vGPU、メモリ、および PyTorch、CUDA サンプル、TensorFlow などの AI/ML フレームワークを事前インストールするオプションを使用して構成できます。
- [AI RAG Workstation] – Retrieval Augmented Generation (RAG) リファレンス ソリューションを提供する GPU 対応の仮想マシン。
- [Triton Inference Server] – Triton Inference Server を備えた GPU 対応の仮想マシン。
- [AI Kubernetes クラスタ] - AI/ML クラウド ネイティブ ワークロードを実行するための GPU 対応のワーカー ノードを備えた VMware Tanzu Kubernetes Grid クラスタ。
- [AI Kubernetes RAG クラスタ] - リファレンス RAG ソリューションを実行するための GPU 対応のワーカー ノードを備えた VMware Tanzu Kubernetes Grid クラスタ。
- [DSM データベース] – VMware Data Services Manager によって管理される pgvector データベース。
- [AI RAG Workstation と DSM] – VMware Data Services Manager によって管理される pgvector データベースを持つ GPU 対応の仮想マシン。
- [DSM を使用する AI Kubernetes RAG クラスタ] - VMware Data Services Manager によって管理される pgvector データベースを持つ VMware Tanzu Kubernetes Grid クラスタ。
- 別のスーパーバイザーで AI ワークロードのプロビジョニングを有効にする。
- クライアント構成 .tok ファイルとライセンス サーバ、または切断された環境の vGPU ゲスト ドライバのダウンロード URL を含む、NVIDIA AI Enterprise ライセンスの変更に対応する。
- ディープ ラーニング仮想マシン イメージの変更に対応する。
- 他の vGPU または非 GPU 仮想マシン クラス、ストレージ ポリシー、またはコンテナ レジストリを使用する。
- 新しいプロジェクトにカタログ アイテムを作成する。
ウィザードが作成したカタログ アイテムのテンプレートを組織の特定のニーズに合わせて変更できます。
始める前に
- 展開ワークフローのこの手順まで VMware Private AI Foundation with NVIDIA が構成されていることを確認します。プライベート AI ワークロード展開のための VMware Cloud Foundation の準備を参照してください。
手順
- VMware Aria Automation にログインしたら、[クイックスタートの起動] をクリックします。
![[クイックスタートの起動] タイルがあるコンソール。](images/GUID-4D75F288-C411-4F5A-9FB7-8297D9ADE6B8-low.png)
- [プライベート AI 自動化サービス] カードで、[開始] をクリックします。
- アクセスをプロビジョニングするクラウド アカウントを選択します。
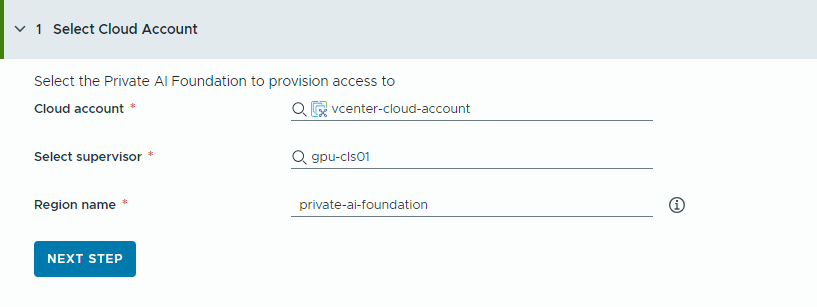
すべての値は使用事例のサンプルであることに注意してください。アカウントの値は環境によって異なります。
- vCenter クラウド アカウントを選択します。
- GPU 対応のスーパーバイザーを選択します。
- リージョン名を入力します。
スーパーバイザーがすでにリージョンで構成されている場合は、リージョンが自動的に選択されます。
スーパーバイザーがリージョンに関連付けられていない場合は、この手順で追加します。ユーザーが GPU 対応のリージョンを他の使用可能なリージョンと区別できるように、リージョンのわかりやすい名前を使用することを検討してください。
- [次のステップ] をクリックします。
- NVIDIA ライセンス サーバに関する情報を指定します。
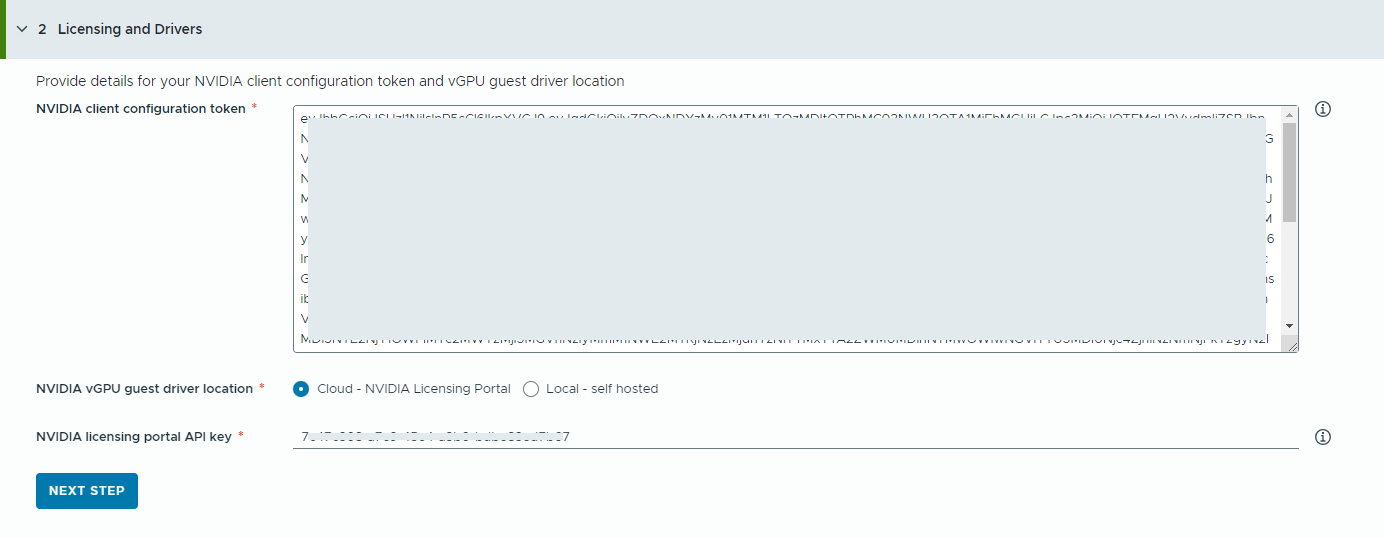
- NVIDIA クライアント構成トークンの内容をコピーして貼り付けます。
クライアント構成トークンは、ディープ ラーニング仮想マシンのゲスト vGPU ドライバと、TKG クラスタの GPU Operator にライセンスを割り当てるために使用されます。
- NVIDIA vGPU ドライバの場所を選択します。
- クラウド – NVIDIA vGPU ドライバは、NVIDIA ライセンス ポータルでホストされます。
NVIDIA ライセンス ポータル API キーを指定する必要があります。これは、NVIDIA vGPU ドライバをダウンロードする適切な資格をユーザーが持っているかどうかを評価するために使用されます。API キーは UUID である必要があります。
- ローカル – NVIDIA vGPU ドライバはオンプレミスでホストされ、プライベート ネットワークからアクセスします。
仮想マシンの vGPU ゲスト ドライバの場所を指定する必要があります。
エアギャップ環境の場合、vGPU ドライバはプライベート ネットワークまたはデータセンターで使用できる必要があります。
- クラウド – NVIDIA vGPU ドライバは、NVIDIA ライセンス ポータルでホストされます。
- [次のステップ] をクリックします。
- NVIDIA クライアント構成トークンの内容をコピーして貼り付けます。
- RAG アプリケーション用の VMware Data Services Manager (DSM) データベースを構成して、個別のデータベース カタログ アイテムを生成します。
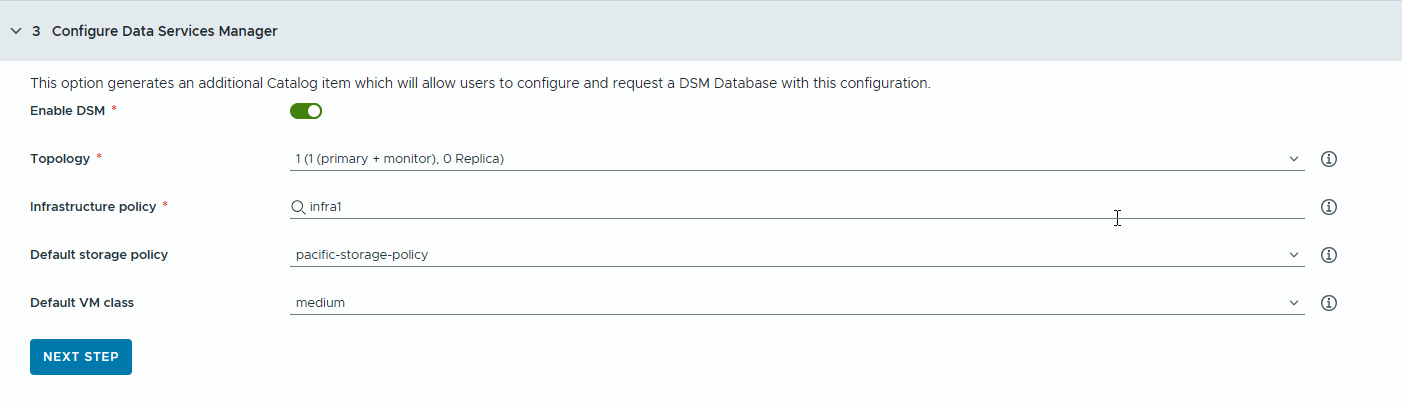
VMware Data Services Manager を使用して、pgvector 拡張機能を備えた PostgreSQL データベースなどのベクター データベースを作成します。
データベースは、ディープ ラーニング仮想マシンとは異なるワークロード ドメインにプロビジョニングされるため、それぞれに異なる仮想マシン クラスとストレージ プロファイルを使用する必要があります。VMware Data Services Manager データベースの場合は、RAG の使用事例に適したストレージ ポリシーと仮想マシン クラスを選択します。
- トグルをオンにします。
開発者とカタログ ユーザーが単一の DSM データベースを共有できるようにする場合は、このオプションを使用します。注: トグルをオンにすると、新しい DSM データベース カタログ アイテムが作成されます。
プロジェクトに DSM 統合が必要ない場合は、トグルをオフにして、次の手順に進むことができます。この場合、DSM カタログ アイテムは生成されませんが、ユーザーは他の RAG カタログ アイテムで組み込みの DSM データベースを利用できます。
- レプリカ モードとトポロジを選択します。
データベース ノードの構成は、レプリカ モードによって異なります。
- 単一サーバ – レプリカのない 1 つのプライマリ ノード。
- 単一 vSphere クラスタ – 単一の vSphere クラスタ上の 3 台のノード(プライマリ 1 台、監視 1 台、レプリカ 1 台)で、中断なしのアップグレードを提供します。
- インフラストラクチャ ポリシーを選択します。
インフラストラクチャ ポリシーは、データベースが vSphere クラスタから使用できるリソースの質と量を定義します。
インフラストラクチャ ポリシーを選択すると、インフラストラクチャ ポリシーに関連付けられているストレージ ポリシーと仮想マシン クラスから選択できます。
- デフォルトのストレージ ポリシーを選択します。
ストレージ ポリシーは、データベースのストレージ配置とリソースを定義します。
- デフォルトの仮想マシン クラスを選択します。
仮想マシン クラスは、新しく要求されたデータベースのプロビジョニングには使用できません。
DSM 仮想マシン クラスはスーパーバイザー仮想マシン クラスとは異なります。
- トグルをオンにします。
- カタログ アイテムを構成します。
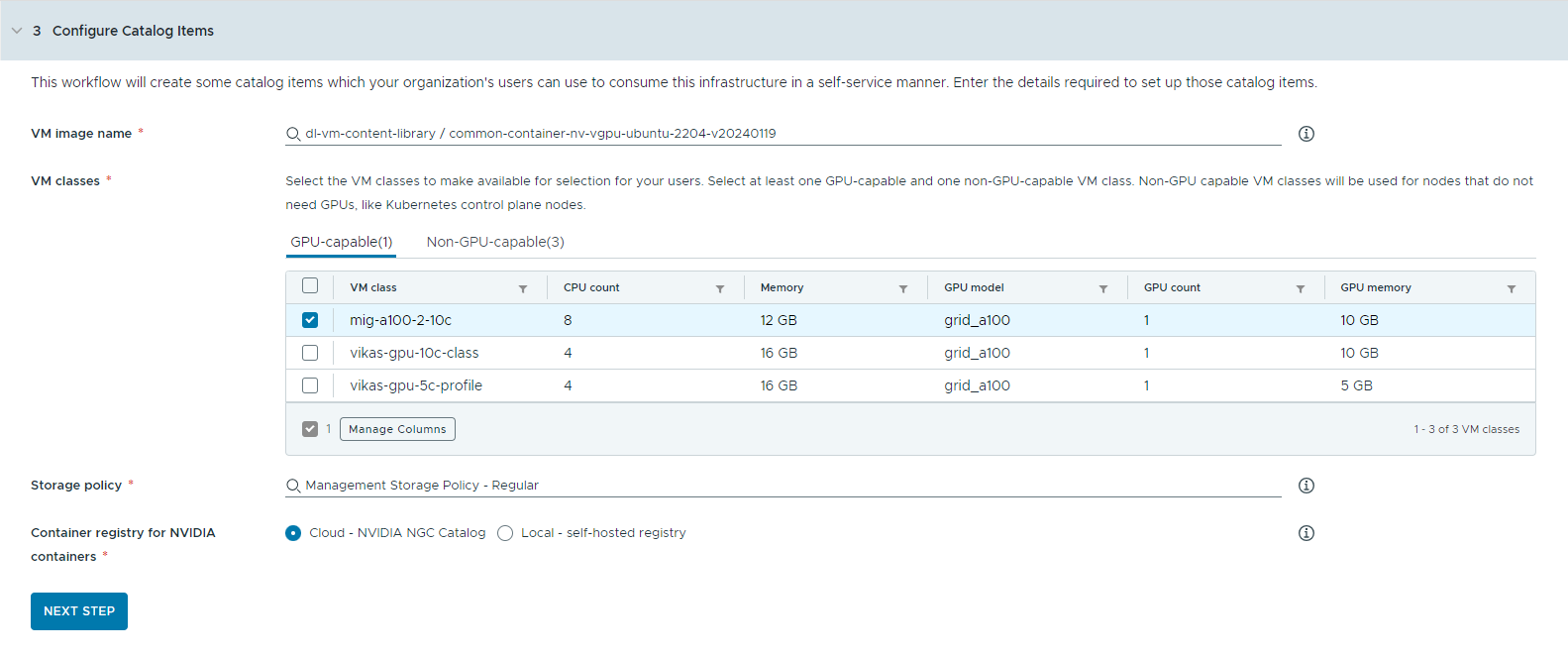
- ディープ ラーニング仮想マシン イメージを含むコンテンツ ライブラリを選択します。
一度にアクセスできるコンテンツ ライブラリは 1 つのみです。コンテンツ ライブラリに Kubernetes イメージが含まれている場合は、ナビゲーションを容易にするためにそれらのイメージが除外されます。
- ワークステーション仮想マシンの作成に使用する仮想マシン イメージを選択します。
- AI Kubernetes クラスタの展開に使用する Tanzu Kubernetes リリースを選択します。
Tanzu Kubernetes リリース (TKr) は、ユーザーが Kubernetes クラスタを要求したときに展開される Kubernetes ランタイム バージョンです。VMware Private AI Foundation でサポートされている 3 つの最新の Tanzu Kubernetes リリース バージョンから選択できます。
- カタログ ユーザーによる使用を可能にする仮想マシン クラスを選択します。
少なくとも 1 つの GPU 対応クラスと 1 つの GPU 非対応クラスを追加する必要があります。
- GPU 対応の仮想マシン クラスは、ディープ ラーニング仮想マシンと TKG クラスタのワーカー ノードに使用されます。カタログ アイテムが展開されると、選択した仮想マシン クラスを使用して TKG クラスタが作成されます。
- Kubernetes 制御プレーンを実行するには、GPU 非対応ノードが必要です。
- Triton Inference Server で AI Workstation を実行するには、統合仮想メモリ (UVM) が有効になっている仮想マシン クラスが必要です。
- ストレージ ポリシーを選択します。
ストレージ ポリシーは、仮想マシンのストレージ配置とリソースを定義します。
仮想マシンに定義したストレージ ポリシーは、VMware Data Services Manager ストレージ ポリシーとは異なります。
- NVIDIA GPU Cloud リソースをプルするコンテナ レジストリを指定します。
- クラウド – コンテナ イメージは、NVIDIA NGC カタログからプルされます。
- ローカル – エアギャップ環境の場合、コンテナはプライベート レジストリからプルされます。
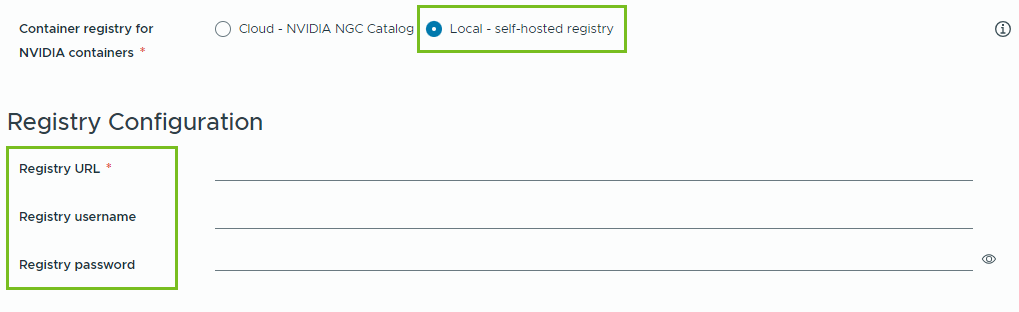
自己ホスト型レジストリの場所を指定する必要があります。レジストリで認証が必要な場合は、ログイン認証情報も指定する必要があります。
NVIDIA NGC カタログのコンテナ イメージのローカル レジストリとして Harbor を使用できます。「VMware Private AI Foundation with NVIDIA でのプライベート Harbor レジストリの設定」を参照してください。
- (オプション)プロキシ サーバを構成します。
インターネットに直接アクセスできない環境では、プロキシ サーバを使用して vGPU ドライバをダウンロードし、RAG 以外の AI Workstation コンテナをプルします。
注: エアギャップ環境のサポートは、AI Workstation および Triton Inference Server カタログ アイテムで使用できます。AI RAG Workstation および AI Kubernetes クラスタ アイテムはエアギャップ環境をサポートしていないため、インターネット接続が必要です。 - [次のステップ] をクリックします。
- ディープ ラーニング仮想マシン イメージを含むコンテンツ ライブラリを選択します。
- プロジェクトを作成してユーザーを割り当てることで、カタログ アイテムへのアクセスを構成します。
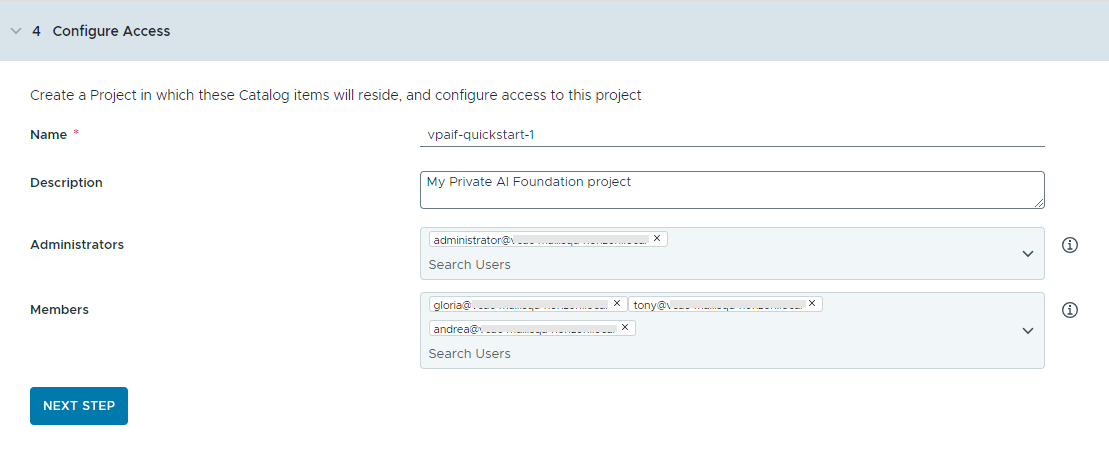
プロジェクトは、ユーザー、割り当てられたリソース、クラウド テンプレート、および展開を管理するために使用されます。
- プロジェクトの名前と説明を入力します。
プロジェクト名には、小文字の英数字またはハイフン (-) のみを使用する必要があります。
- カタログ アイテムを他のユーザーが使用できるようにするには、[管理者] および [メンバー] を追加します。
管理者にはメンバーよりも多くの権限があります。詳細については、VMware Aria Automation のユーザー ロールについてを参照してください。
- [次のステップ] をクリックします。
- プロジェクトの名前と説明を入力します。
- [サマリ] ページで構成を確認します。
ウィザードを実行する前に、構成の詳細を保存することを検討してください。
- [クイックスタートの実行] をクリックします。
結果
次のカタログ アイテム – [AI Workstation]、[AI RAG Workstation]、[AI RAG Workstation with DSM]、[DSM Database]、[Triton Inferencing Server]、[AI Kubernetes Cluster]、[AI Kubernetes RAG Cluster] および [AI Kubernetes RAG Cluster with DSM] は Automation Service Broker カタログに作成され、組織内のユーザーが展開できるようになりました。
![Private AI Foundation カタログ アイテムを含む [Service Broker カタログ] ページの表示。](images/GUID-7D415041-E729-444E-8065-74AAB5C852AA-low.png)
トラブルシューティング
- カタログ セットアップ ウィザードが失敗した場合は、別のプロジェクトに対してウィザードを再実行します。
