









NSX-T Data Center は複数サイトの展開をサポートしており、1 つの NSX Manager クラスタからすべてのサイトを管理できます。
- ディザスタ リカバリ
- アクティブ/アクティブ
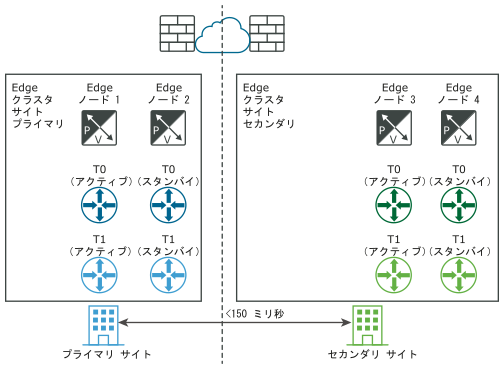
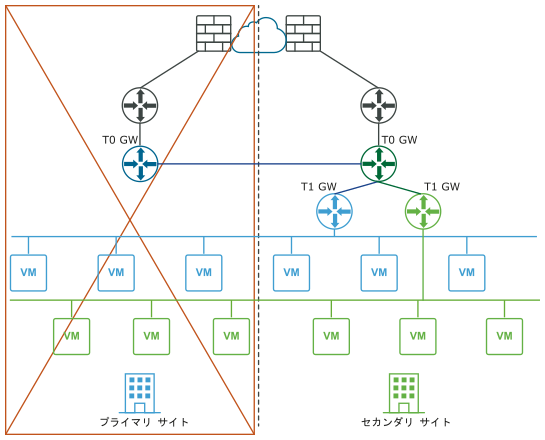
次の図に、ディザスタ リカバリの展開を示します。
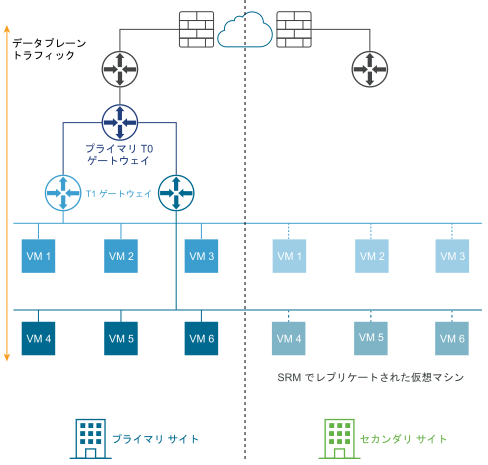
ディザスタ リカバリの展開では、プライマリ サイトの NSX-T Data Center は企業のネットワークを処理します。セカンダリ サイトは、プライマリ サイトで致命的な障害が発生した場合に引き継ぐ準備をしています。
次の図に、アクティブ/アクティブ展開を示します。
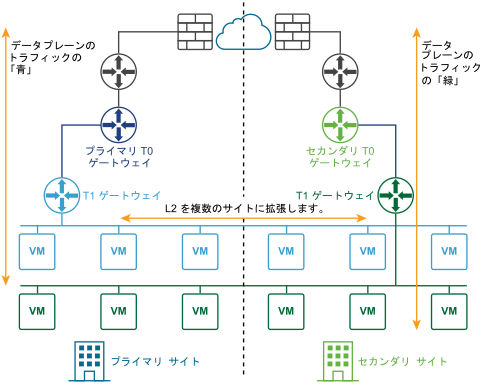
管理プレーンとデータ プレーンのリカバリを自動、手動またはスクリプトで行うため、2 つのサイトを展開できます。
管理プレーンの自動リカバリ
- 拡張された vCenter Server クラスタでサイト間の高可用性 (HA) が構成されている必要があります。
- 管理 VLAN が拡張されている必要があります。
NSX Manager クラスタは管理 VLAN に展開され、プライマリ サイトに物理的に配置されます。プライマリ サイトに障害が発生した場合、vSphere HA はセカンダリ サイトの NSX Manager を再起動します。すべてのトランスポート ノードが、再起動された NSX Manager に自動的に再接続します。このプロセスには約 10 分間かかります。この間、管理プレーンは使用できませんが、データ プレーンに影響はありません。
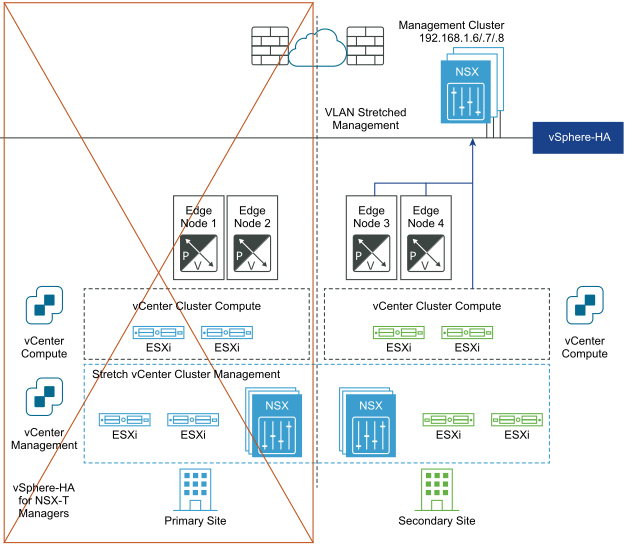
次の図に、管理プレーンの自動リカバリを示します。
障害発生前:

ディザスタ リカバリ後:
データ プレーンの自動リカバリ
データ プレーンの自動リカバリを実現するには、Edge ノードの障害ドメインを構成します。異なる障害ドメインで Edge クラスタ内の Edge ノードをグループ化できます。NSX Manager は、優先障害ドメインに新しいアクティブ Tier-1 ゲートウェイを自動的に配置し、もう一方のドメインにスタンバイ Tier-1 ゲートウェイを自動的に配置します。障害ドメインの作成前に展開された Tier-1 ゲートウェイは、元の Edge ノードの配置を維持します。このため、必要な場所で実行されていない可能性があります。配置を修正する場合は、T1 を編集し、T1-Active と T1-Standby ゲートウェイの Edge ノードを手動で選択します。
- Edge ノード間の最大遅延が 10 ミリ秒でなければなりません。
- NSX Edge ノードの North バウンドで物理ファイアウォールが使用されている場合など、非対称の North-South ルーティングを実行できない場合は、Tier-0 ゲートウェイの HA モードをアクティブ/スタンバイにし、フェイルオーバー モードをプリエンプティブにする必要があります。
- 2 つの場所が 2 つの建物にあり、その間に物理ファイアウォールがない場合など、非対称の North-South ルーティングが可能な場合は、Tier-0 ゲートウェイの HA モードをアクティブ/アクティブにすることができます。
Edge ノードには仮想マシンまたはベアメタルを使用できます。Tier-1 ゲートウェイのフェイルオーバー モードはプリエンプティブまたは非プリエンプティブのいずれかですが、Tier-0 ゲートウェイと Tier-1 ゲートウェイが同じ場所にあることを保証するために、プリエンプティブを使用することをお勧めします。
- API を使用して、2 つのサイト(たとえば、FD1A-Preferred_Site1 と FD2A-Preferred_Site1)に障害ドメインを作成します。プライマリ サイトの場合は preferred_active_edge_services パラメータを
trueに設定し、セカンダリ サイトの場合はfalseに設定します。POST /api/v1/failure-domains { "display_name": "FD1A-Preferred_Site1", "preferred_active_edge_services": "true" } POST /api/v1/failure-domains { "display_name": "FD2A-Preferred_Site1", "preferred_active_edge_services": "false" } - API を使用して、2 つのサイト間で拡張された Edge クラスタを構成します。たとえば、クラスタのプライマリ サイトに Edge ノード EdgeNode1A と EdgeNode1B があり、セカンダリ サイトに Edge ノード EdgeNode2A と EdgeNode2B があるとします。アクティブ Tier-0 とアクティブ Tier-1 ゲートウェイは、EdgeNode1A と EdgeNode1B 上で実行されます。スタンバイ Tier-0 とスタンバイ Tier-1 ゲートウェイは、EdgeNode2A と EdgeNode2B で実行されます。
- API を使用して、各 Edge ノードをサイトの障害ドメインと関連付けます。Edge ノードに関するデータを取得するには、
GET /api/v1/transport-nodes/<transport-node-id>API を実行します。GET API の結果をPUT /api/v1/transport-nodes/<transport-node-id>API の入力として使用し、プロパティ failure_domain_id を適切に設定します。次はその例です。GET /api/v1/transport-nodes/<transport-node-id> Response: "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... } PUT /api/v1/transport-nodes/<transport-node-id> { "resource_type": "TransportNode", "description": "Updated NSX configured Test Transport Node", "id": "77816de2-39c3-436c-b891-54d31f580961", ... "failure_domain_id": "<UUID>", } - API を使用して、障害ドメインに基づいてノードを割り当てるように Edge クラスタを構成します。Edge クラスタに関するデータを取得するには、
GET /api/v1/edge-clusters/<edge-cluster-id>API を実行します。GET API の結果をPUT /api/v1/edge-clusters/<edge-cluster-id>API の入力として使用し、追加のプロパティ allocation_rules を適切に設定します。次はその例です。GET /api/v1/edge-clusters/<edge-cluster-id> Response: { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... } PUT /api/v1/edge-clusters/<edge-cluster-id> { "_revision": 0, "id": "bf8d4daf-93f6-4c23-af38-63f6d372e14e", "resource_type": "EdgeCluster", ... "allocation_rules": [ { "action": { "enabled": true, "action_type": "AllocationBasedOnFailureDomain" } } ], } - API または NSX Manager のユーザー インターフェイスを使用して、Tier-0 と Tier-1 ゲートウェイを作成します。
プライマリ サイト全体で障害が発生した場合、セカンダリ サイトの Tier-0 スタンバイと Tier-1 スタンバイが自動的に処理を引き継ぎ、新しいアクティブ ゲートウェイになります。
次の図に、データ プレーンの自動リカバリを示します。
障害発生前:
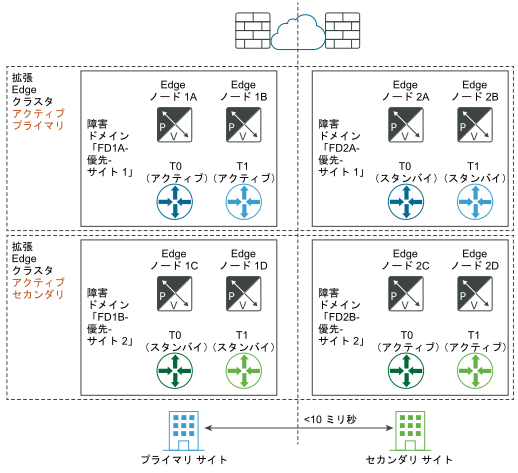
ディザスタ リカバリ後:
プライマリ サイトのいずれかの Edge ノードで障害が発生し、サイト全体の障害ではない場合は、同じ原則が適用されている必要があります。たとえば、「障害発生前」の図で、Edge ノード 1B がアクティブ Tier-1-blue をホストし、Edge ノード 2B がスタンバイ Tier-1-blue をホストしているとします。Edge ノード 1B に障害が発生すると、Edge ノード 2B のスタンバイ Tier-1-blue が引き継ぎ、新しい Tier-1-blue アクティブ ゲートウェイになります。
手動/スクリプトによる管理プレーンのリカバリ
- NSX Manager の DNS に短い TTL(たとえば 5 分)が設定されている必要があります。
- NSX Manager のバックアップが継続的に行われている必要があります。
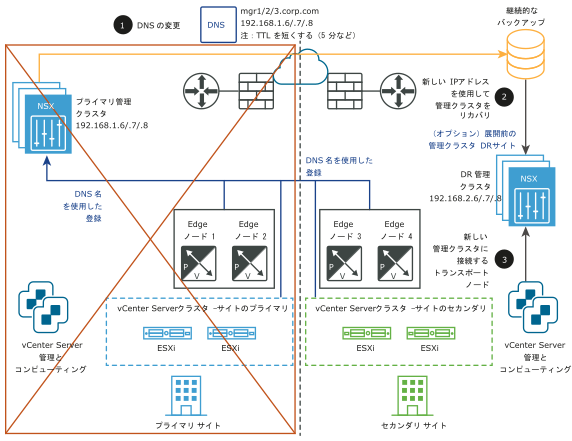
vSphere HA または拡張された管理 VLAN は必要ありません。NSX-T Data Center Manager が、短い TTL の DNS 名に関連付けられている必要があります。すべてのトランスポート ノード(Edge ノードとハイパーバイザー)が、DNS 名を使用して NSX Manager に接続する必要があります。時間を節約するため、セカンダリ サイトに NSX Manager クラスタをプリインストールすることもできます。
- NSX Manager クラスタで異なる IP アドレスを使用できるように DNS レコードを変更します。
- NSX Manager クラスタをバックアップからリストアします。
- 新しい NSX Manager クラスタにトランスポート ノードを接続します。
次の図に、手動/スクリプトによる管理プレーンのリカバリを示します。
障害発生前:

障害発生後:
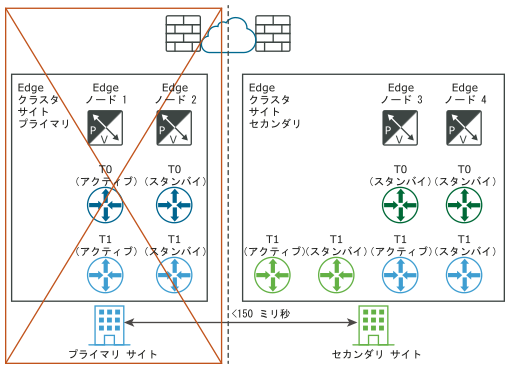
手動/スクリプトによるデータ プレーンのリカバリ
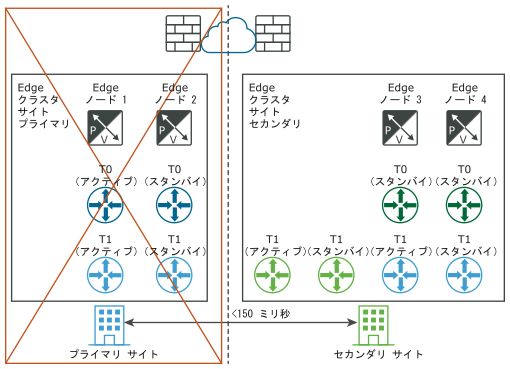
要件:Edge ノード間の最大遅延が 150 ミリ秒でなければなりません。
Edge ノードには仮想マシンまたはベアメタルを使用できます。各場所の Tier-0 ゲートウェイは、アクティブ/スタンバイまたはアクティブ/アクティブにできます。Edge ノード仮想マシンは、別の vCenter Server にインストールできます。vSphere HA は必要ありません。
- プライマリ サイト (blue) のすべての Tier-1 について、Edge クラスタ構成をセカンダリ Edge クラスタ サイトに更新します。
- プライマリ サイト (blue) のすべての Tier-1 について、それらを T0 セカンダリ (green) に再接続します。
次の図に、論理ネットワーク ビューと物理ネットワーク ビューの両方を使用したデータ プレーンの手動/スクリプトによるリカバリを示します。
障害発生前(論理ビューと物理ビュー):
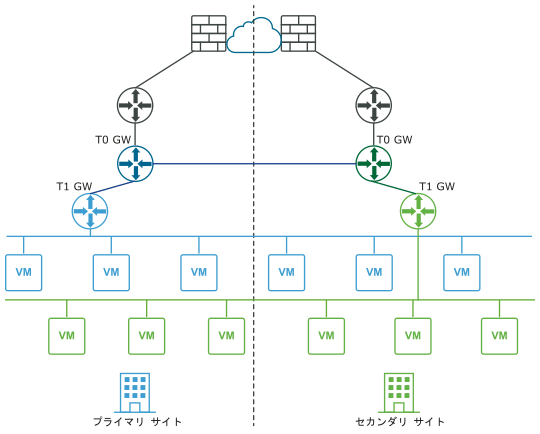
障害発生後(論理ビューと物理ビュー):
複数サイトの展開の要件
- 帯域幅は 1 Gbps 以上で、遅延 (RTT) は 150 ミリ秒未満である必要があります。
- MTU を 9000 に設定します。1600 以上にする必要があります。
- サイト間で VLAN 管理が拡張された管理プレーンの自動リカバリ。NSX Manager 仮想マシンのサイト間での vSphere HA。
- サイト間で VLAN 管理が拡張された管理プレーンの手動/スクリプトによるリカバリ。NSX Manager 仮想マシンの NSX Manager 仮想マシンの VMware SRM。
- サイト間で VLAN 管理が拡張されていない管理プレーンの手動/スクリプトによるリカバリ。
- NSX Manager のバックアップが継続的に行われている必要があります。
- FQDN を使用できるように NSX Manager を設定する必要があります。
- NAT やロード バランサなどのサービスを介してパブリック IP アドレスを公開する場合は、同じインターネット プロバイダを使用する必要があります。
- 管理プレーンの自動リカバリ
- 場所間の最大遅延は 10 ミリ秒です。
- 非対称ルーティングが発生しないように、Tier-0 ゲートウェイの HA モードがアクティブ/スタンバイで、フェイルオーバー モードがプリエンプティブに設定されている必要があります。
- 非対称ルーティングが許容される場合(同じ大都市リージョンにある異なる建物など)、Tier-0 ゲートウェイの HA モードをアクティブ/アクティブにすることができます。
- 手動/スクリプトによる管理プレーンのリカバリ
- 場所間の最大遅延は 150 ミリ秒です。
- CMS は、NSX-T Data Center プラグインをサポートする必要があります。このリリースでは、VMware Integrated OpenStack (VIO) および vRealize Automation (vRA) がこの要件を満たしています。
制限事項
- Local Egress 機能はありません。すべての North-South トラフィックは 1 つのサイト内で発生する必要があります。
- コンピューティング ディザスタリ カバリ ソフトウェアが VMware Site Recovery Manager 8.1.2 以降などの NSX-T Data Center をサポートしている必要があります。
- NSX Manager をマルチサイト環境にリストアする場合は、セカンダリ/プライマリ サイトで次の手順を実行します。
- リストア プロセスが [AddNodeToCluster] 手順で一時停止したら、マネージャ ノードを追加する前に既存の VIP を削除し、 ユーザー インターフェイス ページから新しい仮想 IP を設定する必要があります。
- VIP の更新後、リストアされた 1 ノード クラスタに新しいノードを追加します。
