









VMware Aria Automation bietet Unterstützung für Self-Service-Katalogelemente, die DevOps-Ingenieure und Datenwissenschaftler verwenden können, um KI-Arbeitslasten auf benutzerfreundliche und anpassbare Weise in VMware Private AI Foundation with NVIDIA bereitzustellen.
Voraussetzungen
Stellen Sie als Cloud-Administrator sicher, dass die VMware Private AI Foundation with NVIDIA-Umgebung konfiguriert ist. Weitere Informationen finden Sie unter Vorbereiten von VMware Cloud Foundation für die Bereitstellung von Private AI-Arbeitslasten.
Verbinden von VMware Aria Automation mit einer Arbeitslastdomäne für VMware Private AI Foundation with NVIDIA
Bevor Sie die Katalogelemente für die Bereitstellung von KI-Anwendungen mithilfe von VMware Aria Automation hinzufügen können, verbinden Sie VMware Aria Automation mit VMware Cloud Foundation.
Prozedur
Erstellen von KI-Katalogelementen in VMware Aria Automation mithilfe des Assistenten für die Katalogeinrichtung
Mithilfe des Assistenten für die Katalogeinrichtung in VMware Aria Automation können Cloud-Administratoren GPU-fähige Deep Learning-VMs und VMware Tanzu Kubernetes Grid-Cluster (TKG) als Katalogelemente einrichten und bereitstellen, die von Datenwissenschaftlern und DevOps-Teams in Ihrer Organisation im Automation Service Broker-Self-Service-Katalog angefordert werden können.
Funktionsweise des Assistenten für die Katalogeinrichtung
- Hinzufügen eines Cloud-Kontos. Cloud-Konten sind die Anmeldedaten, die zum Erfassen von Daten aus und zum Bereitstellen von Ressourcen in Ihrer vCenter-Instanz verwendet werden.
- Hinzufügen einer NVIDIA-Lizenz.
- Konfigurieren einer VMware Data Services Manager-Integration.
- Auswählen von Inhalten zum Hinzufügen zum Automation Service Broker-Katalog.
- Erstellen eines Projekts. Das Projekt verknüpft Ihre Benutzer mit Cloud-Kontoregionen, damit Cloud-Vorlagen mit Netzwerken und Speicherressourcen für Ihre vCenter-Instanz bereitgestellt werden können.
- KI-Workstation – eine GPU-fähige virtuelle Maschine, die mit der gewünschten vCPU, der gewünschten vGPU und dem gewünschten Arbeitsspeicher sowie der Option zur Vorabinstallation von KI-/ML-Frameworks wie PyTorch, CUDA Samples und TensorFlow konfiguriert werden kann.
- KI-RAG-Workstation – eine GPU-fähige virtuelle Maschine mit RAG-Referenzlösung (Retrieval Augmented Generation).
- Triton Inference Server – eine GPU-fähige virtuelle Maschine mit Triton Inference Server.
- KI-Kubernetes-Cluster – ein VMware Tanzu Kubernetes Grid-Cluster mit GPU-fähigen Worker-Knoten zum Ausführen von cloudnativen KI-/ML-Arbeitslasten.
- KI-Kubernetes-RAG-Cluster – ein VMware Tanzu Kubernetes Grid-Cluster mit GPU-fähigen Worker-Knoten zum Ausführen einer RAG-Referenzlösung.
- DSM-Datenbank – eine von VMware Data Services Manager verwaltete pgvector-Datenbank.
- KI-RAG-Workstation mit DSM – eine GPU-fähige virtuelle Maschine mit einer von VMware Data Services Manager verwalteten pgvector-Datenbank.
- KI-Kubernetes-RAG-Cluster mit DSM – ein VMware Tanzu Kubernetes Grid-Cluster mit einer von VMware Data Services Manager verwalteten pgvector-Datenbank.
- Aktivieren der Bereitstellung von KI-Arbeitslasten auf einem anderen Supervisor.
- Berücksichtigen einer Änderung Ihrer NVIDIA AI Enterprise-Lizenz, einschließlich der .tok-Datei für die Clientkonfiguration und des Lizenzservers oder der Download-URL für die vGPU-Gasttreiber für eine getrennte Umgebung.
- Integrieren einer Deep Learning-VM-Image-Änderung.
- Verwenden anderer vGPU- oder Nicht-GPU-VM-Klassen, Speicherrichtlinien oder Containerregistrierungen.
- Erstellen von Katalogelementen in einem neuen Projekt.
Sie können die Vorlagen für die vom Assistenten erstellten Katalogelemente ändern, um die spezifischen Anforderungen Ihrer Organisation zu erfüllen.
Vorbereitung
- Stellen Sie sicher, dass VMware Private AI Foundation with NVIDIA bis zu diesem Schritt des Bereitstellungsworkflows konfiguriert ist. Weitere Informationen finden Sie unter Vorbereiten von VMware Cloud Foundation für die Bereitstellung von Private AI-Arbeitslasten.
Prozedur
- Klicken Sie nach der Anmeldung bei VMware Aria Automation auf Schnellstart starten.
- Klicken Sie auf der Karte Private AI Automation Services auf Starten.
- Wählen Sie das Cloud-Konto aus, auf das Zugriff gewährt werden soll.
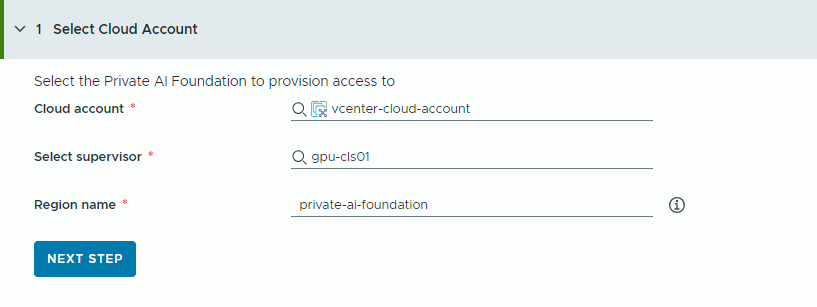
Beachten Sie, dass es sich bei allen Werten um Anwendungsbeispiele handelt. Die Kontowerte richten sich nach der jeweiligen Umgebung.
- Wählen Sie ein vCenter-Cloud-Konto aus.
- Wählen Sie einen GPU-fähigen Supervisor aus.
- Geben Sie einen Namen für die Region ein.
Eine Region wird automatisch ausgewählt, wenn der Supervisor bereits mit einer Region konfiguriert ist.
Wenn der Supervisor keiner Region zugeordnet ist, fügen Sie in diesem Schritt einen Supervisor hinzu. Ziehen Sie die Verwendung eines aussagekräftigen Namens für die Region in Betracht, damit die Benutzer GPU-fähige Regionen problemlos von anderen verfügbaren Regionen unterscheiden können.
- Klicken Sie auf Nächster Schritt.
- Geben Sie Informationen zum NVIDIA-Lizenzserver an.
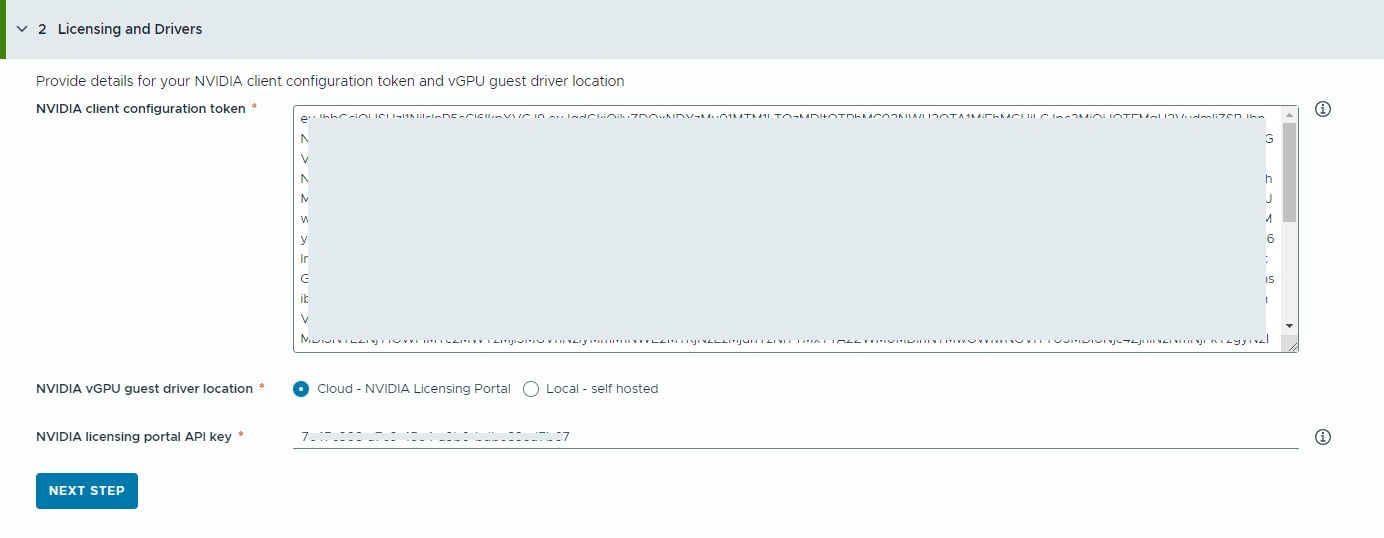
- Kopieren Sie den Inhalt des NVIDIA-Clientkonfigurationstokens und fügen Sie ihn ein.
Das Clientkonfigurationstoken wird verwendet, um dem vGPU-Gasttreiber in der Deep Learning-VM und den GPU-Operatoren auf TKG-Clustern eine Lizenz zuweisen.
- Wählen Sie den Speicherort des NVIDIA vGPU-Treibers aus.
- Cloud – Der NVIDIA vGPU-Treiber im NVIDIA-Lizenzierungsportals gehostet.
Sie müssen den API-Schlüssel des NVIDIA-Lizenzierungsportals angeben, mit dessen Hilfe ermittelt wird, ob ein Benutzer über die Berechtigung zum Herunterladen der NVIDIA vGPU-Treiber verfügt. Beim API-Schlüssel muss es sich um eine UUID handeln.
- Lokal – Der NVIDIA vGPU-Treiber wird lokal gehostet und über ein privates Netzwerk aufgerufen.
Sie müssen den Speicherort der vGPU-Gasttreiber für VMs angeben.
Für Air-Gap-Umgebungen muss der vGPU-Treiber in Ihrem privaten Netzwerk oder Datencenter verfügbar sein.
- Cloud – Der NVIDIA vGPU-Treiber im NVIDIA-Lizenzierungsportals gehostet.
- Klicken Sie auf Nächster Schritt.
- Kopieren Sie den Inhalt des NVIDIA-Clientkonfigurationstokens und fügen Sie ihn ein.
- Konfigurieren Sie eine VMware Data Services Manager-Datenbank (DSM) für RAG-Anwendungen, um separate Katalogelemente für die Datenbank zu generieren.
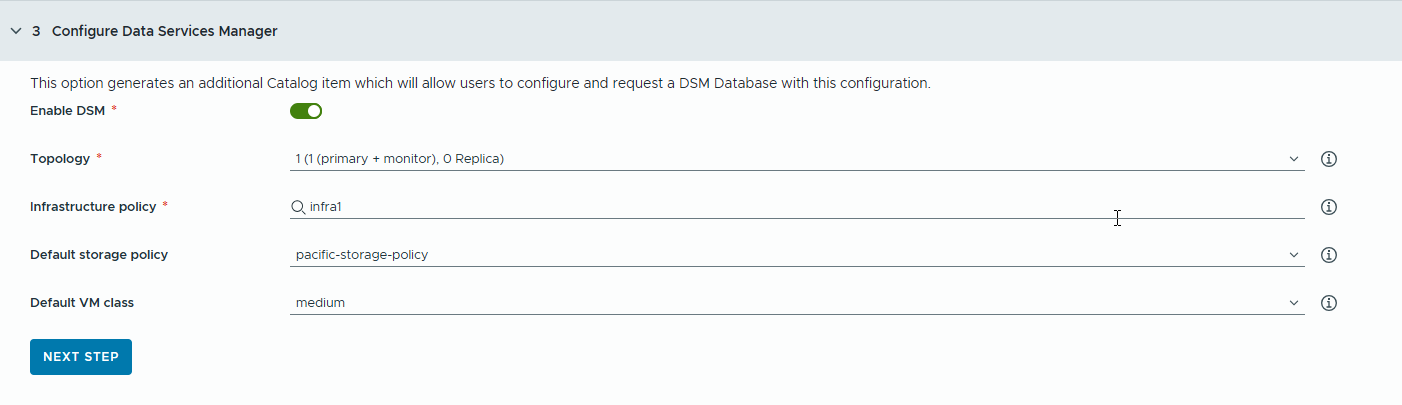
Sie verwenden VMware Data Services Manager, um Vektordatenbanken zu erstellen, z. B. eine PostgreSQL-Datenbank mit der pgvector-Erweiterung.
Datenbanken werden in einer anderen Arbeitslastdomäne als die Deep Learning-VMs bereitgestellt. Daher müssen Sie für jede Datenbank unterschiedliche VM-Klassen und Speicherprofile verwenden. Wählen Sie für VMware Data Services Manager-Datenbanken Speicherrichtlinien und VM-Klassen aus, die für RAG-Anwendungsfälle geeignet sind.
- Aktivieren Sie die Umschaltfläche.
Wenn Sie die Entwickler und Katalogbenutzer eine einzelne DSM-Datenbank gemeinsam nutzen sollen, verwenden Sie diese Option.Hinweis: Wenn die Umschaltfläche aktiviert ist, wird ein neues Katalogelement für die DSM-Datenbank erstellt.
Wenn für Ihr Projekt keine DSM-Integration erforderlich ist, können Sie die Umschaltoption deaktivieren und mit dem nächsten Schritt fortfahren. In diesem Fall wird kein DSM-Katalogelement erzeugt. Ihre Benutzer verfügen aber weiterhin über eine eingebettete DSM-Datenbank in anderen RAG-Katalogelementen.
- Wählen Sie einen Replikatmodus und eine Topologie aus.
Die Konfiguration der Datenbankknoten hängt vom Replikatmodus ab.
- Einzelserver – ein primärer Knoten ohne Replikate.
- Einzelner vSphere-Cluster – drei Knoten (1 primärer Knoten, 1 Monitor, 1 Replikat) auf einem einzelnen vSphere-Cluster, der unterbrechungsfreie Upgrades bereitstellt.
- Wählen Sie eine Infrastrukturtopologie aus.
Mit der Infrastrukturrichtlinie werden Qualität und Quantität der Ressourcen definiert, die von der Datenbank aus vSphere-Clustern verbraucht werden können.
Nach dem Festlegen einer Infrastrukturrichtlinie können Sie eine Auswahl aus Speicherrichtlinien und VM-Klassen treffen, die mit der Infrastrukturrichtlinie verknüpft sind.
- Wählen Sie eine Standardspeicherrichtlinie aus.
Mit der Speicherrichtlinie werden die Speicherplatzierung und die Ressourcen für die Datenbank definiert.
- Wählen Sie eine VM-Standardklasse aus.
Es ist keine VM-Klasse verfügbar, auf der die neu angeforderte Datenbank bereitgestellt werden kann.
Beachten Sie, dass sich DSM-VM-Klassen von Supervisor-VM-Klassen unterscheiden.
- Aktivieren Sie die Umschaltfläche.
- Konfigurieren Sie die Katalogelemente.
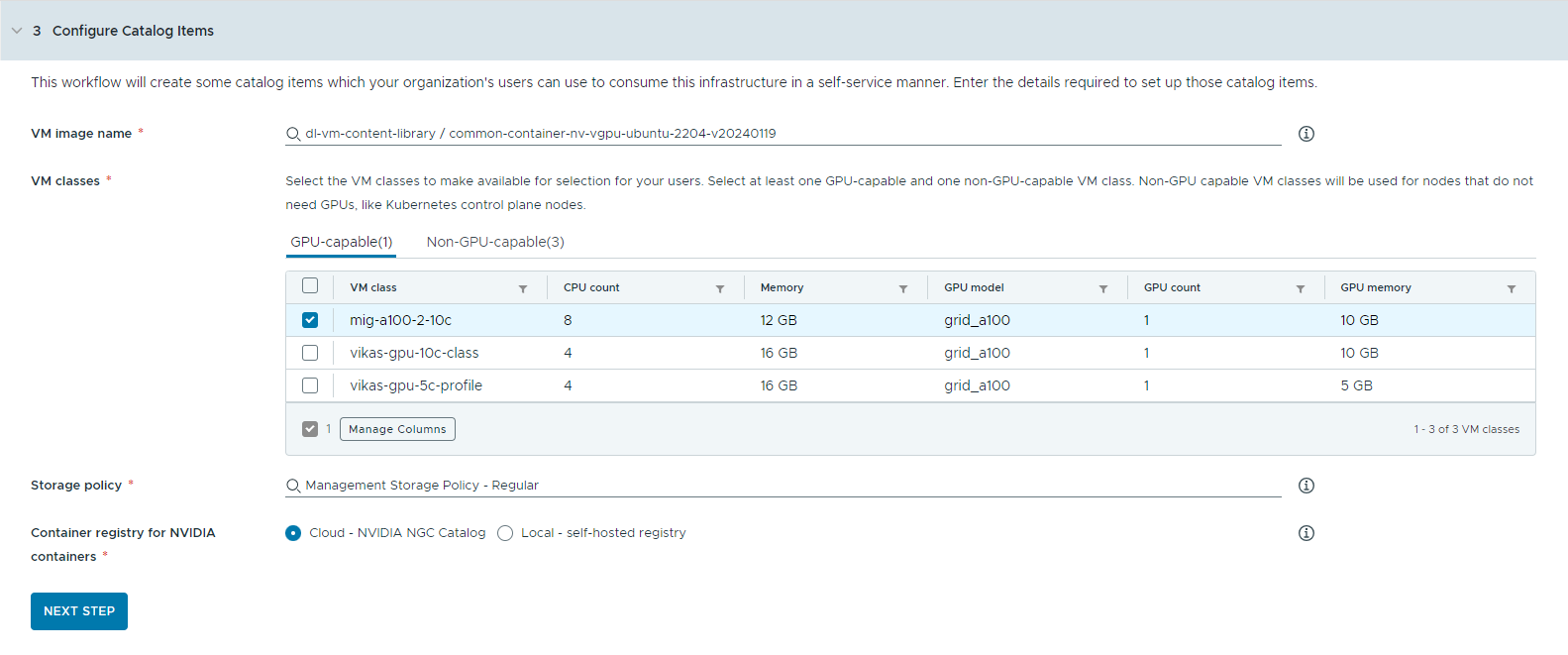
- Wählen Sie die Inhaltsbibliothek aus, die das Deep Learning-VM-Image enthält.
Sie können jeweils nur auf eine Inhaltsbibliothek zugreifen. Wenn die Inhaltsbibliothek Kubernetes-Images enthält, werden diese Images herausgefiltert, um die Navigation zu erleichtern.
- Wählen Sie das VM-Image aus, das Sie zum Erstellen der Workstation-VM verwenden möchten.
- Wählen Sie eine Tanzu Kubernetes-Version aus, die Sie für die Bereitstellung von KI-Kubernetes-Clustern verwenden möchten.
Bei der TKr (Tanzu Kubernetes release) handelt es sich um die Kubernetes-Laufzeitversion, die bei der Anforderung eines Kubernetes-Clusters durch einen Benutzer bereitgestellt wird. Die drei aktuellen TKr-Versionen, die für VMware Private AI Foundation unterstützt werden, stehen zur Auswahl zur Verfügung.
- Wählen Sie die VM-Klassen aus, die Sie Ihren Katalogbenutzern zur Verfügung stellen möchten.
Sie müssen mindestens eine GPU-fähige und eine nicht GPU-fähige Klasse hinzufügen.
- GPU-fähige VM-Klassen werden für die Deep Learning-VM und die Worker-Knoten des TKG-Clusters verwendet. Nach der Bereitstellung des Katalogelements wird der TKG-Cluster mit den ausgewählten VM-Klassen erstellt.
- Zum Ausführen der Kubernetes-Steuerungsebenen sind nicht GPU-fähige Knoten erforderlich.
- VM-Klassen mit aktiviertem UVM (Unified Virtual Memory) sind erforderlich, um KI-Workstations mit Triton Inference Server auszuführen.
- Wählen Sie eine Speicherrichtlinie aus.
Mit der Speicherrichtlinie werden die Speicherplatzierung und die Ressourcen für die virtuellen Maschinen definiert.
Die für die VM definierte Speicherrichtlinie ist nicht mit der VMware Data Services Manager-Speicherrichtlinie identisch.
- Geben Sie die Containerregistrierung an, aus der NVIDIA GPU-Cloud-Ressourcen abgerufen werden sollen.
- Cloud – Die Container-Images werden aus dem NVIDIA NGC-Katalog abgerufen.
- Lokal – Für Air-Gap-Umgebungen werden die Container aus einer privaten Registrierung abgerufen.
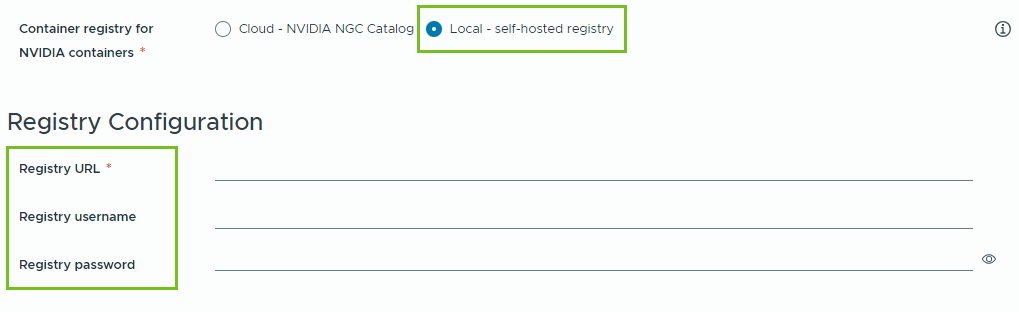
Sie müssen den Speicherort der selbstgehosteten Registrierung angeben. Wenn die Registrierung authentifiziert werden muss, müssen Sie auch Anmeldedaten angeben.
Sie können Harbor als lokale Registrierung für Container-Images aus dem NVIDIA NGC-Katalog verwenden. Weitere Informationen finden Sie unter Einrichten einer Private Harbor-Registrierung in VMware Private AI Foundation with NVIDIA.
- (Optional) Konfigurieren Sie einen Proxyserver.
In Umgebungen ohne direkten Internetzugriff wird der Proxyserver zum Herunterladen des vGPU-Treibers und zum Abrufen der Nicht-RAG-KI-Workstation-Container verwendet.
Hinweis: Unterstützung für Air-Gap-Umgebungen ist für die Katalogelemente „KI-Workstation“ und „Triton Inference Server“ verfügbar. Die Elemente „KI-RAG-Workstation“ und „KI-Kubernetes-Cluster“ bieten keine Unterstützung für Air-Gap-Umgebungen und benötigen eine Internetverbindung. - Klicken Sie auf Nächster Schritt.
- Wählen Sie die Inhaltsbibliothek aus, die das Deep Learning-VM-Image enthält.
- Konfigurieren Sie den Zugriff auf die Katalogelemente, indem Sie ein Projekt erstellen und Benutzer zuweisen.
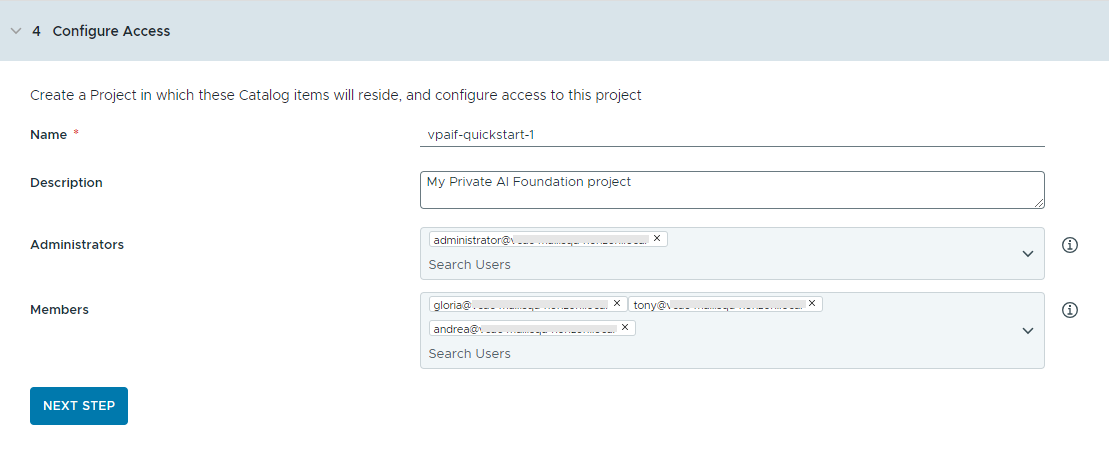
Projekte werden verwendet, um Personen, zugewiesene Ressourcen, Cloud-Vorlagen und Bereitstellungen zu verwalten.
- Geben Sie einen Namen und eine Beschreibung für das Projekt ein.
Der Projektname darf nur alphanumerische Kleinbuchstaben oder Bindestriche (-) enthalten.
- Zur Bereitstellung der Katalogelemente für andere Benutzer fügen Sie einen Administrator und Mitglieder hinzu.
Administratoren verfügen über mehr Berechtigungen als Mitglieder. Weitere Informationen finden Sie unter Definition der VMware Aria Automation-Benutzerrollen.
- Klicken Sie auf Nächster Schritt.
- Geben Sie einen Namen und eine Beschreibung für das Projekt ein.
- Überprüfen Sie Ihre Konfiguration auf der Seite Übersicht.
Sie sollten die Details für Ihre Konfiguration speichern, bevor Sie den Assistenten ausführen.
- Klicken Sie auf Schnellstart ausführen.
Ergebnisse
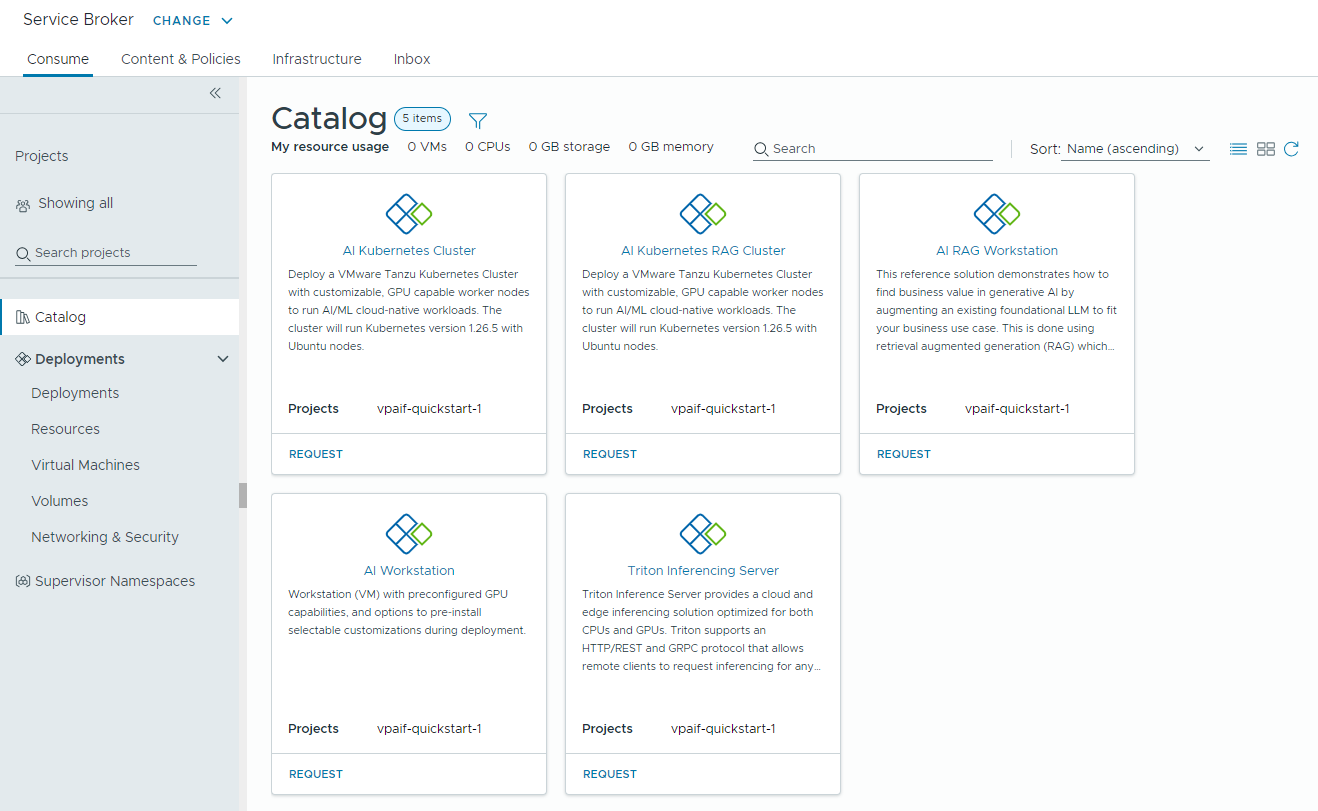
Die folgenden Katalogelemente – KI-Workstation, KI-RAG-Workstation, KI-RAG-Workstation mit DSM, DSM-Datenbank, Triton Inferencing Server, KI-Kubernetes-Cluster, KI-Kubernetes-RAG-Cluster und KI-Kubernetes-RAG-Cluster mit DSM werden im Automation Service Broker-Katalog erstellt und können jetzt von Benutzern in Ihrer Organisation bereitgestellt werden.
Fehlerbehebung
- Wenn der Assistent für die Katalogeinrichtung fehlschlägt, führen Sie den Assistenten für ein anderes Projekt erneut aus.
